Syntetisk Data: En Nyckelresurs i Dagens Dataanalys
I den moderna världen har data blivit en ovärderlig tillgång, avgörande för att utveckla avancerade maskininlärningsmodeller, rigoröst testa applikationer och generera betydelsefulla insikter för affärsverksamheten.
Men tillgången till data är ofta begränsad av strikta regelverk och integritetsbestämmelser. Att få nödvändiga godkännanden för att använda känslig data kan vara en tidskrävande process som sträcker sig över flera månader. Ett alternativ som växer i popularitet är att generera och använda syntetisk data.
Vad är egentligen syntetisk data?
Bildkälla: Twinify
Syntetisk data definieras som artificiellt framställd data, vars statistiska egenskaper liknar en befintlig, verklig datamängd. Denna typ av data kan antingen komplettera riktig data för att förstärka och förbättra AI-modeller eller fungera som en fullständig ersättning.
Eftersom syntetisk data inte är knuten till någon specifik individ och inte innehåller personlig information såsom personnummer, representerar den ett säkert alternativ till att använda riktig data, vilket skyddar användarnas integritet.
Skillnader mellan riktig och syntetisk data
- Den mest grundläggande skillnaden är hur de skapas. Riktig data härstammar från observationer eller interaktioner med verkliga individer, till exempel genom undersökningar eller användning av applikationer. Syntetisk data däremot, genereras på konstgjord väg, men behåller likheten med den ursprungliga datamängden.
- Den andra skillnaden ligger i de lagar och regler som styr dataskyddet. Riktig data är underställd strikta bestämmelser som ger individer rätt att veta vilken data som samlas in om dem och hur den används. Syntetisk data undantas dessa bestämmelser eftersom den inte kan kopplas till enskilda individer och inte innehåller personligt identifierbar information.
- En tredje skillnad är mängden tillgänglig data. Med riktig data är tillgången begränsad till den mängd data som användarna genererar. Syntetisk data kan genereras i obegränsad mängd, vilket ger större flexibilitet.
Varför bör du överväga att använda syntetisk data?
- Produktion av syntetisk data är i regel mer kostnadseffektivt, eftersom det är möjligt att skapa mycket stora datamängder som speglar mindre, befintliga data. Det ger dina maskininlärningsmodeller tillgång till mer träningsdata.
- Den genererade informationen är automatiskt märkt och renad, vilket sparar tid och ansträngning för databearbetning inför maskininlärning och analys.
- Det finns inga integritetsproblem, eftersom den syntetiska datan är fri från personlig identifierbar information och inte kan knytas till någon individ. Det betyder att den kan användas och delas fritt.
- Genom att se till att minoritetsgrupper är väl representerade, kan man motverka AI-bias. Detta bidrar till en rättvis och ansvarsfull AI-utveckling.
Hur man genererar syntetisk data
Genereringsprocessen varierar beroende på verktyg men börjar vanligtvis med att en generator ansluts till en befintlig datamängd. Därefter identifieras personligt identifierbara fält i datan och markeras för att uteslutas eller anonymiseras.
Generatorn identifierar sedan datatyper och statistiska mönster i de återstående kolumnerna. Därefter kan du generera önskad mängd syntetisk data.
Det är vanligt att jämföra den genererade datan med den ursprungliga för att bedöma hur väl den syntetiska datan återspeglar den verkliga.
Låt oss nu utforska några verktyg som kan hjälpa dig att generera syntetisk data för att träna dina maskininlärningsmodeller.
Mostly AI
Mostly AI erbjuder en AI-driven generator för syntetisk data som lär sig av de statistiska mönstren i den ursprungliga datamängden. AI:n skapar sedan fiktiva data som överensstämmer med de inlärda mönstren.
Med Mostly AI kan du generera hela databaser med referensintegritet och syntetisera data av olika typer för att förbättra dina AI-modeller.
Synthesized.io

Synthesized.io används av flera ledande företag för sina AI-projekt. För att använda tjänsten definierar du dina datakrav i en YAML-konfigurationsfil.
Sedan skapar du ett jobb som körs som en del av en datapipeline. Synthesized.io har en generös gratisversion som låter dig experimentera och avgöra om den passar dina behov.
YData

YData ger dig möjlighet att generera data i form av tabeller, tidsserier, transaktioner samt data över flera tabeller och relationer. Detta hjälper dig att undvika problem med insamling, delning och kvalitet.
YData erbjuder en AI och SDK för att interagera med plattformen. De har även en gratisversion där du kan prova tjänsten.
Gretel AI

Gretel AI erbjuder API:er för att generera obegränsade mängder syntetisk data. De tillhandahåller också en datagenerator med öppen källkod som du kan installera och använda lokalt.
