Viktiga punkter
- Samtidighet och parallellism är centrala koncept inom datoranvändning, men med distinkta skillnader.
- Samtidighet optimerar resursanvändning och förbättrar applikationers reaktionsförmåga, medan parallellism är avgörande för prestanda och skalbarhet.
- Python erbjuder flera metoder för att hantera samtidighet, såsom trådar och asynkron programmering via asyncio, samt parallellitet med multiprocessormodulen.
Att hantera flera operationer samtidigt kan göras med hjälp av samtidighet och parallellism. Python erbjuder olika verktyg för att hantera dessa begrepp, vilket ibland kan leda till förvirring.
Låt oss utforska de verktyg och bibliotek som finns tillgängliga för att på ett korrekt sätt implementera samtidighet och parallellism i Python, och hur dessa skiljer sig åt.
Att förstå samtidighet och parallellism
Samtidighet och parallellism är två grundläggande principer inom datoranvändning, men med tydliga skillnader.
- Samtidighet handlar om ett programs förmåga att hantera flera uppgifter samtidigt utan att nödvändigtvis utföra dem exakt samtidigt. Det innebär att man väver samman uppgifter genom att växla mellan dem, vilket ger illusionen av att de sker samtidigt.
- Parallellism, å andra sidan, innebär att flera uppgifter verkligen utförs samtidigt. Detta utnyttjar vanligtvis flera CPU-kärnor eller processorer, vilket möjliggör en genuin samtidig exekvering och snabbare bearbetning, särskilt för beräkningsintensiva uppgifter.

Betydelsen av samtidighet och parallellism
Behovet av samtidighet och parallellism inom databehandling är betydande. Här är anledningarna till varför dessa tekniker är viktiga:
- Resursutnyttjande: Samtidighet möjliggör effektivare resursutnyttjande, vilket säkerställer att uppgifter gör framsteg istället för att vänta på externa resurser.
- Reaktionsförmåga: Samtidighet förbättrar applikationers reaktionsförmåga, speciellt i scenarier med användargränssnitt eller webbservrar.
- Prestanda: Parallellism är avgörande för optimal prestanda, speciellt vid CPU-intensiva uppgifter som komplexa beräkningar, databearbetning och simuleringar.
- Skalbarhet: Både samtidighet och parallellism är avgörande för att utveckla skalbara system.
- Framtidssäkring: I takt med att hårdvaran fortsätter att utvecklas mot flerkärniga processorer blir förmågan att utnyttja parallellism allt viktigare.
Samtidighet i Python
I Python kan samtidighet uppnås genom att använda trådar och asynkron programmering med hjälp av `asyncio`-biblioteket.
Trådar i Python
Trådar är en mekanism i Python som möjliggör att man skapar och hanterar uppgifter inom en och samma process. Trådar passar bra för vissa uppgifter, särskilt de som är I/O-bundna och kan dra nytta av samtidig körning.
Pythons trådningsmodul erbjuder ett användarvänligt gränssnitt för att skapa och hantera trådar. Även om GIL (Global Interpreter Lock) begränsar trådar när det gäller sann parallellitet, kan de ändå uppnå samtidighet genom att effektivt varva uppgifter.
Följande kodexempel illustrerar hur man implementerar samtidighet med hjälp av trådar. Den använder Python-biblioteket `requests` för att skicka en HTTP-förfrågan, en typisk I/O-blockerande uppgift. Dessutom används modulen `time` för att beräkna exekveringstiden.
