

Regression och klassificering är två av de mest grundläggande och betydelsefulla områdena inom maskininlärning.
Det kan vara knepigt att skilja mellan regression och klassificeringsalgoritmer när du precis ska börja med maskininlärning. Att förstå hur dessa algoritmer fungerar och när de ska användas kan vara avgörande för att göra korrekta förutsägelser och effektiva beslut.
Låt oss först se om maskininlärning.
Innehållsförteckning
Vad är maskininlärning?
Maskininlärning är en metod för att lära datorer att lära sig och fatta beslut utan att vara explicit programmerad. Det handlar om att träna en datormodell på en datauppsättning, vilket gör att modellen kan göra förutsägelser eller beslut baserat på mönster och relationer i data.
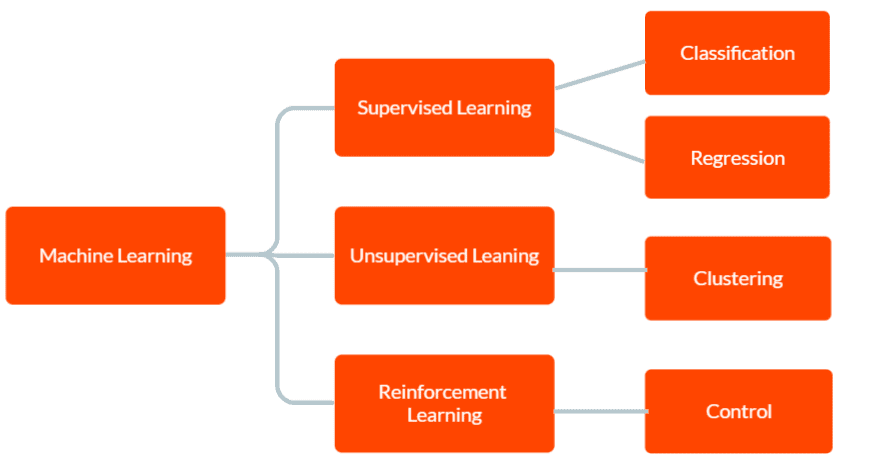
Det finns tre huvudtyper av maskininlärning: övervakad inlärning, oövervakad inlärning och förstärkningsinlärning.
I övervakat lärande förses modellen med märkt träningsdata, inklusive indata och motsvarande korrekta utdata. Målet är att modellen ska göra förutsägelser om utdata för ny, osynlig data baserat på mönstren den lärt sig från träningsdata.
I Unsupervised learning ges modellen inga märkta träningsdata. Istället lämnas det att självständigt upptäcka mönster och samband i datan. Detta kan användas för att identifiera grupper eller kluster i data eller för att hitta anomalier eller ovanliga mönster.
Och i Reinforcement Learning lär sig en agent att interagera med sin omgivning för att maximera en belöning. Det handlar om att träna en modell för att fatta beslut baserat på den feedback den får från omgivningen.
Maskininlärning används i olika applikationer, inklusive bild- och taligenkänning, naturlig språkbehandling, bedrägeriupptäckt och självkörande bilar. Det har potential att automatisera många uppgifter och förbättra beslutsfattandet i olika branscher.
Den här artikeln fokuserar huvudsakligen på klassificerings- och regressionskoncept, som faller under övervakad maskininlärning. Låt oss börja!
Klassificering i maskininlärning

Klassificering är en maskininlärningsteknik som innebär att man tränar en modell för att tilldela en klassetikett till en given ingång. Det är en övervakad inlärningsuppgift, vilket innebär att modellen tränas på en märkt dataset som innehåller exempel på indata och motsvarande klassetiketter.
Modellen syftar till att lära sig förhållandet mellan indata och klassetiketter för att förutsäga klassetiketten för ny, osynlig indata.
Det finns många olika algoritmer som kan användas för klassificering, inklusive logistisk regression, beslutsträd och stödvektormaskiner. Valet av algoritm kommer att bero på egenskaperna hos datan och modellens önskade prestanda.
Några vanliga klassificeringsprogram inkluderar skräppostdetektering, sentimentanalys och bedrägeriupptäckt. I vart och ett av dessa fall kan indata innehålla text, numeriska värden eller en kombination av båda. Klassetiketterna kan vara binära (t.ex. skräppost eller inte skräppost) eller flerklassiga (t.ex. positiva, neutrala, negativa känslor).
Tänk till exempel på en datauppsättning av kundrecensioner av en produkt. Indata kan vara texten i recensionen, och klassetiketten kan vara ett betyg (t.ex. positiv, neutral, negativ). Modellen skulle tränas på en datauppsättning av märkta recensioner och sedan skulle kunna förutsäga betyget för en ny recension som den inte hade sett tidigare.
Typer av ML-klassificeringsalgoritmer
Det finns flera typer av klassificeringsalgoritmer inom maskininlärning:
Logistisk tillbakagång
Detta är en linjär modell som används för binär klassificering. Det används för att förutsäga sannolikheten för att en viss händelse inträffar. Målet med logistisk regression är att hitta de bästa koefficienterna (vikterna) som minimerar felet mellan den förutsagda sannolikheten och det observerade utfallet.
