

Du har säkert hört talas om ICMP och om du bara är en smula tekniskt kunnig, vet du förmodligen (åtminstone) att det har något med Internet att göra.
ICMP är faktiskt ett protokoll, ungefär som IP, TCP och UDP (som vi tidigare diskuterat och förklarat), så det spelar en ganska viktig roll för att våra internetanslutningar ska fungera väl.
ICMP har mer att göra med hur anslutningsproblem upptäcks och hanteras, men låt oss inte förstöra för mycket av vår föreläsning. Fortsätt läsa om du vill veta vad ICMP är och hur det hjälper oss att upprätthålla våra anslutningar på optimala nivåer.

Innehållsförteckning
Vad är ICMP?
Internet Control Message Protocol, som de flesta känner till under sin vänligare akronym ICMP, är ett protokoll som är grundläggande för att felsöka olika anslutningsrelaterade problem.
Detta protokoll används av en mängd olika nätverksenheter, inklusive men inte begränsat till routrar, modem och servrar för att informera andra nätverksdeltagare om potentiella anslutningsproblem.
Vi har nämnt ovan att ICMP är ett protokoll precis som TCP och UDP, men till skillnad från dessa två används ICMP i allmänhet inte för att underlätta utbyte av data mellan system. Dessutom används det inte ofta i nätverksappar för slutanvändare, såvida de inte är diagnostiska verktyg.
ICMP:s ursprungliga definition skissades av Jon Postel, som bidrog massivt och många gånger till utvecklingen av Internet, och den första standarden för ICMP publicerades i april 1981 i RFC 777.
Uppenbarligen gick den ursprungliga definitionen igenom många förändringar för att nå den form som vi är bekanta med idag. Den stabila formen av detta protokoll publicerades 5 månader senare än dess ursprungliga definition, september 1981, i RFC 792, och skrevs också av Postel.
Hur fungerar ICMP?
Kort sagt, ICMP används för felrapportering genom att avgöra om data når sin avsedda destination relativt snabbt eller inte.
I ett grundscenario är två enheter anslutna via Internet och utbyter information genom vad vi kallar datapaket eller datagram. Vad ICMP gör är att generera fel och dela dem med enheten som skickade originaldata ifall paketen aldrig når sin destination.
Om du till exempel skickar ett datapaket som helt enkelt är för stort för routern att hantera, kommer routern först att tappa paketet och sedan generera ett felmeddelande som låter avsändarenheten att dess paket aldrig nådde destinationen det var på väg till.
Det är dock vad vi skulle kalla en passiv färdighet eftersom det absolut inte finns något du behöver göra för att få dessa felmeddelanden (om behovet uppstår). Som du snart kommer att upptäcka har ICMP också ett mer aktivt verktyg, som du kan lita på för att utföra olika felsökningsåtgärder för nätverket.
Till skillnad från TCP och UDP behöver ICMP inte ha en enhet ansluten för att skicka ett meddelande. I en TCP-anslutning, till exempel, måste de anslutna enheterna utföra en flerstegshandskakning, varefter data kan överföras.
Med ICMP behöver ingen anslutning upprättas; ett meddelande kan enkelt skickas i stället för en anslutning. Dessutom kräver ett ICMP-meddelande inte en port att dirigera meddelandet till, jämfört med TCP och UDP, som båda använder specifika portar för att dirigera information genom. Inte nog med att ICMP inte kräver en port, utan det tillåter faktiskt inte inriktning på specifika portar.
ICMP-meddelanden bärs av IP-paket men finns inte i dem. Istället piggyback de på dessa paket, eftersom de bara genereras om deras operatör (dvs. IP-paketen) aldrig når sin destination. Oftare än inte är omständigheterna som gjorde att ett ICMP-paket kunde skapa ett resultat av tillgänglig data i det misslyckade paketets IP-huvud.
Eftersom ICMP inkluderar data från det misslyckade paketets IP-huvud, kan nätverksanalysverktyg användas för att bestämma exakt vilka IP-paket som inte kunde levereras. IP-huvudet är dock inte den enda typen av information som bärs av ICMP-paketet.
Ett ICMP-paket innehåller IP-huvudet, följt av ett ICMP-huvud, och nyttolastens första åtta byte.
