Inom maskininlärning utgör regression och klassificering två centrala och grundläggande områden.
För den som är ny inom maskininlärning kan det ibland vara svårt att urskilja skillnaderna mellan regressions- och klassificeringsalgoritmer. En god förståelse för hur dessa algoritmer fungerar och i vilka sammanhang de ska tillämpas är avgörande för att kunna göra korrekta förutsägelser och fatta välgrundade beslut.
Låt oss först undersöka vad maskininlärning egentligen innebär.
Vad är maskininlärning?
Maskininlärning är en metod där datorer tränas att lära sig och dra slutsatser utan att vara explicit programmerade för varje enskilt fall. Genom att träna en datormodell på en uppsättning data, kan modellen identifiera mönster och relationer i datat, vilket i sin tur möjliggör prediktioner och beslutsfattande.
Det finns huvudsakligen tre typer av maskininlärning: övervakad inlärning, oövervakad inlärning och förstärkningsinlärning.
Vid övervakad inlärning matas modellen med data som har blivit märkt, det vill säga, varje inmatning är kopplad till ett känt korrekt utfall. Modellen lär sig relationen mellan inmatningen och utfallet med syfte att göra förutsägelser om utfallet för ny, tidigare okänd data.
I oövervakad inlärning ges modellen ingen märkt data. Istället får den självständigt utforska datat för att upptäcka mönster och samband, till exempel grupperingar, kluster, eller avvikelser.
Förstärkningsinlärning innebär att en agent interagerar med en miljö för att maximera en belöning. Modellen tränas att fatta beslut baserat på feedback från miljön.
Maskininlärning tillämpas inom många områden, såsom bild- och taligenkänning, naturlig språkbehandling, bedrägeribekämpning och utveckling av självkörande bilar. Maskininlärning har potential att automatisera processer och förbättra beslutsfattande i en rad olika branscher.
I den här artikeln kommer vi att fokusera på koncepten klassificering och regression, som båda tillhör kategorin övervakad maskininlärning. Låt oss börja!
Klassificering inom maskininlärning

Klassificering är en teknik inom maskininlärning där en modell tränas för att tilldela en given inmatning till en specifik kategori. Det är en typ av övervakad inlärning, vilket innebär att modellen tränas med hjälp av märkt data, det vill säga exempel på inmatningar kopplade till motsvarande klassificering.
Modellen strävar efter att lära sig förhållandet mellan inmatningen och kategorierna för att kunna förutsäga klassificeringen för ny, okänd inmatning.
En mängd olika algoritmer kan användas för klassificering, bland annat logistisk regression, beslutsträd och stödvektormaskiner. Valet av algoritm beror på datats egenskaper och den önskade prestandan hos modellen.
Några vanliga tillämpningar av klassificering är exempelvis spamdetektering, sentimentanalys och bedrägeribekämpning. I dessa fall kan inmatningen vara text, numeriska värden eller en kombination av båda. Klassificeringen kan vara binär (t.ex. spam eller inte spam) eller multiklass (t.ex. positiv, neutral eller negativ känsla).
Tänk till exempel på en datauppsättning med kundrecensioner för en viss produkt. Inmatningen är recensionstexten, och klassificeringen är betyget (positiv, neutral eller negativ). Modellen tränas på en uppsättning med märkta recensioner och kan sedan förutsäga betyget för en ny recension som den inte tidigare sett.
Typer av klassificeringsalgoritmer inom maskininlärning
Det finns många olika typer av klassificeringsalgoritmer inom maskininlärning:
Logistisk regression
Detta är en linjär modell som används för binär klassificering. Den beräknar sannolikheten för att en viss händelse ska inträffa. Syftet med logistisk regression är att hitta de optimala koefficienterna (vikterna) som minimerar felet mellan den förutsagda sannolikheten och det faktiska utfallet.
Detta uppnås genom att använda en optimeringsalgoritm, exempelvis gradient descent, som justerar koefficienterna tills modellen passar träningsdatat så bra som möjligt.