import requests
import time
import threading
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
def download_url(url):
response = requests.get(url)
print(f"Nedladdat {url} - Statuskod: {response.status_code}")
start_time = time.time()
for url in urls:
download_url(url)
end_time = time.time()
print(f"Sekventiell nedladdning tog {end_time - start_time:.2f} sekunder\n")
start_time = time.time()
threads = []
for url in urls:
thread = threading.Thread(target=download_url, args=(url,))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
end_time = time.time()
print(f"Trådad nedladdning tog {end_time - start_time:.2f} sekunder")
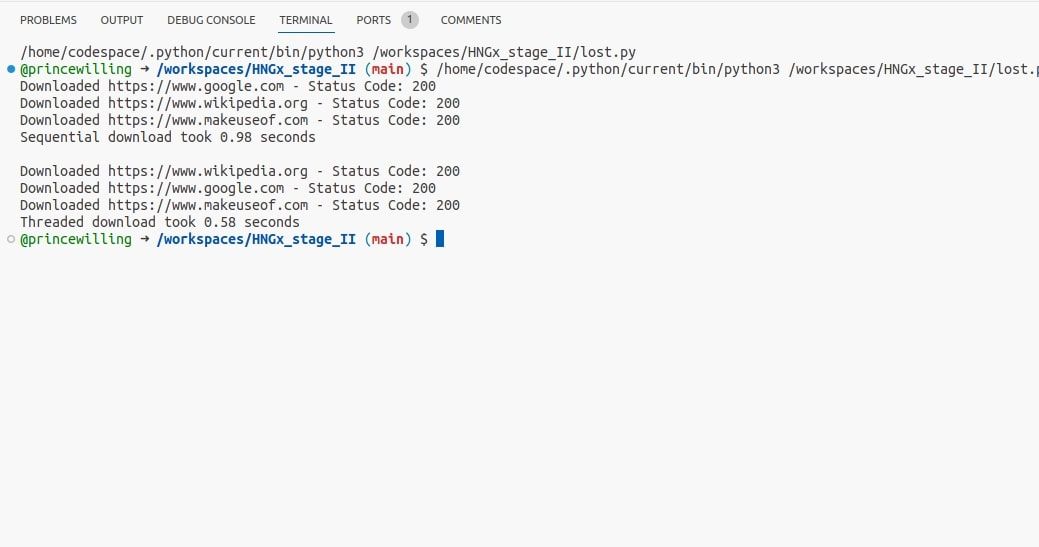
Genom att köra programmet kan man se hur mycket snabbare de trådade förfrågningarna är jämfört med de sekventiella. Även om skillnaden endast är en bråkdels sekund, ger det en klar bild av hur trådar kan förbättra prestandan för I/O-bundna uppgifter.
Asynkron programmering med Asyncio
`asyncio` tillhandahåller en händelseloop som hanterar asynkrona uppgifter, så kallade korutiner. Korutiner är funktioner som kan pausas och återupptas, vilket gör dem idealiska för I/O-bundna uppgifter. Biblioteket är särskilt användbart i situationer där uppgifter innefattar att vänta på externa resurser, såsom nätverksförfrågningar.
Vi kan modifiera det tidigare exemplet med förfrågningar för att använda `asyncio` istället:
import asyncio
import aiohttp
import time
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
async def download_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
content = await response.text()
print(f"Nedladdat {url} - Statuskod: {response.status}")
async def main():
tasks = [download_url(url) for url in urls]
await asyncio.gather(*tasks)
start_time = time.time()
asyncio.run(main())
end_time = time.time()
print(f"Asyncio-nedladdning tog {end_time - start_time:.2f} sekunder")
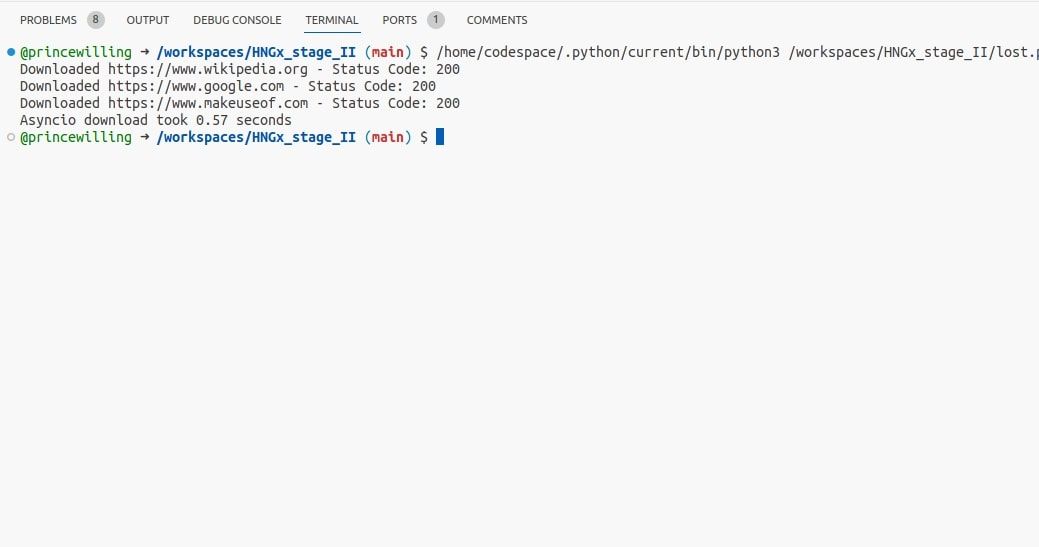
Genom att använda den här koden kan webbsidor laddas ner samtidigt med hjälp av `asyncio`, vilket utnyttjar fördelarna med asynkrona I/O-operationer. Detta kan vara mer effektivt än trådar för I/O-bundna uppgifter.
