Introduktion till Apache Kafka: En Steg-för-Steg-Guide
I dagens digitala landskap genereras otaliga dataposter varje dag. Det kan vara allt från finansiella transaktioner till beställningar online eller data från sensorer i din bil. För att kunna bearbeta dessa dataströmmar i realtid och flytta händelseposter på ett pålitligt sätt mellan olika system, är Apache Kafka en ovärderlig resurs.
Apache Kafka är en öppen källkod-lösning för dataströmning som klarar över en miljon meddelanden per sekund. Utöver denna imponerande genomströmning erbjuder Kafka hög skalbarhet, tillgänglighet, låg latens och permanent lagring av data.
Stora företag som LinkedIn, Uber och Netflix förlitar sig på Apache Kafka för sin realtidsbearbetning och dataströmning. Det enklaste sättet att bekanta sig med Kafka är att installera det lokalt på din dator. Detta ger dig inte bara chansen att se Kafka-servern i aktion, utan också möjligheten att själv producera och konsumera meddelanden.
Genom praktisk erfarenhet av att starta servern, skapa ämnen och skriva Java-kod med Kafka-klienten, är du väl rustad att använda Apache Kafka för att hantera alla dina dataledningsbehov.
Hur du laddar ner Apache Kafka lokalt
Du kan ladda ner den senaste versionen av Apache Kafka från den officiella nedladdningssidan. Det nedladdade arkivet kommer i .tgz-format. När nedladdningen är klar, måste du packa upp filerna.
Om du använder Linux, öppna din terminal. Gå till mappen där du laddade ner arkivet och kör kommandot:
tar -xzvf kafka_2.13-3.5.0.tgz
Efter kommandot har körts, kommer en ny mapp med namnet `kafka_2.13-3.5.0` att skapas. Navigera in i denna mapp med:
cd kafka_2.13-3.5.0
Du kan nu visa innehållet i katalogen med `ls`-kommandot.
För Windows-användare är stegen liknande. Om du inte har tillgång till `tar`-kommandot, kan du använda ett program som WinZip för att packa upp arkivet.
Starta Apache Kafka på din lokala maskin
Nu när du har laddat ner och packat upp Apache Kafka, är det dags att starta det. Kafka behöver inte installeras; du kan starta det direkt via kommandoraden eller terminalen.
Innan du startar Kafka, se till att du har Java 8 eller senare installerat på din dator, eftersom Kafka kräver en Java-miljö för att fungera.
1. Kör Apache Zookeeper-servern
Det första steget är att starta Apache Zookeeper, som ingår i arkivet. Zookeeper är en tjänst som hanterar konfigurationer och synkronisering för andra tjänster.
När du är i katalogen där du har packat upp filerna, kör följande kommando:
För Linux-användare:
bin/zookeeper-server-start.sh config/zookeeper.properties
För Windows-användare:
bin/windows/zookeeper-server-start.bat config/zookeeper.properties
Filen `zookeeper.properties` innehåller konfigurationerna för Zookeeper-servern. Du kan ändra inställningar som datalagringskatalog och portnumret för servern.
2. Starta Apache Kafka-servern
Med Zookeeper igång kan du nu starta Kafka-servern.
Öppna ett nytt terminal- eller kommandotolksfönster och navigera till samma mapp. Starta servern med följande kommando:
För Linux-användare:
bin/kafka-server-start.sh config/server.properties
För Windows-användare:
bin/windows/kafka-server-start.bat config/server.properties
Din Kafka-server är nu igång. Om du vill ändra standardkonfigurationen kan du göra det genom att redigera `server.properties`-filen. Mer information om de olika inställningarna finns i den officiella dokumentationen.
Använd Apache Kafka lokalt
Nu är du redo att använda Kafka för att producera och konsumera meddelanden. Med Zookeeper och Kafka-servrarna igång, låt oss utforska hur du skapar ett ämne, producerar ett meddelande och konsumerar det.
Vad är stegen för att skapa ett ämne i Apache Kafka?
