
Inom området modern artificiell intelligens (AI) är förstärkningsinlärning (RL) ett av de coolaste forskningsämnena. Utvecklare av AI och maskininlärning (ML) fokuserar också på RL-praxis för att improvisera intelligenta appar eller verktyg som de utvecklar.
Maskininlärning är principen bakom alla AI-produkter. Mänskliga utvecklare använder olika ML-metoder för att träna sina intelligenta appar, spel etc. ML är ett mycket diversifierat område och olika utvecklingsteam kommer med nya metoder för att träna en maskin.
En sådan lukrativ metod för ML är djup förstärkningsinlärning. Här straffar du oönskade maskinbeteenden och belönar önskade handlingar från den intelligenta maskinen. Experter anser att denna metod för ML är skyldig att driva AI att lära av sina egna erfarenheter.
Fortsätt att läsa den här ultimata guiden om förstärkningsinlärningsmetoder för intelligenta appar och maskiner om du funderar på en karriär inom artificiell intelligens och maskininlärning.
Innehållsförteckning
Vad är förstärkningsinlärning i maskininlärning?
RL är undervisning av maskininlärningsmodeller till datorprogram. Därefter kan applikationen fatta en sekvens av beslut baserat på inlärningsmodellerna. Programvaran lär sig att nå ett mål i en potentiellt komplex och osäker miljö. I den här typen av maskininlärningsmodell står en AI inför ett spelliknande scenario.
AI-appen använder trial and error för att uppfinna en kreativ lösning på problemet. När AI-appen har lärt sig korrekta ML-modeller, instruerar den maskinen den styr att utföra vissa uppgifter som programmeraren vill ha.
Baserat på rätt beslut och slutförande av uppgiften får AI:n en belöning. Men om AI:n gör fel val möter den straff, som att förlora belöningspoäng. Det slutliga målet för AI-applikationen är att samla maximalt antal belöningspoäng för att vinna spelet.
Programmeraren för AI-appen anger spelreglerna eller belöningspolicyn. Programmeraren tillhandahåller också problemet som AI:n behöver lösa. Till skillnad från andra ML-modeller får AI-programmet ingen ledtråd från programvaruprogrammeraren.
AI:n måste ta reda på hur man löser spelutmaningarna för att få maximala belöningar. Appen kan använda trial and error, slumpmässiga försök, superdatorkunskaper och sofistikerad tankeprocesstaktik för att nå en lösning.
Du måste utrusta AI-programmet med kraftfull datorinfrastruktur och koppla samman dess tankesystem med olika parallella och historiska spel. Sedan kan AI visa kritisk kreativitet på hög nivå som människor inte kan föreställa sig.