Alternativt kan du använda deras REST API eller CLI, vilket medför en kostnad. Prissättningen är dock rimlig och anpassas till verksamhetens storlek.
Copulas
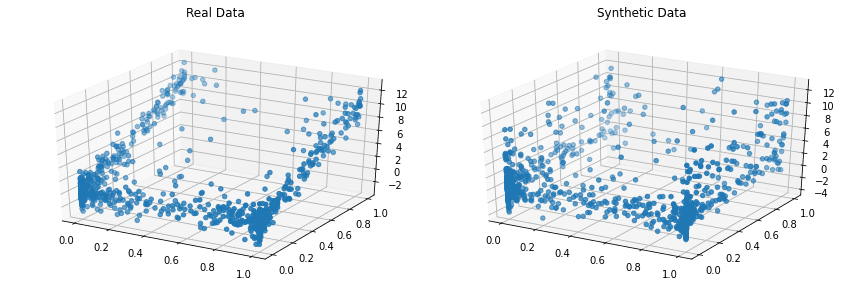
Copulas är ett Python-bibliotek med öppen källkod för modellering av multivariata fördelningar genom copula-funktioner. Det kan även generera syntetisk data som följer samma statistiska egenskaper.
Projektet påbörjades 2018 vid MIT som en del av ”Synthetic Data Vault Project”.
CTGAN
CTGAN består av generatorer som kan lära sig från envärdesdata och generera syntetisk data baserat på de mönster som identifierats.
Det är implementerat som ett Python-bibliotek med öppen källkod. CTGAN är liksom Copulas en del av ”Synthetic Data Vault Project”.
DoppelGANger
DoppelGANger är en öppen källkodsimplementering av ”Generative Adversarial Networks” för att generera syntetisk data.
DoppelGANger är särskilt användbar för tidsseriedata och används av företag som Gretel AI. Python-biblioteket är gratis och har öppen källkod.
Synth

Synth är en datagenerator med öppen källkod som hjälper dig att skapa realistisk data enligt dina specifikationer. Den anonymiserar personlig information och skapar testdata för dina applikationer.
Du kan använda Synth för att generera realtids- och relationsdata för maskininlärning. Synth är också databasagnostisk, vilket innebär att den fungerar med SQL- och NoSQL-databaser.
SDV.dev
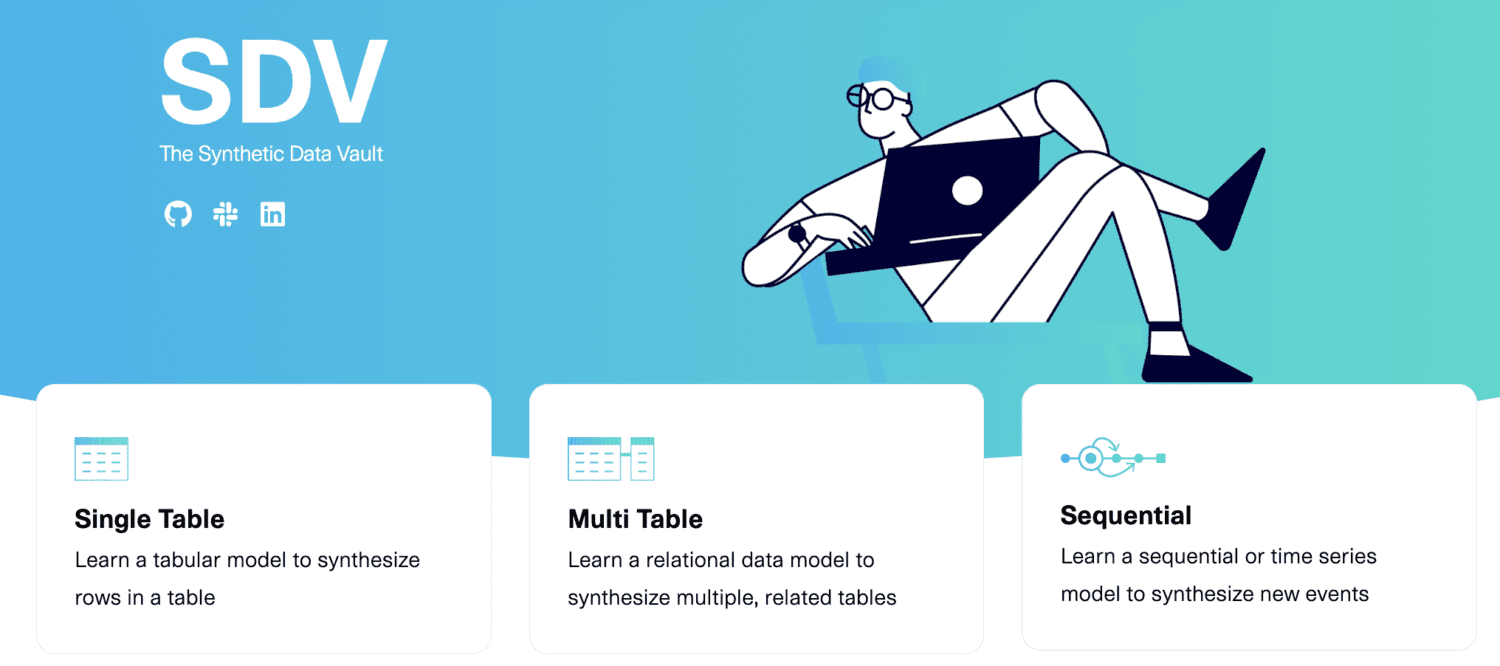
SDV står för ”Synthetic Data Vault”. SDV.dev är ett mjukvaruprojekt som startade vid MIT 2016 och har utvecklat flera verktyg för att generera syntetisk data.
