Scikit-LLM är ett kraftfullt Python-bibliotek som underlättar integrationen av stora språkmodeller (LLM) i scikit-learn-ekosystemet. Det är specialiserat på att utföra sofistikerade textanalysuppgifter. För de som redan är bekanta med scikit-learn, blir inlärningskurvan för Scikit-LLM mycket smidig.
Det är värt att betona att Scikit-LLM inte är en direkt ersättning för scikit-learn. Scikit-learn är ett allmänt bibliotek för maskininlärning, medan Scikit-LLM är specifikt skräddarsytt för textanalys.
Introduktion till Scikit-LLM
För att komma igång med Scikit-LLM, behöver du först installera biblioteket och konfigurera din API-nyckel. Börja med att skapa en ny virtuell miljö i din IDE. Det här steget förhindrar potentiella konflikter mellan olika biblioteksversioner. Därefter kör du följande kommando i terminalen:
pip install scikit-llm
Det här kommandot installerar Scikit-LLM samt alla dess nödvändiga beroenden.
För att konfigurera din API-nyckel behöver du skaffa en från din valda LLM-leverantör. Om du använder OpenAI, följ dessa steg:
Navigera till OpenAI API-sidan. Klicka på din profil i det övre högra hörnet och välj ”Visa API-nycklar”. Det tar dig till en sida för hantering av API-nycklar.
På sidan för API-nycklar, klicka på knappen ”Skapa ny hemlig nyckel”.
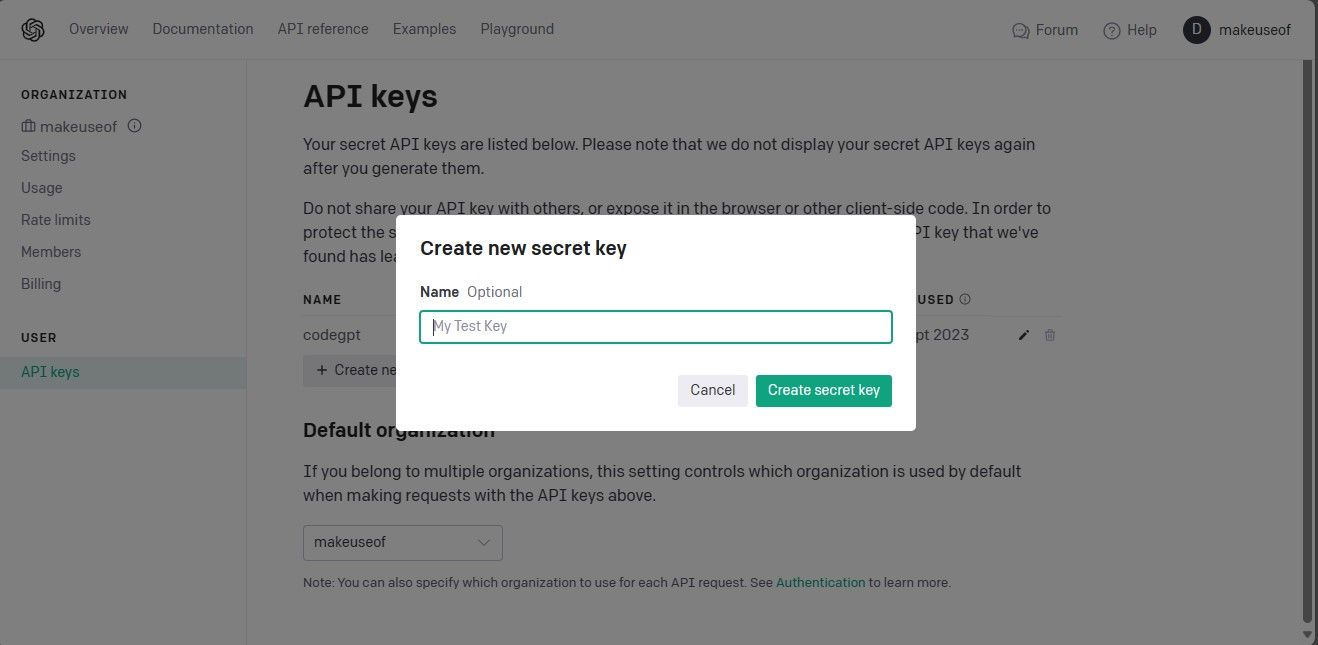
Ge din API-nyckel ett namn och klicka på ”Skapa hemlig nyckel”. Kom ihåg att kopiera nyckeln och förvara den säkert, eftersom OpenAI inte visar den igen. Om du tappar bort nyckeln, behöver du generera en ny.