Populära exempel på förstärkningsinlärning
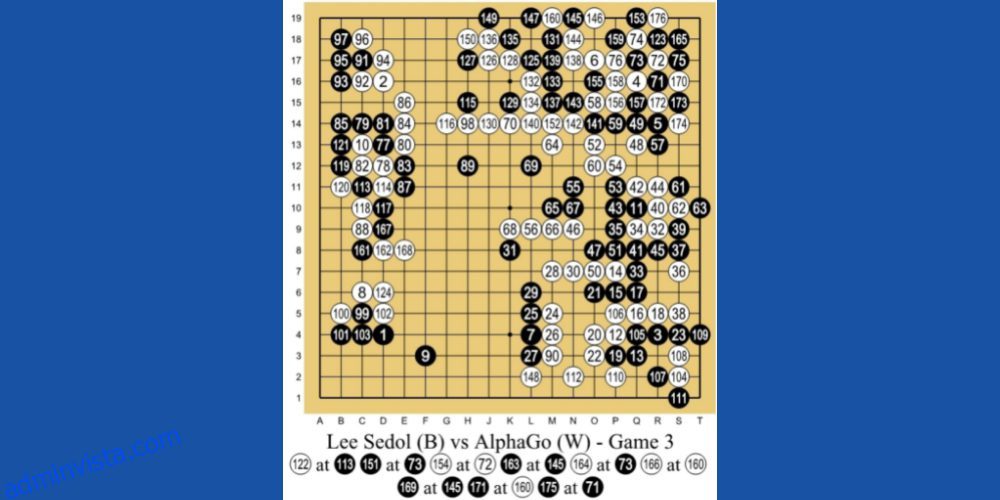
#1. Besegra den bästa Human Go-spelaren
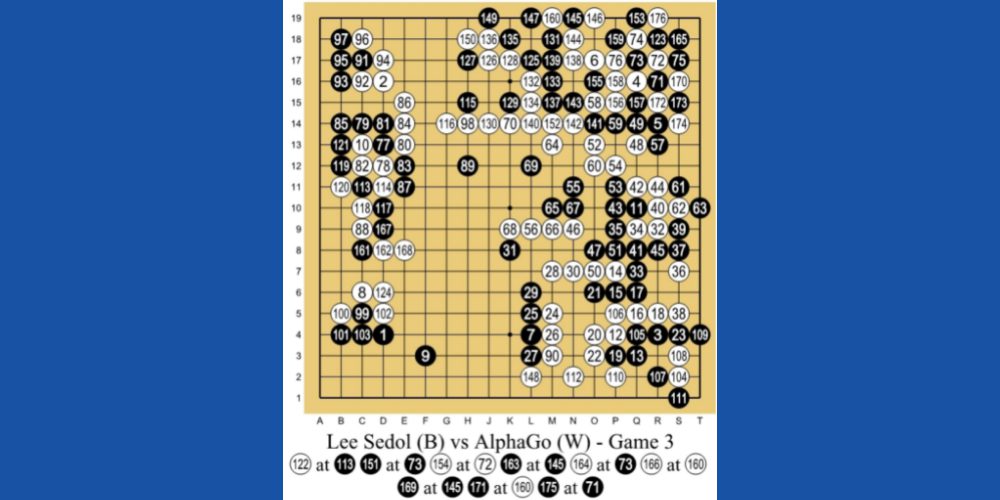
AlphaGo AI från DeepMind Technologies, ett dotterbolag till Google, är ett av de ledande exemplen på RL-baserad maskininlärning. AI:n spelar ett kinesiskt brädspel som heter Go. Det är ett 3 000 år gammalt spel som fokuserar på taktik och strategier.
Programmerarna använde RL-metoden för undervisning för AlphaGo. Den spelade tusentals Go-spelsessioner med människor och sig själv. Sedan, 2016, besegrade den världens bästa Go-spelare Lee Se-dol i en en-mot-en-match.
#2. Real-World Robotics
Människor har använt robotik länge i produktionslinjer där uppgifterna är förplanerade och repetitiva. Men om du behöver göra en generell robot för den verkliga världen där åtgärder inte är förplanerade, då är det en stor utmaning.
Men förstärkningsinlärningsaktiverad AI kan upptäcka en smidig, navigerbar och kort väg mellan två platser.
#3. Självkörande fordon
Autonoma fordonsforskare använder i stor utsträckning RL-metoden för att lära ut sina AI:er för:
- Dynamisk sökväg
- Banoptimering
- Rörelseplanering som parkering och filbyte
- Optimering av styrenheter, (elektronisk styrenhet) ECU, (mikrokontroller) MCU, etc.
- Scenariobaserat lärande på motorvägar
#4. Automatiserade kylsystem

RL-baserade AI:er kan hjälpa till att minimera energiförbrukningen för kylsystem i gigantiska kontorsbyggnader, affärscentra, köpcentra och, viktigast av allt, datacenter. AI:n samlar in data från tusentals värmesensorer.
Den samlar också in data om mänskliga och maskiners aktiviteter. Utifrån dessa data kan AI förutse den framtida värmealstringspotentialen och kopplar på och av kylsystem på lämpligt sätt för att spara energi.
Hur man ställer in en förstärkningsinlärningsmodell
Du kan ställa in en RL-modell baserat på följande metoder:
#1. Policybaserad
Detta tillvägagångssätt gör det möjligt för AI-programmeraren att hitta den idealiska policyn för maximala belöningar. Här använder inte programmeraren värdefunktionen. När du väl har ställt in den policybaserade metoden försöker förstärkningsinlärningsagenten tillämpa policyn så att de åtgärder den utför i varje steg gör att AI:n kan maximera belöningspoängen.
Det finns i första hand två typer av policyer:
#1. Deterministisk: Politiken kan producera samma handlingar i vilken stat som helst.
#2. Stokastisk: De producerade åtgärderna bestäms av sannolikheten att inträffa.
