Introduktion till NLP och dess Algoritmer
Mänskligt språk, med sina invecklade akronymer, mångtydiga betydelser, subtila nyanser, grammatiska regler, kontextberoende, slang och andra komplexiteter, utgör en betydande utmaning för maskiner att tolka. Trots detta, är maskiner centrala i många affärsprocesser, vilket skapar ett behov av effektiv interaktion mellan människor och maskiner.
Därför har forskare utvecklat tekniker för att hjälpa maskiner att dechiffrera och lära sig mänskliga språk. Detta har lett till framväxten av naturlig språkbehandling, eller NLP. Dessa algoritmer möjliggör för datorprogram att förstå olika mänskliga språk, oavsett om de uttrycks i skrift eller tal.
NLP använder olika algoritmer för att bearbeta språkliga data, och dess införande har gjort tekniken till en viktig del av artificiell intelligens (AI) för att effektivisera hanteringen av ostrukturerad data.
Denna artikel undersöker NLP och några av de mest diskuterade NLP-algoritmerna.
Låt oss börja utforska!
Vad är NLP?
Naturlig språkbehandling (NLP) är en tvärvetenskaplig gren inom datavetenskap, lingvistik och artificiell intelligens. Den fokuserar på interaktionen mellan mänskligt språk och datorer. NLP programmerar maskiner att analysera och behandla stora mängder data som är kopplade till naturliga språk.
I enklare termer är NLP en modern teknik som ger maskiner förmågan att förstå, analysera och tolka mänskligt språk. Det gör det möjligt för maskiner att greppa innebörden i texter och talat språk. Med hjälp av NLP kan maskiner utföra uppgifter som översättning, taligenkänning, sammanfattning, ämnesindelning och andra uppdrag som programmerare instruerar dem att göra.
NLP-algoritmer utför dessa uppgifter i realtid med hjälp av flera tekniker, vilket ökar deras effektivitet. Denna teknik kombinerar maskininlärning, djupinlärning, statistiska modeller och regelbaserad lingvistik.
NLP-algoritmer ger datorer förmågan att bearbeta mänskligt språk genom text eller röstdata och att dechiffrera dess innebörd för olika ändamål. Datorernas tolkningsförmåga har utvecklats såpass att maskiner numera även kan förstå de underliggande känslorna och avsikterna bakom en text. Dessutom kan NLP förutspå kommande ord eller meningar medan en användare skriver eller talar.
Denna teknik har funnits i flera decennier och har genomgått kontinuerlig utveckling, vilket har resulterat i ökad bearbetningsnoggrannhet. NLP:s rötter sträcker sig tillbaka till lingvistik och bidrog i skapandet av internetsökmotorer. Med teknikens utveckling har NLP:s användningsområden breddats betydligt.
Idag används NLP inom en mängd områden, från finans och sökmotorer till sjukvård och robotteknik. NLP är djupt integrerat i moderna system och används i populära applikationer som röststyrd GPS, kundtjänstchattbottar, digitala assistenter, tal-till-text-funktioner och många andra.
Hur fungerar NLP?
NLP använder en rad olika metoder för att översätta det komplexa mänskliga språket till maskiner. Den använder främst artificiell intelligens för att bearbeta och tolka skrivna eller talade ord så att datorer kan förstå dem.
Datorer, likt människors hjärnor, bearbetar indata via specialiserade program som hjälper dem att omvandla indata till meningsfull utdata. NLP fungerar i två steg, där det ena är databehandling och det andra är algoritmutveckling.
Databehandling är det första steget, där indatatextdata förbereds och rensas för att maskinen ska kunna analysera det. Data bearbetas för att identifiera alla egenskaper i indatatexten och gör det kompatibelt med datoralgoritmer. I grund och botten förbereder databehandlingssteget data i ett format som maskinen kan förstå.
Teknikerna som används i denna fas är:
Källa: Amazinum
- Tokenisering: Inmatningstexten delas upp i mindre enheter så att NLP kan bearbeta dem effektivt.
- Borttagning av stoppord: Denna teknik avlägsnar vanliga ord från texten och omvandlar den till en form som behåller informationen i ett minimum.
- Lemmatisering och stamning: Genom lemmatisering och stamning reduceras orden till sin rotform, vilket underlättar maskinbearbetningen.
- Part-of-speech-taggning: Här kategoriseras orden i indatatexten som substantiv, adjektiv eller verb innan bearbetningen påbörjas.
Efter det första steget utvecklar maskinen algoritmer för att bearbeta den förbehandlade datan. Bland de många NLP-algoritmer som används, är regelbaserade och maskininlärningsbaserade system de vanligaste:
- Regelbaserade system: Dessa system använder språkliga regler för att bearbeta orden. Det är en etablerad algoritm som fortfarande används i stor utsträckning.
