
En förvirringsmatris är ett verktyg för att utvärdera prestandan för klassificeringstypen av övervakade maskininlärningsalgoritmer.
Innehållsförteckning
Vad är en förvirringsmatris?
Vi människor uppfattar saker olika – till och med sanning och lögner. Det som kan tyckas vara en 10 cm lång linje för mig kan verka som en 9 cm linje för dig. Men det faktiska värdet kan vara 9, 10 eller något annat. Vad vi gissar är det förutsagda värdet!
Hur den mänskliga hjärnan tänker
Precis som vår hjärna använder vår egen logik för att förutsäga något, använder maskiner olika algoritmer (kallade maskininlärningsalgoritmer) för att komma fram till ett förutsagt värde för en fråga. Återigen kan dessa värden vara samma eller olika från det faktiska värdet.
I en konkurrensutsatt värld skulle vi vilja veta om vår förutsägelse är rätt eller inte för att förstå vår prestation. På samma sätt kan vi bestämma en maskininlärningsalgoritms prestanda genom hur många förutsägelser den gjorde korrekt.
Så, vad är en maskininlärningsalgoritm?
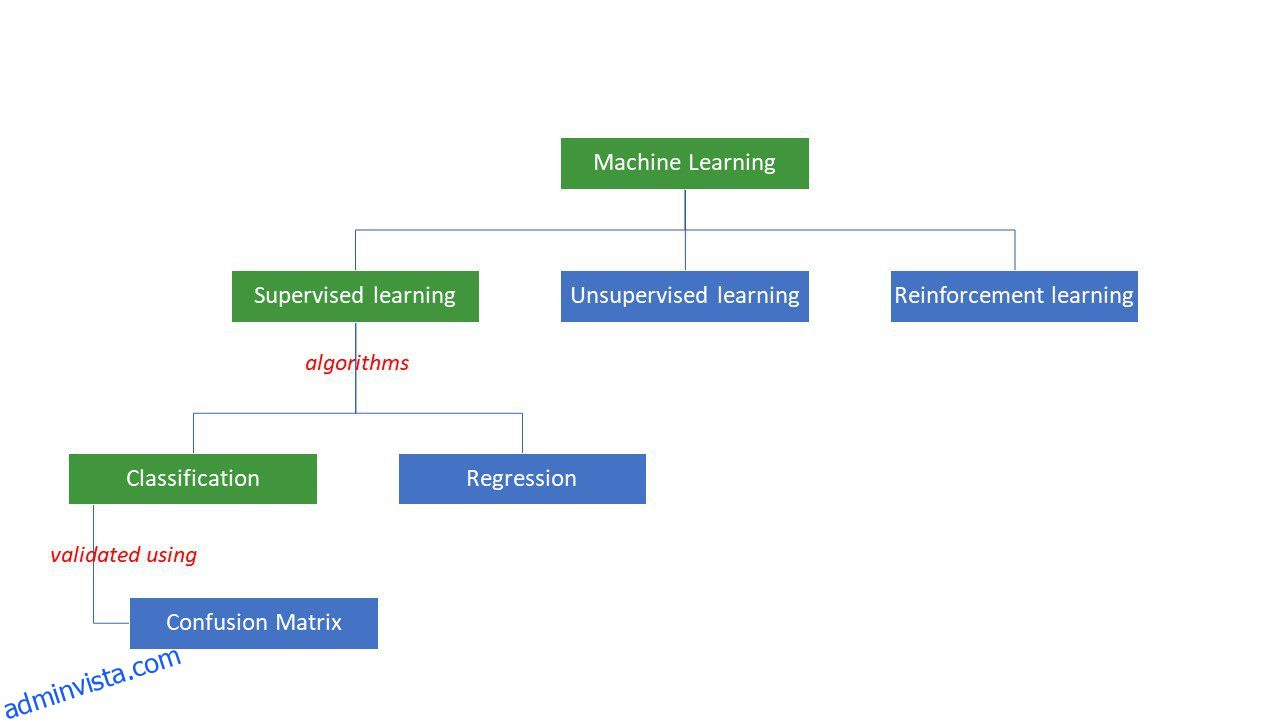
Maskiner försöker komma fram till vissa svar på ett problem genom att tillämpa viss logik eller uppsättning instruktioner, kallade maskininlärningsalgoritmer. Maskininlärningsalgoritmer är av tre typer – övervakad, oövervakad eller förstärkning.
