Tänk dig en omfattande infrastruktur bestående av många olika typer av enheter som kräver regelbunden tillsyn och underhåll, för att säkerställa att de inte utgör någon fara för sin omgivning.
En metod för att åstadkomma detta är att regelbundet skicka ut personal till varje enskild plats för inspektion. Även om detta är genomförbart, är det kostsamt både i tid och resurser. Om infrastrukturen är mycket omfattande kan det dessutom vara svårt att täcka alla platser inom ett år.
Ett annat tillvägagångssätt är att automatisera processen och låta datoriserade system i molnet utföra kontrollerna. För att detta ska vara möjligt behöver följande steg genomföras:
👉 En effektiv metod för att samla in bilder av enheterna. Detta kan initialt göras av personal, eftersom det är betydligt snabbare att ta en bild än att genomföra en fullständig enhetskontroll. Bildinsamlingen kan även ske via fordon eller drönare, vilket leder till en snabbare och mer automatiserad process.
👉 Därefter behöver samtliga insamlade bilder överföras till en central plats i molnet.
👉 I molnet behövs en automatiserad process som hämtar bilderna och bearbetar dem med hjälp av maskininlärningsmodeller som tränats för att identifiera skador eller avvikelser på enheterna.
👉 Slutligen måste resultaten presenteras för de relevanta användarna, så att nödvändiga reparationer kan planeras för enheter med identifierade problem.
Låt oss utforska hur vi kan implementera avvikelsedetektering baserad på bilder i AWS-molnet. Amazon erbjuder flera fördefinierade maskininlärningsmodeller som kan användas för detta ändamål.
Skapa en modell för visuell avvikelsedetektering
För att skapa en modell för visuell avvikelsedetektering krävs följande steg:
Steg 1: Definiera tydligt det problem du vill lösa och vilka typer av avvikelser du vill upptäcka. Detta hjälper dig att identifiera den lämpliga testdata som du behöver för att träna modellen.
Steg 2: Samla in en stor mängd bilddata som representerar både normala och avvikande tillstånd. Märk bilderna för att tydligt ange vilka som är normala och vilka som innehåller avvikelser.
Steg 3: Välj en modellarkitektur som är lämplig för uppgiften. Du kan antingen använda en förtränad modell och finjustera den för ditt specifika behov, eller skapa en anpassad modell från grunden.
Steg 4: Träna modellen med den förberedda datamängden och den valda algoritmen. Detta kan innebära att använda överföringsinlärning för att dra nytta av förtränade modeller eller träna modellen från grunden med tekniker som konvolutionella neurala nätverk (CNN).
Träning av en maskininlärningsmodell
Källa: aws.amazon.com
Träningsprocessen för AWS maskininlärningsmodeller för visuell avvikelsedetektering omfattar vanligtvis flera viktiga steg.
#1. Datainsamling
Inledningsvis måste du samla in och märka en omfattande datauppsättning med bilder som representerar både normala och avvikande tillstånd. Ju större datamängd, desto mer träffsäker och exakt blir modellen. Men en större datamängd kräver också mer tid för träning.
En bra startpunkt brukar vara cirka 1000 bilder i en testdatauppsättning.
#2. Dataförberedelse
Bilddatan måste förberedas innan den kan användas av maskininlärningsmodellerna. Förberedelsen kan omfatta flera åtgärder:
- Ordna bilderna i separata mappar, korrigera metadata etc.
- Ändra storleken på bilderna för att uppfylla modellens upplösningskrav.
- Dela upp bilderna i mindre delar för effektivare och parallell bearbetning.
#3. Modellval
Nu är det dags att välja rätt modell för uppgiften. Du kan antingen använda en förtränad modell eller skapa en anpassad modell som är specifikt anpassad för din visuella avvikelsedetektering.
#4. Utvärdering av resultat
När modellen har bearbetat din datauppsättning är det viktigt att utvärdera dess prestanda och verifiera om resultaten uppfyller dina behov. Du kan till exempel sätta ett krav på att resultaten måste vara korrekta i mer än 99% av fallen.