Parallellism i Python
Parallellism kan implementeras med hjälp av Pythons `multiprocessing`-modul, som gör det möjligt att fullt utnyttja flerkärniga processorer.
Multiprocessing i Python
Pythons `multiprocessing`-modul tillhandahåller ett sätt att uppnå parallellism genom att skapa separata processer, var och en med sin egen Python-tolk och minnesutrymme. Detta går effektivt förbi Global Interpreter Lock (GIL), vilket gör det lämpligt för CPU-bundna uppgifter.
import requests
import multiprocessing
import time
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
def download_url(url):
response = requests.get(url)
print(f"Nedladdat {url} - Statuskod: {response.status_code}")
def main():
num_processes = len(urls)
pool = multiprocessing.Pool(processes=num_processes)
start_time = time.time()
pool.map(download_url, urls)
end_time = time.time()
pool.close()
pool.join()
print(f"Multiprocessing-nedladdning tog {end_time-start_time:.2f} sekunder")
main()
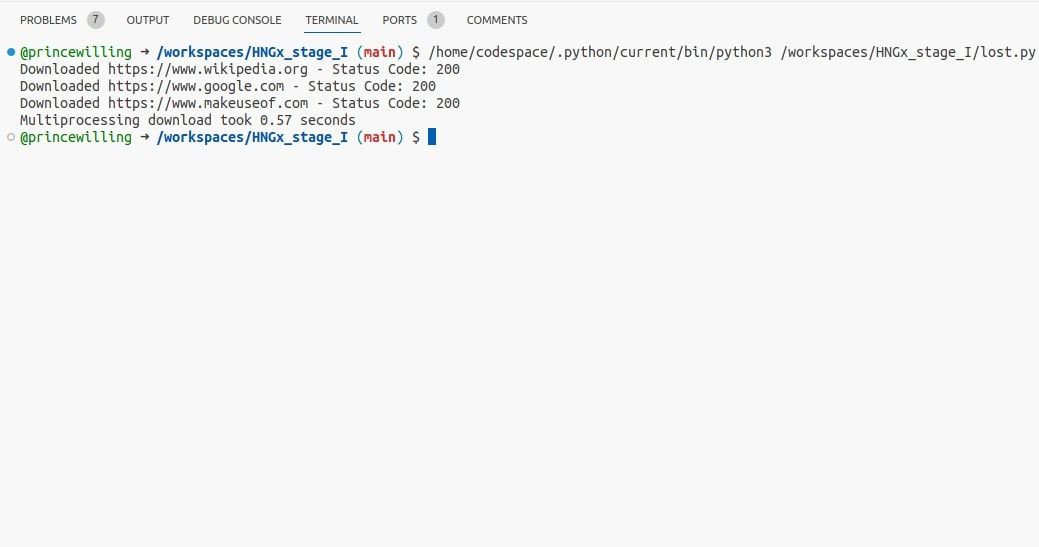
I detta exempel skapar `multiprocessing` flera processer, vilket gör att `download_url`-funktionen kan köras parallellt.
När ska man använda samtidighet eller parallellism
Valet mellan samtidighet och parallellism beror på typen av uppgifter och de tillgängliga hårdvaruresurserna.
Samtidighet är lämpligt att använda vid hantering av I/O-bundna uppgifter, såsom läsning och skrivning till filer eller att göra nätverksförfrågningar, samt när minnesbegränsningar är ett problem.
Multiprocessing bör användas för CPU-bundna uppgifter som kan dra nytta av sann parallellitet, och när det finns behov av robust isolering mellan uppgifter där en uppgifts misslyckande inte ska påverka andra.
Dra nytta av samtidighet och parallellism
Parallellism och samtidighet är effektiva sätt att förbättra svarstider och prestanda i Python-kod. Det är viktigt att förstå skillnaderna mellan dessa koncept och välja den mest effektiva strategin.
Oavsett om du arbetar med CPU-bundna eller I/O-bundna processer erbjuder Python de verktyg och moduler som behövs för att göra din kod mer effektiv genom antingen samtidighet eller parallellism.