

För år sedan, när lokala Unix-servrar med stora filsystem var en sak, byggde företag omfattande mapphanteringsregler och strategier för att administrera åtkomsträttigheter till olika mappar för olika personer.
Vanligtvis betjänar en organisations plattform olika grupper av användare med helt olika intressen, begränsningar på konfidentialitetsnivå eller innehållsdefinitioner. När det gäller globala organisationer kan detta till och med innebära att innehåll separeras baserat på plats, så i princip, mellan användare som tillhör olika länder.
Ytterligare typiska exempel kan vara:
- dataseparation mellan utvecklings-, test- och produktionsmiljöer
- försäljningsinnehåll som inte är tillgängligt för en bred publik
- landsspecifikt lagstiftningsinnehåll som inte kan ses eller nås från en annan region
- projektrelaterat innehåll där ”ledarskapsdata” endast ska lämnas till en begränsad grupp människor etc.
Det finns en potentiellt oändlig lista med sådana exempel. Poängen är att det alltid finns något slags behov av att organisera åtkomsträttigheter till filer och data mellan alla användare som plattformen ger åtkomst till.
När det gäller lösningar på plats var detta en rutinuppgift. Administratören av filsystemet satte bara upp några regler, använde ett valfritt verktyg, och sedan mappades människor till användargrupper och användargrupper mappades till en lista med mappar eller monteringspunkter som de ska kunna komma åt. Längs vägen definierades åtkomstnivån som skrivskyddad eller läs- och skrivåtkomst.
När man nu tittar på AWS molnplattformar är det uppenbart att förvänta sig att människor har liknande krav på begränsningar av innehållsåtkomst. Lösningen på detta problem måste dock vara annorlunda nu. Filer är inte längre motståndskraftiga på Unix-servrar utan i molnet (och potentiellt tillgängliga inte bara för hela organisationen utan till och med hela världen), och innehållet lagras inte i mappar utan i S3-hinkar.

Nedan beskrivs ett alternativ för att närma sig detta problem. Det är byggt på den verkliga erfarenhet jag hade när jag designade sådana lösningar för ett konkret projekt.
Innehållsförteckning
Enkelt men mycket manuellt tillvägagångssätt
Ett sätt att lösa detta problem utan någon automatisering är relativt enkelt och enkelt:
- Skapa en ny hink för varje distinkt grupp människor.
- Tilldela åtkomsträttigheter till hinken så att endast denna specifika grupp kan få åtkomst till S3-hinken.
Detta är säkert möjligt om kravet är att gå med en mycket enkel och snabb lösning. Det finns dock vissa gränser att vara medveten om.
Som standard kan endast upp till 100 S3-segment skapas under ett AWS-konto. Denna gräns kan utökas till 1000 genom att skicka in en tjänstegränshöjning till AWS-biljetten. Om dessa gränser inte är något ditt specifika implementeringsfall skulle vara orolig för, kan du låta var och en av dina distinkta domänanvändare arbeta på en separat S3-hink och kalla det en dag.
Problemen kan uppstå om det finns några grupper av människor med tvärfunktionella ansvarsområden eller helt enkelt vissa personer som behöver tillgång till innehållet på fler domäner samtidigt. Till exempel:
- Dataanalytiker utvärderar datainnehållet för flera olika områden, regioner etc.
- Testteamet delade tjänster som betjänade olika utvecklingsteam.
- Rapportera användare som behöver bygga upp instrumentpanelsanalys ovanpå olika länder inom samma region.
Som du kanske föreställer dig kan den här listan återigen växa så mycket du kan föreställa dig, och organisationers behov kan generera alla typer av användningsfall.
Ju mer komplex denna lista blir, desto mer komplex åtkomsträttighetsorkestrering kommer att behövas för att ge alla dessa olika grupper olika åtkomsträttigheter till olika S3-segment i organisationen. Det kommer att krävas ytterligare verktyg, och kanske till och med en dedikerad resurs (administratör) kommer att behöva underhålla åtkomsträttighetslistorna och uppdatera dem närhelst någon ändring efterfrågas (vilket kommer att vara väldigt ofta, särskilt om organisationen är stor).
Så hur kan man uppnå samma sak på ett mer organiserat och automatiserat sätt?
Om tillvägagångssättet för hink-per-domän inte fungerar, kommer alla andra lösningar att sluta med delade hinkar för fler användargrupper. I sådana fall är det nödvändigt att bygga hela logiken för att tilldela åtkomsträttigheter i något område som är lätt att ändra eller uppdatera dynamiskt.