Beslutsträd
Beslutsträd är trädliknande modeller som fattar beslut baserat på funktionsvärden. De kan användas för både binär och multiklassklassificering. Beslutsträd är populära på grund av sin enkelhet och tolkningsbarhet.
De är också snabba att träna och använda för prediktion, samt kan hantera både numerisk och kategorisk data. Beslutsträd kan dock vara känsliga för överanpassning, särskilt om trädet är djupt och har många grenar.
Slumpmässig skogsklassificering
Slumpmässig skogsklassificering är en ensemblemetod som kombinerar prediktioner från flera beslutsträd för att få en mer exakt och stabil förutsägelse. Den är mindre benägen för överanpassning jämfört med ett enskilt beslutsträd, eftersom medelvärdet av de enskilda trädens prediktioner minskar modellens varians.
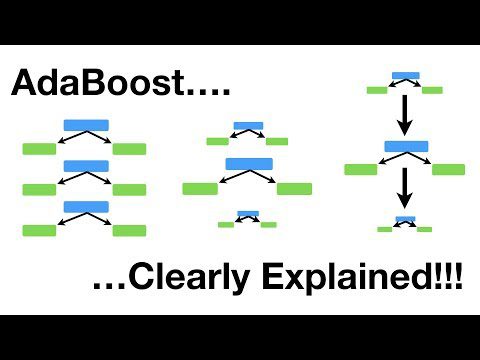
AdaBoost
Detta är en förstärkningsalgoritm som adaptivt anpassar vikten av felklassificerade exempel i träningsdatat. Den används ofta för binär klassificering.
Naiv Bayes
Naiv Bayes bygger på Bayes sats, vilket är ett sätt att uppdatera sannolikheten för en händelse baserat på ny information. Det är en probabilistisk klassificeringsmetod som ofta används för textklassificering och spamfiltrering.
K-Närmaste grannar
K-Nearest Neighbors (KNN) används både för klassificering och regressionsuppgifter. Det är en icke-parametrisk metod som klassificerar en datapunkt baserat på klassificeringen av dess närmaste grannar. KNN är enkel att använda och implementera, och kan hantera både numerisk och kategorisk data utan att göra antaganden om den underliggande datafördelningen.
Gradient Boosting
Detta är en samling av svaga modeller som tränas sekventiellt, där varje modell försöker korrigera misstagen från den föregående. De kan användas för både klassificering och regression.
Regression inom maskininlärning
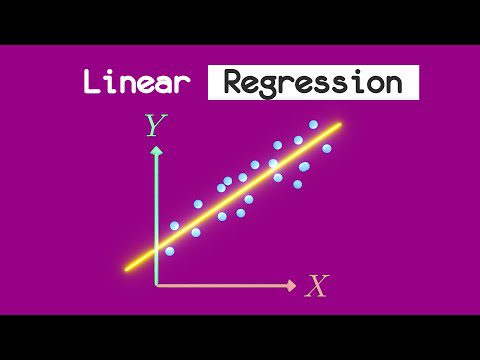
Inom maskininlärning är regression en typ av övervakad inlärning som syftar till att förutsäga en beroende variabel baserat på en eller flera inmatningsfunktioner (även kallade prediktorer eller oberoende variabler).
Regressionsalgoritmer används för att modellera förhållandet mellan inmatningen och utfallet och för att göra förutsägelser baserat på detta förhållande. Regression kan användas för både kontinuerliga och kategoriska beroende variabler.
I grund och botten handlar regression om att skapa en modell som korrekt kan förutsäga utfallet baserat på inmatningsfunktionerna och att förstå den underliggande relationen mellan inmatningsfunktionerna och utfallet.
Regressionsanalys används i en mängd olika sammanhang, som ekonomi, finans, marknadsföring och psykologi, för att förstå och förutsäga samband mellan variabler. Det är ett grundläggande verktyg inom dataanalys och maskininlärning och används för att göra förutsägelser, identifiera trender och förstå mekanismerna bakom datat.
