

Om du har lärt dig några datorprogrammeringsspråk, kanske du har hört termen, att tolka text. Detta används för att förenkla de komplexa datavärdena i filen. Artikeln hjälper dig att veta hur man tolkar text med hjälp av språket. Utöver detta, om du har stött på fel i parse text x, kommer du att veta hur du fixar parse error i artikeln.

Innehållsförteckning
Hur man tolkar text
I den här artikeln har vi visat en fullständig guide för att tolka text på olika sätt och även kortfattat en introduktion till att tolka text.
Vad är att analysera text?
Innan du gräver för att lära dig begreppen att tolka text med valfri kod. Det är viktigt att känna till grunderna i språket och kodningen.
NLP eller Natural Language Processing
För att tolka text används Natural Language Processing eller NLP, som är ett underområde av artificiell intelligens-domänen. Python-språk, som är ett av de språk som tillhör kategorin används för att tolka text.
NLP-koderna gör det möjligt för datorer att förstå och bearbeta mänskliga språk för att göra dem lämpliga för olika tillämpningar. För att tillämpa ML- eller Machine Learning-tekniker på språket måste de ostrukturerade textdata konverteras till strukturerade tabelldata. För att slutföra analysaktiviteten används Python-språket för att ändra programkoderna.
Vad är att analysera text?
Att analysera text innebär helt enkelt att konvertera data från ett format till ett annat format. Formatet som filen sparas i ska tolkas eller konverteras till en fil i ett annat format för att användaren ska kunna använda den i olika applikationer.
- Processen innebär med andra ord att man analyserar strängen eller en text och konverterar till logiska komponenter genom att ändra formatet på filen.
- Vissa regler i Python-språket används för att slutföra denna vanliga programmeringsuppgift. När text tolkas bryts den givna serien av text upp i mindre komponenter.
Vilka är skälen till att tolka text?
Skälen till att texten måste tolkas ges i det här avsnittet och det är en förutsättning för kunskaper innan man vet hur man tolkar text.
- All datoriserad data kommer inte att vara i samma format och kan skilja sig åt beroende på olika applikationer.
- Dataformaten varierar för olika applikationer och en inkompatibel kod skulle leda till detta fel.
- Det finns inget individuellt universellt datorprogram för att välja data för alla dataformat.
Metod 1: Genom DataFrame Class
DataFrame-klassen i Python-språket har alla nödvändiga funktioner för att tolka text. Detta inbyggda bibliotek innehåller de nödvändiga koderna för att tolka data av vilket format som helst till ett annat format.
Kort introduktion av DataFrame Class
DataFrame Class är en funktionsrik datastruktur, som används som ett dataanalysverktyg. Detta är ett kraftfullt dataanalysverktyg som kan användas för att analysera data med minimal ansträngning.
- Koden läses in i pandas DataFrame för att utföra analysen på Python-språket.
- Klassen kommer med många paket från pandorna som används av Python-dataanalytiker.
- Funktionen i den här klassen är en abstraktion, en kod där funktionens interna funktionalitet är dold för användarna, i NumPy-biblioteket. NumPy-biblioteket är ett python-bibliotek som omfattar kommandon och funktioner för att arbeta med arrayer.
- DataFrame-klassen kan användas för att rendera en tvådimensionell array med flera rad- och kolumnindex. Dessa index hjälper till att lagra flerdimensionell data, och kallas därför MultiIndex. Dessa måste ändras för att veta hur man fixar analysfel.
Python-språkets pandor hjälper till att utföra SQL- eller databasliknande operationer med yttersta perfektion för att undvika fel i analys av text x. Den innehåller också några IO-verktyg som hjälper till att analysera filerna i CSV, MS Excel, JSON, HDF5 och andra dataformat.
Process för att analysera text med DataFrame Class
För att veta hur man tolkar text kan du använda standardprocessen med DataFrame Class som ges i det här avsnittet.
- Dechiffrera dataformatet för indata.
- Bestäm utdata för data som CSV eller kommaseparerat värde.
- Skriv på koden en primitiv datatyp som list eller dict.
Obs: Att skriva koden på en tom DataFrame kan vara tråkigt och komplicerat. Pandas tillåter att skapa data på DataFrame-klassen från dessa datatyper. Därför kan data i den primitiva datatypen enkelt tolkas till det önskade dataformatet.
- Analysera data med hjälp av dataanalysverktyget, pandas DataFrame, och skriv ut resultatet.
Alternativ I: Standardformat
Standardmetoden för att formatera en fil med ett visst dataformat som CSV förklaras här.
