

En katastrofåterställningsplan är en främsta åtgärd som en organisation måste ha innan en ovanlig händelse drabbar dem.
Inom IT-branschen börjar det med att skapa ett formellt dokument som innehåller planer, åtgärder och procedurer för att hantera katastrofen och dess efterverkningar.
Katastrof är en händelse som kommer plötsligt utan förvarning och kan vara av olika slag. Och när det landar möter individer och organisationer svårigheter av många slag, inklusive ekonomiska frågor och användarupplevelse.
Om en attack inträffar måste du vara redo att minimera dess effekter och återställa din verksamhet snabbare. Det är här att förbereda en praktisk katastrofåterställningsplan hjälper dig att undanhålla eller förhindra katastrofen. Du kan också minska dess efterverkningar när det gäller användarupplevelse, kostnad och stilleståndstid.
Dessutom måste du hålla dina planer, människor, strategier, utrustning och system redo för att få allt att fungera igen. Men för detta måste du förstå katastrofåterställning på djupet.
I den här artikeln kommer jag att diskutera detta i detalj tillsammans med viktiga terminologier för katastrofåterställning så att du kan slå tillbaka modigt och komma ut starkare under sådana ogynnsamma förhållanden.
Låt oss börja!
Innehållsförteckning
Vad är en katastrof?
En katastrof är en oförutsedd händelse som kan inträffa var som helst, inklusive IT-branschen. Det uppstår antingen naturligt eller av människor och kan störa ett företags verksamhet och störa strukturen i infrastrukturen.
Som ett resultat påverkas en organisation och dess kunder, leverantörer, anställda och partners. Det sätter press på organisationen när det gäller ekonomi, branschrykte, kundförtroende och säkerhetsomkrets.
Därför måste du vara redo i förväg för att övervinna ett sådant scenario. För detta måste du återställa varje operation och data omedelbart. Med enkla ord måste du förbereda din organisation på att återställa allt på kortast möjliga intervall för dina kunder.
Katastrofer är av många slag, såsom cyberattacker, sabotage, terroristattacker, lösenprogram eller fysiska hot, orkaner, jordbävningar, bränder, översvämningar, industriolyckor, strömavbrott och mycket mer.
Vad menar du med katastrofåterställning?

Katastrofåterställning är processen att återfå normal verksamhet efter att ha drabbats av en katastrof. Det innebär att återuppta åtkomst till hårdvara, mjukvara, utrustning, anslutning, nätverk, ström och data. Du måste sätta regler och procedurer i en dokumenterad process för att förbereda din organisation inför en katastrof.
Men om din organisations anläggningar förstörs måste du utöka en del av aktiviteterna genom att arbeta med kommunikation, transport, inköp, arbetsplatser och mer.
Varför är en katastrofåterställningsplan viktig?
Att utarbeta en perfekt plan för att återhämta sig från en katastrof, antingen naturlig eller konstgjord, är avgörande för varje IT-bransch. Se till att du har rätt medarbetare och verktyg på rätt plats för att genomföra planen smidigt.
Låt oss dyka djupare in i varför katastrofåterställning är avgörande.
Begränsa skador
En katastrof är oförutsägbar. Ingen vet när det kommer och går. Men du förbereder dig i förväg för att kontrollera skadorna på din infrastruktur.
Till exempel, i översvämningsutsatta områden kan du placera dina viktiga dokument och typer av utrustning på översta våningen för att undvika skador.
På samma sätt, säkerhetskopiera dina viktiga data innan cyberattacker kan bryta data eller stjäla den.
Återställa tjänster
Om du förbereder en gedigen plan för att återhämta dig från katastrofen går det snabbt och enkelt att återställa alla tjänster till deras normala form. Det betyder att du på kort tid kan återställa nästan alla större tillgångar och tjänster.
Minimera avbrott
Du kan inte veta vad som kommer att hända i morgon eller i nästa steg av en operation. Men med en perfekt återhämtningsplan behöver du inte oroa dig mycket för konsekvenserna. Din infrastruktur kan fortsätta verksamheten med minimala avbrott.
