Amazon Glue ökar i popularitet i takt med att fler företag anammar hanterade tjänster för dataintegration.
Extraktion, transformation och laddning (ETL) är en procedur som flyttar data från en källdatabas till ett datalager. Denna process kan vara komplex och svår att implementera för all företagsdata. Amazon introducerade AWS Glue för att förenkla detta.
Utvecklare av ETL-processer och dataingenjörer använder Glue för att konstruera, kontrollera och utföra ETL-arbetsflöden.
Vad är AWS Glue?
AWS Glue är en serverlös dataintegrationstjänst som förenklar processen att lokalisera, förbereda, flytta och integrera information från varierande källor. Detta är särskilt värdefullt för maskininlärning (ML) och dataanalys.
Tjänsten reducerar avsevärt den tid som krävs för att förbereda data för analys. Den hittar och kategoriserar automatiskt data, genererar Scala- eller Python-kod för dataöverföring och utför laddnings- och transformationsjobb baserat på schemalagda händelser.
Detta möjliggör flexibel planering och genererar en skalbar Apache Spark-miljö för dataladdning. AWS Glue erbjuder också avancerad övervakning av dataströmmar och förändringar. Som en serverlös tjänst förenklar AWS Glue de ofta komplexa aspekterna av applikationsutveckling.
Detta möjliggör en snabb integrering av olika datamängder. Dessutom underlättar det snabb nedbrytning och godkännande av data.
Vad används AWS Glue till?
Det är avgörande att förstå i vilka situationer Amazon Glue är mest användbart. Här är några användningsområden för AWS Glue som kan vara värda att utforska.
- Glue kan användas för att utföra serverlösa frågor på Amazon S3-datasjöar. Amazon Glue är ett utmärkt verktyg för att snabbt komma igång. Det samlar all data på ett ställe och gör det möjligt att analysera informationen utan att flytta den.
- Med Amazon Glue kan du få en överblick över dina datatillgångar. Verktyget gör det enkelt att söka i olika AWS-datauppsättningar via datakatalogen. Dessutom kan du hantera data över flera AWS-tjänster och behålla en enhetlig vy.
- Glue kan vara en nyckelkomponent i skapandet av händelsestyrda ETL-arbetsflöden. Du kan utföra ETL-åtgärder från Amazon S3 genom att använda AWS Lambda-tjänsten för att anropa dina Glue ETL-uppgifter.
- AWS Glue kan även användas för att rengöra, validera, formatera och organisera data innan lagring i en datasjö eller ett datalager.
Vilka delar består AWS Glue av?
Följande är de huvudsakliga komponenterna i AWS Glue:
- Datakatalog: Denna katalog innehåller metadata och datastruktur.
- Databas: Detta är viktigt för att komma åt och konfigurera databasen för både källor och mål.
- Tabell: Skapa en eller flera tabeller i databasen som kan användas av både källan och målet.
- Sökrobot och klassificerare: Sökroboten extraherar data från källan med hjälp av antingen fördefinierade eller anpassade klassificeringar. Den genererar eller använder fördefinierade metadatatabeller i datakatalogen.
- Jobb: Detta är det affärslogiska jobbet som utför en ETL-uppgift. Denna logik är implementerad internt med Apache Spark och använder Python och Scala.
- Trigger: En ETL-trigger startar utförandet av ett ETL-jobb antingen på begäran eller vid en viss tidpunkt.
- Utvecklingsslutpunkt: Detta skapar en miljö för testning, utveckling och felsökning av ETL-jobbskript.
Fördelar med AWS Glue
Här är några av fördelarna med att använda tjänsten i ditt arbete eller inom en organisation.
- AWS Glue använder en sökrobot för att skanna all tillgänglig data.
- Bearbetad data kan lagras på en rad platser (Amazon RDS, Amazon Redshift, Amazon S3, etc.).
- Det är en molnbaserad tjänst, vilket eliminerar behovet av att investera i egen infrastruktur.
- Eftersom det är en serverlös ETL-lösning är den kostnadseffektiv.
- Det är snabbt och levererar omedelbart Python/Scala ETL-kod.
Huvudfunktioner i AWS Glue?
Amazon Glue har alla funktioner som krävs för att integrera data så att du kan få djupare insikter och använda din kunskap för att snabbt göra framsteg. Här är några av de viktigaste funktionerna.
- Dra och släpp-gränssnitt: En jobbredigerare med dra och släpp-funktioner förenklar processen att skapa ETL-processer. AWS Glue bygger direkt den nödvändiga koden för att extrahera, konvertera och ladda upp data.
- Automatisk schemaidentifiering: Använd Glue-tjänsten för att skapa sökrobotar som ansluter till olika datakällor. Den organiserar information och extraherar relevant data. Denna information kan sedan användas för att övervaka ETL-processer via ETL-uppgifter.
- Jobbschemaläggning: Glue kan köras antingen på begäran eller enligt ett förinställt schema. Schemaläggaren kan användas för att skapa komplexa ETL-pipelines med beroenden mellan uppgifter.
- Kodgenerering: Med Glue Elastic Views kan du enkelt bygga materialiserade vyer som kombinerar och replikerar data från olika källor, utan att skriva egen kod.
- Integrerad maskininlärning: Glue levereras med en inbyggd maskininlärningsfunktion kallad ”FindMatches”, som identifierar och tar bort poster som är nästan men inte exakta kopior av varandra.
- Utvecklingsslutpunkter: Om du aktivt utvecklar ETL-kod erbjuder Glue utvecklingsslutpunkter där du kan modifiera, felsöka och testa koden som genererats av systemet.
