Identifiering av namngivna entiteter (NER) är en kraftfull metod för att förstå textinformation och lokalisera specifika enheter eller taggar i texten för diverse tillämpningar.
NER banar väg för en djupare språkuppfattning, genom att kategorisera allt från personnamn till datum, organisationer, platser och mycket mer.
Många företag hanterar stora mängder information, inklusive innehåll, personuppgifter, kundåterkopplingar och produktbeskrivningar.
När du behöver snabb tillgång till information krävs ofta omfattande sökningar, vilket kan vara resurskrävande och tidskonsumerande, särskilt vid hantering av stora datamängder.
NER erbjuder ett effektivt sätt för organisationer att söka och hitta rätt information.
I denna artikel kommer jag att fördjupa mig i detaljerna kring NER, inklusive dess matematiska fundament, olika användningsområden och andra viktiga aspekter.
Låt oss börja!
Vad är identifiering av namngivna entiteter?
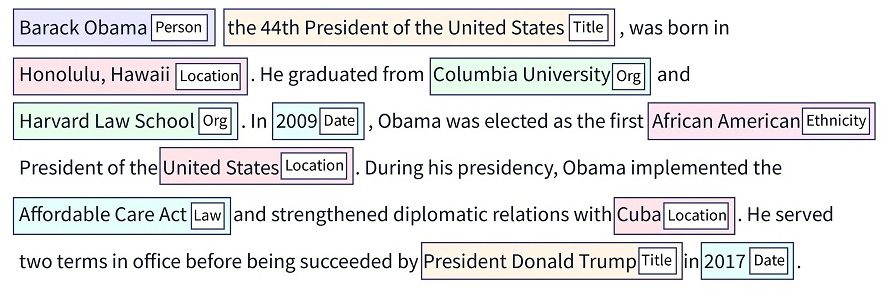
Identifiering av namngivna entiteter (NER) är en gren inom bearbetning av naturligt språk (NLP) som syftar till att identifiera och kategorisera enheter i ostrukturerad text.
Dessa enheter omfattar en rad informationstyper, som företag, platser, individers namn, numeriska värden och datum. Genom att möjliggöra maskinell extraktion av dessa enheter blir NER ett värdefullt verktyg för applikationer som översättning och frågehantering i flera branscher.
Källa: Skalare
NER strävar efter att lokalisera och kategorisera olika enheter i ostrukturerad text till fördefinierade kategorier som organisationer, medicinska termer, kvantiteter, personnamn, procenttal, monetära värden och tidsuttryck.
Låt oss illustrera detta med ett exempel:
[Anna] köpte en fastighet av [TechSolutions AB] år [2023]. Här representerar de markerade delarna de enheter som identifierats av NER och klassificeras som:
- Anna – Namn på en person
- TechSolutions AB – Organisation
- 2023 – Tidsangivelse
NER används inom flera områden av AI, inklusive djupinlärning, maskininlärning (ML) och neurala nätverk. Den är en viktig komponent i NLP-system, som verktyg för sentimentanalys, sökmotorer och chatbots. Dessutom används den i finans, kundsupport, högre utbildning, hälsovård, personalhantering och sociala medier.
Kort sagt, NER identifierar, klassificerar och extraherar viktig information från ostrukturerad text utan behov av mänsklig analys. Den kan snabbt extrahera viktig information från stora datamängder.
Dessutom ger NER organisationer viktig insikt i produkter, marknadstrender, kunder och konkurrenter. Inom hälso- och sjukvården används till exempel NER för att extrahera medicinsk information från patientjournaler. Många företag använder det för att övervaka omnämnanden i olika publikationer.
Nyckelbegrepp: NER

För att förstå NER är det viktigt att känna till grundläggande koncept. Låt oss utforska några nyckeltermer inom NER.
- Namngiven enhet: Varje ord som refererar till en plats, organisation, person eller annan specifik enhet.
- Korpus: En samling av varierande texter som används för att analysera språk och träna NER-modeller.
- POS-taggning: En process där ord i texten märks med motsvarande ordklasser, såsom adjektiv, verb och substantiv.
- Chunking: En process för att gruppera ord i meningsfulla fraser baserat på syntaktisk struktur och ordklass.
