I den snabbrörliga digitala världen är företag starkt beroende av data för att blomstra. Omfattande datamängder samlas in regelbundet, inklusive kundinteraktioner, försäljningssiffror, intäkter, konkurrentanalyser, webbplatsstatistik och mycket mer.
Att hantera denna komplexa datamassa kan vara en utmaning. Om det inte hanteras korrekt kan det leda till betydande problem.
Det är här dataorkestrering kommer in i bilden.
Dataorkestrering hjälper dig att hantera och organisera din viktiga information på ett effektivt sätt.
Genom att använda dataorkestrering kan företag dra nytta av kraften i sin data och skaffa sig en konkurrensfördel på marknaden.
I den här artikeln kommer jag att utforska konceptet dataorkestrering och hur det kan gynna din organisation.
Låt oss börja!
Vad är dataorkestrering?
Dataorkestrering är processen att effektivt samla, omvandla, integrera och hantera data från flera källor.
Huvudsyftet med dataorkestrering är att effektivisera datan från olika platser så att företag kan maximera dess potential. Det är en kritisk komponent i den moderna datadrivna världen.
Dataorkestrering ger dig värdefulla insikter i din verksamhet, dina kunder, marknaden och dina konkurrenter, vilket underlättar välgrundade beslut och hjälper dig att uppnå dina mål.
I enkla termer fungerar dataorkestrering som en dirigent som tolkar och sammanför data från olika databaser. Detta säkerställer att all data ger en korrekt bild av din verksamhets prestationer.
Fördelar med dataorkestrering
Dataorkestrering erbjuder en rad fördelar för organisationer, som anges nedan.
Ökar beslutsfattandet
Dataorkestrering hjälper dig att skapa en sammanhängande och välstrukturerad datauppsättning. Detta leder till bättre beslut eftersom du enkelt kan analysera även komplexa och oorganiserade data.
Bättre kundupplevelse
Genom att få en djupare förståelse för dina kunders beteende, preferenser och feedback kan du ge dem bättre service. Dataorkestrering möjliggör riktade åtgärder, vilket leder till en förbättrad kundupplevelse.
Förbättrad operativ effektivitet
Dataorkestrering minskar den tid som tidigare behövdes för manuell datainsamling och samordning. Detta minskar manuellt arbete, bryter ner datasilos och effektiviserar dataprocesser automatiskt och enkelt.
Ekonomisk
Molnbaserad dataorkestrering ger flexibla lagrings- och bearbetningsalternativ. Detta innebär att du kan undvika onödiga kostnader och bara betala för det du behöver och använder.
Konkurrensfördel
Genom att dra nytta av de insikter du får med dataorkestrering kan du fatta snabbare och mer välgrundade beslut än dina konkurrenter. Du kan ligga steget före genom att upptäcka dolda möjligheter och proaktivt reagera på marknadstrender.
Skalbarhet
Dataorkestrering kan anpassas till ökade belastningar när datavolymen växer. Därför kommer dataorkestreringen att anpassa sig till förändrade behov i takt med att din verksamhet expanderar.
Hur fungerar dataorkestrering?

Processen för dataorkestrering innebär att organisera och koordinera data inom hela din organisation. Detta inkluderar insamling av data från flera källor, transformering av den till en sammanhängande datamassa och automatisering av arbetsflöden.
Dataorkestrering ger dig möjlighet att fatta välgrundade affärsbeslut med hjälp av data som vägledning. Det förbättrar din verksamhetseffektivitet och underlättar samarbete mellan olika team och avdelningar inom organisationen.
Detta möjliggör smidig dataöverföring, analys och distribution, vilket hjälper dig att fatta datadrivna beslut.
Faser av dataorkestrering
Dataorkestrering är en komplex process som består av flera sammanlänkade faser. Varje fas är avgörande för att samla in, bearbeta och analysera data på ett effektivt sätt.
Låt oss titta närmare på var och en av dessa faser:
#1. Datainsamling
Dataorkestreringsresan börjar med datainsamlingsfasen. Det är grunden för hela processen, där data samlas in från många olika källor. Dessa källor kan variera från databaser, API:er, applikationer och externa filer.