#5. Modellimplementering
Om du är nöjd med modellens resultat och prestanda kan du implementera den i din AWS-miljö så att de olika processerna och tjänsterna kan börja använda den.
#6. Övervakning och förbättring
Låt modellen genomgå olika testjobb och utvärdera kontinuerligt om de nödvändiga parametrarna för detekteringskorrektheten bibehålls.
Om inte, träna om modellen med hjälp av de nya datauppsättningarna där modellen gav felaktiga resultat.
AWS maskininlärningsmodeller
Låt oss nu titta på några konkreta modeller som du kan använda i Amazons moln.
AWS Rekognition
Källa: aws.amazon.com
Rekognition är en allmän bild- och videoanalystjänst som kan användas för flera olika ändamål, såsom ansiktsigenkänning, objektidentifiering och textanalys. I de flesta fall kan du använda Rekognition-modellen för en första grov generering av detekteringsresultat för att skapa en dataöversikt över identifierade avvikelser.
Den tillhandahåller ett antal fördefinierade modeller som du kan använda direkt, utan att behöva träna dem. Rekognition erbjuder även realtidsanalys av bilder och videor med hög noggrannhet och låg latens.
Här är några typiska användningsfall där Rekognition är ett bra val för avvikelsedetektering:
- När du har ett generellt behov av avvikelsedetektering, som att upptäcka avvikelser i bilder eller videor.
- När du behöver utföra avvikelsedetektering i realtid.
- När du vill integrera din avvikelsedetekteringsmodell med andra AWS-tjänster som Amazon S3, Amazon Kinesis eller AWS Lambda.
Här är några konkreta exempel på avvikelser som du kan upptäcka med hjälp av Rekognition:
- Avvikelser i ansikten, som att upptäcka ansiktsuttryck eller känslor utanför det normala.
- Saknade eller felplacerade objekt i en scen.
- Felstavade ord eller ovanliga textmönster.
- Ovanliga ljusförhållanden eller oväntade objekt i en scen.
- Olämpligt eller stötande innehåll i bilder eller videor.