IP-rubrik – innehåller information om IP-version, käll- och destinations-IP-adresser, antalet skickade paket, protokollet som används, paketlängd, time to live (TTL), synkroniseringsdata, samt ID-nummer för särskilda datapaket
ICMP header – innehåller en kod som hjälper till att kategorisera felet, en underkod som underlättar felidentifiering genom att erbjuda en beskrivning och en kontrollsumma
Transportlagerhuvud – första åtta byte av nyttolasten (överförd via TCP eller UDP)
ICMP-kontrollmeddelanden
Som vi har nämnt ovan, när ett fel uppstår, kan värdena i det första fältet i ICMP-huvudet användas för att identifiera det. Dessa feltyper, tillsammans med deras identifierare, är följande:
0 – Echo Reply – används för pingsyften
3 – Destinationen går inte att nå
5 – Omdirigeringsmeddelande – används för att indikera val av en annan rutt
8 – Echo Request – används för pingsyften
9 – Routerannonsering – används av routrar för att meddela att deras IP-adresser är tillgängliga för routing
10 – Router Solicitation – routerupptäckt, uppmaning eller val
11 – Tid överskriden – TTL har gått ut eller återmonteringstiden har överskridits
12 – Parameterproblem: Dålig IP-rubrik – dålig längd, obligatoriskt alternativ saknas eller pekare-indikerat fel
13 – Tidsstämpel
14 – Tidsstämpelsvar
41 – används för experimentella mobilitetsprotokoll
42 – Extended Echo Request – ber om utökat Echo
43 – Extended Echo Reply – svar på 42 utökad Echo-förfrågan
253 och 254 – experimentell
TTL-fältet (Time to Live).
TTL-fältet är ett av IP-huvudfälten som kan (och ofta gör) generera ett ICMP-fel. Den innehåller ett värde som är det maximala antalet routrar som ett skickat paket kan passera innan det når sin slutdestination.
Efter att paketet har bearbetats av en router minskar detta värde med ett, och processen fortsätter tills en av två saker händer: antingen når paketet sin destination eller så når värdet noll, vilket vanligtvis följs av att routern tappar paket och skicka ett ICMP-meddelande till den ursprungliga avsändaren.
Så det säger sig självt att om ett paket tappas på grund av att dess TTL nådde noll, är det inte på grund av skadad data i rubriken eller routerspecifika problem. TTL designades faktiskt för att blockera oseriösa paket från att hindra anslutningar och har resulterat i skapandet av ett verktyg som är avgörande för nätverksfelsökning: Traceroute.
ICMP-användning i nätverksdiagnostik
Som nämnts ovan kan ICMP användas med diagnostiska verktyg för att fastställa hur väl en nätverksanslutning fungerar. Du kanske inte visste vad ICMP är innan du läste vår guide, men vi är säkra på att du åtminstone hört talas om ping, det berömda nätverksverktyget som låter dig veta om en värd kan nås eller inte.
Tja, ping är faktiskt ett viktigt verktyg som använder ICMP som sin ryggrad. Traceroute är ett annat bra exempel på verktyg som hjälper oss att diagnostisera och felsöka anslutningsproblem i våra nätverk. Pathping, som är en kombination av ping och traceroute, är ännu ett bra ICMP-baserat verktyg.
Ping
Ping är ett inbyggt Windows-verktyg som kan nås via CMD och är ett av de viktigaste verktygen som använder ICMP för att felsöka potentiella nätverksfel. Ping använder två av koderna i listan ovan, 8 (ekobegäran) och 0 (ekosvar), för att vara mer specifik.
Så här ser två pingkommandonexempel ut:
ping 168.10.26.7
ping wdzwdz.com
När du kör det kommer ping att skicka ett ICMP-paket med en kod 8 i typfältet och väntar tålmodigt på typ 0-svaret. Efter att svaret kommer, kommer ping att bestämma tiden mellan förfrågan (8) och dess svar (0) och returnerar värdet på tur-och returresan uttryckt i millisekunder.
Vi har redan fastställt att ICMP-paket vanligtvis genereras och skickas som ett resultat av ett fel. Emellertid behöver paketet för begäran (typ 8) inget fel för att skickas, därför kan ping också få svaret (0) tillbaka utan att utlösa ett fel.
Som du förmodligen har räknat ut från våra exempel ovan kan du pinga en IP-adress eller en värd. Dessutom har ping en uppsjö av ytterligare alternativ som du kan använda för mer avancerad felsökning genom att helt enkelt lägga till alternativet till kommandot.