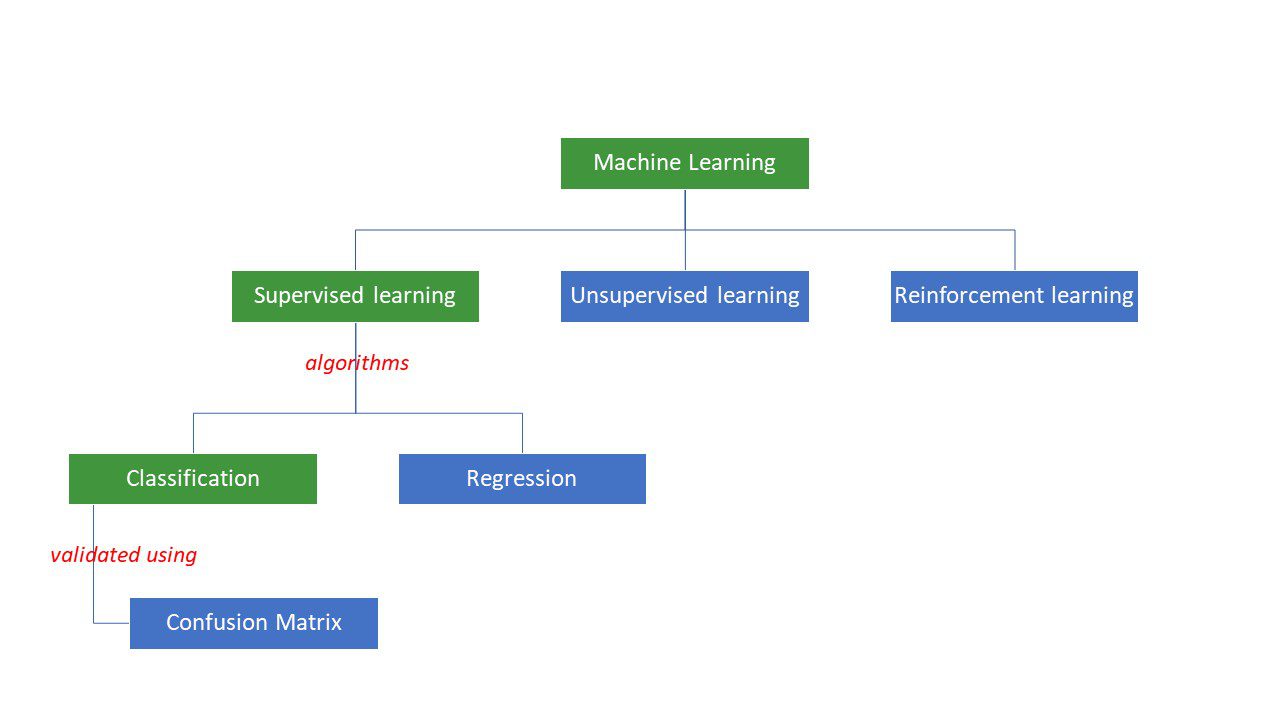 Typer av maskininlärningsalgoritmer
Typer av maskininlärningsalgoritmer
De enklaste typerna av algoritmer övervakas, där vi redan vet svaret, och vi tränar maskinerna att komma fram till det svaret genom att träna algoritmen med mycket data – på samma sätt som hur ett barn skulle skilja mellan människor i olika åldersgrupper genom att tittar på deras egenskaper om och om igen.
Övervakade ML-algoritmer är av två typer – klassificering och regression.
Klassificeringsalgoritmer klassificerar eller sorterar data baserat på en uppsättning kriterier. Om du till exempel vill att din algoritm ska gruppera kunder baserat på deras matpreferenser – de som gillar pizza och de som inte gillar pizza, skulle du använda en klassificeringsalgoritm som beslutsträd, random skog, naiva Bayes eller SVM (Support Vektormaskin).
Vilken av dessa algoritmer skulle göra det bästa jobbet? Varför ska du välja den ena algoritmen framför den andra?
Ange förvirringsmatris…
En förväxlingsmatris är en matris eller tabell som ger information om hur korrekt en klassificeringsalgoritm är vid klassificering av en datauppsättning. Nåväl, namnet är inte för att förvirra människor, men för många felaktiga förutsägelser betyder förmodligen att algoritmen var förvirrad😉!