- Spara filen med datavärdena lokalt på din PC. Du kan till exempel namnge filen data.txt.
- Importera filen i pandor med ett specifikt namn och importera data till en annan variabel. Till exempel importeras språkets pandor till namnet pd i den angivna koden.
- Importen ska ha en komplett kod med detaljerna om namnet på indatafilen, funktionen och indatafilformatet.
Obs: Här används variabeln med namnet res för att utföra läsfunktionen för data i filen data.txt med hjälp av pandorna importerade i pd. Dataformatet för den inmatade texten anges i CSV-format.
- Anropa den namngivna filtypen och analysera den tolkade texten på det utskrivna resultatet. Till exempel kommer kommandot res efter kommandoradens körning att hjälpa till att skriva ut den tolkade texten.
En exempelkod för processen som förklaras ovan ges nedan och hjälper dig att förstå hur man tolkar text.
import pandas as pd res = pd.read_csv(‘data.txt’) res
I det här fallet, om du matar in datavärdena i filen data.txt som t.ex [1,2,3]skulle det tolkas och visas som 1 2 3.
Alternativ II: Strängmetod
Om texten som ges till koden endast innehåller strängar eller alfatecken, kan specialtecken i strängen som kommatecken, mellanslag etc. användas för att separera och tolka texten. Processen liknar de vanliga interna strängoperationerna. För att ta reda på hur man åtgärdar tolkfel måste du följa processen för att tolka texten med det här alternativet förklaras nedan.
- Data extraheras från strängen och alla specialtecken som skiljer texten noteras.
Till exempel, i koden nedan identifieras specialtecknen i strängen my_string, som är ’,’ och ’:’. Denna process måste göras noggrant för att undvika fel i tolka text x.
- Texten i strängen delas upp individuellt baserat på värdena och placeringen av specialtecknen.
Till exempel delas strängen i textdatavärden baserat på specialtecken som identifieras med kommandot split.
- Strängens datavärden skrivs ut ensamma som den analyserade texten. Här används print-satsen för att skriva ut det analyserade datavärdet för texten.
Exempelkoden för processen som förklaras ovan ges nedan.
my_string = ‘Names: Tech, computer’
sfinal = [name.strip() for name in my_string.split(‘:’)[1].split(‘,’)]
print(“Names: {}”.format(sfinal))
I det här fallet skulle resultatet av den analyserade strängen visas som visas nedan.
Names: [‘Tech’, ‘computer’]
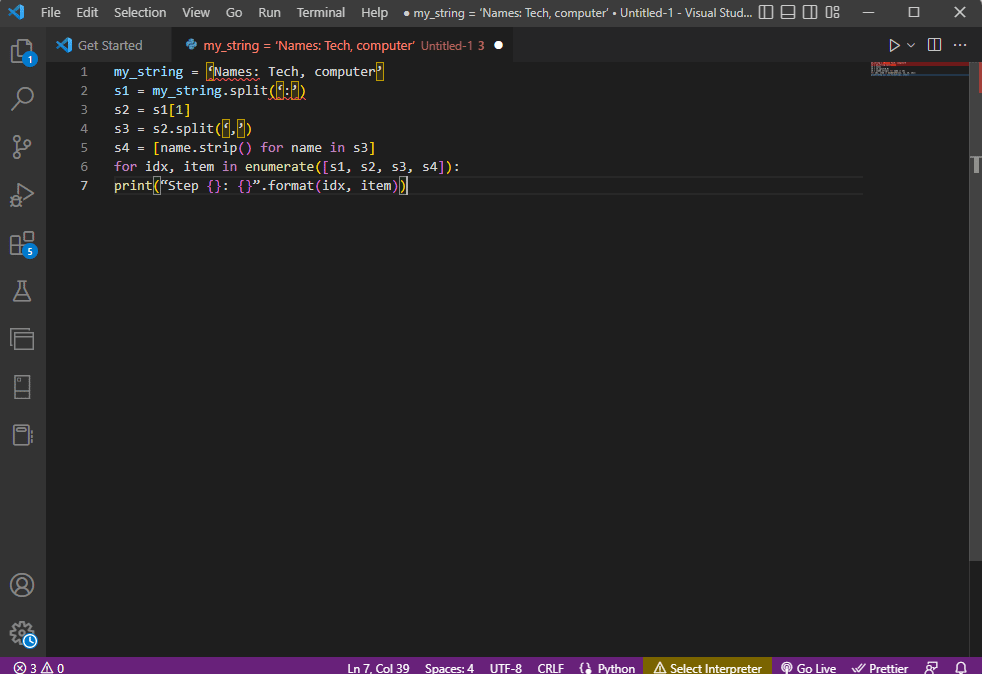
För att få bättre tydlighet och veta hur man tolkar text medan man använder strängtexten, används en for-loop och koden modifieras enligt följande.