Om du till exempel använder alternativet -4 tvingar ping att använda IPv4 exklusivt, medan -6 endast kommer att använda IPv6-adresser. Kolla in skärmdumpen nedan för en komplett lista över alternativ som du kan lägga till ditt pingkommando.
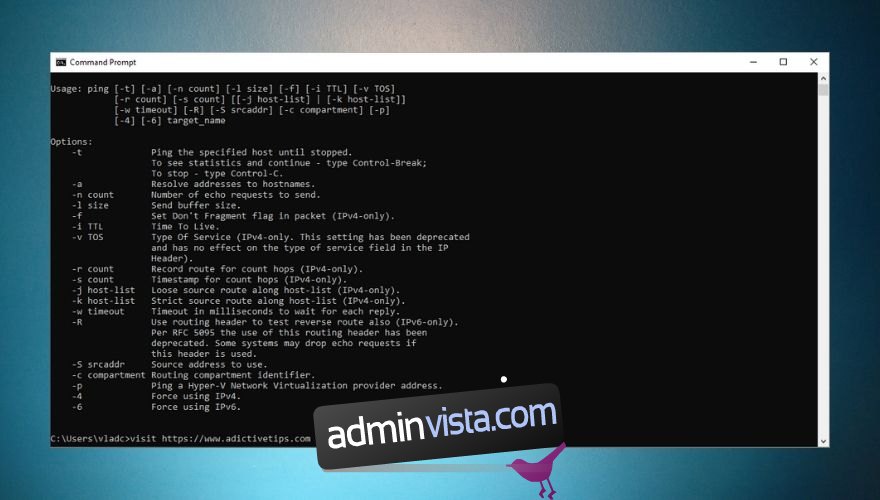
En vanlig missuppfattning om ping är att du kan använda den för att testa tillgängligheten för vissa portar på riktade system. Lång historia kort, du kan inte göra det, eftersom ICMP inte gör något verkligt meddelandeutbyte mellan värdar, till skillnad från TCP eller UDP, och inte kräver portanvändning.
Portskannerappar använder TCP- eller UDP-paket för att avgöra om specifika portar är öppna och tillgängliga eller inte. Verktygen skickar TCP- eller UDP-paket till en specifik port och genererar ett ICMP-meddelande av typ 3 (värd ej nåbar) undertyp 3 (destinationsport ej nåbar) om den porten inte är aktiv.
Traceroute
Precis som ping är traceroute ett annat nätverksfelsökningsverktyg som varje nätverksadministratör inte bara bör ha i sitt verktygsbälte utan också behärska. Vad traceroute gör är att hjälpa dig att kartlägga en rutt för alla enheter som din anslutning stöter igenom tills den når sin angivna destination.
Så om du är intresserad av att hitta hela rutten mellan dig och en annan maskin kan traceroute ge dig exakt den informationen. Det här verktyget kan också användas för att avgöra om det är något fel längs rutten din anslutning följer.
Om det till exempel finns en enhet på anslutningsvägen som har svårt att vidarebefordra dina paket till sin avsedda destination, kommer traceroute att låta dig veta vilken router som ger dig ett försenat svar (eller inget alls).
Sättet som traceroute fungerar är genom att skicka ett paket med ett TTL-värde (Time To Live) på 0, som automatiskt släpps av den första routern den stöter på, som vi har förklarat ovan i TTL-avsnittet. Efter att ha tappat paketet genererar routern ett ICMP-paket och skickar tillbaka det till traceroute.
Programmet extraherar paketets källadress, samt den tid det tog för paketet att komma tillbaka, och skickar sedan ett annat paket med ett TTL-värde på 1. Efter att det andra paketet går genom gatewayen minskar dess TTL med 1 (blir 0 ) och går till den andra routern, som, när TTL-värdet noll detekteras, tappar paketet och skickar ett ICMP-paket tillbaka till traceroute.
Varje gång traceroute tar emot ett ICMP-paket, ökar den TTL med ett och skickar det tillbaka på sitt spår, och denna operation fortsätter och fortsätter tills den angivna destinationen nås, eller traceroute får slut på hopp. Som standard allokerar Windows ett maximalt belopp på 30 hopp, men du kan öka det genom att ange det i kommandosyntaxen.
