Information är en fundamental tillgång för alla verksamheter. Den utgör kärnan för framgång, är avgörande för att samla insikter, fatta välgrundade beslut och förbättra operativa processer.
Företag är i sin dagliga verksamhet beroende av sin information och sina applikationer. Men vad händer om en av deras databaser eller system havererar?
Kritisk affärsinformation och data kan utsättas för risker.
Lyckligtvis finns det metoder för att förebygga sådana scenarier. En av de mest effektiva metoderna för att skydda företagsdata är genom databasreplikering. Det är en åtgärd som alla företag, oavsett storlek, bör implementera för att bibehålla sin konkurrenskraft.
Denna artikel kommer att belysa vad databasreplikering innebär, hur det fungerar, samt andra relevanta aspekter.
Låt oss börja!
Vad innebär databasreplikering?
Databasreplikering är processen att överföra data från en primär datakälla till en eller flera sekundära databaser. Det involverar ofta kopiering eller strömning av data från en databas till en annan, vilket möjliggör synkroniserad dataåtkomst för alla användare, oavsett vilket system de använder.
Om data ändras, kommer ett datareplikeringsverktyg säkerställa att dessa ändringar implementeras även i måldatabasen. Detta skapar ett distribuerat datalagringsnätverk med förbättrad tillgänglighet över flera platser, vilket gör att alla snabbt kan komma åt viktig information.
Genom att implementera en datareplikeringslösning kan du sannolikt förvänta dig en förbättring av datakonsistensen över alla noder, reducerad dataredundans, ökad datatillförlitlighet och i förlängningen, bättre prestanda.
Databasreplikering kan ske i realtid, när data skapas, redigeras eller raderas i källdatabasen, eller som en del av en batchprocess.
Hur fungerar datareplikering?
Databasreplikering kan ske som en engångsföreteelse eller som en kontinuerlig process. Det omfattar alla datakällor inom en organisation, och ett distribuerat databashanteringssystem (DDBMS) används för att överföra eller distribuera data till alla källor.
Eventuella ändringar, tillägg eller raderingar som görs i källdatabasen synkroniseras automatiskt med de andra måldatabaserna, om det krävs. Enligt den traditionella programvarumodellen för utgivare-prenumerant (Publisher-Subscriber) är en eller flera ”utgivare” och ”prenumeranter” involverade i datareplikeringsprocessen.
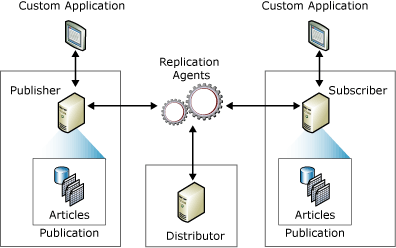
En ”utgivare” är ett system eller en källdatabas där ändringar utförs, medan en ”prenumerant” är ett system där ändringarna replikeras.
Alla ändringar som görs i ett ”utgivare”-system replikeras till ”prenumerant”-databaser. Användare kan även göra ändringar i prenumerantdatabaserna, som sedan replikeras i utgivardatabasen. Om systemet är dubbelriktat distribueras ändringarna till alla andra prenumeranter i nätverket.
De flesta prenumeranter har också en permanent anslutning till utgivaren, vilket möjliggör automatiska ändringar och uppdateringar utan manuell inblandning. Dessa uppdateringar kan ske periodvis i omgångar eller utlösas och tillämpas i realtid.
Typer av databasreplikering
Några av de vanligaste typerna av databasreplikering inkluderar:
#1. Fullständig tabellreplikering
Fullständig tabellreplikering skapar en kopia av hela källdatabasen i mållagringen. Det flyttar rader från utgivaren till prenumeranten, inklusive nya, ändrade och befintliga rader.
Denna replikeringsmetod är dock förknippad med höga underhållskostnader på grund av de beräkningskraft och nätverksbandbredd som krävs för att kopiera allt. Det belastar nätverket och kan orsaka replikeringsfördröjningar, särskilt vid större datavolymer.
#2. Ögonblicksbildreplikering
En ögonblicksbild av källdatabasen används i denna form av databasreplikering för att replikera data i måldatabasen. Den tar inte hänsyn till dataändringar, som till exempel nya, uppdaterade eller raderade data, utan skapar istället en kopia av det data som samlats in vid ett visst tillfälle.
Denna replikeringsteknik är att föredra när dataändringar är begränsade. Det är betydligt snabbare än fullständig tabellreplikering, men den spårar inte raderade data.