my_string = ‘Names: Tech, computer’
s1 = my_string.split(‘:’)
s2 = s1[1]
s3 = s2.split(‘,’)
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print(“Step {}: {}”.format(idx, item))
Resultatet av den analyserade texten för vart och ett av dessa steg visas enligt nedan. Du kan notera att i steg 0 separeras strängen baserat på specialtecknet : och textdatavärdena separeras baserat på tecknet i ytterligare steg.
Step 0: [‘Names’, ‘Tech, computer’] Step 1: Tech, computer Step 2: [‘ Tech’, ‘ computer’] Step 3: [‘Tech’, ‘computer’]
Alternativ III: Parsning av komplex fil
I de flesta fall innehåller fildata som behöver analyseras olika datatyper och datavärden. I det här fallet kan det vara svårt att analysera filen med de metoder som förklarats tidigare.
Funktionerna med att analysera komplexa data i filen är att få datavärdena att visas i ett tabellformat.
- Titeln eller metadata för värdena skrivs ut överst i filen,
- Variablerna och fälten skrivs ut i utdata i tabellform, och
- Datavärdena bildar en sammansatt nyckel.
Innan du fördjupar dig i hur man tolkar text i den här metoden är det nödvändigt att lära sig några grundläggande begrepp. Analysen av datavärdena görs baserat på reguljära uttryck eller Regex.
Regex-mönster
För att veta hur man fixar analysfel måste du se till att regexmönstren i uttrycken är korrekta. Koden för att analysera datavärdena för strängarna skulle involvera de vanliga Regex-mönstren som listas nedan i det här avsnittet.
-
’d’ : matchar decimalsiffran i strängen,
-
’s’ : matchar blanktecken,
-
’w’: matchar det alfanumeriska tecknet,
-
’+’ eller ’*’: utför en girig matchning genom att matcha ett eller flera tecken i strängarna,
-
’a-z’ : matchar grupperna med små bokstäver i textdatavärdena,
-
’A-Z’ eller ’a-z’ : matchar strängens stora och gemena grupper, och
-
’0-9’ : matchar de numeriska värdena.
Vanliga uttryck
Reguljära uttrycksmoduler är en stor del av pandaspaketet i Python-språket och en felaktig re kan leda till ett fel i analystext x. Det är ett litet språk inbäddat i Python för att hitta strängmönstret i uttrycket. Regular Expressions eller Regex är strängar med speciell syntax. Det låter användaren matcha mönster i andra strängar baserat på värdena i strängarna.
Regex skapas baserat på datatypen och kravet för uttrycket i strängen, till exempel ’String = (.*)n. Regex används före mönstret i varje uttryck. Symbolerna som används i de reguljära uttrycken listas nedan och hjälper dig att veta hur man tolkar text.
-
. : för att hämta valfritt tecken från data,
-
* : använd noll eller fler data från föregående uttryck,
-
(.*) : för att gruppera en del av det reguljära uttrycket inom parentes,
-
n : Skapa ett nytt linjetecken i slutet av raden i koden,
-
d : skapa ett kort integralvärde i intervallet 0 till 9,
-
+ : använd en eller flera data från föregående uttryck, och
-
| : skapa ett logiskt uttalande; används för eller uttryck.
RegexObjects
RegexObject är ett returvärde för kompileringsfunktionen och används för att returnera ett MatchObject om uttrycket matchar matchningsvärdet.
1. MatchObject
Eftersom det booleska värdet för MatchObject alltid är True, kan du använda en if-sats för att identifiera de positiva matchningarna i objektet. I fallet med if-satsen används gruppen som refereras till av indexet för att ta reda på matchningen av objektet i uttrycket.
-
group() returnerar en eller flera undergrupper av matchning,
-
grupp(0) returnerar hela matchningen,
-
group(1) returnerar den första undergruppen med parentes, och
- Medan vi hänvisar till flera grupper bör vi använda en pythonspecifik förlängning. Detta tillägg används för att ange namnet på gruppen där matchningen ska hittas. Den specifika förlängningen tillhandahålls inom parentesgruppen. Till exempel skulle uttrycket (?P
regex1) hänvisa till den specifika gruppen med namnet group1 och leta efter matchning i det reguljära uttrycket, regex1. För att lära dig hur man fixar analysfel måste du kontrollera om gruppen pekar rätt.