Här är ett exempel på hur du kan köra traceroute i CMD:
tracert wdzwdz.com
Precis som ping har traceroute en rad alternativ som du kan lägga till syntaxen om du vill vara mer specifik. Du kan tvinga fram IPv4 eller IPv6, men du kan också hoppa över att lösa adresser till värdnamn och öka det maximala antalet hopp för att söka efter målet. Kolla in vår skärmdump nedan för ett traceroute-användningsexempel och en lista över alla alternativ du kan använda med den.
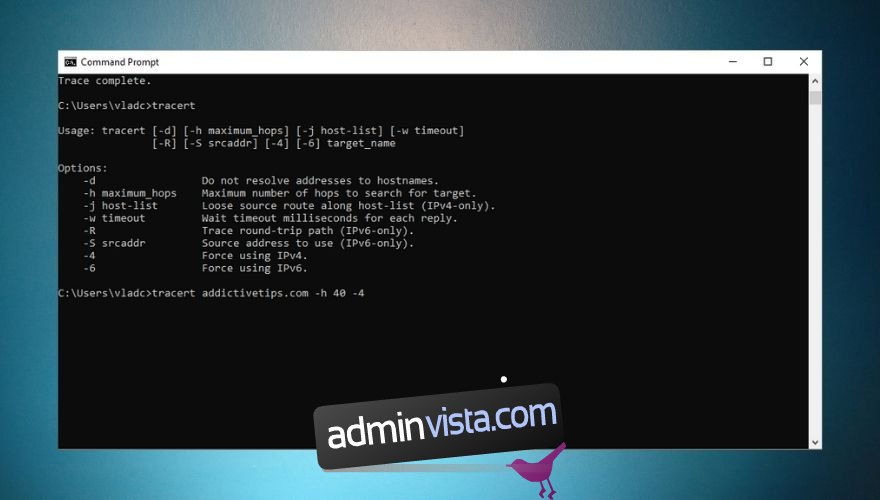
Det är dock värt att nämna att traceroute bara kan ge dig realtidsinformation. Därför, om du har stött på en avmattning i din anslutning och vill använda det här verktyget för att undersöka det, kan du få missvisande resultat eftersom rutten kan ha ändrats under tiden.
Även om det är möjligt att tvinga traceroute att följa en viss väg genom att använda -j-alternativet och lägga till routeradresser manuellt, innebär det att du redan är medveten om den felaktiga sökvägen. Detta är något paradoxalt, eftersom att upptäcka sökvägen i första hand kräver att du använder traceroute utan alternativet -j.
Om du inte precis är ett fan av att använda CLI-verktyg (Command Line Interface) och mycket hellre skulle föredra ett GUI (Graphical User Interface) tillvägagångssätt, finns det många tredjeparts mjukvarulösningar för traceroute. SolarWinds Traceroute NG är ett av de bästa exemplen vi kan tänka oss. Nämnde vi att det är helt gratis?
Pathping
Som vi kort har nämnt ovan, fullbordar pathping trifektan av oumbärliga nätverksfelsökningsverktyg. Ur funktionssynpunkt är patphing en kombination av ping och traceroute, eftersom den använder sig av alla tre meddelandetyper som ovannämnda duon utnyttjar: ekobegäran (8), ekosvar (0) samt överskriden tid (11).
Oftast används sökväg för att identifiera anslutningsnoder som påverkas av hög latens och paketförlust. Visst kan du använda traceroute och sedan pinga för att få dessa detaljer, men att ha funktionaliteten för båda verktygen under ett enda kommando är mycket bekvämare för nätverksadministratörer.
En av nackdelarna med att använda pathping är att det kan ta ganska lång tid att avsluta sin förfrågan (25 sekunder per hopp för att ge pingstatistik). Pathping visar dig både rutten till den angivna destinationen och tider för tur och retur dit.
I motsats till ping och traceroute kommer pathping att pinga varje router i dess väg upprepade gånger, vilket ökar dess totala effektivitet. Men om den stöter på en router som har inaktiverat dess ICMP-funktioner, kommer pathping att stoppa dess begäran om information, medan ping fortfarande kan nå en router utan ICMP-funktioner, och traceroute hoppar till nästa router i dess väg och visar en rad asterisker för alla icke-ICMP-routrar.
Pathping är ett Windows inbyggt verktyg och har varit så sedan Windows NT, så du kan använda det som du skulle pinga eller tracert: via en kommandorad.