Dessa verktyg inkluderar Copulas, CTGAN, DeepEcho och RDT. De är implementerade som Python-bibliotek med öppen källkod som är enkla att använda.
Tofu
Tofu är ett Python-bibliotek med öppen källkod för att generera syntetisk data som baseras på den brittiska biobankens data. Till skillnad från de tidigare nämnda verktygen genererar Tofu endast data som liknar den från biobanken.
UK Biobank är en studie av fenotypiska och genotypiska egenskaper hos 500 000 medelålders vuxna från Storbritannien.
Twinify
Twinify är en programvara som används som bibliotek eller kommandoradsverktyg för att anonymisera känslig data genom att generera syntetisk data med identiska statistiska fördelningar.

För att använda Twinify laddar du upp den riktiga datan i en CSV-fil. Programvaran lär sig sedan av datan för att skapa en modell som kan användas för att generera syntetisk data. Twinify är helt gratis att använda.
Datanamic
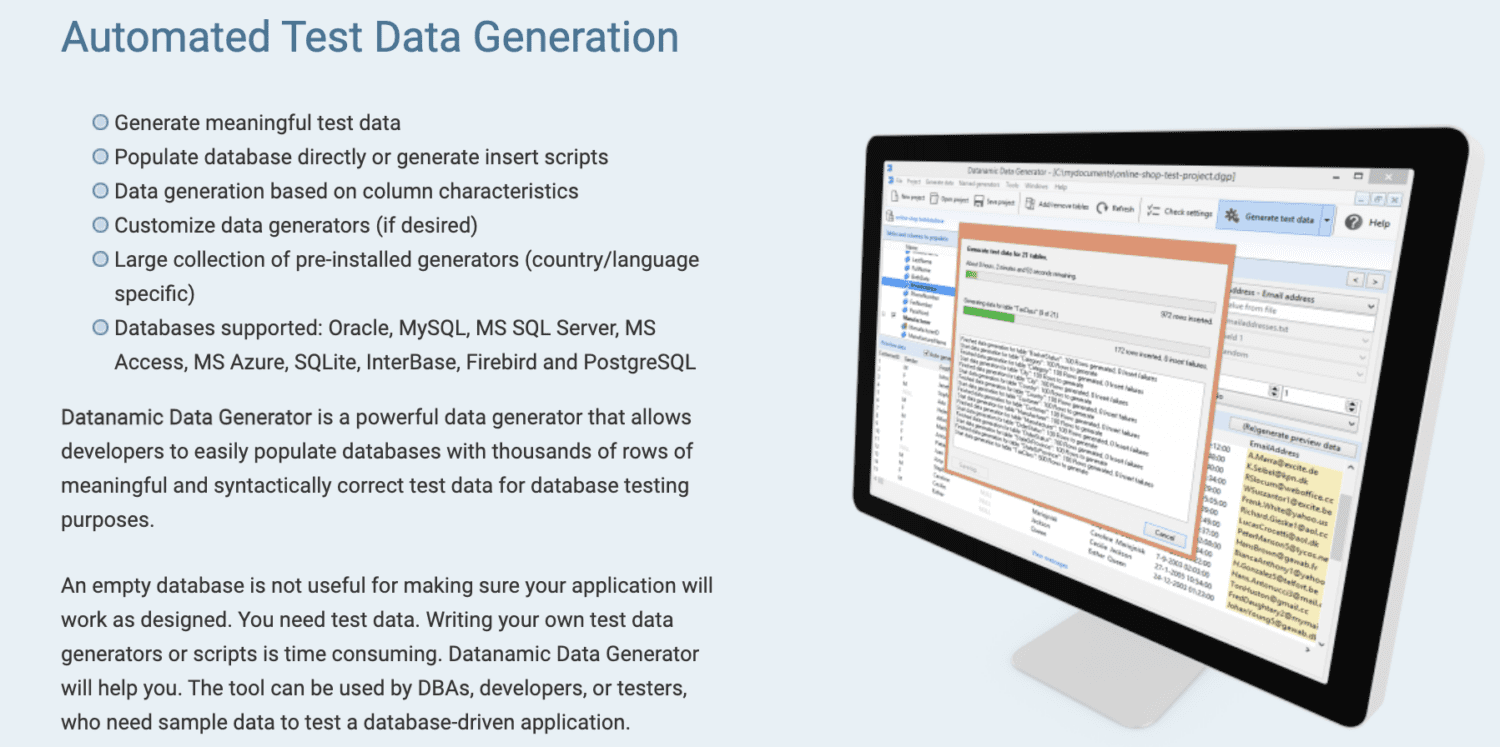
Datanamic hjälper dig att generera testdata för data- och maskininlärningsapplikationer. Datan skapas utifrån kolumnegenskaper som e-postadresser, namn och telefonnummer.