2. Metoder för MatchObject
När du hittar hur man tolkar text är det viktigt att veta att MatchObject har två grundläggande metoder som listas nedan. Om MatchObject hittas i det angivna uttrycket skulle det returnera sin instans, annars skulle det returnera None.
- Match(sträng)-metoden används för att hitta matchningarna av strängen i början av det reguljära uttrycket, och
- Sök(sträng)-metoden används för att skanna igenom strängen för att hitta platsen för en matchning i det reguljära uttrycket.
Reguljära uttrycksfunktioner
Regex-funktioner är kodrader som används för att utföra en viss funktion som specificeras av användaren från uppsättningen av datavärden som skaffats.
Obs: För att skriva funktionerna används råsträngar för de reguljära uttrycken för att undvika fel i analystext x. Detta görs genom att lägga till subscript r före varje mönster i uttrycket.
De vanliga funktionerna som används i uttrycken förklaras nedan.
1. re.findall()
Denna funktion returnerar alla mönster i strängen om en matchning hittas och returnerar en tom lista om ingen matchning hittas. Till exempel, funktionen, string = re.findall(’[aeiou]’, regex_filnamn) används för att hitta vokalförekomsten i filnamnet.
2. re.split()
Den här funktionen används för att dela strängen i händelse av en matchning med ett tecken specificerat som t.ex. mellanslag. Om ingen matchning hittas returnerar den en tom sträng.
3. re.sub()
Funktionen ersätter den matchade texten med innehållet i den angivna ersätt-variabeln. I motsats till andra funktioner, om inget mönster hittas, returneras den ursprungliga strängen.
4. re.search()
En av de grundläggande funktionerna för att hjälpa till att lära sig att analysera text är sökfunktionen. Det hjälper till att söka efter mönstret i strängen och returnera matchningsobjektet. Om sökningen misslyckas med att identifiera matchningen returneras inget värde.
5. re.compile(pattern)
Denna funktion används för att kompilera reguljära uttrycksmönster till ett RegexObject, vilket diskuterades tidigare.
Andra krav
De angivna kraven är en extra funktion som används av avancerade programmerare i dataanalys.
- För att visualisera det reguljära uttrycket används regexper, och
- För att testa det reguljära uttrycket används regex101.
Processen för att analysera text
Metoden för att analysera texten i detta komplexa alternativ beskrivs enligt nedan.
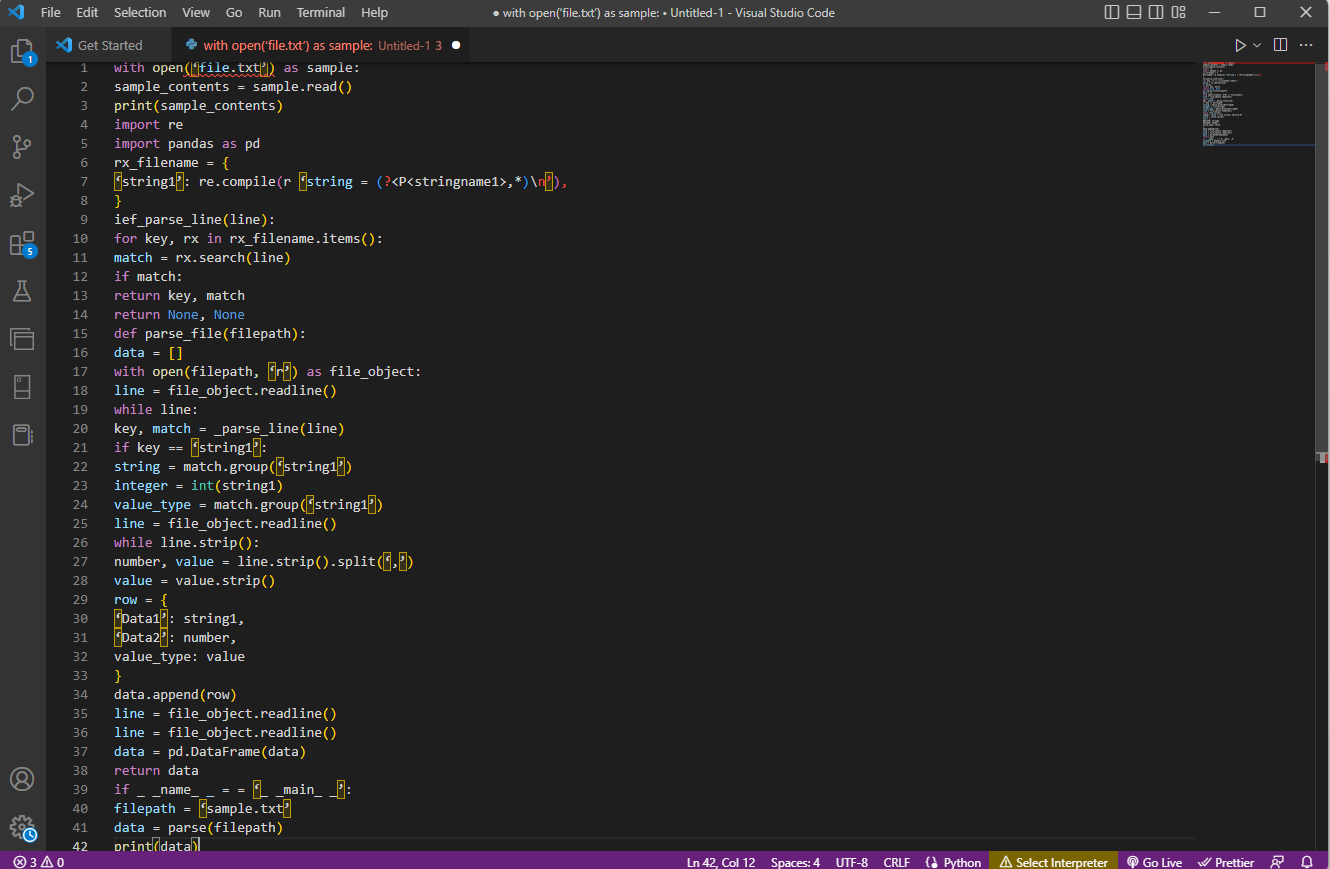
