Grunderna i webbskrapning och varför Python är ett bra val
Webbskrapning, eller dataskrapning, innebär att automatiskt hämta information från webbsidor och använda den för olika ändamål. Tänk dig att du behöver extrahera en tabell från en webbplats, konvertera den till JSON-format och sedan använda dessa JSON-data för att skapa interna verktyg. Webbskrapning gör just detta möjligt genom att selektivt hämta önskade element från webbsidor. Att använda Python för webbskrapning är ett populärt alternativ, eftersom Python erbjuder flera effektiva bibliotek, som BeautifulSoup och Scrapy, för att hantera dataextraktion.
Som utvecklare eller dataforskare är förmågan att effektivt extrahera data mycket värdefull. Denna artikel ger dig en förståelse för hur du kan skrapa webbsidor på ett effektivt sätt och skaffa den information du behöver för att sedan bearbeta den efter dina specifika behov. I den här guiden kommer vi att fokusera på att använda biblioteket BeautifulSoup, ett vanligt använt verktyg för webbskrapning i Python.
Varför Python för webbskrapning?
Python är ett populärt val bland utvecklare för att skapa webbskrapningsverktyg. Det finns flera skäl till detta, men vi ska titta närmare på tre huvudargument:
Omfattande bibliotek och aktiv community: Python har ett rikt utbud av bibliotek som underlättar webbskrapning, till exempel BeautifulSoup, Scrapy och Selenium. Dessa bibliotek erbjuder avancerade funktioner för att effektivt skrapa webbsidor. Dessutom finns det ett stort och aktivt Python-community, vilket gör det lätt att hitta hjälp när du stöter på problem.
Automatisering: Python är känt för sina starka automatiseringsmöjligheter. Om du utvecklar ett mer komplext verktyg som bygger på webbskrapning, kan du enkelt lägga till automatiserade processer. Ett bra exempel är ett verktyg som spårar priserna på produkter i en webbutik dagligen och lägger till denna information i en databas. Python ger dig verktygen för att automatisera sådana processer med lätthet.
Datahantering och visualisering: Webbskrapning används ofta av dataforskare, som ofta behöver extrahera data från webbsidor. Med hjälp av bibliotek som Pandas kan Python enkelt hantera och visualisera data som har extraherats från webbsidor.
Populära Python-bibliotek för webbskrapning
Det finns ett flertal bibliotek i Python som gör webbskrapning enklare. Vi ska gå igenom tre av de mest använda:
#1. BeautifulSoup
BeautifulSoup är ett mycket omtyckt bibliotek för webbskrapning som har hjälpt utvecklare sedan 2004. Det erbjuder enkla metoder för att navigera, söka och ändra i HTML-strukturer. Dessutom hanterar BeautifulSoup kodningen av inkommande och utgående data. Det är ett väletablerat bibliotek med en stor community.
#2. Scrapy
Scrapy är ett annat populärt ramverk för dataextraktion som är omtyckt och väl utvecklat. Det kan användas för att skrapa data från både webbsidor och API:er, och har dessutom inbyggda funktioner som att skicka e-post.
#3. Selenium
Selenium är primärt ett bibliotek för att automatisera webbläsare, men det kan även användas för webbskrapning. Det använder WebDriver-protokollet för att styra olika webbläsare och har funnits på marknaden i nästan 20 år. Med Selenium kan du automatisera processer och skrapa data från webbsidor.
Utmaningar med webbskrapning i Python
Det finns ett antal utmaningar som man kan stöta på vid webbskrapning. Problem som långsamma nätverk, anti-skrapningsverktyg, IP-baserad blockering och captcha-blockering kan skapa hinder. Dessa problem kan allvarligt försvåra skrapningsprocessen.
Man kan dock kringgå dessa utmaningar genom att använda vissa metoder. En webbplats kan blockera en IP-adress om den får ett stort antal förfrågningar inom en kort tidsperiod. För att undvika detta kan man programmera skrapan så att den gör pauser mellan förfrågningarna.
Utvecklare använder ibland så kallade ”honungsfällor” för att fånga skrapor. Dessa fällor är ofta osynliga för det mänskliga ögat, men kan upptäckas av skrapor. Om du skrapar en webbplats som använder en sådan fälla, måste du programmera din skrapa på ett sätt som hanterar det.
Captcha-verifieringar utgör också en utmaning. Många webbplatser använder captcha för att skydda sig mot automatiserade bots. I dessa fall kan det vara nödvändigt att använda en captcha-lösare.
Skrapa en webbsida med Python – Ett praktiskt exempel
Vi kommer att använda BeautifulSoup för att skrapa data. I den här guiden kommer vi att skrapa historisk data för Ethereum från CoinGecko och lagra tabellinformationen i en JSON-fil. Vi börjar med att bygga skrapan.