Nu när du har din API-nyckel, öppna din IDE och importera klassen `SKLLMConfig` från Scikit-LLM-biblioteket. Den här klassen låter dig konfigurera inställningar för användningen av stora språkmodeller.
from skllm.config import SKLLMConfig
Den här klassen kräver att du anger din OpenAI API-nyckel och organisationsinformation.
SKLLMConfig.set_openai_key("Din API-nyckel")
SKLLMConfig.set_openai_org("Ditt organisations-ID")
Observera att organisations-ID och organisationsnamn inte är samma sak. Organisations-ID är en unik identifierare för din organisation. Du hittar ditt organisations-ID genom att gå till OpenAI:s inställningssida för organisationer och kopiera det därifrån. Nu har du upprättat en koppling mellan Scikit-LLM och den stora språkmodellen.
Scikit-LLM kräver att du har en betalningsplan (pay-as-you-go) aktiverad. Detta beror på att den kostnadsfria provversionen av OpenAI har en hastighetsbegränsning på tre förfrågningar per minut, vilket inte är tillräckligt för Scikit-LLM.
Att använda det kostnadsfria testkontot resulterar i felmeddelanden liknande det nedan när du utför textanalys:

För mer information om hastighetsbegränsningar, se OpenAI:s sida för hastighetsbegränsningar.
Du är inte begränsad till att bara använda OpenAI som LLM-leverantör. Du kan även använda andra LLM-leverantörer.
Importera nödvändiga bibliotek och ladda datamängden
Börja med att importera pandas för att hantera datamängden. Importera också de nödvändiga klasserna från Scikit-LLM och scikit-learn.
import pandas as pd from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier from skllm.preprocessing import GPTSummarizer from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.preprocessing import MultiLabelBinarizer
Ladda nu in den datamängd som du vill använda för textanalys. I det här exemplet används en IMDB-filmdatauppsättning. Du kan naturligtvis anpassa koden för att använda din egen datamängd.
data = pd.read_csv("imdb_movies_dataset.csv")
data = data.head(100)
Att begränsa sig till de första 100 raderna av datamängden är inte nödvändigt. Du kan använda hela datamängden om du vill.
Extrahera därefter funktionerna och etikettkolumnerna. Dela sedan upp datamängden i tränings- och testset.
X = data['Description'] y = data['Genre'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Kolumnen ’Genre’ innehåller de etiketter som du vill förutsäga.
Noll-skotts textklassificering med Scikit-LLM
Noll-skotts textklassificering är en avancerad funktion som erbjuds av stora språkmodeller. Den klassificerar text i fördefinierade kategorier utan behov av explicit träning på märkta data. Den här funktionen är extremt användbar när du behöver klassificera text i kategorier som inte förutsågs under modellutbildningen.
För att utföra noll-skotts textklassificering med Scikit-LLM, använder du klassen `ZeroShotGPTClassifier`.
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
print("Noll-skotts textklassificeringsrapport:")
print(classification_report(y_test, zero_shot_predictions))
Resultatet ser ut ungefär så här:
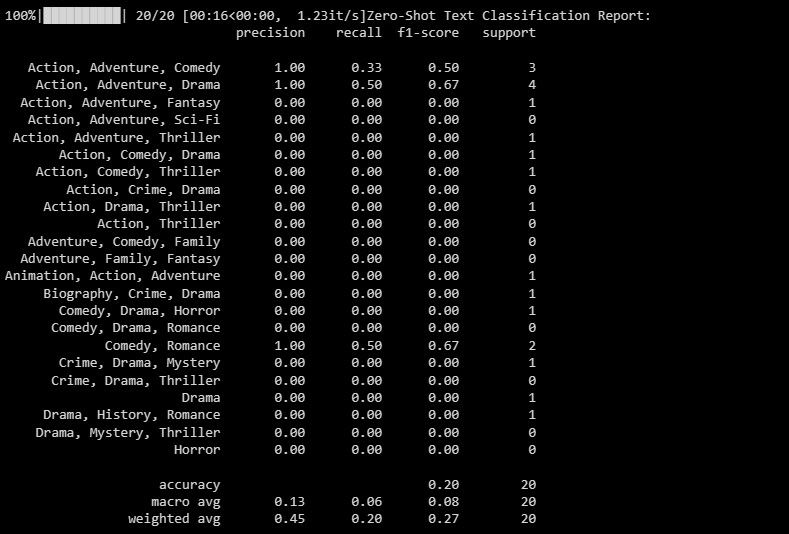
Klassificeringsrapporten ger värden för varje etikett som modellen har försökt att förutsäga.