Detta görs genom att använda en optimeringsalgoritm, såsom gradient descent, för att justera koefficienterna tills modellen passar träningsdatan så bra som möjligt.
Beslutsträd
Dessa är trädliknande modeller som fattar beslut baserat på funktionsvärden. De kan användas för både binär och multiklassklassificering. Beslutsträd har flera fördelar, inklusive deras enkelhet och interoperabilitet.
De är också snabba att träna och göra förutsägelser, och de kan hantera både numeriska och kategoriska data. De kan dock vara benägna att överanpassa, speciellt om trädet är djupt och har många grenar.
Slumpmässig skogsklassificering
Random Forest Classification är en ensemblemetod som kombinerar förutsägelser från flera beslutsträd för att göra en mer exakt och stabil förutsägelse. Det är mindre benäget att överanpassa än ett enskilt beslutsträd eftersom förutsägelserna för de enskilda träden är medelvärde, vilket minskar variansen i modellen.
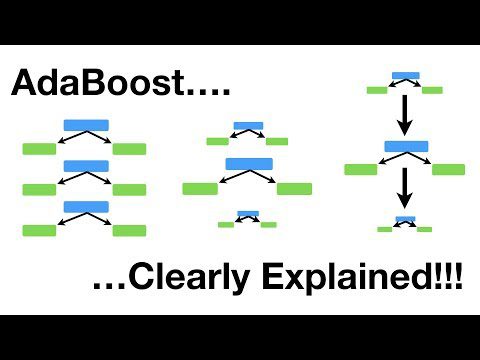
AdaBoost
Detta är en förstärkningsalgoritm som adaptivt ändrar vikten av felklassificerade exempel i träningsuppsättningen. Det används ofta för binär klassificering.
Naiva Bayes
Naiv Bayes bygger på Bayes sats, som är ett sätt att uppdatera sannolikheten för en händelse baserat på nya bevis. Det är en probabilistisk klassificering som ofta används för textklassificering och skräppostfiltrering.
K-Närmaste granne
K-Nearest Neighbors (KNN) används för klassificerings- och regressionsuppgifter. Det är en icke-parametrisk metod som klassificerar en datapunkt baserat på klassen för dess närmaste grannar. KNN har flera fördelar, bland annat dess enkelhet och att det är lätt att implementera. Den kan också hantera både numerisk och kategorisk data, och den gör inga antaganden om den underliggande datafördelningen.
Gradient Boosting
Dessa är ensembler av svaga elever som tränas sekventiellt, där varje modell försöker rätta till misstagen i den tidigare modellen. De kan användas för både klassificering och regression.
Regression i maskininlärning
Inom maskininlärning är regression en typ av övervakad inlärning där målet är att förutsäga ac-beroende variabel baserat på en eller flera indatafunktioner (även kallade prediktorer eller oberoende variabler).
Regressionsalgoritmer används för att modellera förhållandet mellan indata och utdata och göra förutsägelser baserat på det förhållandet. Regression kan användas för både kontinuerliga och kategoriskt beroende variabler.
I allmänhet är målet med regression att bygga en modell som exakt kan förutsäga utdata baserat på indatafunktionerna och att förstå det underliggande förhållandet mellan indatafunktionerna och utdata.
Regressionsanalys används inom olika områden, inklusive ekonomi, finans, marknadsföring och psykologi, för att förstå och förutsäga sambanden mellan olika variabler. Det är ett grundläggande verktyg inom dataanalys och maskininlärning och används för att göra förutsägelser, identifiera trender och förstå de underliggande mekanismerna som driver data.
Till exempel, i en enkel linjär regressionsmodell kan målet vara att förutsäga priset på ett hus baserat på dess storlek, läge och andra egenskaper. Storleken på huset och dess läge skulle vara de oberoende variablerna, och priset på huset skulle vara den beroende variabeln.
Modellen skulle tränas på indata som inkluderar storleken och placeringen av flera hus, tillsammans med deras motsvarande priser. När modellen väl är tränad kan den användas för att göra förutsägelser om priset på ett hus, givet dess storlek och läge.
Typer av ML-regressionsalgoritmer
Regressionsalgoritmer finns tillgängliga i olika former, och användningen av varje algoritm beror på antalet parametrar, såsom typen av attributvärde, trendlinjens mönster och antalet oberoende variabler. Regressionstekniker som ofta används inkluderar:
Linjär regression
Denna enkla linjära modell används för att förutsäga ett kontinuerligt värde baserat på en uppsättning funktioner. Den används för att modellera förhållandet mellan funktionerna och målvariabeln genom att anpassa en linje till data.
Polynomregression
Detta är en icke-linjär modell som används för att anpassa en kurva till data. Den används för att modellera relationer mellan funktionerna och målvariabeln när sambandet inte är linjärt. Den är baserad på idén att lägga till termer av högre ordning till den linjära modellen för att fånga icke-linjära samband mellan de beroende och oberoende variablerna.