- Glue DataBrew: Ett verktyg för dataförberedelse som används av dataanalytiker och datavetare för att rensa och normalisera data. Det har ett intuitivt och visuellt gränssnitt.
Hur fungerar AWS Glue-prissättning?
AWS Glue tar ut en timtaxa, debiterad per sekund, för både sökrobotar (dataidentifiering) och ETL-jobb (databehandling och laddning). En fast månadsavgift debiteras för åtkomst till och lagring av metadata i AWS Glue Data Catalog.
Amazon Glue startar på $0,44. Det finns fyra prissättningsmodeller:
- ETL-uppgifter, utvecklingsslutpunkter och andra ETL-uppgifter kostar $0,44.
- Interaktiva sessioner med sökrobotar kostar $0,44.
- DataBrew-jobb börjar på $0,48.
- Månadslagring och förfrågningar till datakatalogen kostar $1,00.
AWS erbjuder inte någon gratisplan för Glue. Varje timme kostar $0,44 per DPU. I genomsnitt skulle det kosta dig cirka 21 USD per dag. Priserna kan variera beroende på var du befinner dig.
Steg för att konfigurera AWS Glue
Datakatalogen kan användas för att snabbt hitta och söka i en mängd AWS-datauppsättningar utan att flytta data. När data har katalogiserats är de omedelbart tillgängliga för sökning och frågor med Amazon Athena och Amazon EMR.
Ref: https://aws.amazon.com/glue/
- Amazon Redshift, Amazon S3, Amazon RDS och databaser på Amazon EC2: Upptäck dina data, lagra metadata och använd AWS Glue Data Catalog.
- AWS Glue Data Catalog: Hantera data med datakatalogen som fungerar som ett centralt register för metadata.
- AWS Glue ETL: Läs och skriv metadata till din datakatalog.
- Amazon Athena och Amazon Redshift, Amazon EMR, Amazon ETL: Hämta datakatalogen för ETL, analyser och mer.
Hur konfigurerar jag AWS Glue?
Börja med att logga in på AWS Management Console och öppna IAM-konsolen. Klicka på ”Skapa roll”. Välj ”Glue” som rolltyp och sedan ”Behörigheter”.
Jag väljer ”AWSGlueServiceRole” för allmänna AWS Glue Studio- och AWS Glue-behörigheter och den AWS-hanterade policyn ”AmazonS3FullAccess” för att få tillgång till Amazon S3-resurser.
Ange ett namn för rollen.
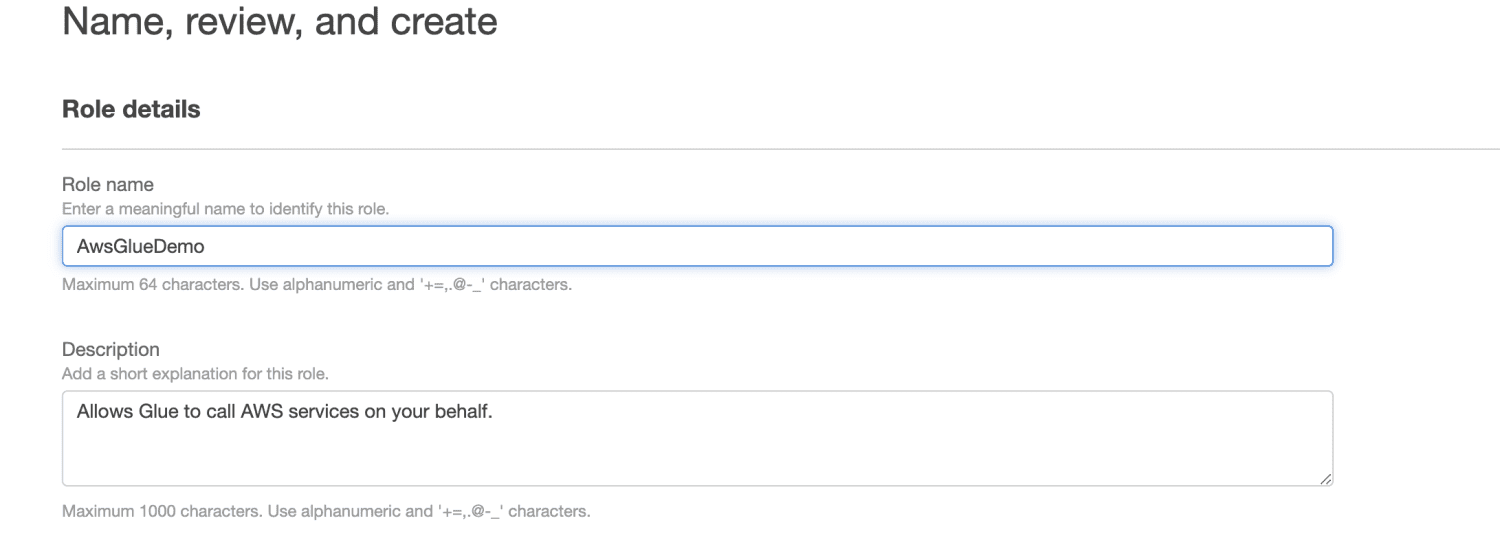
Klicka på ”Skapa roll”.