- Det främsta steget är att förstå inmatningsformatet genom att läsa innehållet i filen. Till exempel används funktionerna with open och read() för att öppna och läsa innehållet i filen med namnet sample. Exempelfilen har innehållet från filen file.txt; för att lära sig att åtgärda tolkfel måste filen läsas fullständigt.
- Innehållet i filen skrivs ut för att analysera data manuellt för att ta reda på metadata för värdena. Här används print()-funktionen för att skriva ut innehållet i exempelfilen.
- De datapaket som krävs för att tolka texten importeras till koden och ett namn ges till klassen för ytterligare kodning. Här importeras de reguljära uttrycken och pandorna.
- De reguljära uttryck som krävs för koden definieras i filen genom att inkludera regex-mönstret och regex-funktionen. Detta gör att textobjektet eller korpusen kan ta koden för dataanalys.
- För att veta hur man tolkar text kan du hänvisa till exempelkoden som ges här. Funktionen compile() används för att kompilera strängen från gruppen stringname1 i filen filnamn. Funktionen för att leta efter matchningar i regexet används av kommandot ief_parse_line(line),
- Radtolkare för koden skrivs med hjälp av def_parse_file(filepath), där den definierade funktionen kontrollerar för alla regex-matchningar i den angivna funktionen. Här söker metoden regex search() efter nyckeln rx i filens filnamn och returnerar nyckeln och matchningen för det första matchande regexet. Alla problem med steget kan leda till ett fel i analystext x.
- Nästa steg är att skriva en filtolkare med hjälp av filparserfunktionen, som är def_parse_file(filsökväg). En tom lista skapas för att samla in kodens data, som data = []matchningen kontrolleras på varje rad av matchning = _parse_line(line), och den exakta värdedatan returneras baserat på datatypen.
- För att extrahera numret och värdet för tabellen används kommandot line.strip().split(’,’). Kommandot row{} används för att skapa en ordbok med dataraden. Kommandot data.append(row) används för att förstå data och analysera dem till ett tabellformat.
Kommandot data = pd.DataFrame(data) används för att skapa en pandas DataFrame från dict-värdena. Alternativt kan du använda följande kommandon för respektive ändamål enligt nedan.
-
data.set_index([‘string’, ‘integer’]inplace=True) för att ställa in tabellens index.
-
data = data.groupby(level=data.index.names).first() för att konsolidera och ta bort nans.
-
data = data.apply(pd.to_numeric, errors=’ignore’) för att uppgradera poäng från flytande till heltalsvärde.
Det sista steget för att veta hur man analyserar text är att testa parsern med hjälp av if-satsen genom att tilldela värdena till en variabel data och skriva ut den med kommandot print(data).