#2. Värdebaserad
Det värdebaserade tillvägagångssättet, tvärtom, hjälper programmeraren att hitta den optimala värdefunktionen, vilket är det maximala värdet under en policy i varje givet tillstånd. När RL-agenten väl har använts förväntar sig den långsiktiga avkastningen i en eller flera stater enligt nämnda policy.
#3. Modellbaserad
I den modellbaserade RL-metoden skapar AI-programmeraren en virtuell modell för miljön. Sedan flyttar RL-agenten runt i miljön och lär sig av den.
Typer av förstärkningsinlärning
#1. Positiv förstärkningsinlärning (PRL)
Positivt lärande innebär att lägga till några element för att öka sannolikheten att det förväntade beteendet kommer att hända igen. Denna inlärningsmetod påverkar RL-agentens beteende positivt. PRL förbättrar också styrkan hos vissa beteenden hos din AI.
PRL-typ av inlärningsförstärkning bör förbereda AI för att anpassa sig till förändringar under lång tid. Men att injicera för mycket positiv inlärning kan leda till en överbelastning av tillstånd som kan minska AI:s effektivitet.

#2. Negativ förstärkningsinlärning (NRL)
När RL-algoritmen hjälper AI:n att undvika eller stoppa ett negativt beteende, lär den sig av det och förbättrar sina framtida handlingar. Det är känt som negativt lärande. Det ger bara AI en begränsad intelligens bara för att uppfylla vissa beteendekrav.
Real-Life Use Cases of Reinforcement Learning
#1. Utvecklare av e-handelslösningar har byggt anpassade verktyg för produkt- eller tjänsteförslag. Du kan ansluta verktygets API till din shoppingsajt online. Sedan kommer AI:n att lära sig av enskilda användare och föreslå anpassade varor och tjänster.
#2. TV-spel med öppen värld kommer med oändliga möjligheter. Det finns dock ett AI-program bakom spelprogrammet som lär sig av spelarnas input och modifierar videospelskoden för att anpassa sig till en okänd situation.
#3. AI-baserade aktiehandels- och investeringsplattformar använder RL-modellen för att lära av aktierörelserna och globala index. Följaktligen formulerar de en sannolikhetsmodell för att föreslå aktier för investeringar eller handel.
#4. Onlinevideobibliotek som YouTube, Metacafe, Dailymotion, etc., använder AI-bots utbildade på RL-modellen för att föreslå personliga videor till sina användare.
Förstärkningsinlärning vs. Övervakat lärande
Förstärkningsinlärning syftar till att träna AI-agenten att fatta beslut sekventiellt. I ett nötskal kan du överväga att utdata från AI beror på tillståndet för den nuvarande ingången. På liknande sätt kommer nästa ingång till RL-algoritmen att bero på utdata från tidigare ingångar.

En AI-baserad robotmaskin som spelar ett parti schack mot en mänsklig schackspelare är ett exempel på RL-maskininlärningsmodellen.
Tvärtom, i övervakad inlärning, tränar programmeraren AI-agenten att fatta beslut baserat på indata som gavs i början eller någon annan initial input. Autonoma bilkörande AI:er som känner igen miljöobjekt är ett utmärkt exempel på övervakat lärande.
Förstärkningsinlärning vs. Oövervakat lärande
Hittills har du förstått att RL-metoden driver AI-agenten att lära sig av policyer för maskininlärningsmodeller. Huvudsakligen kommer AI bara att göra de steg som den får maximala belöningspoäng för. RL hjälper en AI att improvisera sig själv genom försök och misstag.
Å andra sidan, vid oövervakad inlärning, introducerar AI-programmeraren AI-programvaran med omärkta data. Dessutom berättar ML-instruktören inte AI något om datastrukturen eller vad man ska leta efter i data. Algoritmen lär sig olika beslut genom att katalogisera sina egna observationer på de givna okända datamängderna.