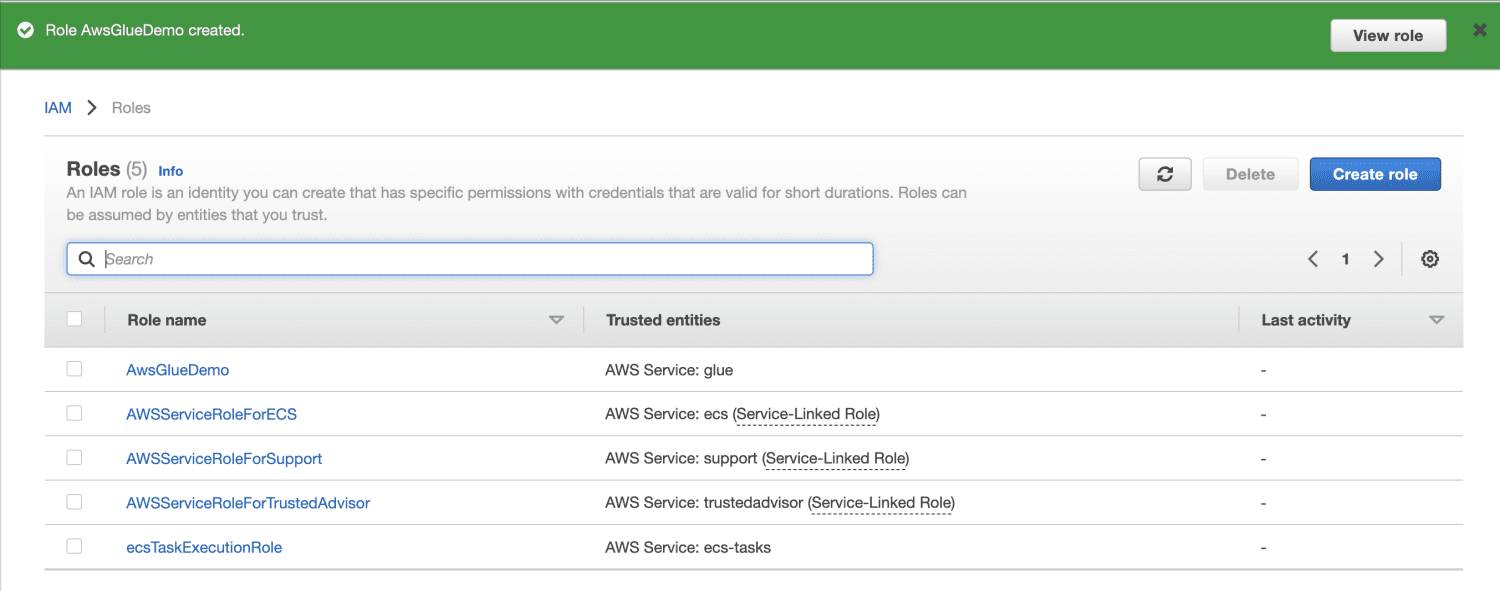
Skapa en Amazon S3-bucket.
Skapa en mapp inuti S3-bucketen.
Välj filen du vill ladda upp.
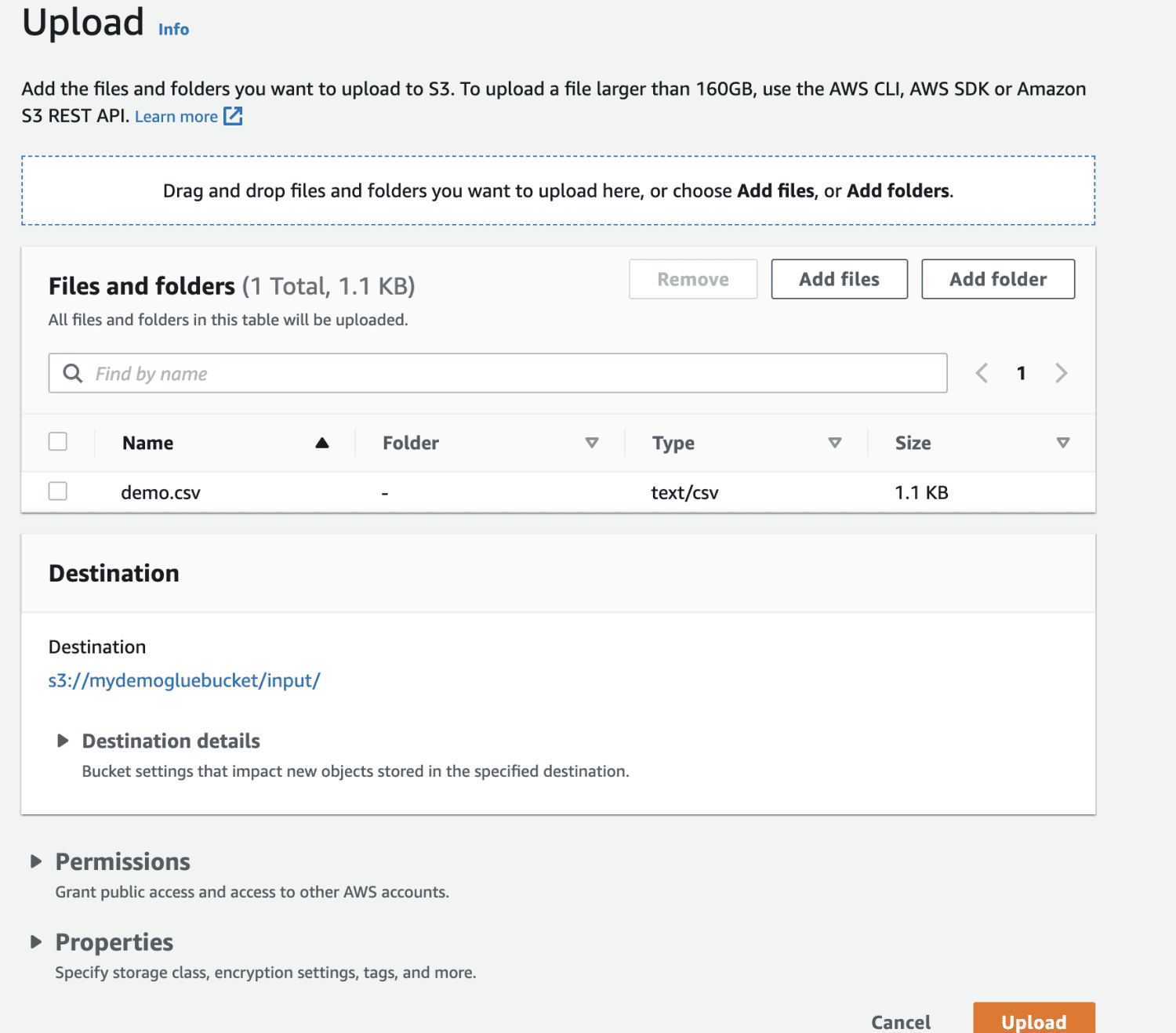
Slutligen, ladda upp filen i bucketen.