Så, en förvirringsmatris är en metod för att utvärdera prestandan hos en klassificeringsalgoritm.
Hur?
Låt oss säga att du tillämpade olika algoritmer på vårt tidigare nämnda binära problem: klassificera (segregera) personer baserat på om de gillar eller inte gillar pizza. För att utvärdera den algoritm som har värden närmast det korrekta svaret, skulle du använda en förvirringsmatris. För ett binärt klassificeringsproblem (gillar/gillar inte, sant/falskt, 1/0) ger förvirringsmatrisen fyra rutnätsvärden, nämligen:
- Sant positiv (TP)
- True Negative (TN)
- Falskt positivt (FP)
- Falskt negativt (FN)
Vilka är de fyra rutnäten i en förvirringsmatris?
De fyra värden som bestäms med hjälp av förvirringsmatrisen bildar matrisens rutnät.
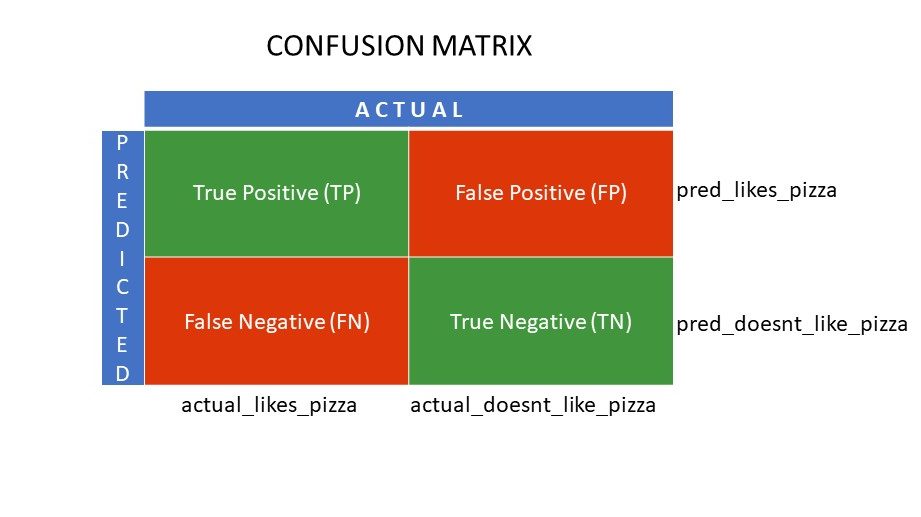 Förvirringsmatrisnät
Förvirringsmatrisnät
True Positive (TP) och True Negative (TN) är de värden som korrekt förutsägs av klassificeringsalgoritmen,
- TP representerar de som gillar pizza, och modellen klassificerade dem korrekt,
- TN representerar de som inte gillar pizza, och modellen klassificerade dem korrekt,
Falskt positivt (FP) och Falskt negativt (FN) är de värden som felaktigt förutsägs av klassificeraren,
- FP representerar de som inte gillar pizza (negativ), men klassificeraren förutspådde att de gillar pizza (felaktigt positivt). FP kallas också ett typ I-fel.
- FN representerar de som gillar pizza (positivt), men klassificeraren förutspådde att de inte gör det (felaktigt negativt). FN kallas även typ II-fel.
För att ytterligare förstå konceptet, låt oss ta ett verkligt scenario.
Låt oss säga att du har en datauppsättning på 400 personer som genomgick Covid-testet. Nu fick du resultaten av olika algoritmer som bestämde antalet Covid-positiva och Covid-negativa personer.
Här är de två förvirringsmatriserna för jämförelse:
Genom att titta på båda kan du bli frestad att säga att den första algoritmen är mer exakt. Men för att få ett konkret resultat behöver vi några mätvärden som kan mäta noggrannheten, precisionen och många andra värden som bevisar vilken algoritm som är bättre.
Mått som använder förvirringsmatris och deras betydelse
De viktigaste mätvärdena som hjälper oss att avgöra om klassificeraren gjorde rätt förutsägelser är:
#1. Återkallelse/Känslighet
Recall eller Sensitivity eller True Positive Rate (TPR) eller Probability of Detection är förhållandet mellan de korrekta positiva förutsägelserna (TP) och de totala positiva (dvs. TP och FN).