Innan du skapar ditt första ämne, låt oss förstå vad ett ämne är i Kafka. Ett ämne är en logisk datalagringsplats som hanterar dataströmning. Tänk på det som en kanal där data transporteras mellan olika komponenter.
Ett ämne kan hantera flera producenter och konsumenter. Det innebär att flera system kan skriva och läsa från samma ämne. Till skillnad från andra meddelandesystem, kan meddelanden i ett Kafka-ämne konsumeras flera gånger. Du kan också bestämma hur länge meddelanden ska sparas.
Låt oss illustrera med ett exempel där ett system (producent) skickar transaktionsdata och ett annat system (konsument) läser denna data för att skicka aviseringar till användare. Ett ämne möjliggör denna kommunikation.
Öppna en ny terminal eller ett kommandotolksfönster och gå till mappen där du packade upp Kafka. Följande kommando skapar ett ämne som heter ”transaktioner”:
För Linux-användare:
bin/kafka-topics.sh --create --topic transactions --bootstrap-server localhost:9092
För Windows-användare:
bin/windows/kafka-topics.bat --create --topic transactions --bootstrap-server localhost:9092
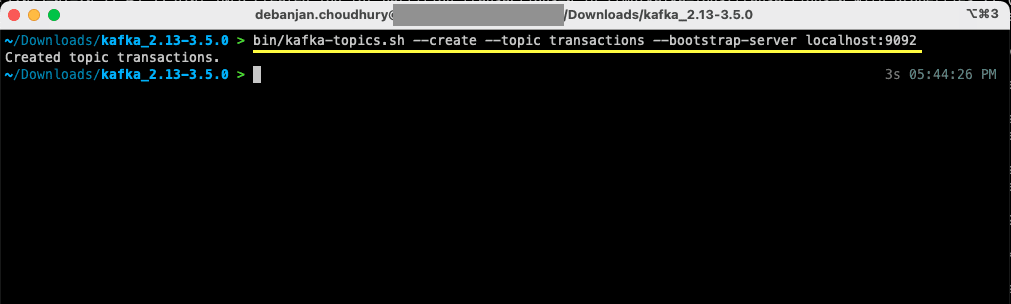
Nu har du skapat ditt första ämne och kan börja producera och konsumera meddelanden.
Hur producerar man ett meddelande till Apache Kafka?
Med ditt ämne redo, kan du skapa ditt första meddelande. Öppna ett nytt terminal- eller kommandotolksfönster, eller använd samma som du använde för att skapa ämnet. Se till att du befinner dig i rätt katalog. Använd följande kommando för att skicka ett meddelande till ditt ämne:
För Linux-användare:
bin/kafka-console-producer.sh --topic transactions --bootstrap-server localhost:9092
För Windows-användare:
bin/windows/kafka-console-producer.bat --topic transactions --bootstrap-server localhost:9092
När du kör kommandot kommer terminalen att vänta på din inmatning. Skriv ditt meddelande och tryck på Enter.
> This is a transactional record for $100
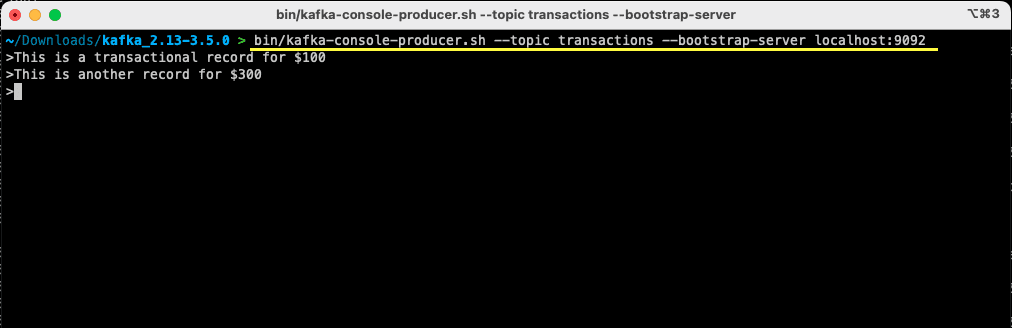
Du har nu skickat ditt första meddelande till Kafka lokalt, och är redo att konsumera det.