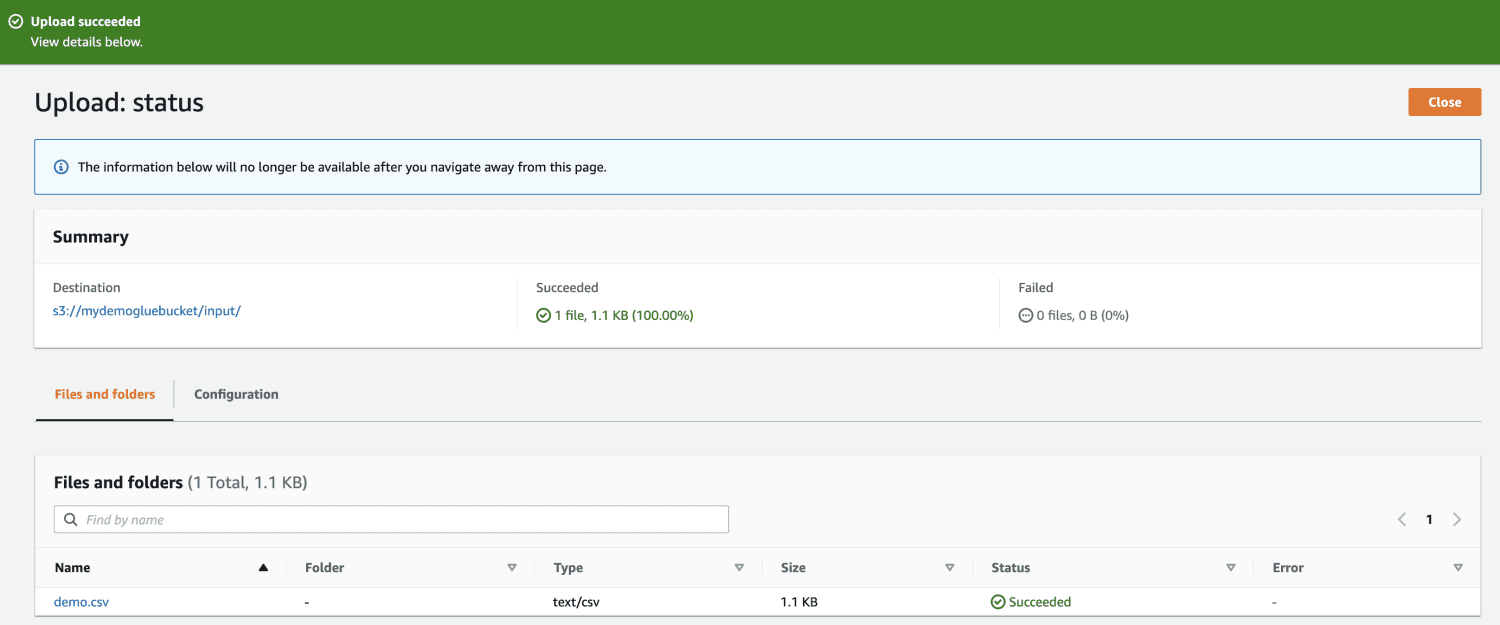
Gå sedan till AWS Glue i AWS-hanteringskonsolen och skapa en databas.