Datan som samlas in kan vara strukturerad data, som följer ett specifikt format, eller ostrukturerad data, som saknar en fördefinierad modell eller form. Kvaliteten, noggrannheten och relevansen hos datan som samlas in i detta skede påverkar avsevärt de efterföljande faserna av dataorkestreringen.
Därför är det viktigt att ha robusta datainsamlingsstrategier och verktyg för att säkerställa insamling av relevanta och högkvalitativa data.
#2. Dataintag
Dataintagsfasen innebär att importera och ladda den insamlade datan till ett centralt lagringsutrymme, vanligtvis ett datalager.
Denna centrala plats fungerar som en samlingspunkt där data från olika källor samlas. Denna konsolidering effektiviserar hanteringen och behandlingen av data, vilket gör att du kan hantera och använda den effektivt.
För att säkerställa korrekt överföring av all relevant data till den centrala lagringsplatsen är det absolut nödvändigt att datainmatningsprocessen sker smidigt och utan fel.
#3. Dataintegration och -transformation
Den tredje fasen av dataorkestrering innebär att integrera och transformera insamlad data för att göra den användbar för analys. Dataintegration samlar data från olika källor och slår samman dem för att presentera en sammanhängande och meningsfull information.

Denna process är avgörande för att eliminera datasilos och säkerställa att all data är tillgänglig och användbar.
När det gäller datatransformation måste du hantera saknade värden, åtgärda datainkonsekvenser och konvertera data till ett standardiserat format för enklare analys. Denna avgörande process underlättar förbättrad datakvalitet och ökar dess lämplighet för analys.
#4. Datalagring och hantering
Efter att data har integrerats och transformerats innebär nästa fas att lagra den i ett lämpligt lagringssystem.
Stora datamängder kan kräva distribuerade lagringssystem, medan höghastighetsdata kan kräva realtidsbearbetningskapacitet. Datahanteringsprocessen inkluderar inställning av kontroller för dataåtkomst, definition av datastyrningspolicyer och organisering av data för att möjliggöra effektiv analys.
Att se till att data lagras på ett säkert, välorganiserat och lättillgängligt sätt för analys är avgörande i denna fas.
#5. Databearbetning och analys
Databearbetning och analys innebär att utföra dataarbetsflöden för att utföra olika databearbetningsuppgifter. Dessa uppgifter kan inkludera filtrering, sortering, aggregering och sammanslagning av datauppsättningar.

Beroende på dina affärsbehov kan du välja mellan två bearbetningsmetoder: realtidsströmning eller batchbearbetning. Efter att datan har bearbetats är den redo för analys med hjälp av olika plattformar som business intelligence, datavisualiseringsverktyg eller maskininlärning.
Detta steg är otroligt viktigt för att extrahera värdefulla insikter från datan och möjliggöra datadrivet beslutsfattande.
#6. Datarörelse och distribution
Beroende på ditt företags behov kan du behöva flytta data till olika system för specifika ändamål.
Dataförflyttning innebär att på ett säkert sätt överföra eller replikera data till externa partners eller andra system inom organisationen. Denna fas säkerställer att data finns tillgänglig där du behöver den, oavsett om det är för vidare bearbetning, analys eller rapportering.
#7. Arbetsflödeshantering
Att automatisera arbetsflöden minskar manuella ingrepp och fel, vilket förbättrar dataeffektiviteten.
De flesta dataorkestreringsverktyg erbjuder funktioner för att övervaka dataarbetsflöden och underlätta en smidig och effektiv drift. Denna fas spelar en avgörande roll för att säkerställa att hela dataorkestreringsprocessen löper problemfritt.
#8. Datasäkerhet