- Tränings- och testdata: Denna process innebär att träna en modell med märkta data och sedan utvärdera modellens prestanda på en separat uppsättning data.
Användning av NER i NLP

NER har många tillämpningar inom NLP, inklusive sentimentanalys, rekommendationssystem, frågehantering och informationsutvinning.
- Sentimentanalys: NER används för att identifiera känslor som uttrycks i en mening eller ett stycke i förhållande till en specifik namngiven enhet, som en produkt eller tjänst. Denna information används för att förbättra kundupplevelsen och identifiera förbättringsområden.
- Rekommendationssystem: NER används för att identifiera användares preferenser och intressen baserat på namngivna enheter som nämns i onlineinteraktioner eller sökfrågor. Detta används för att förbättra användarupplevelsen genom personliga rekommendationer.
- Frågehantering: NER används för att upptäcka specifika enheter i text, som sedan används för att svara på en fråga. Detta är vanligt i virtuella assistenter och chatbots.
- Informationsutvinning: NER används för att extrahera viktig information från stora mängder ostrukturerad text, inklusive inlägg i sociala medier, recensioner online och nyhetsartiklar. Denna data används för att generera värdefulla insikter och fatta datadrivna beslut.
Matematiska koncept: NER
NER-processen involverar olika matematiska begrepp, som maskininlärning, djupinlärning och sannolikhetsteori. Här är några matematiska tekniker:
- Dolda Markov-modeller: Dolda Markov-modeller (HMM) är en statistisk metod för sekvensklassificeringsuppgifter, som NER. Detta innebär att en sekvens av ord i texten representeras som olika tillstånd, där varje tillstånd representerar en specifik namngiven enhet. Genom att analysera sannolikheterna kan man identifiera namngivna enheter i texten.
- Djupinlärning: Djupinlärningstekniker som neurala nätverk används i NER-uppgifter, vilket möjliggör effektiv och korrekt identifiering och kategorisering av namngivna enheter.
- Villkorliga slumpmässiga fält: Dessa ingår i en grafisk modell som används i sekvensmärkningsuppgifter. De erbjuder villkorad sannolikhetsmodellering för varje tagg som ingår i ordsekvensen, vilket möjliggör identifiering av namngivna enheter i texten.
Hur fungerar NER?
Källa: ACS-publikationer
Identifiering av namngivna entiteter (NER) fungerar som en form av informationsutvinning. Processen är indelad i olika steg:
#1. Förbearbeta texten
Det första steget i NER involverar bearbetning av textinformation för analys. Vanliga uppgifter är tokenisering, där texten delas upp i mindre enheter innan NER börjar identifiera enheter.
Till exempel kan ”Lisa Johansson grundade Innovativa AB” delas upp i token som ”Lisa”, ”Johansson”, ”grundade” och ”Innovativa AB”.
#2. Identifiera enheter
Potentiella namngivna enheter kan identifieras med hjälp av statistiska metoder eller språkliga regler. Detta steg använder mönsterigenkänning, som specifika format (datum) eller versaler (i namn som ”Lisa Johansson”). Efter förbearbetningen skannar NER-algoritmer texten för att identifiera sekvenser som motsvarar enheter.
#3. Klassificera enheter
Efter att NER har identifierat enheterna kategoriseras de i olika typer, klasser eller grupper. Vanliga kategorier är organisation, datum, plats och person. Detta görs med hjälp av maskininlärningsmodeller tränade med märkt data.
Till exempel skulle ”Lisa Johansson” identifieras som en ”person” och ”Innovativa AB” som en ”organisation”.
#4. Kontextuell analys
NER nöjer sig inte med att endast känna igen och klassificera enheter, utan analyserar även sammanhanget för ökad noggrannhet. Detta steg beaktar sammanhanget där enheterna visas, vilket bidrar till korrekt kategorisering.
Till exempel i meningen ”Lisa Johansson grundade Innovativa AB” hjälper sammanhanget systemet att identifiera ”Lisa” som ett personnamn och inte en betalningsfaktura.