Först måste vi installera BeautifulSoup och Requests. För den här guiden kommer jag att använda Pipenv. Pipenv är en verktyg för att hantera virtuella miljöer i Python. Du kan också använda Venv, men jag föredrar Pipenv. En diskussion om Pipenv ligger utanför den här guiden, men du kan följa den här guiden om du vill lära dig mer. Eller, om du är intresserad av Python-miljöer, ta en titt här.
Starta ett Pipenv-skal i din projektkatalog med kommandot `pipenv shell`. Detta startar ett underskal i din virtuella miljö. För att installera BeautifulSoup, använd kommandot:
pipenv install beautifulsoup4
För att installera requests, använd kommandot:
pipenv install requests
När installationerna är klara, importera de nödvändiga paketen i huvudfilen. Skapa en fil `main.py` och importera paketen enligt nedan:
from bs4 import BeautifulSoup import requests import json
Nästa steg är att hämta innehållet från sidan med historisk data och analysera det med HTML-tolken som finns i BeautifulSoup.
r = requests.get('https://www.coingecko.com/en/coins/ethereum/historical_data#panel')
soup = BeautifulSoup(r.content, 'html.parser')
I koden ovan används `get`-metoden från biblioteket `requests` för att nå webbsidan. Det analyserade innehållet lagras sedan i en variabel som kallas `soup`.
Den faktiska skrapningen börjar här. Först måste du identifiera tabellen i DOM. Om du inspekterar sidan med webbläsarens utvecklarverktyg, ser du att tabellen har klasserna `table table-striped text-sm text-lg-normal`.
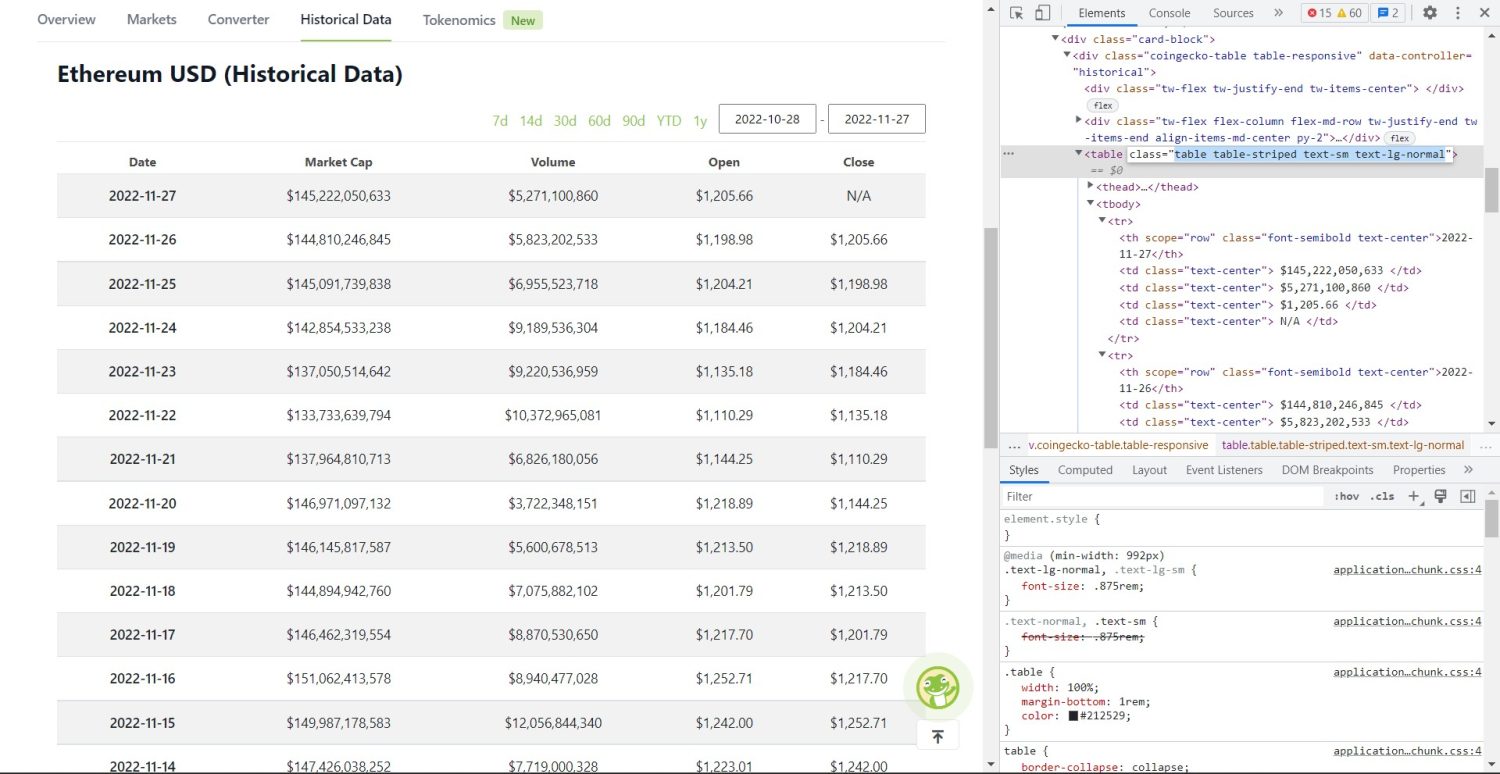 Coingecko Ethereum Historisk datatabell
Coingecko Ethereum Historisk datatabell
Du kan använda `find`-metoden för att identifiera tabellen:
table = soup.find('table', attrs={'class': 'table table-striped text-sm text-lg-normal'})
table_data = table.find_all('tr')
table_headings = []
for th in table_data[0].find_all('th'):
table_headings.append(th.text)
I ovanstående kod hittas tabellen med `soup.find`-metoden och sedan används `find_all`-metoden för att söka efter alla `tr`-element i tabellen. Dessa lagras i variabeln `table_data`. Tabellen har en rad med kolumnrubriker. En ny variabel som heter `table_headings` initieras för att lagra dessa rubriker i en lista.