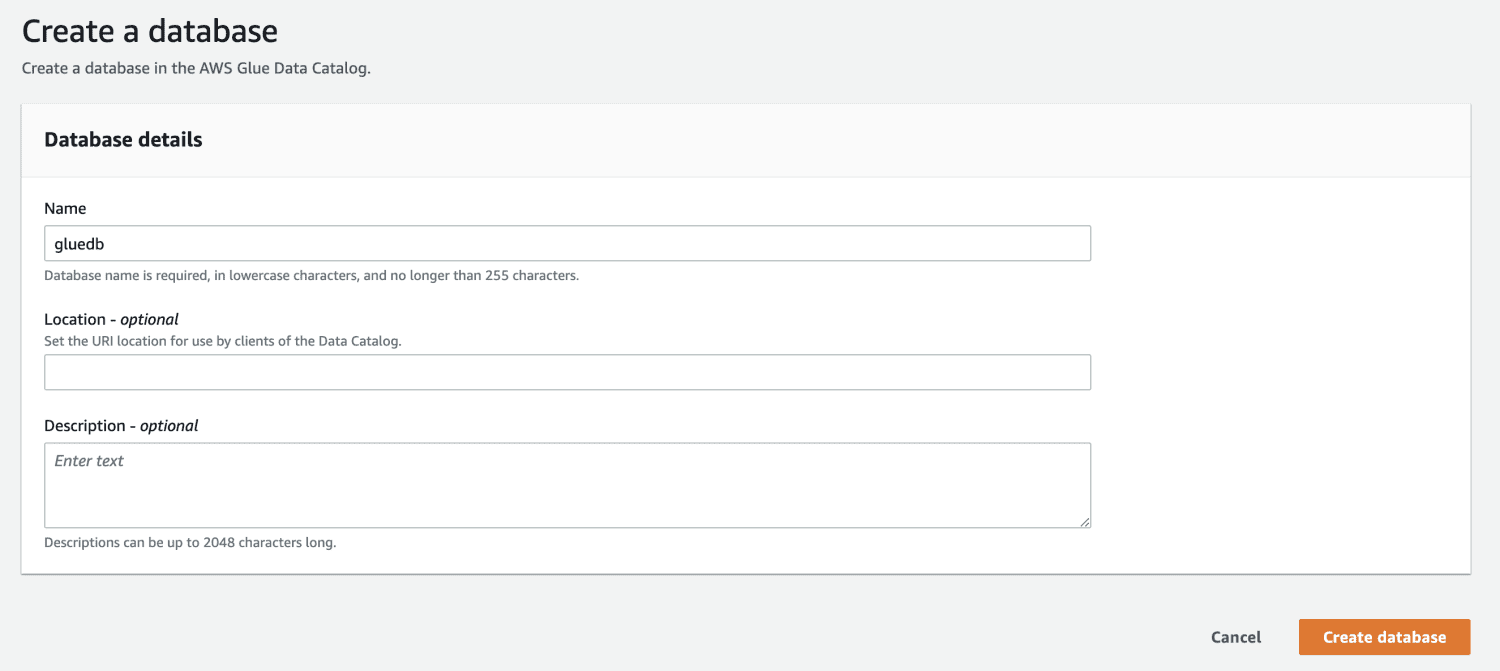
När du har en databas i AWS Glue, skapa en sökrobot.
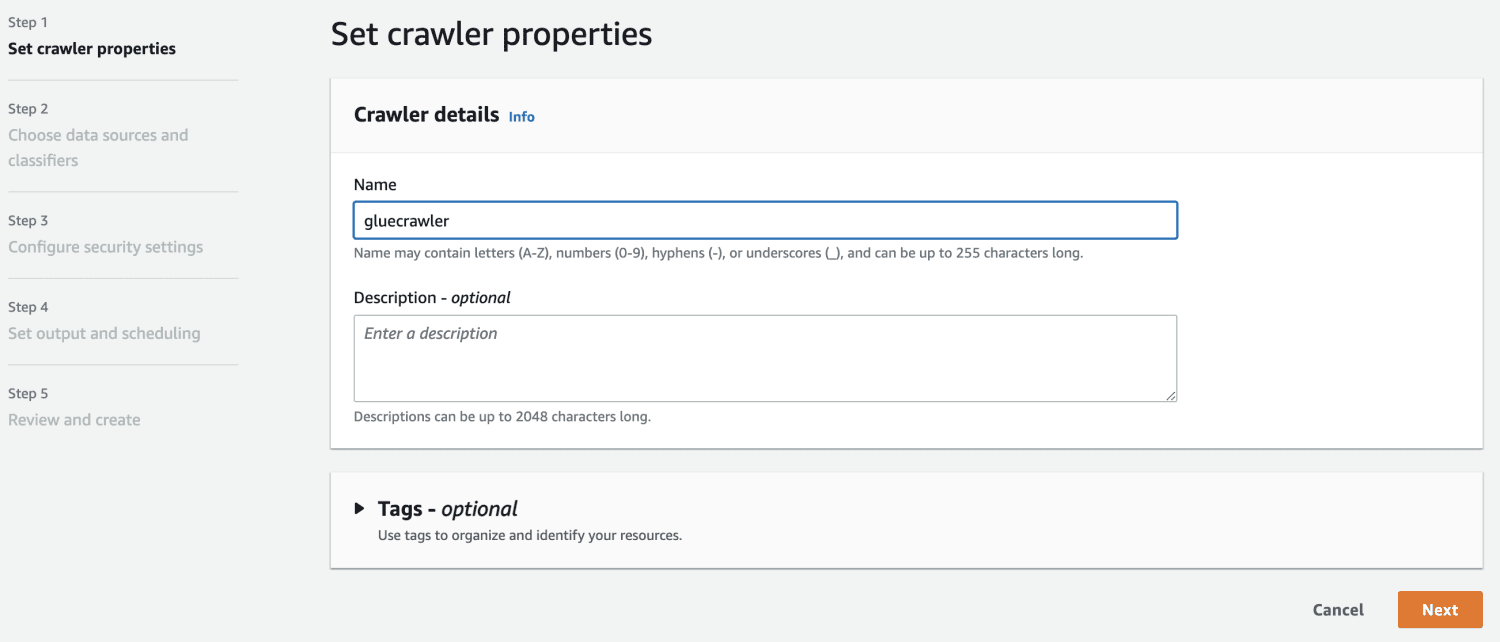
Som datakälla väljer du den S3-bucket du skapade.
Välj sedan den IAM-roll för AWS Glue som du skapade tidigare.
I utdata anger du den gluedb som du skapade.
Kontrollera alla inställningar och skapa sökroboten.