För att aktivera datasäkerhet måste du upprätta åtkomstkontroller och autentiseringsmekanismer. Dessa åtgärder skyddar värdefull information från obehörig åtkomst och hjälper till att säkerställa efterlevnad av dataregler och interna policyer.
Genom att skydda datans integritet och konfidentialitet under hela dess livscykel kan du upprätthålla en säker miljö för känslig information. Denna fas är avgörande för att upprätthålla kundernas förtroende och förhindra överträdelser.
#9. Övervakning och prestandaoptimering
När dataorkestreringsprocessen väl är på plats är det viktigt att övervaka dataarbetsflöden och bearbetningsprestanda. Detta hjälper till att identifiera flaskhalsar, problem med resursutnyttjande och potentiella fel.
Denna fas innebär att analysera prestandamått och optimera processer för att öka effektiviteten. Denna kontinuerliga övervakning och optimering hjälper till att hålla dataorkestreringsprocessen effektiv och ändamålsenlig.
#10. Feedback och ständiga förbättringar
Dataorkestrering är en iterativ process. Det handlar om att samla in kontinuerlig feedback från dataanalytiker, intressenter och företagsanvändare för att identifiera förbättringsområden och nya krav, samt förfina befintliga dataarbetsflöden.
Denna feedbackslinga säkerställer att dataorkestreringsprocessen ständigt utvecklas och förbättras och därmed uppfyller de förändrade behoven hos ditt företag.
Användningsfall av dataorkestrering
Dataorkestrering används inom olika branscher för en mängd olika ändamål.
E-handel och detaljhandel

Dataorkestrering hjälper e-handels- och detaljhandelsföretag att hantera stora mängder produktdata, lagerinformation och kundinteraktioner. Det hjälper dem också att integrera data från webbutiker, kassasystem och leveranskedjeplattformar.
Sjukvård och Livsvetenskap
Dataorkestrering spelar en viktig roll inom hälso- och sjukvårds- och biovetenskap. Det hjälper dem att säkert hantera, integrera och analysera elektroniska journaler, medicintekniska data och forskningsstudier. Det hjälper också till med datainteroperabilitet, delning av patientdata och medicinsk forskning.
Finansiell sektor
Finansiella tjänster genererar olika finansiella data, såsom transaktionsregister, marknadsdata, kundinformation etc. Genom att använda dataorkestrering kan organisationer inom finanssektorn förbättra sin riskhantering, upptäckt av bedrägerier och efterlevnad av regelverk.
Personalavdelning
HR-avdelningar kan använda dataorkestrering för att konsolidera och analysera personaldata, prestationsmått och rekryteringsinformation. Det hjälper också till med talanghantering, medarbetarengagemang och personalplanering.
Media och underhållning

Medie- och underhållningssektorn hanterar distribution av innehåll över olika plattformar. Mediebranschen kan enkelt göra riktade annonser, förbättra motorer för innehållsrekommendationer och göra målgruppsanalyser genom dataorkestrering.
Supply Chain Management
Supply chain management omfattar data från leverantörer, logistikpartners och lagersystem. Här hjälper dataorkestrering till att integrera all denna data och möjliggör realtidsspårning av produkter.
Bästa dataorkestreringsplattformar
Nu när du har en förståelse för dataorkestrering, låt oss diskutera de bästa dataorkestreringsplattformarna.
#1. Flyte

Flyte är en omfattande plattform för orkestrering av arbetsflöden som är utformad för att sömlöst förena data, maskininlärning (ML) och analysdata. Detta molnbaserade system för maskininlärning och databearbetning kan hjälpa dig att hantera data med tillförlitlighet och effektivitet.
Flyte inkluderar en öppen källkod, strukturerad programmering och distribuerad lösning. Det gör att du kan använda samtidiga, skalbara och lättunderhållna arbetsflöden för maskininlärning och databearbetningsuppgifter.
En av Flytes unika aspekter är användningen av protokollbuffertar som specifikationsspråk för att definiera dessa arbetsflöden och uppgifter, vilket gör det till en flexibel och anpassningsbar lösning för olika databehov.
Nyckelfunktioner
- Underlättar snabba experiment med programvara av produktionskvalitet
- Designad med skalbarhet i åtanke för att hantera varierande arbetsbelastningar och resursbehov
- Ger datautövare och forskare möjlighet att bygga arbetsflöden självständigt med Python SDK
- Ger mycket flexibla data- och ML-arbetsflöden med datalinje från början till slut och återanvändbara komponenter
- Erbjuder en centraliserad plattform för att hantera livscykeln för arbetsflöden
- Kräver minimalt underhåll
- Stöds av en aktiv gemenskap
- Erbjuder ett antal integrationer för en smidig utvecklingsprocess av arbetsflöden
#2. Prefect
Möt Prefect, en toppmodern lösning för arbetsflödeshantering som drivs av arbetsflödesmotorn Prefect Core med öppen källkod. Det representerar den senaste tekniken inom arbetsflödeshantering med avancerade funktioner.