En loop körs sedan över den första raden i tabellen. I den raden genomsöks alla `th`-element och deras textvärden läggs till i listan `table_headings`. Texten extraheras med hjälp av `text`-metoden. Om du nu skriver ut variabeln `table_headings`, kommer du att se:
['Date', 'Market Cap', 'Volume', 'Open', 'Close']
Nästa steg är att skrapa resten av informationen, skapa en dictionary för varje rad och lägga till dessa i en lista:
table_details = []
for tr in table_data:
th = tr.find_all('th')
td = tr.find_all('td')
data = {}
for i in range(len(td)):
if th:
data.update({table_headings[0]: th[0].text})
data.update({table_headings[i+1]: td[i].text.replace('\n', '')})
if data.__len__() > 0:
table_details.append(data)
Detta är den viktigaste delen av koden. För varje `tr` i variabeln `table_data` söks `th`-elementen. Dessa `th`-element innehåller datumen som visas i tabellen och lagras i variabeln `th`. På samma sätt lagras alla `td`-element i variabeln `td`.
En tom dictionary, `data`, initieras. Efter initieringen går vi igenom intervallet med `td`-elementen. För varje rad uppdaterar vi först det första fältet i dictionaryn med den första posten i `th`. Koden `table_headings[0]: th[0].text` tilldelar ett nyckel-värdepar med datum och den första element.
Efter initialiseringen av det första elementet tilldelas de övriga elementen med hjälp av `data.update({table_headings[i+1]: td[i].text.replace(’\n’, ”)})`. Här extraheras `td`-elementets text med `text`-metoden och alla `\n`-tecken ersätts med `replace`-metoden. Värdet tilldelas sedan det `i+1`:a elementet i `table_headings`, eftersom det `i`:te elementet redan har tilldelats.
Sedan, om dictionaryn `data` har en längd som är större än noll, lägger vi till den i listan `table_details`. Du kan skriva ut `table_details` för att kontrollera. Men vi kommer att lagra värdena i en JSON-fil, vilket görs med följande kod:
with open('table.json', 'w') as f:
json.dump(table_details, f, indent=2)
print('Data saved to json file...')
Här använder vi `json.dump`-metoden för att skriva värdena i en JSON-fil med namnet `table.json`. När skrivningen är klar skriver vi ut `Data saved to json file…` i konsolen.
Kör nu filen med kommandot:
python main.py
Efter en stund kommer du att se texten `Data saved to json file…` i konsolen. Du kommer även att hitta en ny fil med namnet `table.json` i arbetskatalogen. Filen kommer att se ut ungefär så här:
[
{
"Date": "2022-11-27",
"Market Cap": "$145,222,050,633",
"Volume": "$5,271,100,860",
"Open": "$1,205.66",
"Close": "N/A"
},
{
"Date": "2022-11-26",
"Market Cap": "$144,810,246,845",
"Volume": "$5,823,202,533",
"Open": "$1,198.98",
"Close": "$1,205.66"
},
{
"Date": "2022-11-25",
"Market Cap": "$145,091,739,838",
"Volume": "$6,955,523,718",
"Open": "$1,204.21",
"Close": "$1,198.98"
},
// ...
// ...
]
Du har nu lyckats implementera en webbskrapa med Python! Om du vill se hela koden kan du besöka detta GitHub-repo.
Sammanfattning
I den här artikeln har vi gått igenom hur du kan implementera en enkel webbskrapa med Python. Vi har förklarat hur BeautifulSoup kan användas för att snabbt skrapa data från webbplatser. Vi har också diskuterat andra bibliotek som finns tillgängliga och varför Python är ett populärt förstahandsval för många utvecklare som vill skrapa webbplatser.
Du kan också utforska andra ramverk för webbskrapning.