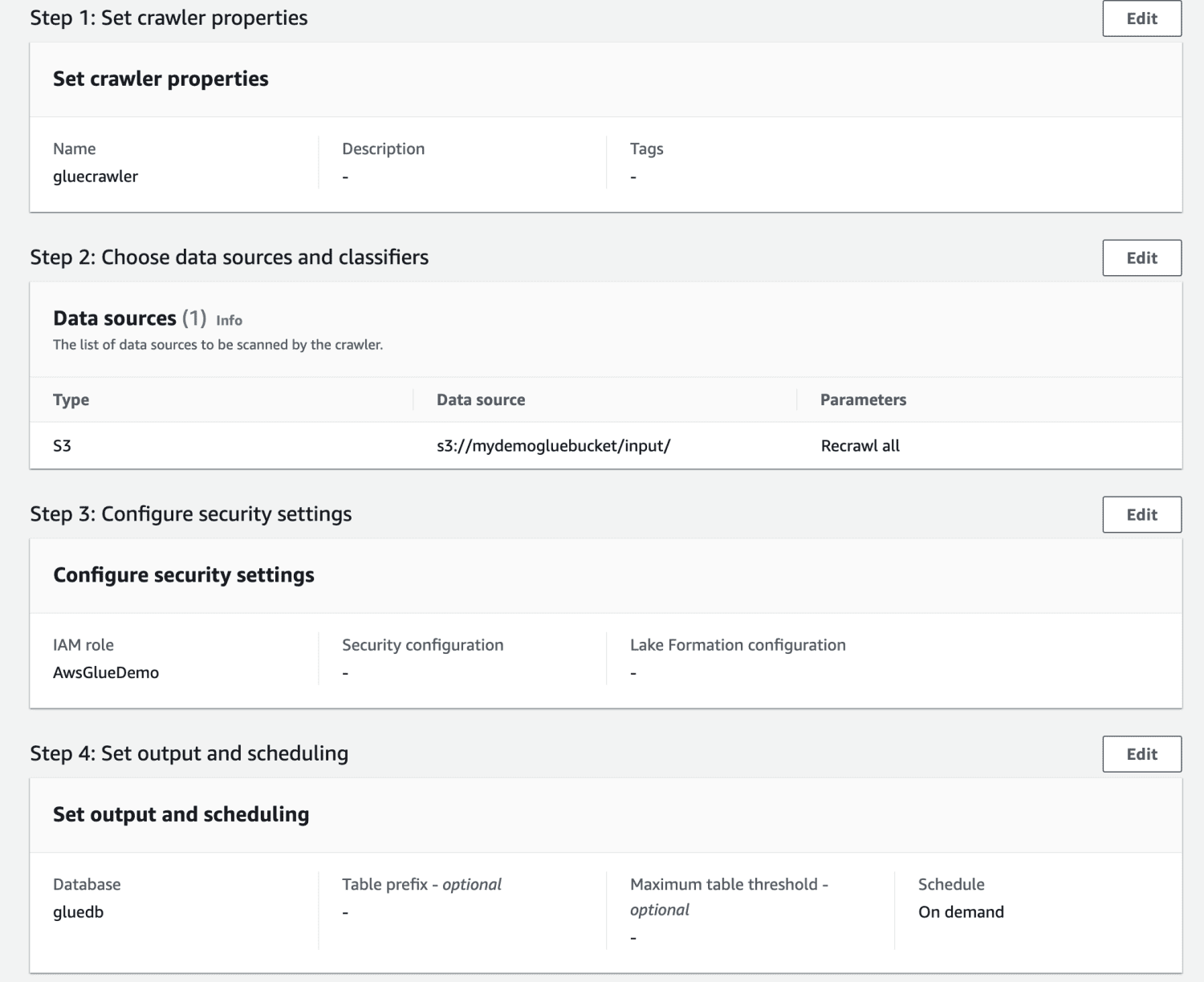
När sökroboten har skapats, markera den och klicka på ”Kör”. Efter en stund kommer statusen att ändras till ”klar”.
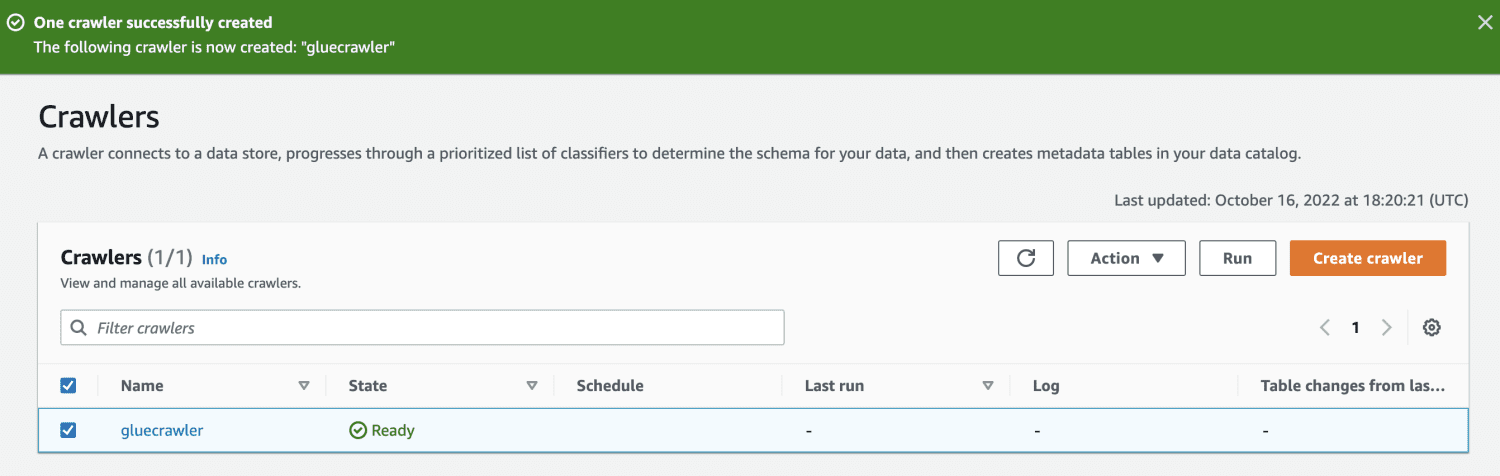
Genom att köra sökroboten skapas en tabell i databasen med all data från CSV-filen.