Prefect är särskilt utformad för att hjälpa dig att smidigt hantera komplexa datarelaterade uppgifter med enkelhet och effektivitet som kärnvärden. Med Prefect till ditt förfogande kan du enkelt organisera dina Python-funktioner i hanterbara arbetsenheter samtidigt som du har tillgång till omfattande övervaknings- och koordineringsmöjligheter.
En av Prefects viktigaste egenskaper är dess förmåga att skapa robusta och dynamiska arbetsflöden, så att du enkelt kan anpassa dig till förändringar i miljön. Om oväntade händelser skulle inträffa återställer Prefect dem utan problem, vilket säkerställer smidig datahantering.
Denna anpassningsförmåga gör Prefect till ett idealiskt val för situationer där flexibilitet är avgörande. Med automatiska återförsök, distribuerad körning, schemaläggning, cachning och mer blir Prefect ett ovärderligt verktyg som kan hantera alla datarelaterade utmaningar du kan stöta på.
Nyckelfunktioner
- Automatisering för observerbarhet och kontroll i realtid
- En aktiv gemenskap för support och kunskapsdelning
- Omfattande dokumentation för att bygga kraftfulla dataapplikationer
- Diskussionsforum för svar på prefektrelaterade frågor
#3. Control-M
Control-M är en robust lösning som ansluter, automatiserar och orkestrerar applikations- och dataarbetsflöden i lokala, privata och offentliga molnmiljöer.
Detta verktyg säkerställer att jobben slutförs i tid varje gång, vilket gör det till en pålitlig lösning om du behöver konsekvent och effektiv datahantering. Med ett konsekvent gränssnitt och ett brett utbud av plugin-program kan användare enkelt hantera alla sina operationer, inklusive filöverföringar, applikationer, datakällor och infrastruktur.