R = TP/(TP + FN)
Återkallelse är måttet på korrekta positiva resultat som returneras av antalet korrekta positiva resultat som kunde ha producerats. Ett högre värde på Recall betyder att det finns färre falsknegativ, vilket är bra för algoritmen. Använd Recall när det är viktigt att känna till de falska negativen. Till exempel, om en person har flera blockeringar i hjärtat och modellen visar att han mår helt bra, kan det visa sig vara dödligt.
#2. Precision
Precision är måttet på de korrekta positiva resultaten av alla förutspådda positiva resultat, inklusive både sanna och falska positiva.
Pr = TP/(TP + FP)
Precision är ganska viktigt när de falska positiva är för viktiga för att ignoreras. Till exempel, om en person inte har diabetes, men modellen visar det, och läkaren ordinerar vissa mediciner. Detta kan leda till allvarliga biverkningar.
#3. Specificitet
Specificitet eller True Negative Rate (TNR) är korrekta negativa resultat som hittats av alla resultat som kunde ha varit negativa.
S = TN/(TN + FP)
Det är ett mått på hur väl din klassificerare identifierar de negativa värdena.
#4. Noggrannhet
Noggrannhet är antalet korrekta förutsägelser av det totala antalet förutsägelser. Så om du hittade 20 positiva och 10 negativa värden korrekt från ett urval av 50, kommer noggrannheten för din modell att vara 30/50.
Noggrannhet A = (TP + TN)/(TP + TN + FP + FN)
#5. Utbredning
Prevalens är måttet på antalet positiva resultat som erhållits av alla resultat.
P = (TP + FN)/(TP + TN + FP + FN)
#6. F-poäng
Ibland är det svårt att jämföra två klassificerare (modeller) med bara Precision och Recall, som bara är aritmetiska medel för en kombination av de fyra rutnäten. I sådana fall kan vi använda F Score eller F1 Score, som är det harmoniska medelvärdet – vilket är mer exakt eftersom det inte varierar för mycket för extremt höga värden. Högre F-poäng (max 1) indikerar en bättre modell.
F-poäng = 2*Precision*Recall/ (Återkallning + Precision)
När det är viktigt att ta hand om både falska positiva och falska negativa är F1-poängen ett bra mått. Till exempel behöver de som inte är covid-positiva (men algoritmen visade det) inte isoleras i onödan. På samma sätt måste de som är Covid-positiva (men algoritmen sa att de inte är det) isoleras.
#7. ROC-kurvor
Parametrar som Noggrannhet och Precision är bra mått om data är balanserad. För en obalanserad datauppsättning behöver en hög noggrannhet inte nödvändigtvis betyda att klassificeraren är effektiv. Till exempel kan 90 av 100 elever i en grupp spanska. Nu, även om din algoritm säger att alla 100 kan spanska, kommer dess noggrannhet att vara 90%, vilket kan ge en felaktig bild av modellen. I fall av obalanserade datamängder är mätvärden som ROC mer effektiva bestämningsfaktorer.
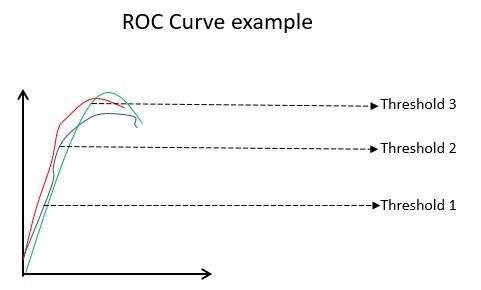 Exempel på ROC-kurva
Exempel på ROC-kurva
ROC-kurvan (Receiver Operating Characteristic) visar visuellt prestandan för en binär klassificeringsmodell vid olika klassificeringströsklar. Det är en plot av TPR (True Positive Rate) mot FPR (False Positive Rate), som beräknas som (1-Specificitet) vid olika tröskelvärden. Värdet som är närmast 45 grader (överst till vänster) i diagrammet är det mest exakta tröskelvärdet. Om tröskeln är för hög kommer vi inte att ha många falska positiva, men vi kommer att få fler falska negativa och vice versa.
Generellt, när ROC-kurvan för olika modeller plottas, anses den som har störst Area Under the Curve (AUC) vara den bättre modellen.