Hur konsumerar man ett meddelande från Apache Kafka?
Nu när du har ett skapat ett ämne och skickat ett meddelande, kan du konsumera det.
Kafka tillåter flera konsumenter att prenumerera på samma ämne. Varje konsument kan tillhöra en konsumentgrupp, en logisk identifierare. Om två tjänster behöver konsumera samma data, kan de ha olika konsumentgrupper. Om du har två instanser av samma tjänst vill du undvika dubbel bearbetning, så de bör ha samma konsumentgrupp.
Se till att du är i rätt katalog i terminalen. Använd följande kommando för att starta konsumenten:
För Linux-användare:
bin/kafka-console-consumer.sh --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer
För Windows-användare:
bin/windows/kafka-console-consumer.bat --topic transactions --from-beginning --bootstrap-server localhost:9092 --group notif-consumer

Du kommer att se meddelandet du skapade tidigare visas i terminalen. Du har nu använt Kafka för att konsumera ditt första meddelande.
Kommandot `kafka-console-consumer` accepterar flera argument. Låt oss gå igenom dem:
- `–topic` anger vilket ämne konsumenten ska läsa från.
- `–from-beginning` instruerar konsumenten att börja läsa från det första meddelandet.
- `–bootstrap-server` anger adressen till din Kafka-server.
- `–group` anger namnet på konsumentgruppen.
- Om ingen konsumentgrupp anges, skapas en automatiskt.
Med konsumenten igång kan du skicka nya meddelanden, och de kommer att synas i terminalen.
Nu när du har skapat ett ämne och skickat och konsumerat meddelanden, låt oss integrera detta med en Java-applikation.
Skapa Apache Kafka-producent och konsument med Java
Innan du börjar, se till att du har Java 8 eller senare installerat. Kafka har ett eget klientbibliotek som underlättar anslutningen. Om du använder Maven, lägg till följande beroende i din `pom.xml`:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.0</version>
</dependency>
Du kan också ladda ner biblioteket från Maven-förrådet och lägga till det i din Java-klassväg.
Med biblioteket på plats, öppna valfri kodredigerare. Låt oss se hur du kan starta din producent och konsument med Java.
Skapa Apache Kafka Java-producent
Med Kafka-klientbiblioteket i ordning, kan du börja skapa din Kafka-producent.
Skapa en klass som heter `SimpleProducer.java`. Denna klass kommer att ansvara för att skicka meddelanden till det ämne du skapade tidigare. Inuti klassen skapar du en instans av `org.apache.kafka.clients.producer.KafkaProducer`. Sedan använder du denna producent för att skicka dina meddelanden.
För att skapa Kafka-producenten behöver du värden och porten för din Kafka-server. Eftersom du kör servern lokalt, kommer värden att vara localhost, och om du inte har ändrat standardporten är den 9092. Se följande kod som hjälper dig att skapa producenten:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
}
Du kommer att märka att det finns tre egenskaper som anges. Låt oss snabbt gå igenom var och en av dem:
- `BOOTSTRAP_SERVERS_CONFIG` anger adressen till Kafka-servern.
- `KEY_SERIALIZER_CLASS_CONFIG` anger formatet för att skicka meddelandenycklarna.
- `VALUE_SERIALIZER_CLASS_CONFIG` anger formatet för det faktiska meddelandet.
Eftersom du skickar textmeddelanden, är båda inställda på `StringSerializer.class`.