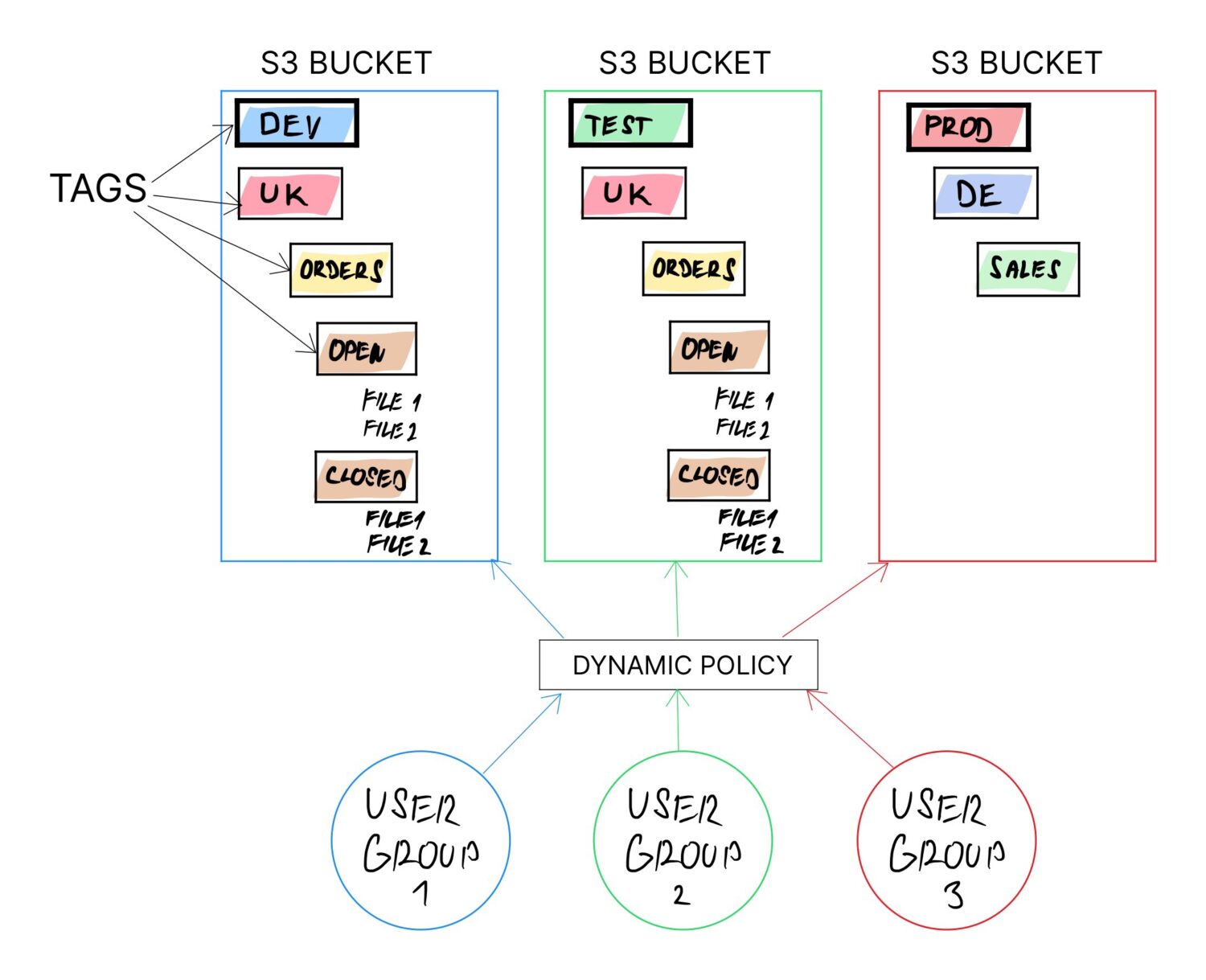
Ett av sätten att uppnå det är genom att använda Tags på S3-hinkarna. Taggarna rekommenderas att användas i alla fall (om inte för något annat än för att möjliggöra enklare faktureringskategorisering). Taggen kan dock ändras när som helst i framtiden för vilken hink som helst.
Om hela logiken är byggd utifrån bucket-taggarna och resten bakom är konfigurationsberoende på taggvärdena, säkerställs den dynamiska egenskapen eftersom man kan omdefiniera syftet med hinken bara genom att uppdatera taggvärdena.
Vilken typ av taggar ska man använda för att få detta att fungera?
Detta beror på ditt konkreta användningsfall. Till exempel:
- Det kan behövas att separera hinkar per miljötyp. Så i så fall ska ett av taggnamnen vara något som ”ENV” och med möjliga värden ”DEV”, ”TEST”, ”PROD”, etc.
- Kanske vill du separera laget utifrån landet. I så fall kommer en annan tagg att vara ”COUNTRY” och värdera något landsnamn.
- Eller så kanske du vill separera användarna baserat på den funktionella avdelning de tillhör, som affärsanalytiker, datalageranvändare, datavetare, etc. Så du skapar en tagg med namnet ”USER_TYPE” och respektive värde.
- Ett annat alternativ kan vara att du uttryckligen vill definiera en fast mappstruktur för specifika användargrupper som de är skyldiga att använda (för att inte skapa sin egen röran av mappar och gå vilse där med tiden). Du kan göra det igen med taggar, där du kan specificera flera arbetskataloger som: ”data/import”, ”data/bearbetad”, ”data/fel”, etc.
Helst vill du definiera taggarna så att de kan kombineras logiskt och få dem att bilda en hel mappstruktur på hinken.