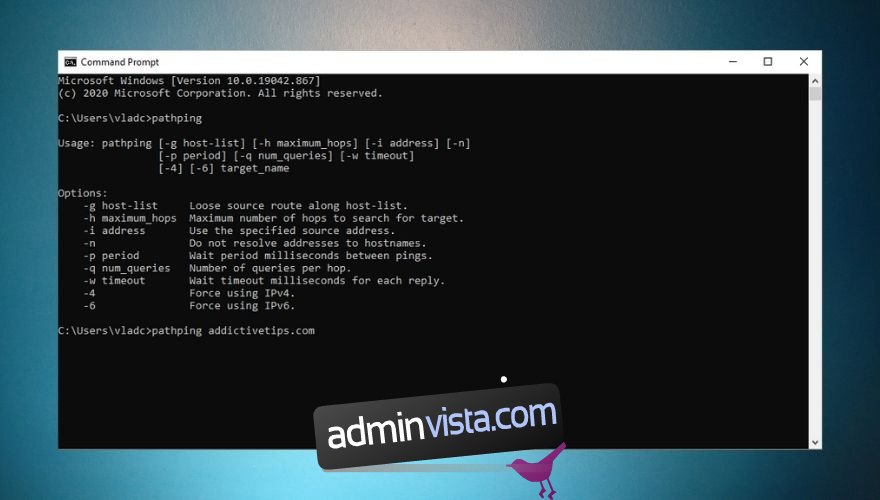
Här är ett exempel på hur du kan använda pathping:
pathping wdzwdz.com -h 40 -w 2 -4
Kommandot ovan visar dig rutten till vår webbplats, såväl som tur-returtiderna till varje router i anslutningsvägen. Dessutom kommer alternativen vi använde i vårt exempel att öka standardvärdet för maximalt hopp från 30 till 40, lägga till ett timeoutvärde på 2 millisekunder för varje svar och tvinga fram IPv4.
Kolla in vår skärmdump nedan för en snabbguide för användning av sökvägar och en lista över alternativ som du kan lägga till i kommandosyntaxen.
ICMP tillämplighet vid cyberattacker
Även om ICMP:s utbud underlättar många felsökningsoperationer för anslutningar, kan detta protokoll också utnyttjas för att utföra olika cyberattacker. Om du har varit tillräckligt länge på Internet har du förmodligen hört talas om ping-översvämningar, DDoS, Ping of Death, Smurfattacker eller ICMP-tunnlar.
Medan vissa av dessa attacker nuförtiden fungerar som PoC (Proof of Concept), används andra fortfarande av skadliga agenter för att skada Internet-aktiverade system eller av säkerhetsexperter för att testa för sårbarheter.
Vi börjar med den mest populära, som är pingfloden (förresten fortfarande allmänt använd), och förklarar hur den använder ICMP för ondska.
Pingflod
Att använda ping för att skicka ekoförfrågningar och vänta på ekosvar verkar ganska ofarligt. Men vad händer om, istället för att vänta på svaret, ping bara skulle skicka en enorm mängd ICMP-ekoförfrågningar? I detta klassiska DoS (Denial of Service)-attackscenario skulle målenheten uppleva kraftig eftersläpning och till och med anslutningen avbryts om attacken lyckas.
Den här attacken är mest effektiv om angriparen har mer bandbredd än offret, och om offret skickar ICMP-ekosvar på de många förfrågningar den tar emot, vilket förbrukar såväl inkommande som utgående bandbredd.
Angriparen kan ange ett ”flood”-alternativ för ping-kommandot, men detta alternativ är ganska sällsynt och inte inbäddat i operativsystemets inbyggda verktyg. Till exempel har Windows ping inte ett ”flood”-alternativ, men det finns några tredjepartsverktyg som integrerar den här funktionen.
En pingflodsattack kan verkligen bli katastrofal om den förvandlas till en DDoS-attack (Distributed Denial of Service). En DDoS-attack använder flera system för att rikta in sig på ett enda, vilket överväldigar det med paket från flera platser samtidigt.
Ett säkert sätt att skydda dig mot en pingflod är att inaktivera ICMP-funktioner på din router. Du kan också installera en webbappsbrandvägg om du behöver skydda en webbserver från sådana attacker.