Låt oss beräkna alla metriska värden för våra klassificerare I och klassificerare II förvirringsmatriser:
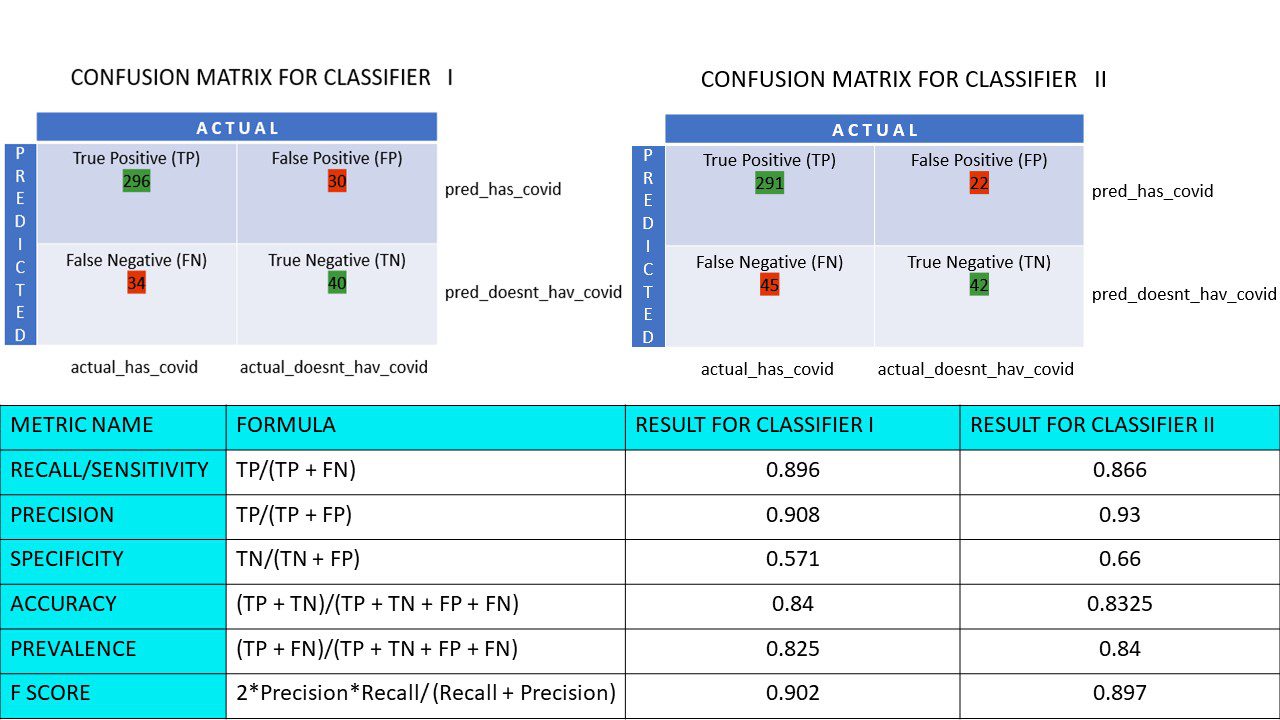 Metrisk jämförelse för klassificerare 1 och 2 i pizzaundersökningen
Metrisk jämförelse för klassificerare 1 och 2 i pizzaundersökningen
Vi ser att precisionen är mer i klassificerare II medan noggrannheten är något högre i klassificerare I. Baserat på problemet kan beslutsfattare välja klassificerare I eller II.
N x N förvirringsmatris
Hittills har vi sett en förvirringsmatris för binära klassificerare. Tänk om det fanns fler kategorier än bara ja/nej eller gilla/ogilla. Till exempel, om din algoritm var att sortera bilder av röda, gröna och blå färger. Denna typ av klassificering kallas flerklassklassificering. Antalet utdatavariabler avgör också matrisens storlek. Så i det här fallet kommer förvirringsmatrisen att vara 3×3.
 Förvirringsmatris för en klassificerare i flera klasser
Förvirringsmatris för en klassificerare i flera klasser
Sammanfattning
En förvirringsmatris är ett utmärkt utvärderingssystem eftersom det ger detaljerad information om prestandan hos en klassificeringsalgoritm. Det fungerar bra för både binära klassificerare och klassificerare med flera klasser, där det finns mer än 2 parametrar att ta hand om. Det är lätt att visualisera en förvirringsmatris, och vi kan generera alla andra mätvärden för prestanda som F Score, precision, ROC och noggrannhet med hjälp av förvirringsmatrisen.
Du kan också titta på hur man väljer ML-algoritmer för regressionsproblem.