Exempelkoden för förklaringen ovan ges här.
with open(‘file.txt’) as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
‘string1’: re.compile(r ‘string = (?<P<stringname1>,*)n’),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, ‘r’) as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == ‘string1’:
string = match.group(‘string1’)
integer = int(string1)
value_type = match.group(‘string1’)
line = file_object.readline()
while line.strip():
number, value = line.strip().split(‘,’)
value = value.strip()
row = {
‘Data1’: string1,
‘Data2’: number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if _ _name_ _ = = ‘_ _main_ _’:
filepath = ‘sample.txt’
data = parse(filepath)
print(data)
Metod 2: Genom Word Tokenization
Processen att konvertera en text eller korpus till tokens eller mindre bitar baserat på vissa regler kallas Tokenization. För att lära dig hur man fixar parsefel är det viktigt att analysera ordtokeniseringskommandona i koden. I likhet med regex kan egna regler skapas i den här metoden och den hjälper till vid textförbehandlingsuppgifter som att kartlägga delar av tal. Även aktiviteter som att hitta och matcha vanliga ord, rensa text och förbereda data för avancerade textanalystekniker som sentimentanalys utförs i denna metod. Om tokeniseringen är felaktig kan fel i analystext x uppstå.
Ntlk bibliotek
Processen tar hjälp av det populära språkverktygsbiblioteket nltk, som har en rik uppsättning funktioner för att utföra många NLP-jobb. Dessa kan laddas ner via Pip- eller Pip-installationspaketen. För att veta hur man tolkar text kan du använda baspaketet för Anaconda-distributionen som inkluderar biblioteket som standard.
Former av tokenisering
De vanligaste formerna av denna metod är ordtokenisering och meningstokenisering. På grund av symbolen på ordnivå skriver den förra endast ett ord en gång, medan den senare skriver ut ordet på meningsnivå.
Processen för att analysera text
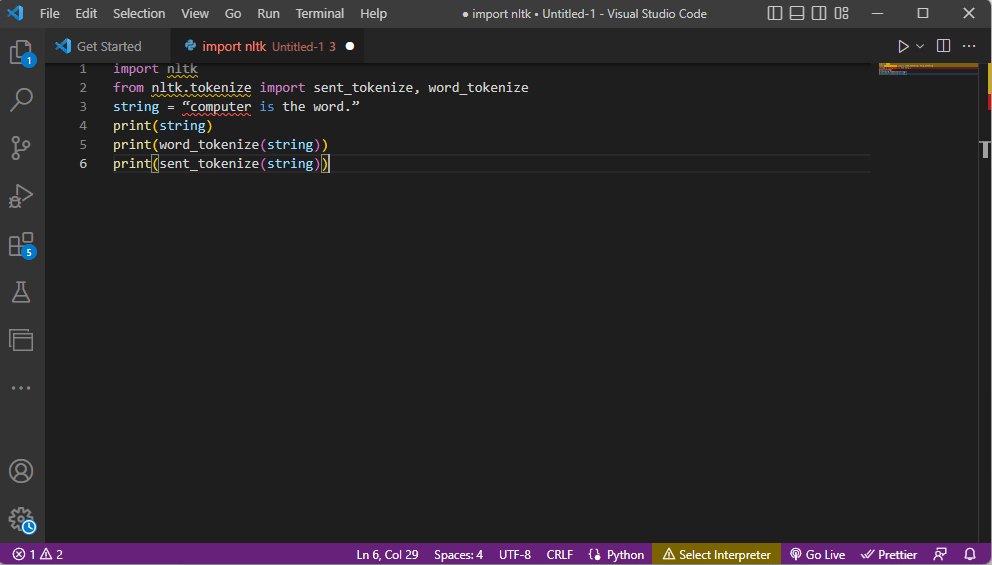
- ntlk toolkit-biblioteket importeras och tokeniseringsformulären importeras från biblioteket.
- En sträng ges och kommandona för att utföra tokeniseringen ges.
- Medan strängen skrivs ut skulle utdata vara dator är ordet.
- När det gäller ordtokenisering eller word_tokenize(), skrivs vart och ett av orden i meningen ut individuellt inom ” och separeras med ett kommatecken. Utdata för kommandot skulle vara ’dator’, ’is’, ’the’, ’word’, ’.’
- Vid meningstokenisering eller sent_tokenize() placeras de individuella meningarna inom ” och ordupprepning tillåts. Utdata för kommandot skulle vara ”dator är ordet.”
Koden som förklarar stegen för tokenisering ovan ges här.