Fleretiketts noll-skotts textklassificering med Scikit-LLM
I vissa fall kan en text tillhöra flera kategorier samtidigt. Traditionella klassificeringsmodeller har svårt med detta. Scikit-LLM däremot gör denna typ av klassificering möjlig. Fleretiketts textklassificering är viktig för att tilldela flera beskrivande etiketter till ett enda textprov.
Använd klassen `MultiLabelZeroShotGPTClassifier` för att förutsäga vilka etiketter som är lämpliga för varje textprov.
candidate_labels = ["Action", "Comedy", "Drama", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
print("Fleretiketts noll-skotts textklassificeringsrapport:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))
I koden ovan definierar du vilka etiketter som texten kan tillhöra.
Utdata kan se ut som nedan:
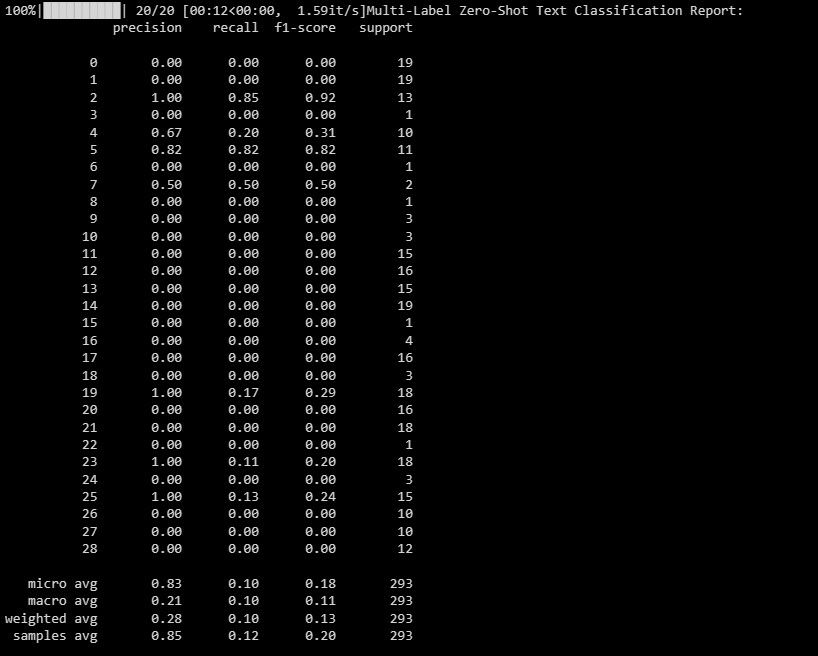
Den här rapporten ger information om hur väl modellen presterar för varje etikett i fleretikettsklassificeringen.
Textvektorisering med Scikit-LLM
Textvektorisering innebär att textdata konverteras till ett numeriskt format som maskininlärningsmodeller kan bearbeta. Scikit-LLM tillhandahåller `GPTVectorizer` för detta ändamål. Med hjälp av GPT-modeller kan text omvandlas till vektorer med fast dimension.
Detta kan åstadkommas med hjälp av termfrekvens-invers dokumentfrekvens (TF-IDF).