Ping of Death
Denna attack innebär att en felaktig ping skickas till en måldator. I denna typ av attack kommer det skickade paketet att innehålla en mängd fyllmedel i nyttolasten som är för stor för att kunna behandlas på en gång.
Men innan den skickas kommer denna skadliga ping att fragmenteras i mindre delar, eftersom det skulle vara omöjligt för Internet Protocol-processorn att överföra den i sin ursprungliga, sammansatta form.
Datorn som är måltavla av Ping of Death kommer att ta emot bitarna och försöka sätta ihop dem igen innan det skadliga paketet skickas till dess målapplikation. Det är här som skadan inträffar: om det sammansatta paketet är längre än det tillgängliga minnet i måldatorn, kan återmontering resultera i ett buffertspill, systemkraschar och till och med tillåta att skadlig kod injiceras i den drabbade maskinen.
På den ljusa sidan är Ping of Death inte längre en nyhet, eftersom många säkerhetssystem känner igen den utan hicka och framgångsrikt blockerar den.
Smurf attack
Till skillnad från de två föregående attacktyperna attackerar inte en Smurfattack en enhet direkt utan använder sig av andra enheter på samma nätverk för att koordinera en distribuerad DoS-attack (en DDoS) mot en enda maskin.
Angriparen behöver sitt måls IP-adress och målnätverkets IP-sändningsadress. Angriparen lägger till offrets IP-adress till ICMP-paket (spoofar det) och sänder dem sedan till målets nätverk med hjälp av en IP-sändningsadress.
Som svar kommer de flesta enheter som är anslutna till samma nätverk att skicka ett svar till källans IP-adress (ersätts för att återspegla målets maskin), vilket kan överväldigas med trafik om nätverket är tillräckligt stort (har ett stort antal anslutna enheter).
Som ett resultat kan målets dator saktas ner och till och med göras oanvändbar under en viss tidsperiod, om attacken är tillräckligt allvarlig.
Som tidigare kan du undvika en Smurfattack genom att helt enkelt stänga av din gateway-routers ICMP-funktioner. Ett annat sätt du kan uppnå skydd är genom att svartlista förfrågningar som kommer från ditt nätverks sändnings-IP-adress.
Twinge attack
En Twinge-attack leds av ett program som skickar en flod av falska ICMP-paket för att skada ett system. ICMP-paketen är falska eftersom de alla använder slumpmässiga falska IP-adresser, men i verkligheten kommer paketen från en enda källa (angriparens maskin).
Enligt uppgift innehåller ICMP-paketen en signatur som kan ge bort det faktum att attacken inte kom från flera källor, utan koordinerades med hjälp av Twinge istället.
Även om denna attack kan vara katastrofal om den planeras rätt, kan du skydda dig mot den genom att stänga av ICMP på din gateway-router och installera en brandvägg eller ett intrångsdetekteringssystem.
ICMP-tunnel
Som standard söker routrar endast efter ICMP-paketets rubriker, vilket gör det möjligt att paket som faktiskt innehåller mycket extra data enkelt kan kringgå upptäckt bara så länge de innehåller en ICMP-sektion. Denna typ av attack kallas en ping- eller ICMP-tunnel. Lyckligtvis kan standard ping-verktyg inte tunnla genom brandväggar och gateways, eftersom ICMP-tunnlar måste anpassas noggrant till de nätverk de är avsedda för.
Å andra sidan finns det många onlineresurser som angripare kan använda och efterlikna en sådan tunnel, vilket ger sig själva fri passage genom privata nätverk och maskiner som är anslutna till den. Som tidigare kan det vara avgörande att stänga av ICMP-funktioner på din gateway-router, använda brandväggar och upprätthålla strikta svartlistningsregler för att undvika denna typ av attack.
ICMP – Slutsats
Allt övervägt, även om ICMP inte används för att utbyta information mellan anslutna enheter på ett givet nätverk som TCP och UDP gör, har det fortfarande ett enormt tillämplighetsområde. Faktum är att ICMP är ett av de mest flexibla grundläggande protokollen som hjälper till att hålla Internet som vi känner det.
Bortsett från dess grundläggande syfte att låta ett system veta när det finns en choke i dess anslutning till ett annat system, är ICMP ryggraden i många felsökningsverktyg som ping, pathping och traceroute. Tyvärr hjälper det också skadliga agenter att leverera ett brett utbud av DoS- och infiltrationsattacker till sårbara maskiner.