Som exempel, i en enkel linjär regressionsmodell kan målet vara att förutsäga priset på ett hus baserat på dess storlek, läge och andra egenskaper. Storleken på huset och dess läge är de oberoende variablerna, och huspriset är den beroende variabeln.
Modellen tränas med hjälp av data som inkluderar storleken och läget för flera hus tillsammans med deras motsvarande priser. När modellen är färdigtränad kan den användas för att förutsäga priset på ett hus baserat på dess storlek och läge.
Typer av regressionsalgoritmer inom maskininlärning
Regressionsalgoritmer finns i olika former, och valet av algoritm beror på ett antal parametrar, exempelvis vilken typ av attributvärde som används, mönstret för trendlinjen och antalet oberoende variabler. Vanligt använda regressionstekniker är bland annat:
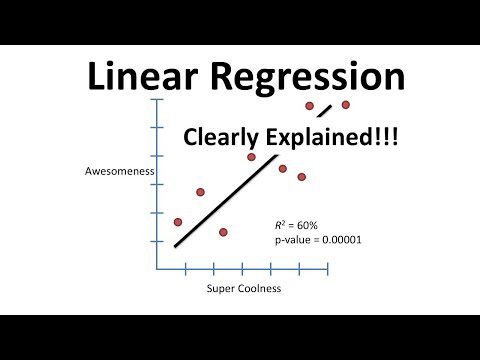
Linjär regression
Detta är en enkel linjär modell som används för att förutsäga ett kontinuerligt värde baserat på en uppsättning funktioner. Den används för att modellera relationen mellan funktionerna och målvariabeln genom att anpassa en linje till datat.
Polynomregression
Detta är en icke-linjär modell som används för att anpassa en kurva till datat. Den används för att modellera relationer mellan funktionerna och målvariabeln när relationen inte är linjär. Den bygger på att lägga till högre ordningstermer till den linjära modellen för att fånga icke-linjära samband mellan de beroende och oberoende variablerna.
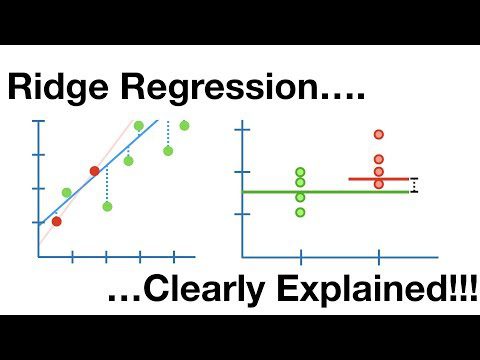
Ridge regression
Detta är en linjär modell som hanterar överanpassning i linjär regression. Det är en regulariserad version av linjär regression som lägger till en straffterm till kostnadsfunktionen för att minska modellens komplexitet.
Stödvektorregression
Liksom SVM är stödvektorregression en linjär modell som försöker anpassa datat genom att hitta det hyperplan som maximerar marginalen mellan de beroende och oberoende variablerna.
Men till skillnad från SVM, som används för klassificering, används SVR för regressionsuppgifter där målet är att förutsäga ett kontinuerligt värde istället för en klassificering.
Lasso regression
Detta är en annan regulariserad linjär modell som används för att förhindra överanpassning i linjär regression. Den lägger till en straffterm till kostnadsfunktionen baserat på koefficienternas absoluta värde.
Bayesiansk linjär regression
Bayesiansk linjär regression är ett probabilistiskt synsätt på linjär regression som bygger på Bayes sats, vilket är ett sätt att uppdatera sannolikheten för en händelse baserat på ny information.
Denna regressionsmodell syftar till att uppskatta den bakre fördelningen av modellparametrarna givet datat. Det görs genom att definiera en tidigare fördelning över parametrarna och sedan använda Bayes sats för att uppdatera fördelningen baserat på de observerade data.