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
print("TF-IDF vektoriserade funktioner (första 5 exemplen):")
print(X_train_tfidf[:5])
Utdata ser ut ungefär så här:
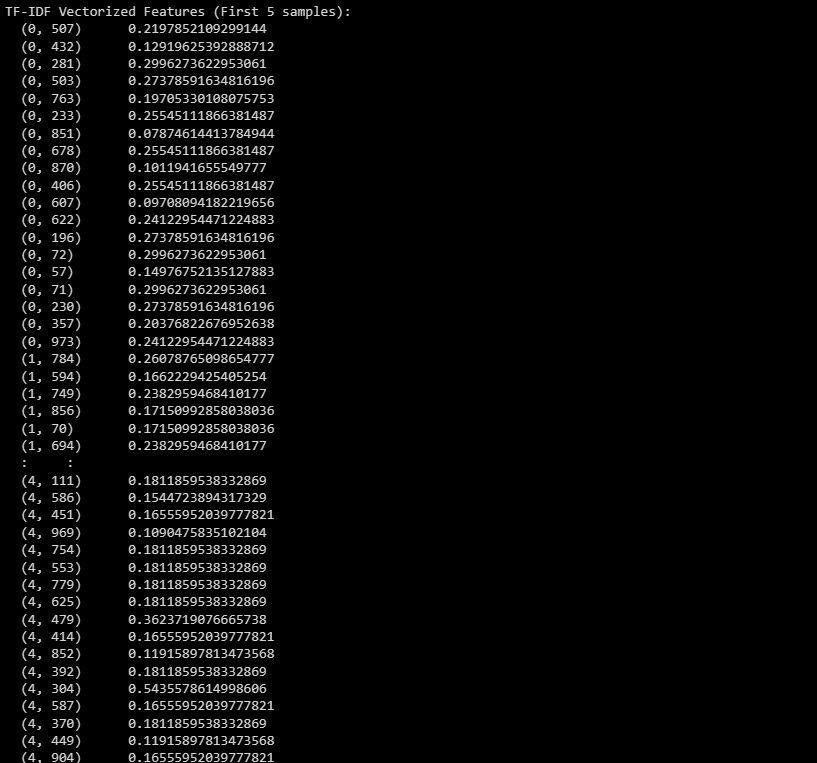
Utdata representerar de TF-IDF vektoriserade funktionerna för de första 5 exemplen i datamängden.
Textsammanfattning med Scikit-LLM
Textsammanfattning används för att komprimera en text samtidigt som den viktigaste informationen bevaras. Scikit-LLM tillhandahåller klassen `GPTSummarizer`, som använder GPT-modeller för att generera korta sammanfattningar av text.
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15) summaries = summarizer.fit_transform(X_test) print(summaries)
Utdata ser ut ungefär så här:
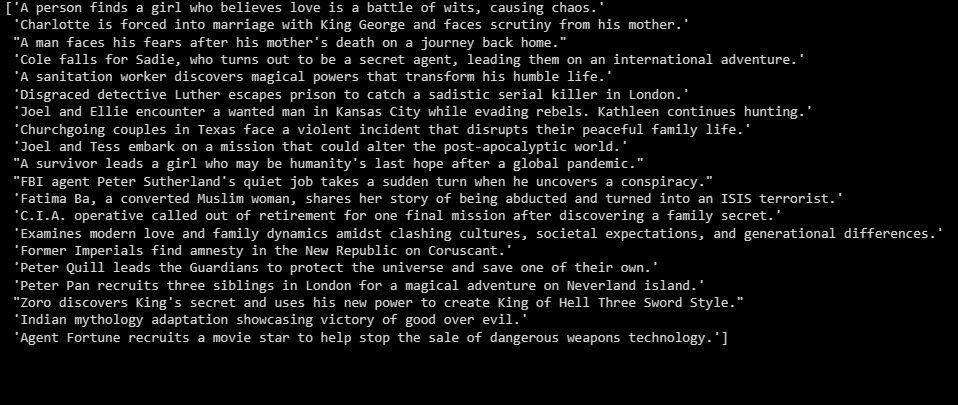
Ovanstående är en sammanfattning av testdatan.
Utveckla applikationer baserade på LLM
Scikit-LLM öppnar upp en mängd möjligheter för textanalys med stora språkmodeller. Att förstå tekniken bakom dessa modeller är grundläggande. Det hjälper dig att förstå deras styrkor och svagheter, vilket i sin tur hjälper dig att bygga effektiva applikationer baserade på denna banbrytande teknik.