- Maskininlärningsbaserade system: Dessa avancerade algoritmer kombinerar neurala nätverk, djupinlärning och maskininlärning för att skapa egna regler för ordbehandling. Genom att använda statistiska metoder, bestämmer algoritmen bearbetningen av ord baserat på träningsdata och justerar processen kontinuerligt.
Olika Kategorier av NLP-algoritmer
NLP-algoritmer är maskininlärningsbaserade algoritmer eller instruktioner som används för att bearbeta naturliga språk. De fokuserar på utvecklingen av protokoll och modeller som gör det möjligt för en maskin att tolka mänskliga språk.

NLP-algoritmer anpassar sig efter AI:s strategi och de träningsdata de matas med. Deras främsta uppgift är att använda olika tekniker för att effektivt omvandla förvirrande eller ostrukturerad indata till användbar information som maskiner kan lära sig av.
Förutom olika tekniker, använder NLP-algoritmer naturliga språkprinciper för att göra indata mer förståeliga för maskiner. De ansvarar för att hjälpa maskinen att förstå kontextvärdet av en given indata, annars kommer maskinen inte att kunna utföra begäran.
NLP-algoritmer är uppdelade i tre huvudkategorier, och AI-modeller väljer en kategori baserat på datavetarens tillvägagångssätt. Dessa kategorier är:
#1. Symboliska algoritmer
Symboliska algoritmer utgör en av grundpelarna i NLP-algoritmer. De är ansvariga för att analysera betydelsen av varje inmatad text och använda den för att skapa kopplingar mellan olika begrepp.
Symboliska algoritmer representerar kunskap och relationer mellan begrepp med hjälp av symboler. Dessa algoritmer använder logik och tilldelar ord betydelser baserat på kontext, vilket ger en hög noggrannhet.
Kunskapsgrafer spelar också en central roll för att definiera begrepp för ett inmatningsspråk och relationer mellan dessa begrepp. Denna algoritms förmåga att definiera begrepp korrekt och förstå ordkontext underlättar utvecklingen av XAI.
Det kan vara svårt att utöka en regeluppsättning i symboliska algoritmer på grund av diverse begränsningar.
#2. Statistiska algoritmer
Statistiska algoritmer underlättar maskinens förståelse av text genom att bearbeta, analysera och härleda betydelser. De är effektiva eftersom de hjälper maskiner att lära sig mänskliga språk genom att identifiera mönster och trender i stora mängder text. Denna analys gör det möjligt för maskiner att förutsäga nästa ord i realtid.
Statistiska algoritmer används i många applikationer, från taligenkänning och sentimentanalys till maskinöversättning och textförslag. En viktig anledning till den breda användningen är deras förmåga att bearbeta stora datamängder.
Statistiska algoritmer kan också avgöra om två meningar i ett stycke har liknande betydelse och vilken som bör användas. En nackdel är att de delvis är beroende av komplex funktionsteknik.
#3. Hybridalgoritmer
Hybridalgoritmer kombinerar styrkan i både symboliska och statistiska algoritmer för att leverera effektiva resultat. Genom att fokusera på de viktigaste fördelarna och funktionerna kan de minimera svagheterna i båda metoderna, vilket är avgörande för att uppnå hög noggrannhet.
Det finns många sätt att kombinera dessa metoder:
- Symboliskt stöd för maskininlärning
- Maskininlärning som stöder symbolik
- Symbolik och maskininlärning som arbetar parallellt
Symboliska algoritmer kan stödja maskininlärning genom att hjälpa modellen att träna mer effektivt. På motsvarande sätt kan maskininlärning stödja symbolisk inlärning genom att skapa en initial uppsättning regler för det symboliska systemet, vilket sparar datavetare från manuell konstruktion.
När symboliska algoritmer och maskininlärning arbetar tillsammans, uppnås bättre resultat eftersom de ser till att modeller förstår ett specifikt textavsnitt korrekt.