Regression kontra Klassificering
Regression och klassificering är två typer av övervakad inlärning, vilket innebär att de används för att förutsäga ett utfall baserat på en uppsättning inmatningsfunktioner. Det finns dock några viktiga skillnader mellan de två:
| Regression | Klassificering | |
| Definition | En typ av övervakad inlärning som förutsäger ett kontinuerligt värde | En typ av övervakad inlärning som förutsäger ett kategoriskt värde |
| Utfallstyp | Kontinuerlig | Diskret |
| Utvärderingsmått | Medelkvadratfel (MSE), rotmedelkvadratfel (RMSE) | Noggrannhet, precision, återkallning, F1-poäng |
| Algoritmer | Linjär regression, polynomregression, Ridge, Lasso, SVR, Bayesiansk regression, Gradient Boosting | Logistisk regression, SVM, Naiv Bayes, KNN, Beslutsträd, Slumpmässig skog |
| Modellkomplexitet | Mindre komplexa modeller | Mer komplexa modeller |
| Antaganden | Linjärt samband mellan attribut och mål | Inga specifika antaganden om förhållandet mellan attribut och mål |
| Klassobalans | Ej tillämpligt | Kan vara ett problem |
| Utskick | Kan påverka modellens prestanda | Ej en viktig faktor |
| Faktatypvärde | Avvikelse rankas inte efter betydelse | Karaktär |
| Exempelanvändningar | Förutsäga priser, temperaturer, kvantiteter | Förutsäga om e-post är spam, förutsäga kundbortfall |
Lärresurser
Det kan vara svårt att välja rätt onlineresurser för att lära sig koncepten inom maskininlärning. Vi har undersökt populära kurser från betrodda plattformar för att ge rekommendationer om de bästa maskininlärningskurserna inom regression och klassificering.
#1. Machine Learning Classification Bootcamp i Python
Detta är en kurs som erbjuds på Udemy-plattformen. Den behandlar en mängd olika klassificeringsalgoritmer och tekniker, inklusive beslutsträd, logistisk regression och stödvektormaskiner.

Du får även lära dig om överanpassning, avvägningen mellan bias och varians och modellutvärdering. Kursen använder Python-bibliotek som sci-kit-learn och pandas för att implementera och utvärdera maskininlärningsmodeller. Grundläggande kunskaper i Python krävs för att delta i kursen.
#2. Machine Learning Regression Masterclass i Python
I den här Udemy-kursen går instruktören igenom grunderna och den underliggande teorin för olika regressionsalgoritmer, inklusive linjär regression, polynomregression och Lasso- & Ridge-regressionstekniker.
Efter den här kursen kommer du att kunna implementera regressionsalgoritmer och utvärdera prestandan hos tränade maskininlärningsmodeller med hjälp av olika nyckelprestandaindikatorer.
Avslutningsvis
Maskininlärningsalgoritmer kan vara mycket användbara i många sammanhang och kan bidra till att automatisera och effektivisera olika processer. Maskininlärningsalgoritmer använder statistiska tekniker för att lära sig mönster i data och göra förutsägelser eller beslut baserat på dessa mönster.
De kan tränas på stora mängder data och kan användas för att utföra uppgifter som skulle vara svåra eller tidskrävande för människor att göra manuellt.
Varje maskininlärningsalgoritm har sina styrkor och svagheter, och valet av algoritm beror på uppgifternas karaktär och kraven i den specifika uppgiften. Det är viktigt att välja rätt algoritm eller kombination av algoritmer för det problem du försöker lösa.
Det är avgörande att välja rätt typ av algoritm för ett givet problem, eftersom fel algoritm kan leda till dålig prestanda och felaktiga förutsägelser. Om du är osäker på vilken algoritm du ska använda kan det vara bra att prova både regressions- och klassificeringsalgoritmer och jämföra deras prestanda på din datauppsättning.
Jag hoppas att du har haft nytta av den här artikeln för att lära dig mer om regression kontra klassificering inom maskininlärning. Du kan också vara intresserad av att lära dig mer om de bästa maskininlärningsmodellerna.