För att skicka ett meddelande till ditt ämne, måste du använda metoden `producer.send()`, som tar in ett `ProducerRecord`. Följande kod ger en metod som skickar ett meddelande och skriver ut svaret, inklusive meddelande-offset:
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
Med hela koden på plats, kan du nu skicka meddelanden. Du kan använda en huvudmetod för att testa det, som i koden nedan:
package org.example.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class SimpleProducer {
private final KafkaProducer<String, String> producer;
public SimpleProducer(String host, String port) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
this.producer = new KafkaProducer<>(properties);
}
public void produce(String topic, String message) throws ExecutionException, InterruptedException {
ProducerRecord<String, String> record = new ProducerRecord<>(topic, message);
final Future<RecordMetadata> send = this.producer.send(record);
final RecordMetadata recordMetadata = send.get();
System.out.println(recordMetadata);
}
public static void main(String[] args) throws Exception{
SimpleProducer producer = new SimpleProducer("localhost", "9092");
producer.produce("transactions", "This is a transactional record of $200");
}
}
Denna kod skapar en `SimpleProducer` som ansluter till din lokala Kafka-server. Den använder KafkaProducer för att skicka textmeddelanden till ditt ämne.
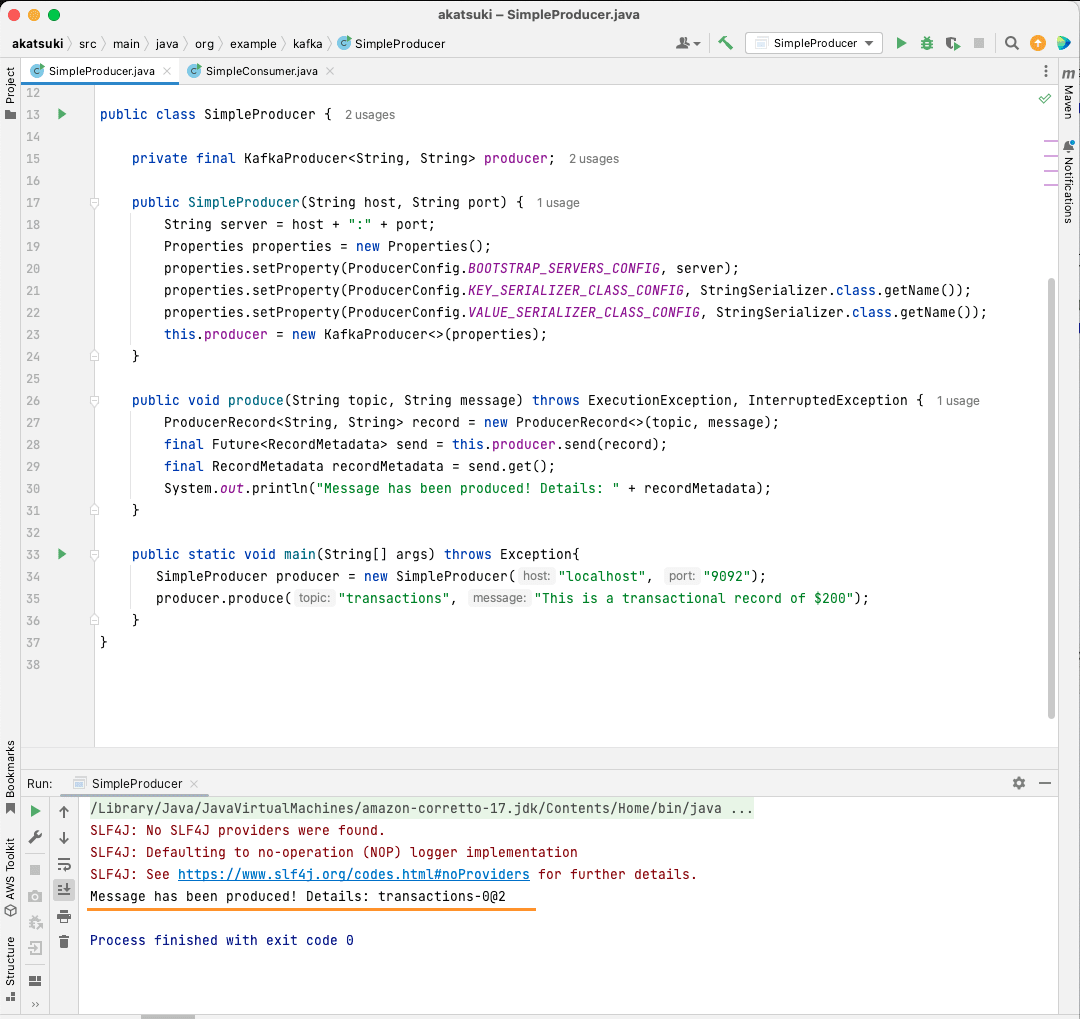
Skapa Apache Kafka Java-konsument
Nu är det dags att skapa en Kafka-konsument med Java-klienten. Skapa en klass som heter `SimpleConsumer.java`. Skapa en konstruktor som initierar `org.apache.kafka.clients.consumer.KafkaConsumer`. För att skapa konsumenten behöver du värden och porten där Kafka-servern körs, konsumentgruppen och ämnet du vill konsumera från. Använd koden nedan:
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
}
I likhet med Kafka-producenten, tar Kafka-konsumenten också ett Properties-objekt. Låt oss titta på alla egenskaperna:
- `BOOTSTRAP_SERVERS_CONFIG` talar om var Kafka-servern körs.
- `GROUP_ID_CONFIG` anger konsumentgruppen.
- `AUTO_OFFSET_RESET_CONFIG` anger var konsumenten ska börja läsa meddelanden.