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = “computer is the word.” print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Metod 3: Genom DocParser Class
I likhet med DataFrame Class kan Class DocParser användas för att analysera texten i koden. Klassen låter dig anropa parsefunktionen med filsökvägen.
Processen för att analysera text
För att veta hur man tolkar text med hjälp av DocParser-klassen, följ instruktionerna nedan.
- Funktionen get_format(filnamn) används för att extrahera filtillägget, returnera det till en inställd variabel för funktionen och skicka det till nästa funktion. Till exempel skulle p1 = get_format(filnamn) extrahera filtillägget för filnamn, ställa in det till variabeln p1 och skicka det till nästa funktion.
- En logisk struktur med andra funktioner konstrueras med hjälp av if-elif-else-satserna och funktionerna.
- Om filtillägget är giltigt och strukturen är logisk, används funktionen get_parser för att analysera data i filsökvägen och returnera strängobjektet till användaren.
Obs: För att veta hur man fixar analysfel måste den här funktionen implementeras korrekt.
- Analysen av datavärdena görs med filtillägget för filen. Den konkreta implementeringen av klassen, som är parse_txt eller parse_docx, används för att generera strängobjekt från delarna av den givna filtypen.
- Analysen kan göras för filer med andra läsbara tillägg som parse_pdf, parse_html och parse_pptx.
- Datavärdena och gränssnittet kan importeras till applikationer med importsatser och instansiera ett DocParser-objekt. Detta kan göras genom att analysera filer på Python-språket, till exempel parse_file.py. Denna operation måste göras noggrant för att undvika fel i analys av text x.
Metod 4: Genom att analysera textverktyg
Textverktyget Parse används för att extrahera specifik data från variabler och mappa dem till andra variabler. Detta är oberoende av alla andra verktyg som används i en uppgift och BPA-plattformsverktyget används för att konsumera och mata ut variabler. Använd länken här för att komma åt Parse Text Tool online och använd de svar som ges tidigare om hur man tolkar text.
Metod 5: Genom TextFieldParser (Visual Basic)
TextFieldParser använde objekt för att analysera och bearbeta mycket stora filer som är strukturerade och avgränsade. Bredden och kolumnen av text som loggfiler eller äldre databasinformation kan användas i den här metoden. Analysmetoden liknar att iterera koden över en textfil och används huvudsakligen för att extrahera textfält som liknar strängmanipulationsmetoder. Detta görs för att tokenisera avgränsade strängar och fält med olika bredder med hjälp av den definierade avgränsaren som kommatecken eller tabbutrymme.
Funktioner för att analysera text
Följande funktioner kan användas för att analysera texten i denna metod.
- För att definiera en avgränsare används SetDelimiters. Till exempel, kommandot testReader.SetDelimiters (vbTab) används för att ställa in tabbutrymme som avgränsare.
- För att ställa in en fältbredd till ett positivt heltalsvärde till en fast fältbredd för textfiler kan du använda kommandot testReader.SetFieldWidths (integer).
- För att testa fälttypen för texten kan du använda följande kommando testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidth.
Metoder för att hitta MatchObject
Det finns två grundläggande metoder för att hitta MatchObject i koden eller den tolkade texten.
- Den första metoden är att definiera formatet och gå igenom filen med hjälp av ReadFields-metoden. Denna metod skulle hjälpa till att bearbeta varje rad i koden.
- PeekChars-metoden används för att kontrollera varje fält individuellt innan du läser det, definiera flera format och reagera.
I båda fallen, om ett fält inte matchar det angivna formatet när man utför analysen eller hittar hur man analyserar text, returneras ett MalformedLineException-undantag.
Proffstips: Hur man analyserar text genom MS Excel
Som en sista och enkel metod för att analysera texten kan du använda MS Excel app som en parser för att skapa tabbavgränsade och kommaavgränsade filer. Detta skulle hjälpa till att korskontrollera med ditt analyserade resultat och hjälpa till att hitta hur man fixar analysfel.
1. Välj datavärdena i källfilen och tryck på Ctrl + C samtidigt för att kopiera filen.
2. Öppna Excel-appen med hjälp av sökfältet i Windows.