Du kan snabbt distribuera Control-M i molnet med hjälp av de övergående funktionerna i molnbaserade tjänster. Detta gör det till en mångsidig och anpassningsbar lösning för olika databehov.
Nyckelfunktioner
- Avancerad operativ kapacitet för utveckling och drift
- Proaktiv SLA-hantering med intelligent prediktiv analys
- Robust support för revisioner, efterlevnad och styrning
- Beprövad stabilitet för att skala från tiotals till miljontals jobb utan stilleståndstid
- ”Jobs-as-Code”-metod för att öka samarbetet mellan utveckling och drift
- Förenklade arbetsflöden i hybrid- och multicloudmiljöer
- Säker, integrerad, intelligent filöverföring och synlighet
#4. Datacoral
Datacoral är en ledande leverantör av en omfattande datainfrastruktur för big data. Den kan samla in data från olika källor i realtid utan manuellt ingrepp. När du har samlat in data organiserar den automatiskt denna data i en sökmotor efter eget val.
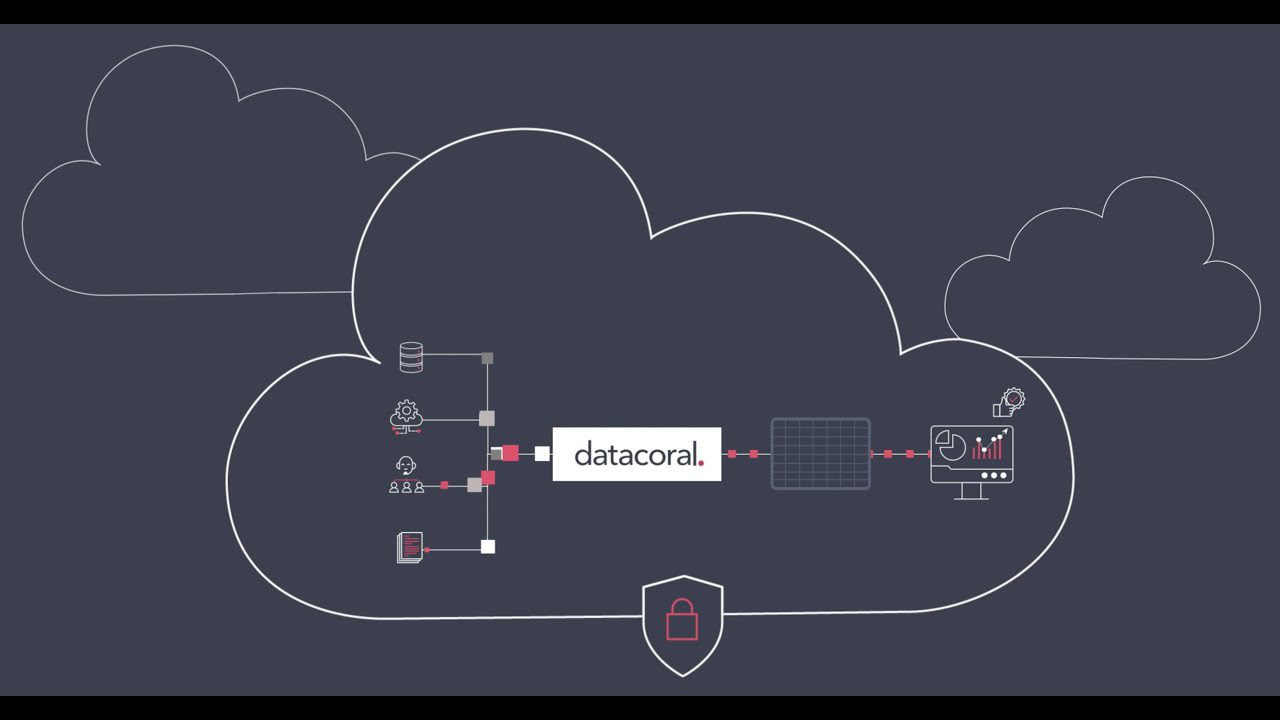
Efter att ha fått värdefulla insikter kan du använda den här informationen för olika ändamål och publicera den. Språket är datafokuserat, vilket möjliggör realtidsåtkomst till datakällor för alla frågemotorer. Det fungerar också som ett verktyg för att övervaka datans aktualitet och säkerställa dataintegritet, vilket gör det till en idealisk lösning om du behöver tillförlitlig och effektiv datahantering.
Nyckelfunktioner
- Kodfria datakontakter för säker och pålitlig dataåtkomst
- Metadata-första arkitektur för en komplett datavy
- Anpassningsbar dataextraktion med full insyn i datans aktualitet och kvalitet
- Säker installation i din VPC
- Datakvalitetskontroller direkt från paketet
- CDC-anslutningar för databaser som PostgreSQL och MySQL
- Byggd för skalbarhet med ett förenklat ramverk för molnbaserade dataintegrationer och pipelines
#5. Dagster
Dagster är en nästa generations orkestreringsplattform med öppen källkod för utveckling, produktion och övervakning av datatillgångar.

Verktyget har en ny syn på datateknik och täcker hela utvecklingslivscykeln, från initial utveckling och driftsättning till kontinuerlig övervakning och observerbarhet. Dagster är en komplett och allomfattande lösning om du behöver effektiv och pålitlig datahantering.
Nyckelfunktioner
- Ger integrerad härstamning och observerbarhet
- Använder en deklarativ programmeringsmodell för enklare arbetsflödeshantering
- Erbjuder den bästa testbarheten för pålitliga och exakta arbetsflöden
- Dagster Cloud för serverlösa eller hybridinstallationer, ”native branching” och CI/CD
- Integreras med de verktyg du redan använder och kan distribueras till din infrastruktur
Slutsats
Dataorkestrering är ett utmärkt sätt att effektivisera och optimera hela datahanteringsprocessen. Det förenklar hur företag hanterar sin data, från att samla in och förbereda den till att analysera och använda den effektivt.
Dataorkestrering ger företag möjlighet att samarbeta smidigt med olika datakällor, applikationer och team. Som ett resultat kommer du att uppleva snabbare, mer exakt beslutsfattande, förbättrad produktivitet och förbättrad övergripande prestanda.
Välj därför något av ovanstående dataorkestreringsverktyg baserat på dina preferenser och krav och dra nytta av fördelarna.
Du kan också utforska olika verktyg för containerorkestrering för DevOps