Utbildning och förberedelser

En IT-infrastruktur består av många anställda som arbetar under tak. Alla måste känna till återhämtningen för att omedelbart agera som krävs och förväntat i händelse av en nödsituation.
Korrekt förberedelse kommer också att sänka stressnivåerna för alla som är associerade med din organisation. Dessutom kan du träna dina anställda att vidta nödvändiga åtgärder om en oväntad händelse inträffar.
Terminologier för katastrofåterställning
Låt oss börja med terminologierna för att förstå katastrofåterställning från en närmare bild.
RTO
Återhämtningstidsmål (RTO) är den tid som en organisation sätter i enlighet med verksamhetens natur för att tolerera katastrofer utan att påverka den ekonomiska tillväxten.
När man ställer in RTO måste ett företag kontrollera de driftstopp som kan påverka din organisation på många sätt. Det används för att studera hållbara strategier för att fortsätta din affärsverksamhet även efter en katastrof. När kunder stöter på några störningar i applikationen frågar de hur lång tid det tar för en app att återgå till handlingen. Svaret är RTO för varje organisation.
Exempel: Anta att du är ett onlinetransaktionsföretag som PayPal eller Pioneer som står inför oförutsägbara händelser. I det här fallet kommer din RTO att vara snabb nog att återställa operationen.
Med andra ord sätter ett företag sin RTO till en timme eller två för att undvika konsekvenser i form av ekonomi eller data.
RPO
Recovery Point Objectives (RPO) är den dataförlust som en IT-infrastruktur kan hantera när det gäller tid och mängd information.
Förvirrande?
Ta ett exempel på en databas som registrerar transaktioner från en bank, inklusive överföringar, schemaläggning, betalningar och mer. När en katastrof inträffar återställs databasen i realtid. Skillnaden mellan databasen vid tidpunkten för katastrofen och databasåterställningen efter en katastrof är noll i detta fall.
För vissa företag är det acceptabelt att det tar cirka 24 timmar att återställa all information från säkerhetskopian, men det kan ibland vara katastrofalt. Det är viktigt att ställa in din infrastruktur enligt RPO-kraven. Detta inkluderar att öka frekvensen av säkerhetskopieringarna, lägga till en standby-databas i din arkitektur och mer.
Failover
Tänk på en situation där du reser långa sträckor. Plötsligt fick du ett punkterat däck av någon oväntad anledning. Du tackar reservdäcket som finns i ditt fordon och verktygen för att byta det defekta däcket.
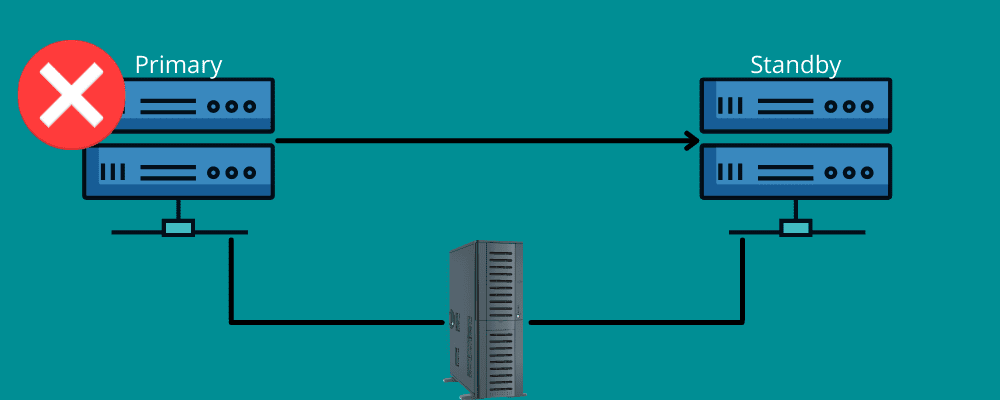
Failover fungerar på samma sätt.