#5. Efterbehandling
Efter den första identifieringen och kategoriseringen är efterbehandling nödvändig för att finjustera de slutliga resultaten. Det innefattar att lösa tvetydigheter, använda kunskapsbaser och slå samman enheter bestående av flera ord för att förbättra enhetsdatan.
NERs styrka ligger i dess förmåga att tolka och förstå ostrukturerad text som innehåller viktig data för företag. Den extraherar data från nyhetsartiklar, webbsidor, forskningsrapporter, sociala medieinlägg och mer.
Genom att känna igen och kategorisera namngivna enheter ger NER texten ytterligare struktur och mening.
Metoder för NER

De vanligaste metoderna är:
#1. Övervakad maskininlärningsbaserad metod
Denna metod använder maskininlärningsmodeller som tränas på texter som har märkts manuellt med namngivna entitetskategorier.
Denna metod använder algoritmer, som maximal entropi och villkorliga slumpmässiga fält, för att generera komplexa statistiska språkmodeller. Metoden är effektiv för att hantera språkliga betydelser och andra komplexiteter, men kräver stora mängder träningsdata.
#2. Regelbaserade system
Denna metod använder regler för att samla in information. Det kan handla om att identifiera titlar eller versaler, som ”Herr”. Mänsklig inblandning är nödvändig för att mata in, övervaka och justera reglerna. Denna metod kan missa textvariationer som inte ingår i träningskommentarerna. Därför är regelbaserade system inte lika bra som maskininlärningsmodeller när det gäller komplexitet.
#3. Ordboksbaserade system
I denna metod används en ordbok med synonymer och termer för att identifiera och verifiera namngivna identiteter. Metoden har svårigheter med att kategorisera namngivna enheter med olika stavningar.
Det finns också många nya NER-metoder. Låt oss diskutera dem också:
#4. Oövervakade maskininlärningssystem
Dessa ML-system använder modeller som inte är förtränade på textdata. Oövervakade inlärningsmodeller har ofta bättre prestanda än övervakade modeller för komplexa uppgifter.
#5. Bootstrapping-system
Bootstrapping-system, även kända som självövervakade system, kategoriserar namngivna enheter baserat på grammatiska egenskaper som ordklasstaggar, versaler och andra förtränade kategorier.
En människa justerar sedan systemet genom att markera förutsägelser som felaktiga eller korrekta och lägger till de korrekta i träningsdatan.
#6. Neurala nätverkssystem
Dessa system bygger NER-modeller med hjälp av dubbelriktade arkitekturinlärningsmodeller (dubbelriktade kodarrepresentationer från transformatorer), neurala nätverk och kodningstekniker. Denna metod minimerar mänsklig inblandning.
#7. Statistiska system
Denna metod använder probabilistiska modeller som tränas på textuella relationer och mönster. Det underlättar enkel identifiering av namngivna enheter från ny textbaserad data.
#8. Semantiska rollmärkningssystem
Detta system förbearbetar NER-modeller med semantiska inlärningstekniker som lär sig relationen mellan kategorier och sammanhang.
#9. Hybridsystem
Denna metod kombinerar aspekter från flera olika tillvägagångssätt.
Fördelar med NER
NER-modeller erbjuder många fördelar:
- NER automatiserar datautvinningsprocessen för stora datamängder.
- Det används i olika branscher för att extrahera viktig information från ostrukturerad text.
- Det sparar tid för personal som annars skulle utföra datautvinning manuellt.
- Det kan förbättra precisionen i NLP-processer och -uppgifter.
- Det säkerställer datasäkerhet genom att vara värd för anpassade NER-modeller, vilket eliminerar behovet av att dela känslig information med tredje part.
- Det anpassar sig till nya entitetstyper och terminologier i takt med att domänen utvecklas.
NERs utmaningar
- Tvetydighet: Ord i text kan vara tvetydiga. Till exempel kan ordet ”Amazon” syfta på ett företag, en flod eller en regnskog. Kontexten hjälper till att skilja betydelsen, vilket gör identifieringen svårare.
- Kontextberoende: Ord får olika betydelser beroende på sammanhanget. Till exempel kan ”Äpple” i en teknisk text syfta på företaget, medan det i ett annat sammanhang syftar på frukten. Detta gör det svårare att korrekt identifiera entiteten.