- Plötsliga förändringar i rörelse eller oväntade rörelsemönster.
AWS Lookout for Vision
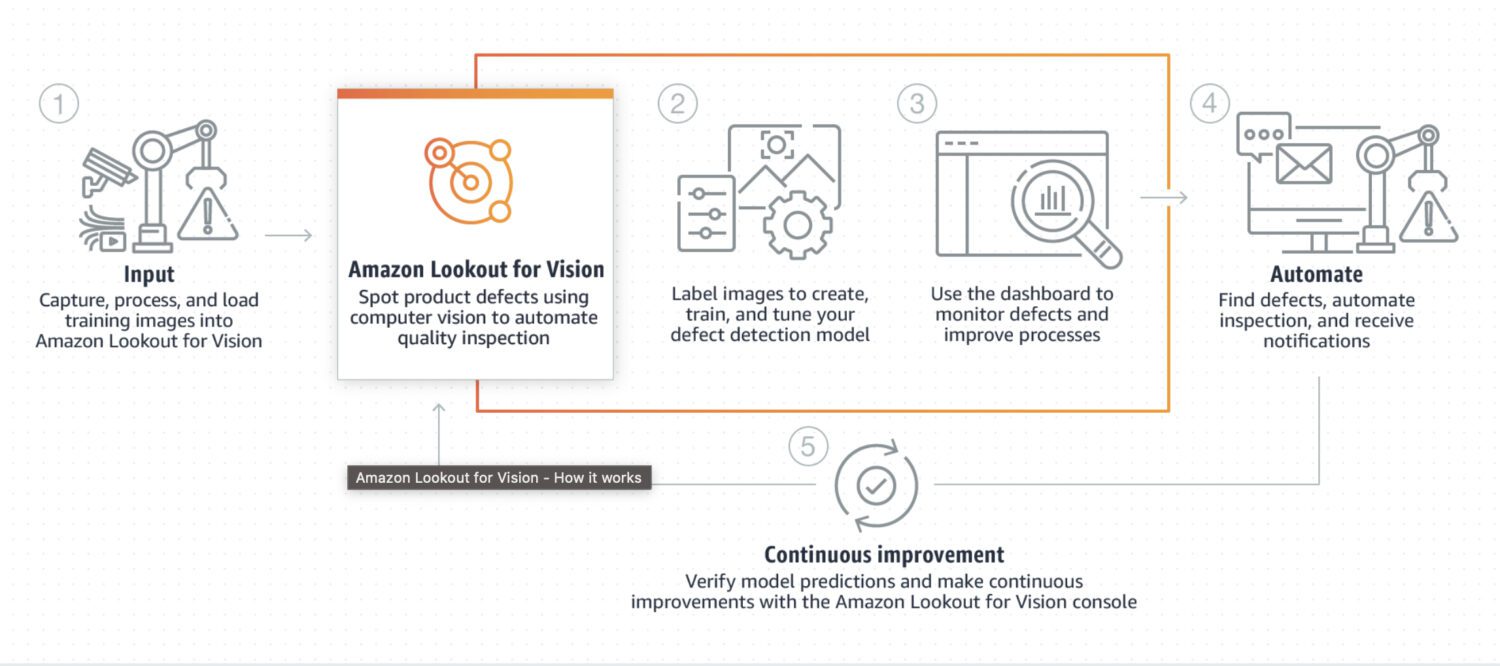
Källa: aws.amazon.com
Lookout for Vision är en modell som är speciellt utformad för avvikelsedetektering i industriella processer, såsom tillverkning och produktionslinjer. Den kräver ofta en viss förbearbetning och efterbearbetning av bilder, vanligen med hjälp av programmeringsspråket Python. Modellen är specialiserad på att hantera specifika problem i bilden.
Den behöver anpassad träning med en datauppsättning av normala och avvikande bilder för att skapa en anpassad modell för avvikelsedetektering. Fokus ligger inte på realtidsanalys; istället är den optimerad för batchbearbetning av bilder, med fokus på noggrannhet och precision.
Här är några typiska användningsfall där Lookout for Vision är ett bra alternativ:
- Om du behöver upptäcka defekter i tillverkade produkter eller identifiera fel på utrustning i en produktionslinje.
- Om du har en stor datauppsättning med bilder eller annan data.
- Om du behöver utföra avvikelsedetektering i en industriell process.
- Om du behöver integrera din avvikelsedetektering med andra AWS-tjänster, som Amazon S3 eller AWS IoT.
Här är några konkreta exempel på avvikelser som du kan upptäcka med Lookout for Vision:
- Defekter i tillverkade produkter, som repor, bucklor eller andra fel som kan påverka produktkvaliteten.
- Fel på utrustning i en produktionslinje, som att upptäcka trasiga eller felaktiga maskiner som kan orsaka förseningar eller säkerhetsrisker.
- Problem med kvalitetskontroll i en produktionslinje, som att upptäcka produkter som inte uppfyller de nödvändiga specifikationerna eller toleranserna.
- Säkerhetsrisker i en produktionslinje, som att upptäcka objekt eller material som kan utgöra en risk för arbetare eller utrustning.
- Avvikelser i en produktionsprocess, som att upptäcka oväntade förändringar i flödet av material eller produkter genom produktionslinjen.