#3. Sammanfogningsreplikering
Sammanfogningsreplikering är en process som överför och distribuerar databasobjekt och data från en databas till en annan med hjälp av databassynkronisering. Processen är komplex eftersom prenumeranter och utgivare kan göra ändringar i databasen, vilket kan leda till frekventa datakonflikter som är kopplade till versioner.
Sammanslagningsagenter distribuerade på servrarna synkroniserar alla ändringar och följer en fördefinierad konfliktlösningsprocess för att hantera eventuella datakonflikter.
#4. Nyckelbaserad inkrementell replikering
Nyckelbaserad inkrementell replikering använder nycklar eller index i en databas för att identifiera ändringar såsom raderingar, tillägg och uppdateringar. Replikationsmekanismen kopierar sedan endast de nödvändiga replikeringsnycklarna till replikeringsdatabasen för att återspegla de ändringar som har skett sedan den senaste uppdateringen. Dessa nycklar är ofta en tidsstämpel, ett datum eller ett heltal.
Processen går snabbare eftersom endast specifika ändringar replikeras till replikdatabasen. Dessvärre tillåter inte denna metod permanenta borttagningar, eftersom det kritiska värdet tas bort genom att radera posten i primärdatabasen.
#5. Loggbaserad inkrementell replikering
Denna typ av databasreplikering duplicerar data enligt databasens binära loggfil. Vid inspektion av den binära loggfilen kommer den att visa information om de ändringar som gjorts i den primära databasen, till exempel uppdateringar, insättningar eller borttagningar. Samma ändringar eller uppdateringar utförs sedan i din måldatabas.
Detta är en av de mest använda metoderna för datareplikering, eftersom den är effektiv, särskilt för statiska databaser. Dessutom stöder de flesta databasleverantörer det, inklusive Oracle, MongoDB, MySQL och PostgreSQL.
#6. Transaktionsreplikering
Vid nya händelser gällande källdata flyttar transaktionsreplikering all befintlig data från källdatabasen till målet. Samma transaktion genomförs sedan i replikerna.
Även om det är en effektiv replikeringsmetod används den främst för läsoperationer och tillåter vanligtvis inte skapande, radering eller uppdatering.
Varför är databasreplikering viktigt?

Databasreplikering är viktig av följande skäl:
Datatillförlitlighet och tillgänglighet
Datareplikering främjar datatillgänglighet. Den spelar en viktig roll när en server fallerar under exceptionella omständigheter genom att tillhandahålla databasbackuper. Det kan rädda dagen, eftersom datan då är tillgänglig på andra platser. Det förbättrar också datatillförlitligheten genom att aktuell, relevant data lagras säkert på flera servrar.
Katastrofåterställning
Databasreplikering är en tillgång vid serverfel. Det är en utmärkt metod för katastrofhantering och återställning, eftersom den replikerar och lagrar data och de senaste ändringarna på andra serverplatser, istället för att förlita sig på en enda server.
Serverprestanda
Dataåtkomst går betydligt snabbare när data bearbetas och körs på flera servrar. Genom att omdirigera alla dataläsoperationer till en replik kan administratörer dessutom frigöra behandlingscykler på den ursprungliga servern för mer resurskrävande skrivoperationer.
Bättre nätverksprestanda
Genom att ha flera kopior av samma data på olika platser kan dataåtkomstfördröjningar minskas, eftersom relevant information kan hämtas från platsen där transaktionen utförs.
Exempelvis kan användare i europeiska länder uppleva latensproblem när de hämtar data från australiensiska datacenter. Att placera en kopia av datan nära användaren kan förbättra åtkomsttiderna, samtidigt som nätverksbelastningen balanseras.
Förbättrad testsystemprestanda

Databasreplikering effektiviserar distribution och synkronisering av data för testsystem som kräver snabb åtkomst, för snabbare beslutsfattande.
Databassäkerhetskopiering kontra databasreplikering
Det finns flera skillnader mellan databassäkerhetskopiering och databasreplikering. Några av dem är följande:
- Databassäkerhetskopior måste rekonstrueras och återställas innan de kan användas. Datareplikering kräver inte rekonstruktion, utan kan användas direkt.
- Databassäkerhetskopior består av filer eller mappar, databasdatafiler och programfiler, beroende på organisationens säkerhetskopierings- och återställningsprotokoll. Databasreplikering används däremot ofta för att duplicera hela volymer eller filsystem, databaser och applikationer.
- Både säkerhetskopiering och replikering är metoder för dataskydd. Säkerhetskopiering syftar till att minska återställningspunktmålen (RPO) och förhindra dataförlust. Replikering syftar till att minska återställningstidsmålen (RTO) och säkerställa kontinuitet i verksamheten, samt minimera driftstopp.
- Databassäkerhetskopiering är en kostnadseffektiv metod för att undvika total dataförlust. Det är viktigt för efterlevnad, men garanterar inte fortsatt drift. Replikering garanterar däremot att affärsapplikationer och processer alltid är tillgängliga, även vid strömavbrott.
- Databassäkerhetskopiering handlar om efterlevnad och detaljerad återställning, som till exempel långtidslagring av företagsdokument. Databasreplikering fokuserar på katastrofåterställning, samt snabb och smidig återupptagande av verksamheten efter ett avbrott.
- Databassäkerhetskopiering används ofta på arbetsplatsen för allt från produktionsservrar till stationära datorer. Databasreplikering används ofta för verksamhetskritiska applikationer som alltid måste vara tillgängliga.
Tekniker för databasreplikering