Det betyder att du behöver en backup-anslutning under katastrofen. I ett nötskal betyder failover att ha nätverk och system som du kan använda vid tidpunkten för en katastrof för att byta din information till återställningssystemet.
Failover säkerställer att alla dina tjänster fungerar smidigt, även om det finns infrastruktur- eller hårdvarufel. På så sätt kan du förhindra att din organisation förlorar data och intäkter och undvika tjänsteavbrott för dina slutanvändare.
Du kan antingen ställa in den manuellt eller låta den fungera automatiskt för att flytta data till standbyservern.
Failback
IT-failback är en enkel operation där den ursprungliga produktionen går tillbaka till sin ursprungliga plats (system) efter att en katastrof har hanterats. Under attacken följer företag en failover-operation på grund av vilken alla arbetsbelastningar överförs till en VM-replika eller backup-system.
Du kan dock inte bara hoppa över nästa steg att återvända. När du återställer allt och kommer igång igen måste du överföra alla arbetsbelastningar till deras ursprungliga virtuella datorer eller system. Denna övergripande process för att återföra arbetsbelastningen till den ursprungliga arbetsplatsen eller systemet kallas för failback. Det betyder att du kommer ”tillbaka” efter attacken.
Failback används också för schemalagt underhåll av ett företag. Det är sant att failback alltid inträffar efter failover. Med andra ord är failover det första steget och failback är det andra steget för att återställa viktig data. Det kan ställas in mellan moln till moln, lokalt till lokalt, lokalt till moln, eller någon kombination av dessa.
DR
Disaster Recovery (DR) är processen där du har förbyggda planer för att återställa dina tillgångar inom tidsramen.
DR ger en organisation möjlighet att reagera snabbt och återställa varje enskild tjänst från en oväntad händelse. Den ger också formell dokumentation som innehåller instruktioner om att vidta omedelbara åtgärder vid oförutsedda händelser.
BCP
Business Continuity Plan (BCP) är en av de mest acceptabla katastrofåterställningsplanerna som gör det möjligt för IT-infrastruktur att skapa strategier för att hantera IT-störningar på servrar, mobila enheter, persondatorer och nätverk.
BCP skiljer sig något från katastrofåterställning eftersom det hjälper en organisation att göra planer för att återupprätta företagsprogramvara och produktivitet för att möta viktiga affärsbehov.
Här skapar ett företag ett återställningssystem för att övervinna potentiella hot, såsom cyberattacker eller naturkatastrofer. Den är utformad för att säkra tillgångar och säkerställa att alla tjänster kommer att vara tillbaka i aktion snabbt efter strejken.
BCM

Business Continuity Management (BCM) är en riskhanteringsprocess speciellt utformad för att fungera som en sköld mot hot mot affärsprocesser. BCM är nästa steg i BCP, där det validerar återhämtningsplanerna för att se till att alla i verksamheten reagerar på planen omedelbart och återställer alla viktiga saker.
BCM fungerar som ett ledningsramverk för att identifiera infrastrukturrisker när det står inför externa och/eller interna hot. Det säkerställer också att ramverket fungerar effektivt med hjälp av regelbundna tester för att förbättra förutsägbarheten, minska risken och anpassa planen för framtida attacker.
BIA
Business Impact Analysis (BIA) är processen för att analysera ett företags överlevnadsgrad genom att identifiera viktiga system, operationer och processer. Den berättar om effekten av en katastrof på din organisation på grund av avbrottet i din verksamhet.
BIA förutsäger konsekvenserna innan en attack faktiskt inträffar för att samla in nyckelinformation som kan hjälpa till att skapa kraftfulla återställningsstrategier. Den identifierar också kostnaden på grund av felen, såsom ersättningskostnad för utrustning, förlust av kassaflöde, vinster, löner och mer.
När du skapar en BIA-rapport måste du ta hänsyn till de avgörande processerna som är involverade i din verksamhet, effekterna av störningar på olika områden, acceptabel varaktighet, tolererbara områden, finansiella kostnader och mer.