AWS Sagemaker
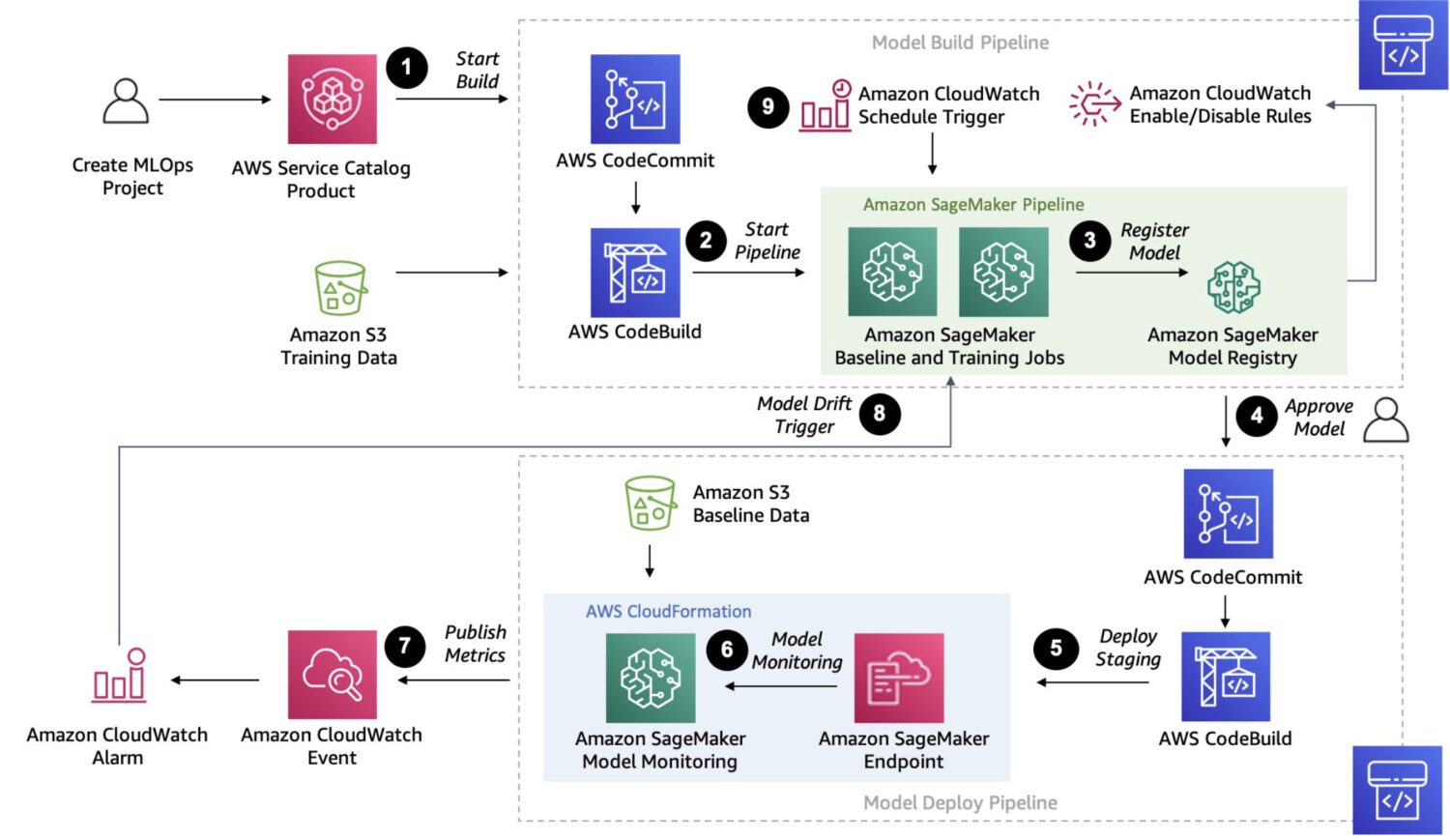
Källa: aws.amazon.com
Sagemaker är en helt hanterad plattform för att utveckla, träna och implementera anpassade maskininlärningsmodeller.
Det är en mycket robust lösning. Den erbjuder möjlighet att koppla samman och exekvera flera steg i en sekvens av uppgifter, i likhet med AWS Step Functions.
Eftersom Sagemaker använder ad-hoc EC2-instanser för bearbetning, finns det ingen 15-minutersbegränsning för enskilda jobb, som det är fallet med AWS Lambda-funktioner i AWS Step Functions.
Du kan även utföra automatisk modelloptimering med Sagemaker, vilket är en funktion som gör det till ett utmärkt alternativ. Sagemaker gör det enkelt att implementera modellen i en produktionsmiljö.