Datanamics generatorer är anpassningsbara och stöder de flesta databaser, som Oracle, MySQL, MS Access och Postgres. Den säkerställer även referensintegriteten i den genererade datan.
Benerator
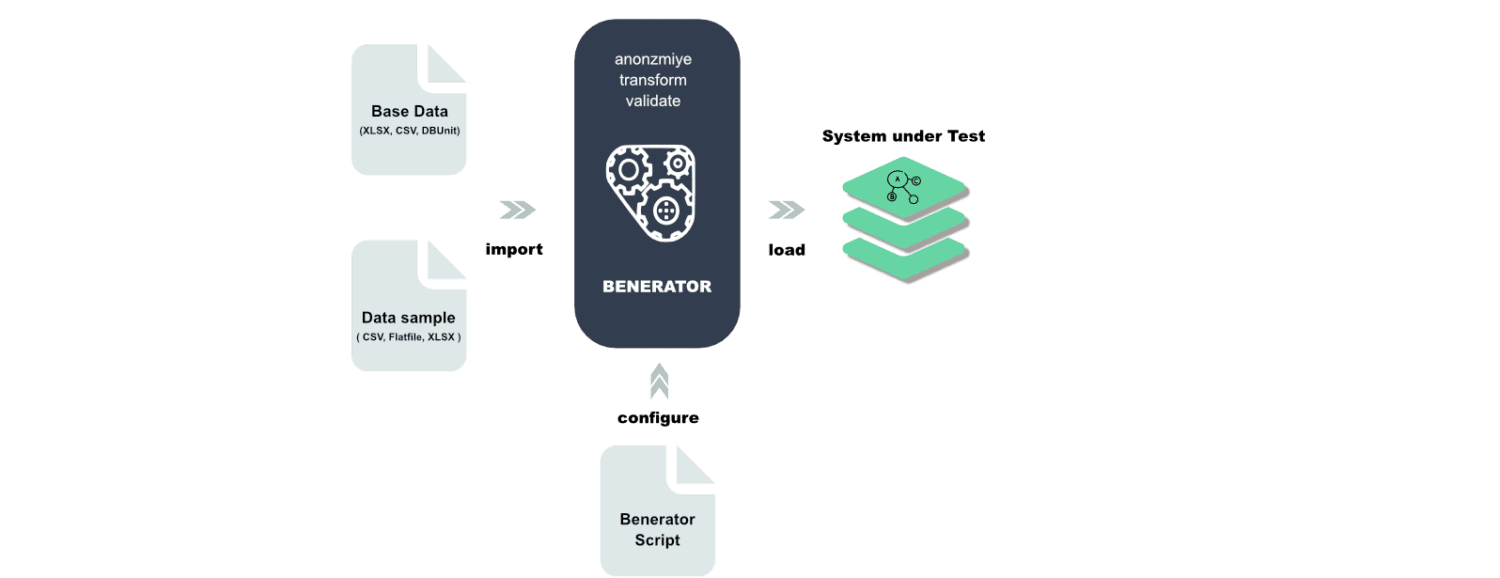
Benerator är en programvara för att anonymisera, generera och migrera data för test- och utbildningsändamål. Du beskriver datan med XML (Extensible Markup Language) och genererar med ett kommandoradsverktyg.
Benerator är utformad för att vara användarvänlig även för icke-utvecklare och kan generera miljarder rader data. Benerator är gratis och har öppen källkod.
Sammanfattning
Gartner uppskattar att år 2030 kommer mer syntetisk data att användas för maskininlärning än riktig data.
Det är inte svårt att förstå varför, med tanke på de höga kostnaderna och integritetsproblemen som är kopplade till användning av riktig data. Det är därför viktigt att företag lär sig mer om syntetisk data och de olika verktyg som finns för att generera den.
Kolla in verktyg för syntetisk övervakning för din onlineverksamhet här.