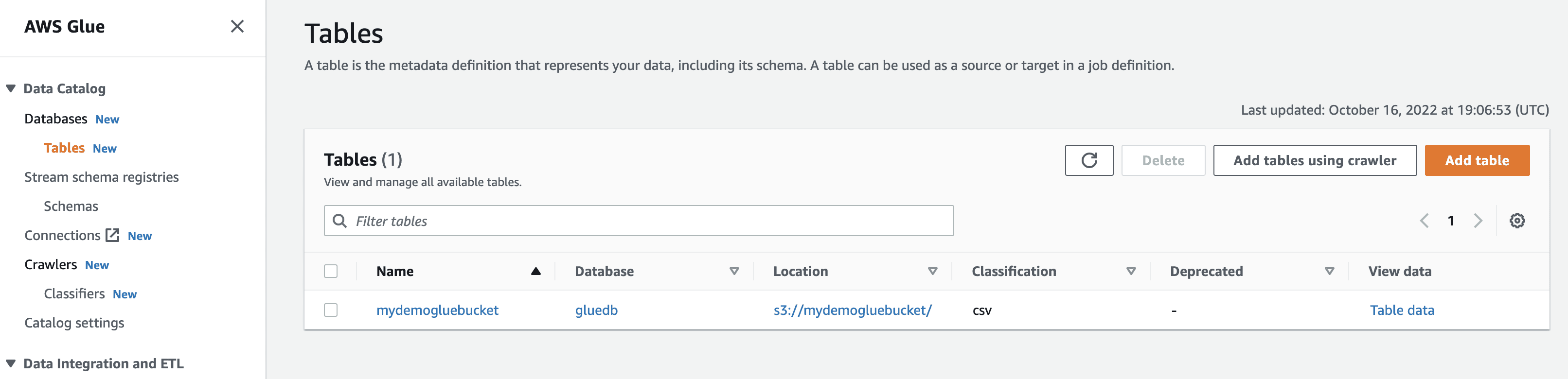
När du klickar på ”visa data” kommer du till Amazon Athena (frågeredigerare). Genom att köra frågan kan du visa tabelldata.
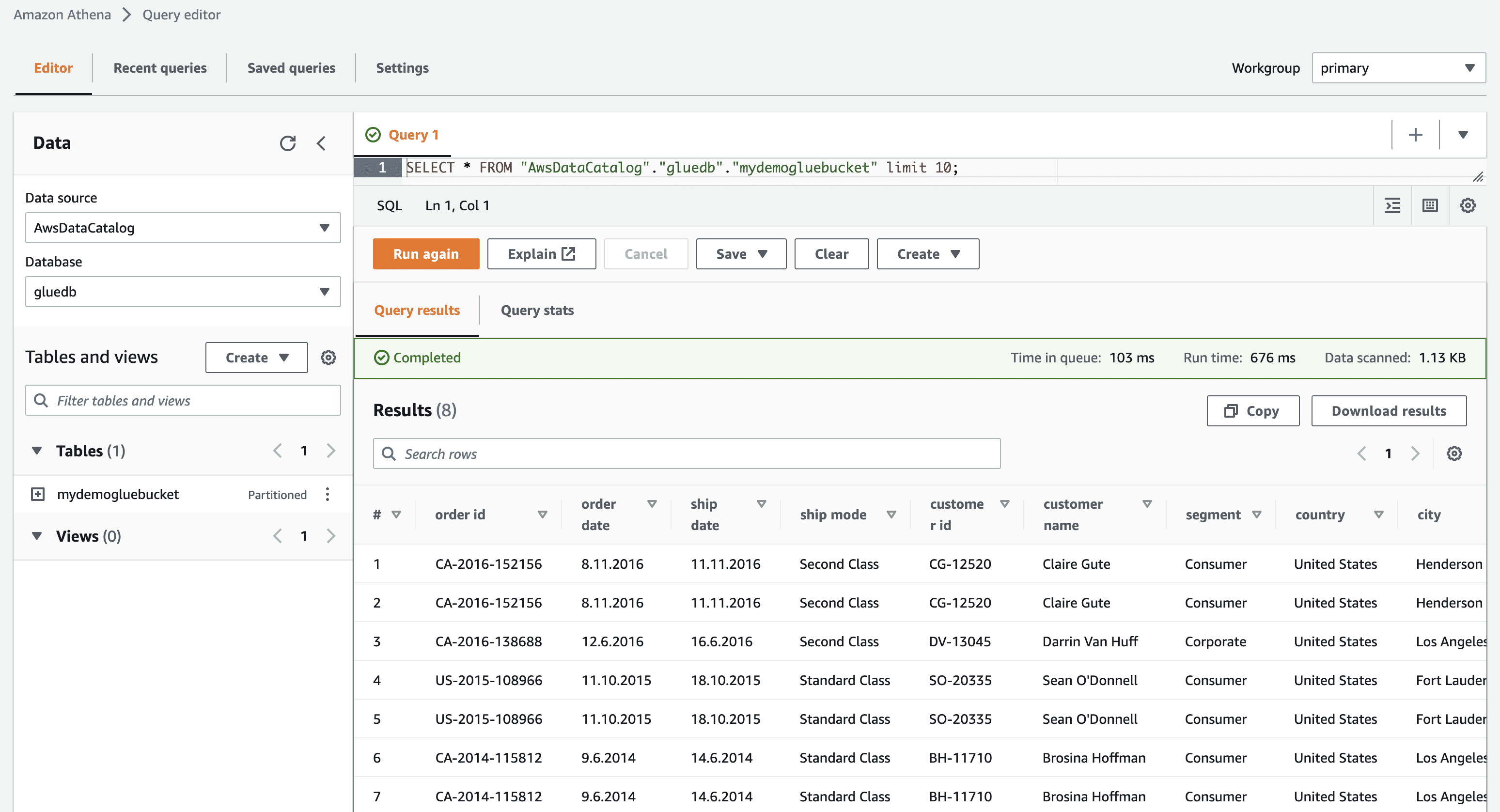
Nu kan du använda denna AWS Glue-crawler i alla ETL-jobb.