Ridge regression
Detta är en linjär modell som adresserar överanpassning i linjär regression. Det är en regulariserad version av linjär regression som lägger till en straffterm till kostnadsfunktionen för att minska modellens komplexitet.
Stöd vektorregression
Liksom SVM är Support Vector Regression en linjär modell som försöker passa data genom att hitta hyperplanet som maximerar marginalen mellan de beroende och oberoende variablerna.
Men till skillnad från SVM, som används för klassificering, används SVR för regressionsuppgifter, där målet är att förutsäga ett kontinuerligt värde snarare än en klassetikett.
Lasso regression
Detta är en annan regulariserad linjär modell som används för att förhindra överanpassning vid linjär regression. Den lägger till en straffterm till kostnadsfunktionen baserat på koefficienternas absoluta värde.
Bayesiansk linjär regression
Bayesiansk linjär regression är ett probabilistiskt tillvägagångssätt för linjär regression baserat på Bayes teorem, vilket är ett sätt att uppdatera sannolikheten för en händelse baserat på nya bevis.
Denna regressionsmodell syftar till att uppskatta den bakre fördelningen av modellparametrarna givet data. Detta görs genom att definiera en tidigare fördelning över parametrarna och sedan använda Bayes sats för att uppdatera fördelningen baserat på de observerade data.
Regression vs. Klassificering
Regression och klassificering är två typer av övervakat lärande, vilket innebär att de används för att förutsäga en utdata baserat på en uppsättning indatafunktioner. Det finns dock några viktiga skillnader mellan de två:
RegressionClassificationDefinitionEn typ av övervakad inlärning som förutsäger ett kontinuerligt värdeEn typ av övervakad inlärning som förutsäger ett kategoriskt värdeUtgångstypContinuousDiscreteEvaluation metricsMean squared error (MSE), root mean squared error (RMSE) Noggrannhet, precision, återkallelse, F1 scoreAlgorithms,NNar, Ridge, NNar, Lasso, Regression Decision TreeLogistic regression, SVM, Naive Bayes, KNN, Decision TreeModellkomplexitetMindre komplexa modellerMer komplexa modellerAntagandenLinjärt samband mellan egenskaper och målInga specifika antaganden om förhållandet mellan egenskaper och målKlassobalansEj tillämpligtDet kan vara ett problemOutliersKan påverka modellens prestandaEj viktighetFaktatypvärdekaraktäravvikelse rankas inte efter betydelseExempelapplikationer Förutsäga priser, temperaturer, kvantiteter Förutsäga om e-postspam, förutsäga kundförlust
Lärresurser
Det kan vara utmanande att välja de bästa onlineresurserna för att förstå koncept för maskininlärning. Vi har undersökt de populära kurserna som tillhandahålls av pålitliga plattformar för att presentera våra rekommendationer för de bästa ML-kurserna om regression och klassificering.
#1. Machine Learning Classification Bootcamp i Python
Detta är en kurs som erbjuds på Udemy-plattformen. Den täcker en mängd olika klassificeringsalgoritmer och tekniker, inklusive beslutsträd och logistisk regression, och stöder vektormaskiner.

Du kan också lära dig om ämnen som överanpassning, avvägning mellan bias-varians och modellutvärdering. Kursen använder Python-bibliotek som sci-kit-learn och pandor för att implementera och utvärdera maskininlärningsmodeller. Så, grundläggande pytonkunskaper krävs för att komma igång med den här kursen.
#2. Machine Learning Regression Masterclass i Python
I den här Udemy-kursen täcker tränaren grunderna och den underliggande teorin för olika regressionsalgoritmer, inklusive linjär regression, polynomregression och Lasso & Ridge-regressionstekniker.
I slutet av den här kursen kommer du att kunna implementera regressionsalgoritmer och bedöma prestandan hos utbildade maskininlärningsmodeller med hjälp av olika nyckelprestandaindikatorer.
Avslutar
Maskininlärningsalgoritmer kan vara mycket användbara i många applikationer, och de kan hjälpa till att automatisera och effektivisera många processer. ML-algoritmer använder statistiska tekniker för att lära sig mönster i data och göra förutsägelser eller beslut baserat på dessa mönster.
De kan tränas på stora mängder data och kan användas för att utföra uppgifter som skulle vara svåra eller tidskrävande för människor att göra manuellt.
Varje ML-algoritm har sina styrkor och svagheter, och valet av algoritm beror på uppgifternas karaktär och uppgiftens krav. Det är viktigt att välja lämplig algoritm eller kombination av algoritmer för det specifika problem du försöker lösa.
Det är viktigt att välja rätt typ av algoritm för ditt problem, eftersom att använda fel typ av algoritm kan leda till dålig prestanda och felaktiga förutsägelser. Om du är osäker på vilken algoritm du ska använda kan det vara bra att prova både regressions- och klassificeringsalgoritmer och jämföra deras prestanda på din datauppsättning.
Jag hoppas att du tyckte att den här artikeln var användbar för att lära dig regression vs. klassificering i maskininlärning. Du kanske också är intresserad av att lära dig mer om de bästa maskininlärningsmodellerna.