- `KEY_DESERIALIZER_CLASS_CONFIG` anger typen av meddelandenyckel.
- `VALUE_DESERIALIZER_CLASS_CONFIG` anger typen av meddelandet.
Eftersom du konsumerar textmeddelanden, är deserializer-egenskaperna satta till `StringDeserializer.class`.
Nu kommer du att konsumera meddelanden från ditt ämne. För enkelhetens skull kommer meddelandet att skrivas ut i konsolen. Så här kan du åstadkomma det med följande kod:
private boolean keepConsuming = true;
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
Denna kod fortsätter att läsa från ämnet. När en konsumentpost hittas, skrivs meddelandet ut. Testa din konsument med en huvudmetod. Detta startar en Java-applikation som kontinuerligt läser och skriver ut meddelanden. Stoppa applikationen för att avsluta konsumenten.
package org.example.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicBoolean;
public class SimpleConsumer {
private static final String OFFSET_RESET = "earliest";
private final KafkaConsumer<String, String> consumer;
private boolean keepConsuming = true;
public SimpleConsumer(String host, String port, String consumerGroupId, String topic) {
String server = host + ":" + port;
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, server);
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, consumerGroupId);
properties.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, OFFSET_RESET);
properties.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
this.consumer = new KafkaConsumer<>(properties);
this.consumer.subscribe(List.of(topic));
}
public void consume() {
while (keepConsuming) {
final ConsumerRecords<String, String> consumerRecords = this.consumer.poll(Duration.ofMillis(100L));
if (consumerRecords != null && !consumerRecords.isEmpty()) {
consumerRecords.iterator().forEachRemaining(consumerRecord -> {
System.out.println(consumerRecord.value());
});
}
}
}
public static void main(String[] args) {
SimpleConsumer simpleConsumer = new SimpleConsumer("localhost", "9092", "transactions-consumer", "transactions");
simpleConsumer.consume();
}
}
När du kör koden ser du att den konsumerar meddelanden från Java-producenten såväl som meddelanden från konsolproducenten. Detta beror på att `AUTO_OFFSET_RESET_CONFIG` är inställt på ”earliest”.