Bästa NLP-algoritmerna
Det finns många NLP-algoritmer som hjälper datorer att förstå och efterlikna det mänskliga språket. Nedan följer några av de bästa NLP-algoritmerna:
#1. Ämnesmodellering
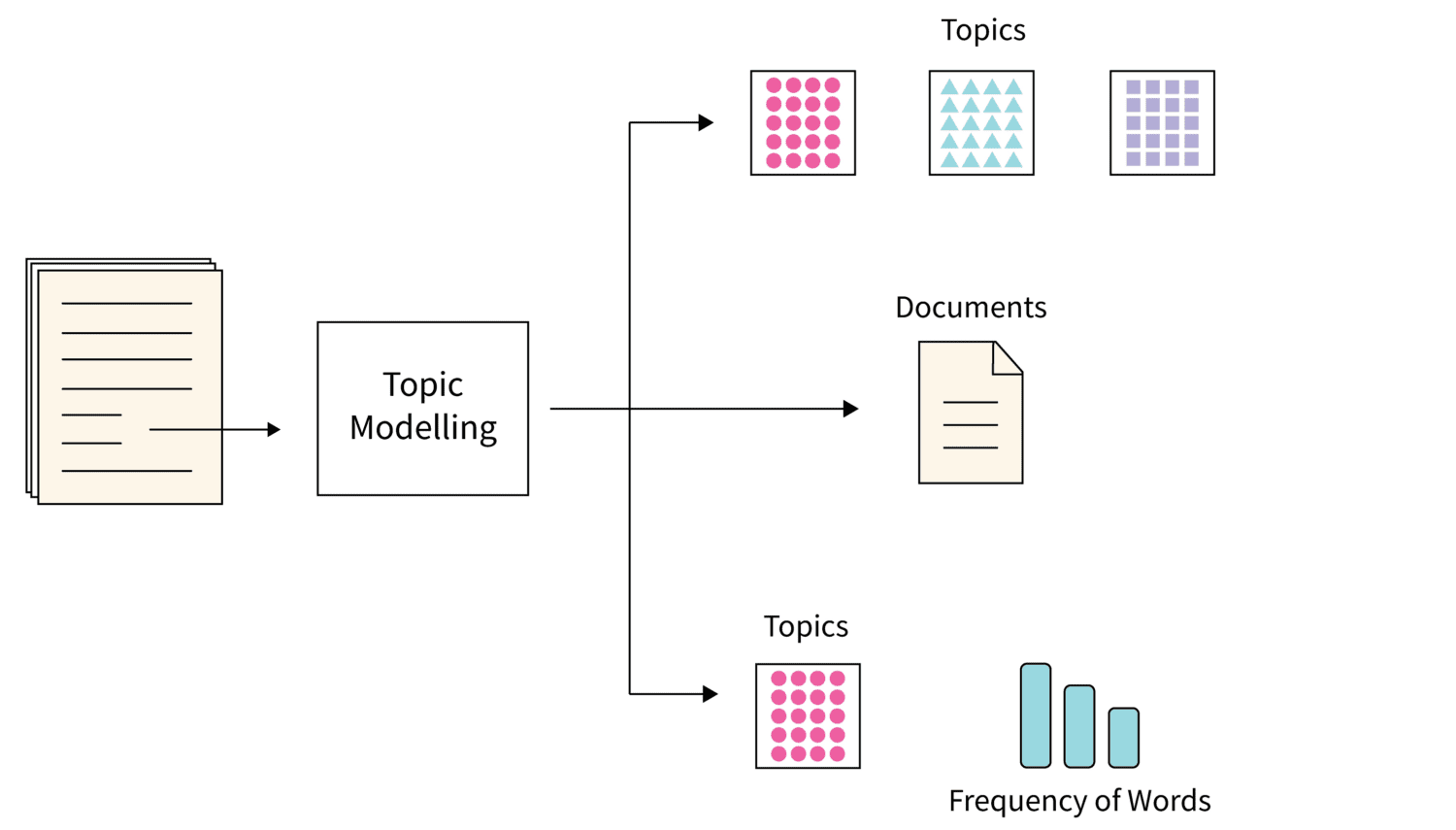 Bildkälla: Scaler
Bildkälla: Scaler
Ämnesmodellering är en algoritm som använder statistiska NLP-tekniker för att identifiera teman eller huvudämnen i stora mängder textdokument. Algoritmen hjälper maskiner att identifiera ämnet som bäst beskriver en specifik textsamling. Eftersom varje samling textdokument kan innehålla flera ämnen, använder algoritmen lämpliga tekniker för att upptäcka varje ämne genom att utvärdera specifika ordförråd.
Latent Dirichlet Allocation är ett populärt val när det gäller att använda bästa teknik för ämnesmodellering. Det är en oövervakad maskininlärningsalgoritm och hjälper till att ackumulera och organisera stora arkiv med data som inte är möjligt genom manuell annotering.
#2. Textsammanfattning
Detta är en krävande NLP-teknik där algoritmen sammanfattar en text på ett kortfattat och flytande sätt. Det är en snabb process eftersom sammanfattning hjälper till att extrahera all värdefull information utan att analysera varje ord.