Till exempel kan du kombinera följande taggar från exemplen ovan för att konstruera en dedikerad mappstruktur för olika typer av användare från olika länder med fördefinierade importmappar som de förväntas använda:
- /
/ / /
Bara genom att ändra
Detta kommer att möjliggöra användningen av samma hink för många olika användare. Buckets stöder inte mappar uttryckligen, men de stöder ”etiketter”. Dessa etiketter fungerar som undermappar i slutändan eftersom användarna måste gå igenom en serie etiketter för att nå sina data (precis som de skulle göra med undermappar).
Efter att ha definierat taggarna i någon användbar form är nästa steg att bygga S3-segmentpolicyer som skulle använda taggarna.
Om policyerna använder taggnamnen skapar du något som kallas ”dynamiska policyer”. Detta betyder i princip att din policy kommer att bete sig annorlunda för segment med olika taggvärden som policyn hänvisar till i form eller platshållare.
Det här steget involverar uppenbarligen lite anpassad kodning av de dynamiska policyerna, men du kan förenkla detta steg med hjälp av Amazon AWS policyredigeringsverktyg, som guidar dig genom processen.
I själva policyn kommer du att vilja koda konkreta åtkomsträttigheter som ska tillämpas på hinken och åtkomstnivån för sådana rättigheter (läsa, skriva). Logiken läser taggarna på hinkarna och bygger upp mappstrukturen på hinken (skapar etiketter baserat på taggarna). Baserat på taggarnas konkreta värden kommer undermapparna att skapas och nödvändiga åtkomsträttigheter kommer att tilldelas längs linjen.
Det fina med en sådan dynamisk policy är att du bara kan skapa en dynamisk policy och sedan tilldela samma dynamiska policy till många segment. Den här policyn kommer att fungera annorlunda för segment med olika taggvärden, men den kommer alltid att stämma överens med dina förväntningar på en hink med sådana taggvärden.
Det är ett riktigt effektivt sätt att hantera tilldelningar av åtkomsträttigheter på ett organiserat, centraliserat sätt för ett stort antal hinkar, där det är förväntningen att varje hink kommer att följa några mallstrukturer som är överenskomna i förväg och kommer att användas av dina användare inom hela organisationen.
Automatisera introduktionen av nya enheter
Efter att ha definierat dynamiska policyer och tilldelat dem till befintliga hinkar, kan användarna börja använda samma buckets utan risk att användare från olika grupper inte kommer åt innehåll (lagrat i samma bucket) som finns under en mappstruktur där de inte har tillgång.
För vissa användargrupper med bredare åtkomst kommer det också att vara lätt att nå ut efter data eftersom allt kommer att lagras i samma hink.
Det sista steget är att göra introduktionen av nya användare, nya hinkar och till och med nya taggar så enkelt som möjligt. Detta ledde till en annan anpassad kodning, som dock inte behöver vara alltför komplex, förutsatt att din introduktionsprocess har några mycket tydliga regler som kan kapslas in med enkel, okomplicerad algoritmlogik (åtminstone kan du bevisa på detta sätt att din processen har viss logik och den görs inte på ett alltför kaotiskt sätt).
Detta kan vara så enkelt som att skapa ett skript körbart med AWS CLI-kommando med parametrar som behövs för att framgångsrikt integrera en ny enhet i plattformen. Det kan till och med vara en serie CLI-skript, körbara i någon specifik ordning, som till exempel:
- create_new_bucket(
, , , , ..) - create_new_tag(
, , ) - update_existing_tag(
, , ) - create_user_group(
, , ) - etc.
Du förstår poängen. 😃
Ett proffstips 👨💻
Det finns ett Pro Tips om du vill, som enkelt kan appliceras ovanpå ovanstående.
De dynamiska policyerna kan utnyttjas inte bara för att tilldela åtkomsträttigheter för mappplatser utan också för att tilldela tjänsträttigheter för buckets och användargrupper automatiskt!
Allt som skulle behövas är att utöka listan med taggar på buckets och sedan lägga till dynamiska policyåtkomsträttigheter för att använda specifika tjänster för konkreta grupper av användare.
Till exempel kan det finnas någon grupp användare som också behöver åtkomst till den specifika databasklusterservern. Detta kan utan tvekan uppnås genom dynamiska policyer som utnyttjar bucket-uppgifter, mer så om åtkomsterna till tjänsterna drivs av ett rollbaserat tillvägagångssätt. Lägg bara till en del till den dynamiska policykoden som kommer att bearbeta taggar angående databasklusterspecifikationen och tilldela policyåtkomstbehörigheterna till just det DB-klustret och användargruppen direkt.
På detta sätt kommer introduktionen av en ny användargrupp att kunna köras bara med denna enda dynamiska policy. Dessutom, eftersom den är dynamisk, kan samma policy återanvändas för onboarding av många olika användargrupper (förväntas följa samma mall men inte nödvändigtvis samma tjänster).
Du kan också ta en titt på dessa AWS S3-kommandon för att hantera hinkar och data.