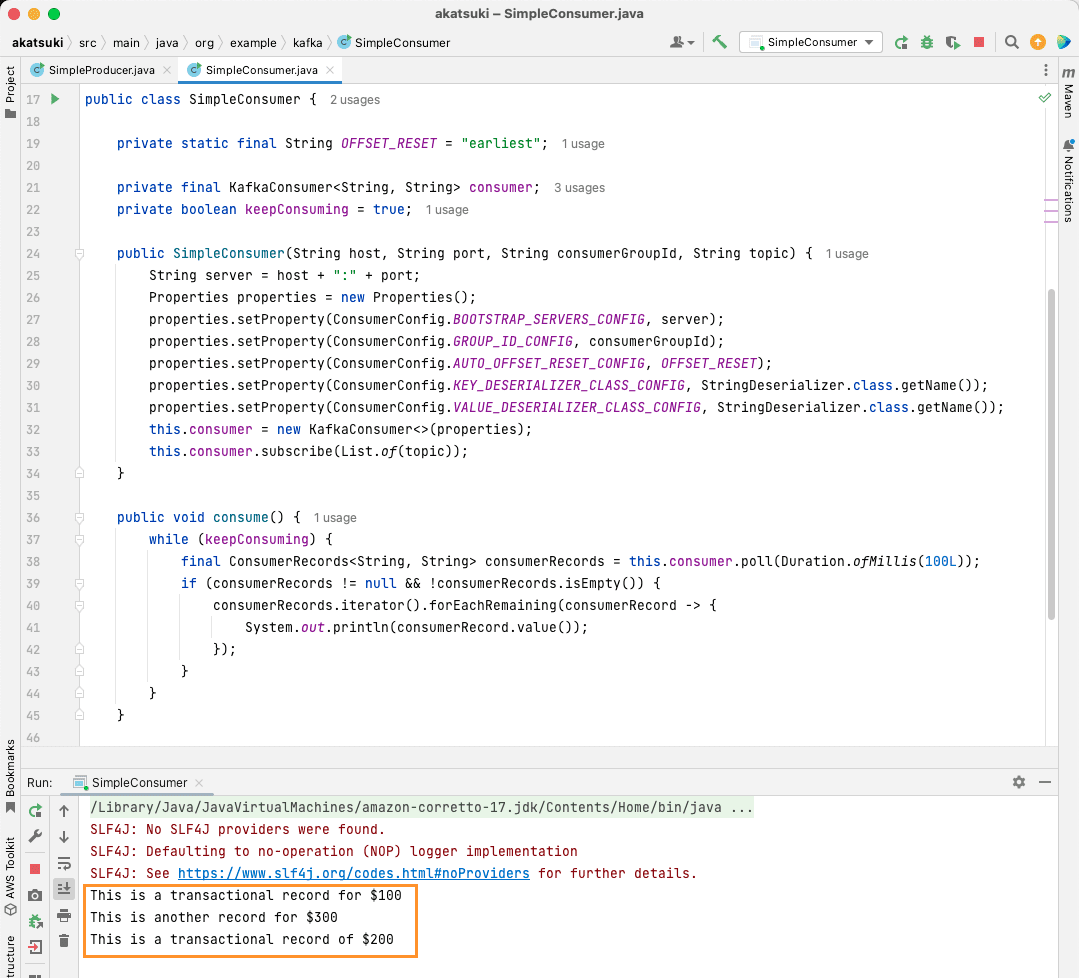
Med `SimpleConsumer` igång kan du använda konsolproducenten eller `SimpleProducer`-applikationen för att skicka fler meddelanden. De kommer att konsumeras och skrivas ut i konsolen.
Tillgodose dina dataledningsbehov med Apache Kafka
Apache Kafka ger dig verktygen du behöver för att hantera dina dataledningsbehov. Med en lokal Kafka-installation kan du utforska de olika funktionerna. Dessutom ger den officiella Java-klienten möjligheten att effektivt skriva, ansluta och kommunicera med din Kafka-server.
Kafka är ett mångsidigt, skalbart och högpresterande dataströmningssystem som kan vara en verklig förändring för dig. Du kan använda det för lokal utveckling eller integrera det i dina produktionssystem. Att sätta upp Kafka för större applikationer är lika enkelt som den lokala installationen.
Om du letar efter dataströmningsplattformar kan du undersöka de bästa dataströmningsplattformarna för realtidsanalys och bearbetning.