Vad är AWS Glue DataBrew?
AWS Glue DataBrew låter användare normalisera och rensa data utan att skriva kod. DataBrew kan minska den tid det tar att förbereda data för maskininlärning och analyser med så mycket som 80 procent jämfört med traditionell dataförberedelse.
Det finns över 250 färdiga datatransformationer som kan användas för att automatisera databeredningsuppgifter som att filtrera bort avvikelser, korrigera ogiltiga värden och konvertera data till standardformat.
DataBrew gör det enklare för datavetare, affärsanalytiker och ingenjörer att samarbeta för att extrahera information från rådata. DataBrew är serverlöst, så du behöver inte hantera infrastruktur eller skapa kluster för att undersöka och omvandla stora mängder rådata.
DataBrew-funktioner för företag
Visualiserad dataförberedelse
DataBrew visualiserar information som vanligtvis visas i kolumndatabaser som alfanumeriska siffror. DataBrew visar alla inlästa datakällor på ett sätt som hjälper dig att förstå datarelationer och hierarki.
250+ databeredningsautomatiseringar
Dataforskare förväntas utföra en rad repeterbara, isolerade arbetsflöden som en del av sitt arbete. AWS har modellerat dessa arbetsflöden och processer som modulära enheter som är oberoende av både språk och datatyp. Detta bibliotek innehåller åtgärder som slutanvändare kan använda.
Data härstamning
I likhet med granskningsloggar som används för att spåra kundaktivitet i ett IT-nätverk, ger datalinje möjligheten att spåra aktiviteter för datatransformationer inom AWS DataBrew. Denna information innehåller datakällan, de transformationer som utförts och datautmatningen, inklusive målplatsen.
Datakartläggning
Med Databrew kan du lokalisera matchande fält i två datakällor. När matchande fält har identifierats kan de laddas in i ett schema.
Fördelar med AWS Glue DataBrew
Här är några av funktionerna i AWS Glue DataBrew:
- Lägre tröskel för dataförberedelse
- Automatisk generering av dataprofil
- Automatisering av över 250 databeredningsprocesser
- Intelligenta rekommendationer för processer
Alternativ till AWS Glue
Airflow
Airflow är ett verktyg för arbetsflödeshantering med öppen källkod. Det stödjer GitHub-stjärnor, gafflar och andra funktioner. Airflow gör det möjligt att bygga arbetsflöden med hjälp av riktade acykliska grafer (DAG). Airflow Scheduler utför dina uppgifter med hjälp av en rad arbetare och följer angivna beroenden.
Matillion

Matillion ETL är ett ETL/ELT-verktyg specifikt designat för molndatabasplattformar som Amazon Redshift och Google BigQuery. Det erbjuder ett modernt webbläsarbaserat användargränssnitt med kraftfulla push-down ETL/ELT-funktioner. Snabb installation gör det enkelt att komma igång.
Stitch
Stitch är en ETL-tjänst med öppen källkod som sammankopplar flera datakällor och replikerar data till de destinationer du väljer. Den är enkel att använda, då det inte krävs några kodningskunskaper för att flytta data. Den har ett användarvänligt gränssnitt och är snabb.
Till skillnad från andra ETL-verktyg låter Stitch dig inte välja en färdig instrumentpanel. Istället måste du integrera dina data i de öppna datalager som du väljer som destination. Detta kan göra inventeringen svår att hantera.
Alteryx

Alteryx är en analysautomatiseringsplattform som hjälper till med förberedelse och blandning av datainsamling. Dessa data kan användas för att påskynda processer och ge affärsinsikter. Eftersom det är ett dra och släpp-verktyg krävs ingen programmeringskunskap. Alteryx är en bra plats för att söka råd och svar från branschfolk.
Slutsats
Detta var en genomgång av AWS Glue, en molnbaserad lösning för hantering av ETL-pipelines. Sammanfattningsvis består användarinteraktionsprocessen i AWS Glue av tre steg. Först använder du datasökrobotar för att skapa en datakatalog. Därefter genereras ETL-koden som krävs för AWS-datapipelines. Slutligen skapas ett ETL-schema. Jag hoppas att denna blogg har gett en bra översikt över Amazon Glue.
Du kan också utforska de bästa tipsen för att säkra AWS S3-lagring.