Förstärkningskurser
Nu när du har lärt dig grunderna, här är några onlinekurser för att lära dig avancerad förstärkningsinlärning. Du får också ett certifikat som du kan visa upp på LinkedIn eller andra sociala plattformar:
Reinforcement Learning Specialization: Coursera
Vill du behärska kärnkoncepten för förstärkningsinlärning med ML-kontext? Du kan prova detta Coursera RL kurs som är tillgängligt online och kommer med inlärnings- och certifieringsalternativ i egen takt. Kursen passar dig om du tar med dig följande som bakgrundskompetens:
- Programmeringskunskaper i Python
- Grundläggande statistiska begrepp
- Du kan konvertera pseudokoder och algoritmer till Python-koder
- Erfarenhet av mjukvaruutveckling på två till tre år
- Andra året studenter i datavetenskap disciplin är också berättigade
Kursen har ett betyg på 4,8 stjärnor och över 36 000 studenter har redan anmält sig till kursen under olika tidsperioder. Dessutom kommer kursen med ekonomiskt stöd förutsatt att kandidaten uppfyller vissa behörighetskriterier för Coursera.
Slutligen erbjuder Alberta Machine Intelligence Institute vid University of Alberta denna kurs (ingen poäng ges). Ärade professorer inom datavetenskap kommer att fungera som dina kurslärare. Du får ett Coursera-certifikat efter avslutad kurs.
AI Reinforcement Learning i Python: Udemy
Om du är intresserad av finansmarknaden eller digital marknadsföring och vill utveckla intelligenta mjukvarupaket för nämnda områden måste du kolla in detta Udemy-kurs på RL. Förutom RL:s kärnprinciper, kommer utbildningsinnehållet också att coacha dig om hur du utvecklar RL-lösningar för onlineannonsering och aktiehandel.

Några anmärkningsvärda ämnen som kursen tar upp är:
- En översikt över RL på hög nivå
- Dynamisk programmering
- Monet Carlo
- Approximationsmetoder
- Aktiehandelsprojekt med RL
Över 42 000 studenter har deltagit i kursen hittills. Onlineinlärningsresursen har för närvarande ett betyg på 4,6 stjärnor, vilket är ganska imponerande. Dessutom syftar kursen till att tillgodose en global studentgemenskap eftersom lärandeinnehållet är tillgängligt på franska, engelska, spanska, tyska, italienska och portugisiska.
Deep Reinforcement Learning i Python: Udemy
Om du har nyfikenhet och grundläggande kunskap om djupinlärning och artificiell intelligens kan du prova denna avancerade RL-kurs i Python från Udemy. Med ett betyg på 4,6 stjärnor från studenter är det ännu en populär kurs för att lära sig RL i AI/ML-sammanhang.

Kursen har 12 avsnitt och täcker följande viktiga ämnen:
- OpenAI Gym och grundläggande RL-tekniker
- TD Lambda
- A3C
- Theanos grunder
- Grunderna i Tensorflow
- Python-kodning till att börja med
Hela kursen kommer att kräva en engagerad investering på 10 timmar och 40 minuter. Förutom texter kommer det också med 79 expertföreläsningar.
Deep Reinforcement Learning Expert: Udacity
Vill du lära dig avancerad maskininlärning från världsledande inom AI/ML som Nvidia Deep Learning Institute och Unity? Udacity låter dig uppfylla din dröm. Kolla in det här Deep Reinforcement Learning kurs för att bli ML-expert.

Du måste dock komma från en bakgrund av avancerad Python, mellanstatistik, sannolikhetsteori, TensorFlow, PyTorch och Keras.
Det kommer att ta flitigt lärande på upp till 4 månader att slutföra kursen. Under hela kursen kommer du att lära dig viktiga RL-algoritmer som Deep Deterministic Policy Gradients (DDPG), Deep Q-Networks (DQN), etc.
Slutord
Förstärkningsinlärning är nästa steg i AI-utveckling. AI-utvecklingsbyråer och IT-företag öser in investeringar i denna sektor för att skapa pålitliga och pålitliga AI-utbildningsmetoder.
Även om RL har avancerat mycket, finns det fler utvecklingsområden. Till exempel delar separata RL-agenter inte kunskap mellan sig. Därför, om du tränar en app att köra bil, kommer inlärningsprocessen att bli långsam. Eftersom RL-agenter som objektdetektering, vägreferenser etc. inte delar data.
Det finns möjligheter att investera din kreativitet och ML-expertis i sådana utmaningar. Att registrera dig för onlinekurser hjälper dig att öka dina kunskaper om avancerade RL-metoder och deras tillämpningar i verkliga projekt.
En annan relaterad inlärning för dig är skillnaderna mellan AI, Machine Learning och Deep Learning.