Ring Tree
Ett samtalsträd är en process för att sammanställa en lista över personal att ringa till under en nödsituation. Det är en procedur som följer en trädliknande struktur.
Till exempel, under en katastrof kommer en person att kontakta en liten grupp medlemmar med ett brådskande meddelande, de anställda ringer varje grupp separat. På så sätt kommer all personal att bli informerad under hotet och påbörja sitt tilldelade jobb för att återställa varje funktion och process i tid. Att göra en lista är enkelt men att implementera den i realtid skapar förvirring.
Du måste utföra regelbundna samtalsaktiviteter för att förbereda varje räddningspersonal att hålla sig alert. Regelbundna tester kan också hjälpa till att identifiera ändrade eller saknade siffror som kan påverka prestandan allvarligt.
Ett samtalsträd innehåller information som ska användas under en nödsituation för att leverera instruktioner. Det kan också göras manuellt, men människor använder automatisering för att påskynda processen och meddela medlemmarna i dagens digitala värld.
Kommandocenter/Kontrollcenter
Det är en virtuell eller fysisk anläggning speciellt förberedd för att ge kommando eller kontroll över återhämtningsplanerna under en kris. Den kommunicerar med teamet för att hantera systemen och funktionerna under katastrofen.
Traditionellt sett är infrastrukturen beroende av att ledningscentralen hanterar kriser utan någon ordentlig inställning. Nuförtiden har organisationer designat sitt kontrollcenter perfekt, vilket vänder det omedelbara svaret till kärnkompetens.
När den väl känner av en katastrof, kör ledningscentralen snabbt mot återhämtningsfasen. Dessutom fungerar den som rapporteringspunkt när det gäller tjänster, press, leveranser med mera. Den samlar också människor från flera discipliner under sådana scenarier.
Incidentrespons

Incidentrespons är en typ av respons som ges för att hantera en attack. Det görs med hjälp av rätt rutiner och personal för att bevara nätverks- och datasäkerheten effektivt vid rätt tidpunkt.
Om en organisation har en incidentplan före den oväntade händelsen kan den säkra sin data från hot i realtid. Incidentresponsspecialisterna är alltid uppmärksamma på problemen och agerar naturligt under en incident. De vidtar vissa åtgärder för att undvika säkerhetsintrång och säkerställer att de inte hoppar över ett enda steg under katastrofåterställning.
I början måste du fastställa den kritiska informationen och lagra den i molnet eller någon annan avlägsen plats för att garantera säkerheten. Ta itu med aktuella infrastrukturbehov och utvecklande cyberhot genom att regelbundet uppdatera åtgärdsplaner för incidenter.
Säkerhetskopiering
Säkerhetskopieringslösningar hjälper en IT-infrastruktur att underhålla kopior av data och lagra dem säkert vid rätt tidpunkt. Om du möter databaskorruption, oavsiktlig radering av all data eller något annat problem, måste du vara redo med säkerhetskopian för att återställa data direkt och fortsätta med tjänsterna.

Det innebär att replikera filerna och lagra dem på en säker plats för att enkelt komma åt alla data efter en ovanlig händelse. Det hjälper om du säkerhetskopierar din data på flera platser för att säkerställa att du kan återställa den även om en webbplats misslyckas.
Elasticitet
Förmågan hos samhällen, stater, organisationer och individer att stå emot eller stå emot en katastrof utan att kompromissa med tjänsterna och systemen kallas för katastrofresiliens.
En organisation måste vara beredd att hålla tillbaka en stor mängd stress på grund av farorna. Se till att du har förmågan att minimera dina förluster med bättre planering istället för att vänta på att någon ska komma och rädda dig. Detta hjälper dig att hantera katastroferna och effektivt återställa din IT-infrastruktur.