3. Klicka på A1-cellen och tryck på tangenterna Ctrl + V samtidigt för att klistra in den kopierade texten.
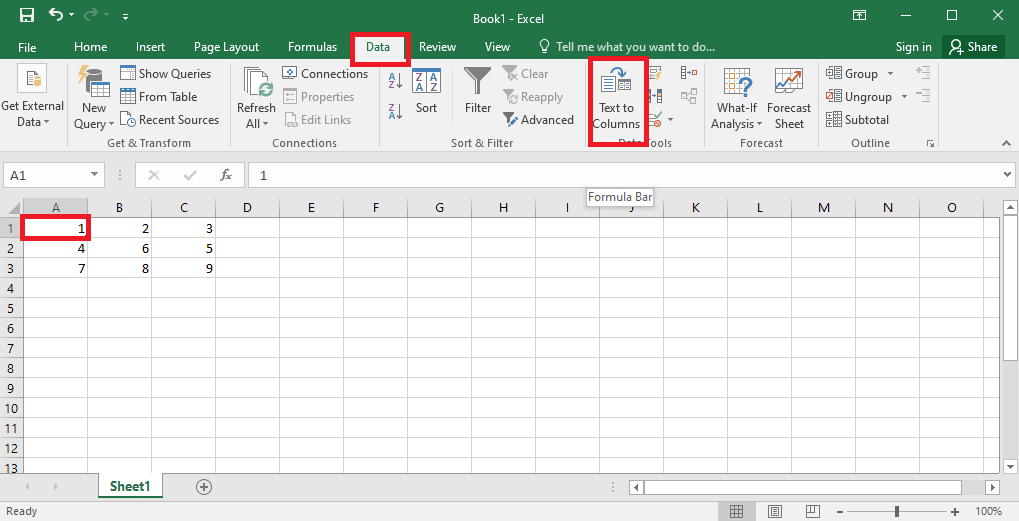
4. Välj A1-cellen, navigera till fliken Data och klicka på alternativet Text till kolumner i avsnittet Dataverktyg.
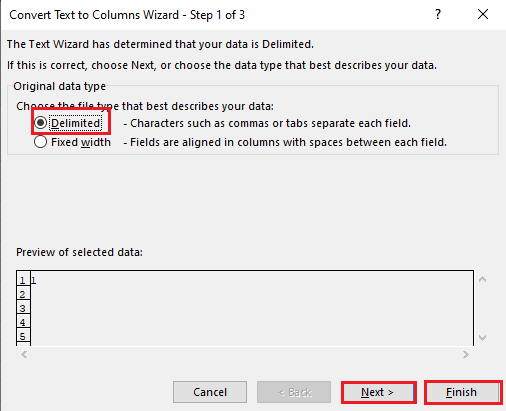
5A. Välj alternativet Avgränsat om ett kommatecken eller tabbutrymme används som avgränsare och klicka på knapparna Nästa och Slutför.
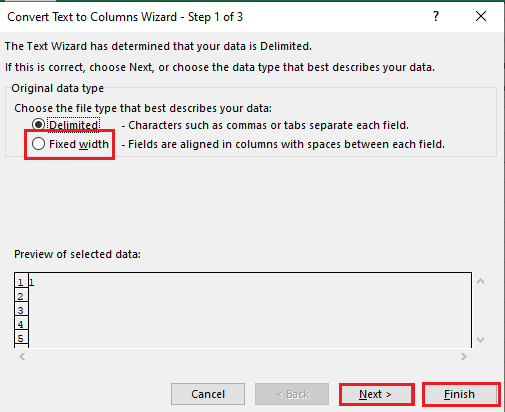
5B. Välj alternativet Fast bredd, tilldela ett värde för avgränsaren och klicka på knapparna Nästa och Slutför.
Så här åtgärdar du analysfel
Fel i analystext x kan uppstå på Android-enheter som, Parse Error: Det uppstod ett problem med att analysera paketet. Detta inträffar vanligtvis när appen inte kan installeras från Google Play Butik eller när en app från tredje part körs.
Feltexten x kan uppstå om listan med teckenvektorer är loopad och andra funktioner bildar en linjär modell för att beräkna datavärdena. Felmeddelandet är Error in parse(text = x, keep.source = FALSE):
Du kan läsa artikeln om hur du åtgärdar analysfel på Android för att lära dig orsakerna och metoderna för att åtgärda felet.
Förutom lösningarna i guiden kan du prova följande korrigeringar.
- Ladda ner .apk-filen igen eller återställa namnet på filen.
- Återställa ändringar i filen Androidmanifest.xml, om du har expertkunskaper i programmering.
***
Artikeln hjälper till att lära ut hur man tolkar text och att lära sig hur man åtgärdar tolkfel. Låt oss veta vilken metod som hjälpte till att fixa fel i analystext x och vilken analysmetod som är att föredra. Vänligen dela dina förslag och frågor i kommentarsfältet nedan.