Organisationer kan replikera data genom att följa specifika tekniker för dataöverföring. Dessa strategier skiljer sig från de replikeringstyper som beskrivs ovan.
#1. Full databasreplikering
Fullständig databasreplikering replikerar en hel databas för användning på olika värdar. Detta garanterar den högsta graden av dataredundans och tillgänglighet. För globala företag tillåter det användare i Asien att komma åt samma data som sina kollegor i Nordamerika, med samma hastighet. Om den asiatiska servern fallerar, kan användarna använda sina europeiska eller nordamerikanska servrar som backup.
Nackdelen med denna teknik är den långsamma uppdateringsprocessen. Det är även svårt att säkerställa konsistens för varje filplats, vilket är viktigt om data ständigt ändras.
#2. Partiell databasreplikering
Partiell databasreplikering är processen att dela upp data i en databas i mindre delar och spara dem på olika platser, beroende på vad som är relevant för varje plats.
Försäkringsjusterare, finansiella rådgivare och säljare tjänar på partiell replikering. Dessa anställda kan ha de partiella databaserna på andra enheter eller bärbara datorer och synkronisera dem regelbundet med en central server.
För analytiker kan det vara mer kostnadseffektivt att behålla europeisk data i Europa, australisk data i Australien, etc. Detta innebär att ha datan nära användarna, samtidigt som en omfattande datauppsättning finns tillgänglig på huvudkontoret för analyser på hög nivå.
Nackdelar med databasreplikering

Även om datareplikering kan erbjuda betydande värde för ditt arbete och företag, har det även följande nackdelar:
Högre kostnader
När data replikeras och lagras på flera platser kräver det mer lagringsutrymme och beräkningsresurser. Denna ökade efterfrågan på hårdvara och beräkningsresurser kan leda till högre kostnader, som till exempel inköp och underhåll av ytterligare lagringsenheter, servrar och nätverksinfrastruktur.
Tidsbegränsningar
Datareplikering är en komplex process som involverar kopiering av data från en plats till flera andra platser, och att upprätthålla konsistens mellan alla kopior. Denna process kan ta betydande tid, speciellt för organisationer som måste replikera stora mängder data.
Bandbredd
När mängden data som ska replikeras ökar, ökar även bandbreddskraven, vilket kan belasta nätverksresurserna.
Inkonsekvent data
Vid replikering av data i en distribuerad miljö finns det en risk att data blir osynkroniserad, om uppdateringar inte genomförs konsekvent över alla repliker. Det kan resultera i inkonsekvent data och kräva extra ansträngning för att lösa.
Användningsområden för databasreplikering

Det finns flera användningsområden för datareplikering, till exempel:
Lastbalansering
Genom att replikera data till flera servrar fördelas lasten över dessa servrar, vilket förbättrar prestandan. Lastbalansering säkerställer att en enskild server inte överbelastas av för många förfrågningar och att systemet förblir tillgängligt och responsivt, även under perioder med hög trafik.
Datalagring
Ett datalager är ett centraliserat arkiv för att lagra stora mängder data från flera källor. Genom att replikera data från dessa källor till datalagret kan organisationer analysera och rapportera om sina data på ett centraliserat och organiserat sätt.
Geografisk spridning
Genom att replikera data till flera regioner kan organisationer förbättra datatillgänglighet och redundans. Om en region upplever ett avbrott, kan data fortfarande nås från en annan region. Att ha data i flera regioner kan dessutom hjälpa till att förbättra åtkomsthastigheten för användare i olika delar av världen.
Säkerhetskopiering och arkivering
Genom att replikera data till sekundär lagring kan organisationer behålla en långsiktig kopia av sin data. Detta säkerställer enkel åtkomst till data och att den inte går förlorad, även om den primära lagringen fallerar.
Datasynkronisering
Genom att replikera data mellan flera system kan man säkerställa att data förblir synkroniserad, konsekvent och uppdaterad överallt. Det är viktigt för applikationer som e-handel, där samma data måste vara tillgänglig från flera system.
Samarbete på flera platser
Genom att replikera data mellan flera platser kan organisationer dela data i realtid, vilket möjliggör samarbete och ökad produktivitet. Detta är särskilt användbart för organisationer med team på flera platser, eller företag som behöver dela data med partners eller kunder.
Läromedel
Här är några läromedel som hjälper dig att förstå ämnet bättre:
#1. Databasreplikering av Bettina Kemme
Den här boken hjälper dig att förstå olika kontrollmekanismer för samtidig åtkomst och repliker, samt relaterade frågor.
#2. Databasreplikering: En komplett guide:
Denna bok förbereder dig för att hantera utmaningar inom databasreplikering genom att förklara och besvara dina frågor.
Sammanfattning
Datareplikering är en underskattad strategi i dagens snabbt föränderliga, datadrivna värld. Om du är företagare kommer du troligen att bli imponerad av dess fördelar.
När antalet källor och destinationer ökar måste företagen vara beredda att möta de utmaningar som följer med det. Därför kan en pålitlig och skalbar datareplikeringsstrategi vara till stor nytta.
Du kan också undersöka användbara databasövervakningsprogram för att analysera prestanda.