Här är huvudmålet att bevara och återställa de väsentliga funktionerna och strukturerna vid rätt tidpunkt närhelst det behövs. För att bli en katastrofbeständig organisation måste du förbereda dig i förväg och ha förmågan att förutse risker, anpassa dig till förändringar, dela och lära dig, integrera olika sektorer och hantera risknivåer.
SLA

Service Level Agreement (SLA) är en katastrofplan där du nämner för slutanvändarna den tid du kan ta för att återställa tjänster under en nödsituation.
SLA försäkrar kunderna att deras data är säker och inte äventyras eller delas med tredje part. Det är den enda kontaktpunkten med slutanvändarfrågor.
Varje IT-infrastruktur ger säkerhet om SLA till sina kunder. Så se till att du kommunicerar med dina slutanvändare i förväg.
SPOF
A Single Point of Failure (SPOF) är en utrustning, en individ, resurs eller applikation som många andra system eller applikationer är anslutna till.
Om en sådan utrustning eller resurs går sönder, går alla väsentliga delar som är anslutna till systemet ner med den. Därmed kommer hela processen och affärsverksamheten att påverkas.
Därför måste du ha en strategi för att hantera ett sådant problem för att hålla din organisation igång. Det allra första du kan göra är att identifiera den enda utrustningen eller systemet som kan påverka mer. Kör sedan en affärskonsekvensanalys och få ett riskbedömningspoäng för att vara medveten om scenerna som kommer att hända. Gräv i och hitta dem innan evenemanget.
När du har listat alla SPOF, klassificera dem enligt återställningsprocessen. Placera var och en av SPOF i tre olika kategorier:
- Återställ enkelt och direkt med mindre tid och budget.
- Återställning skulle vara svårt, men en pålitlig process skulle kunna utvecklas för att återställa.
- Inget kan göras för att återhämta sig när det väl går ner.
Du kan agera därefter baserat på kategorin.
Systemåterställning
Under maskinvarufel måste du köra en återställningsprocess för att återställa det specifika systemet eller servern till dess ursprungliga form. Och för att återställa hela systemet måste du vara redo med återställningskrav, säkerhetskopior, firmwarekompatibilitet och hårdvarukompatibilitet.
Systemåterställning är en process som återställer maskinen till dess tidigare inställningar eller till samma tillstånd som den var när den var ny. Om du gör detta kommer du att radera alla virusinfektioner på grund av installerad programvara eller applikationer i ditt system.
Denna process inkluderar återhämtningsplanering av en IT-infrastruktur som ställer in och följer vissa procedurer för att säkerställa datatillgänglighet mot konstgjorda eller naturliga störningar.
Systemåterställning
Systemåterställning är ett återställningsverktyg som låter dig återställa vissa filer och information till deras tidigare tillstånd vid rätt tidpunkt.
Med systemåterställning kan du återställa registernycklar, installerade program, drivrutiner, systemfiler och mer tillbaka till sin tidigare version. Detta fungerar som en livräddare i många katastrofer.
Testplan
Det hänvisar till ett dokument som lagrar information om en teststrategi, uppskattningar, resurser, deadlines, mål och scheman. Det fungerar som en ritning som kör tester för att säkerställa hård- och mjukvarusäkerhet.
Detta inkluderar olika tester enligt de förfaranden och steg som planeras för att hantera katastrofens efterverkningar. Utför de regelbundna testerna för att förbereda dig själv och din organisation på att inte hoppa över ett enda steg under handlingsförloppet. På så sätt kan en IT-infrastruktur förstå bristerna och vara redo för kampen.
Slutsats
Ingen vet när en katastrof kommer att hända. Därför är korrekta säkerhets- och säkerhetsåtgärder viktiga för varje företag.
Terminologier för återställning av katastrofer hjälper dig att förstå hur du ska reagera på attacker och katastrofer. Det hjälper dig också att förbereda dig i förväg så att du kan skydda din infrastruktur under en oväntad händelse. Du kommer att kunna skapa en effektiv katastrofåterställningsstrategi i realtid för att spara miljontals dollar och hålla tillbaka kundernas förtroende.