Sammanfattningen kan ske på två sätt:
- Extraktionsbaserad sammanfattning: Maskinen extraherar de viktigaste orden och fraserna från dokumentet utan att ändra originalet.
- Abstraktionsbaserad sammanfattning: Nya ord och fraser skapas från textdokumentet för att förmedla all information och avsikt.
#3. Sentimentanalys
Sentimentanalys är en NLP-algoritm som hjälper en maskin att förstå innebörden och avsikten bakom en användares text. Det är populärt och används i olika AI-modeller av företag eftersom det hjälper dem att förstå vad kunder tycker om deras produkter eller tjänster.
Genom att analysera avsikten i en kunds text- eller röstdata på olika plattformar kan AI-modeller identifiera kundens känslor och hjälpa företag att anpassa sin respons därefter.
#4. Nyckelordsextraktion
Nyckelordsextraktion är en annan populär NLP-algoritm som hjälper till att identifiera relevanta ord och fraser i stora mängder textdata. Det finns flera algoritmer för nyckelordsextraktion, såsom TextRank, Term Frequency och RAKE. Vissa algoritmer kan använda extra ord, medan andra fokuserar på innehållet i den givna texten.
Varje algoritm för nyckelordsextraktion använder sin egen metod. Det är fördelaktigt för organisationer då det hjälper dem att lagra, söka och hämta information från stora mängder ostrukturerad data.
#5. Kunskapsgrafer
Kunskapsgrafer är ett utmärkt val av NLP-algoritm. Den använder en trippelstruktur för att lagra information. Den består av tre delar: ämne, predikat och objekt. Att skapa kunskapsgrafer kräver flera NLP-tekniker för att vara effektiva och detaljerade. Ämnesansatsen används för att extrahera information från ostrukturerad text.
#6. TF-IDF
TF-IDF är en statistisk NLP-algoritm som bedömer vikten av ett ord i ett dokument som tillhör en stor samling. Denna teknik använder två distinkta värden:
- Termfrekvens: Detta värde anger antalet gånger ett ord förekommer i ett visst dokument. Stoppord har vanligtvis en hög termfrekvens.
- Invers dokumentfrekvens: Denna värdering framhäver ord som är specifika för ett dokument eller som förekommer mindre i en hel samling dokument.
#7. Ordmoln
Ordmoln är en NLP-algoritm som använder datavisualisering. Viktiga ord markeras och visas i en tabell. De viktigaste orden visas med större typsnitt, medan de minst viktiga visas med små teckensnitt. Ibland visas de mindre viktiga orden inte alls.
Läroresurser
Förutom den information som nämns ovan, kan du överväga följande kurser och böcker om du vill lära dig mer om naturlig språkbehandling (NLP).
#1. Datavetenskap: Naturlig Språkbehandling i Python

Denna kurs från Udemy har fått höga betyg av studenterna och är noggrant skapad av Lazy Programmer Inc. Den ger en omfattande genomgång av NLP och NLP-algoritmer och lär dig hur man utför sentimentanalyser. Med en total längd på 11 timmar och 52 minuter erbjuder kursen 88 föreläsningar. Udemy
#2. Naturlig Språkbehandling: NLP med Transformatorer i Python
Denna populära Udemy-kurs ger dig kunskap om NLP och transformatormodeller, samt ger dig möjligheten att skapa finjusterade transformatormodeller. Kursen erbjuder 11,5 timmars on-demand-video och fem artiklar. Du kommer också att lära dig om vektorbyggnadstekniker och förbearbetning av textdata för NLP. Udemy
#3. Naturlig Språkbehandling med Transformatorer
Denna bok publicerades först 2017 och syftar till att hjälpa datavetare och programmerare att lära sig om NLP. Genom att läsa boken kommer du att lära dig att bygga och optimera transformatormodeller för olika NLP-uppgifter. Du kommer även att lära dig att använda transformatorer för språköverskridande överföringsinlärning. Amazon
#4. Praktisk Bearbetning av Naturligt Språk
I denna bok har författarna förklarat uppgifterna, problemen och lösningarna inom NLP. Boken lär dig också hur man implementerar och utvärderar olika NLP-applikationer. Amazon
Slutsats
NLP är en viktig del av den moderna AI-världen som hjälper maskiner att förstå och tolka mänskliga språk. NLP-algoritmer används i en mängd olika applikationer, från sökmotorer och IT till finans, marknadsföring och andra områden. För att underlätta djupare förståelse har vi tillhandahållit detaljer samt rekommenderade några av de bästa NLP-kurserna och böckerna som du kan använda för att förbättra dina kunskaper om NLP.