- Datasparsitet: För ML-baserade NER-metoder är tillgången på märkt data avgörande. Att extrahera sådan data, särskilt för specialiserade områden eller mindre vanliga språk, kan vara en utmaning.
- Språkvariationer: Mänskliga språk varierar i dialekter, regionala skillnader och slang. Detta gör det svårt att tolka text på främmande språk.
- Modellgeneralisering: NER-modeller kan vara mycket duktiga på att klassificera enheter inom ett specifikt område, men ha svårt att generalisera i ett annat. NER-modeller kan alltså fungera olika i olika domäner.
Dessa utmaningar kan hanteras med hjälp av avancerade algoritmer, språklig kompetens och kvalitetsdata. Forskning och utveckling är viktigt för att hantera dessa utmaningar när NER utvecklas.
Användningsfall för NER
#1. Kategorisering av innehåll

Förlag och nyhetsbyråer genererar stora mängder onlineinnehåll. Effektiv hantering av detta är avgörande för att få ut det mesta av varje artikel eller nyhet.
NER skannar allt innehåll automatiskt och extraherar data som organisationer, platser och personnamn. Att känna till relevanta taggar för varje artikel underlättar kategorisering i den definierade hierarkin, vilket förbättrar innehållsleveransen.
#2. Sökalgoritmer
Anta att du har en intern sökmotor för din onlinepublikation som innehåller miljontals artiklar. För varje sökfråga samlar den alla ord från dessa artiklar, vilket är tidskrävande.
Om du använder NER för din onlinepublikation hämtar den istället enkelt de relevanta enheterna från alla artiklar och lagrar dem separat, vilket snabbar upp sökprocessen.
#3. Innehållsrekommendationer
Automatisering av rekommendationsprocessen är ett viktigt användningsfall för NER. Rekommendationssystem hjälper användare att upptäcka nya idéer och innehåll.
Netflix är ett bra exempel på detta. Ett effektivt rekommendationssystem kan hjälpa dig att skapa mer engagemang.
För nyhetsutgivare kan NER användas för att rekommendera liknande artiklar genom att samla taggar från en specifik artikel och rekommendera innehåll med liknande enheter.
#4. Kundsupport

Kundsupport är avgörande för alla organisationer. Det finns flera sätt att hantera kundfeedback smidigt, och NER är en av dem. Låt oss illustrera detta med ett exempel.
Anta att en kund lämnar feedback: ”Personalen i Adidas butik i Stockholm saknar detaljerad kunskap om sportskor.” Här extraherar NER taggarna ”Stockholm” (plats) och ”sportskor” (produkt).
NER kan alltså användas för att kategorisera feedback och skicka den till rätt avdelning inom organisationen. Det går även att skapa en databas med feedback kategoriserad per avdelning för vidare analys.
#5. Forskningsrapporter
En onlinepublikation eller tidskriftswebbplats kan innehålla ett stort antal vetenskapliga artiklar och forskningsrapporter. Det kan finnas många rapporter som liknar varandra men med små skillnader. Att organisera all denna data strukturerat kan vara komplicerat.
Genom att använda NER kan man sortera rapporterna baserat på relevanta taggar.
Till exempel kan det finnas tusentals artiklar om maskininlärning. Om du letar efter en som nämner användningen av faltningsnätverk (CNN) behöver du lägga till enheter. Detta gör det möjligt att snabbt hitta artikeln som matchar dina krav.
Slutsats
NLP-tekniken, Named Entity Recognition (NER), hjälper till att identifiera namngivna enheter i ostrukturerad text och kategorisera dem i fördefinierade grupper som platser, personnamn och produkter.
Huvudsyftet med NER är att samla in strukturerad information från ostrukturerad text och presentera den i ett läsbart format. Den använder olika modeller och processer och erbjuder många fördelar för yrkesverksamma och företag. Den används också för många tillämpningar inom NLP.
Jag hoppas att du har en bra förståelse för tekniken och kan implementera den i din verksamhet för att få relevant och värdefull information i tid.
Du kan även utforska några av de bästa NLP-kurserna för att lära dig mer om bearbetning av naturligt språk.