Här är några typiska användningsfall där SageMaker är ett bra val för avvikelsedetektering:
- Om du har ett specifikt användningsfall som inte täcks av fördefinierade modeller eller API:er och behöver skapa en skräddarsydd modell för dina behov.
- Om du har en stor datauppsättning med bilder eller annan data. Fördefinierade modeller kan kräva förbearbetning, men Sagemaker kan hantera det utan.
- Om du behöver utföra avvikelsedetektering i realtid.
- Om du behöver integrera din modell med andra AWS-tjänster, som Amazon S3, Amazon Kinesis eller AWS Lambda.
Här är några exempel på avvikelsedetektering som Sagemaker kan utföra:
- Bedrägeriupptäckt i finansiella transaktioner, till exempel ovanliga utgiftsmönster eller transaktioner utanför det normala intervallet.
- Cybersäkerhet i nätverkstrafik, som ovanliga dataöverföringsmönster eller oväntade anslutningar till externa servrar.
- Medicinsk diagnos i medicinska bilder, som att upptäcka tumörer.
- Avvikelser i utrustningens prestanda, som att upptäcka förändringar i vibrationer eller temperatur.
- Kvalitetskontroll i tillverkningsprocesser, som att upptäcka defekter i produkter eller avvikelser från förväntade kvalitetsstandarder.
- Ovanliga mönster för energianvändning.
Integrering av modeller i en serverlös arkitektur
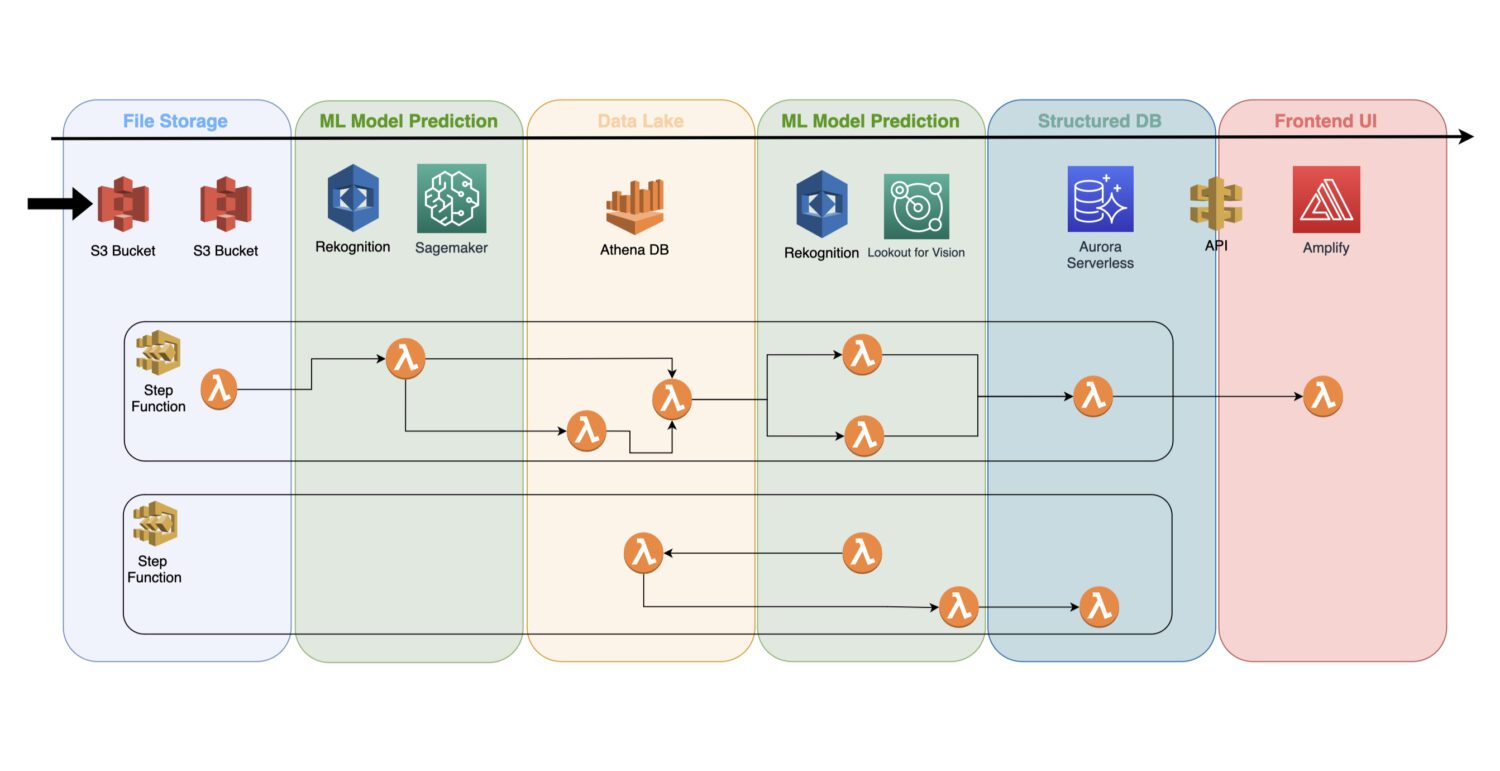
En tränad maskininlärningsmodell är en molntjänst som inte använder några klusterservrar i bakgrunden; därför kan den enkelt inkluderas i en befintlig serverlös arkitektur.
Automatiseringen sker via AWS Lambda-funktioner, kopplade till ett multistegsjobb i tjänsten AWS Step Functions.
Vanligtvis behöver du en första detektering direkt efter att du har samlat in bilderna och förberett dem i S3-lagring. Det är här du genererar en enkel avvikelsedetektering på de inkommande bilderna och sparar resultaten i en datasjö, som t.ex. representeras av en Athena-databas.
I vissa fall räcker inte den första detekteringen för ditt specifika användningsfall. Du kan behöva en ytterligare, mer detaljerad detektering. Till exempel kan den första modellen (t.ex. Rekognition) identifiera ett problem med enheten, men det är inte möjligt att med säkerhet identifiera exakt vilken typ av problem det är.
Då kan du behöva en annan modell med andra förmågor. I så fall kan du köra den andra modellen (t.ex. Lookout for Vision) på den delmängd av bilder där den ursprungliga modellen har identifierat ett problem.
Detta är också ett bra sätt att spara pengar, eftersom du inte behöver köra den andra modellen på hela bilduppsättningen. Istället kör du den bara på de relevanta bilderna.
AWS Lambda-funktioner hanterar all bearbetning med kod skriven i Python eller Javascript. Det beror på hur komplexa processerna är och hur många AWS Lambda-funktioner du behöver inkludera i ett flöde. Tidsbegränsningen på 15 minuter för maximal körningstid för ett AWS Lambda-anrop kommer att styra hur många steg en sådan process behöver omfatta.
Avslutande tankar
Att arbeta med maskininlärningsmodeller i molnet är ett mycket intressant och givande arbete. Om du ser det ur ett kompetens- och teknikperspektiv kommer du att upptäcka att du behöver ett team med en bred variation av färdigheter.
Teamet måste förstå hur man tränar en modell, oavsett om den är fördefinierad eller skapas från grunden. Detta innebär en hel del matematik eller algebra för att balansera tillförlitlighet och prestanda.
Du behöver även kunskaper i avancerad programmering i Python eller Javascript, samt kunskaper om databaser och SQL. När utvecklingsarbetet är klart behövs DevOps-kunskaper för att koppla ihop alla komponenter i en pipeline som skapar en automatiserad process redo för driftsättning och körning.
Att definiera avvikelser och träna modellen är en sak. Men det är en utmaning att integrera allting i ett fungerande team som kan bearbeta resultaten från modellerna och spara data på ett effektivt och automatiserat sätt för att leverera dem till slutanvändarna.
Kolla sedan in allt om ansiktsigenkänning för företag.