Förbättra din SEO med REGEX i Google Search Console
Google Search Console (GSC) är ett oumbärligt verktyg för SEO-specialister som vill granska och förbättra en webbplats prestanda. Med introduktionen av REGEX (reguljära uttryck) har möjligheterna att analysera data och hitta värdefulla insikter ökat avsevärt.
REGEX var en länge efterfrågad funktion som möjliggör avancerad filtrering av URL:er och data, något som tidigare var svårt eller till och med omöjligt att uppnå. Nu kan du dyka djupare in i din webbplats data och få fram unika slutsatser.
I denna artikel kommer du att lära dig grunderna i hur du kan använda REGEX i Google Search Console och vilka olika operatorer och koder som du kan kombinera för att nå dina analysmål.
REGEX: En introduktion
Google Search Console är en kostnadsfri tjänst som ger webbansvariga möjlighet att övervaka webbplatsens prestanda. GSC erbjuder detaljerade rapporter över klickfrekvens, visningar, klick och sökordsrankningar. Dessa data är avgörande för att förstå hur väl dina SEO-kampanjer presterar.
Tidigare fanns det begränsningar i hur du kunde filtrera data från specifika URL:er. GSC tillät endast export av maximalt 1000 rader för analys, och filtreringen var begränsad till enkla element som sökvägar, domäner eller prefix. Mer komplexa strängar och varianter var svåra att hantera.
Med REGEX kan SEO-experter dra nytta av ett kraftfullt system för att få djupare insikter i en webbplats funktion och prestanda. REGEX-koder används i sid- eller frågefilter och består av metatecken som omsluter en sträng relaterad till filterparametern. Resultaten kan sparas för senare referens.
Fördelarna med att Använda REGEX i GSC
I Google Search Console analyseras webbplatsen ur en teknisk synvinkel. SEO-team använder olika verktyg och strategier för att optimera webbplatsens ranking på sökmotorer och driva trafik. Med REGEX får du ett ännu mer värdefullt verktyg för datainsamling.
Här är några fördelar med att använda REGEX:
✨ Du kan använda REGEX-koder för att identifiera sökvolymen för specifika sökord eller fraser. Detta hjälper dig skapa nya innehållsidéer och generera mer trafik.
✨ REGEX sparar tid för SEO-specialister som arbetar med stora datamängder. Med rätt syntax kan du snabbt sortera frågor och sidor för specifika behov.
✨ Du kan filtrera efter specifika kombinationer av ord, meningar och webbadresser genom att placera tecknen i rätt ordning.
✨ Få bättre insikter i webbplatsens prestanda, inklusive både hög- och lågpresterande sidor och identifiera trender.
✨ Använd REGEX i anpassade rapporter för att spåra trafikflödet på specifika webbsidor för vissa frågor. Detta ger teamet insikt i vilken riktning som är bäst att arbeta.
Du kan kombinera flera REGEX-tecken för att skapa en kod som kan ge dig lösningar för att optimera din webbplats.
Var Använder du REGEX i Google Search Console?
För att använda REGEX i GSC måste du ha äganderätt till webbplatsen. Det är ett obligatoriskt krav för att få tillgång till analysverktyget.
Logga in på Google Search Console med ditt Gmail-ID och lägg till din webbplats som en egendom. En egendom är webbplatsen du äger eller har behörighet att komma åt i konsolen.
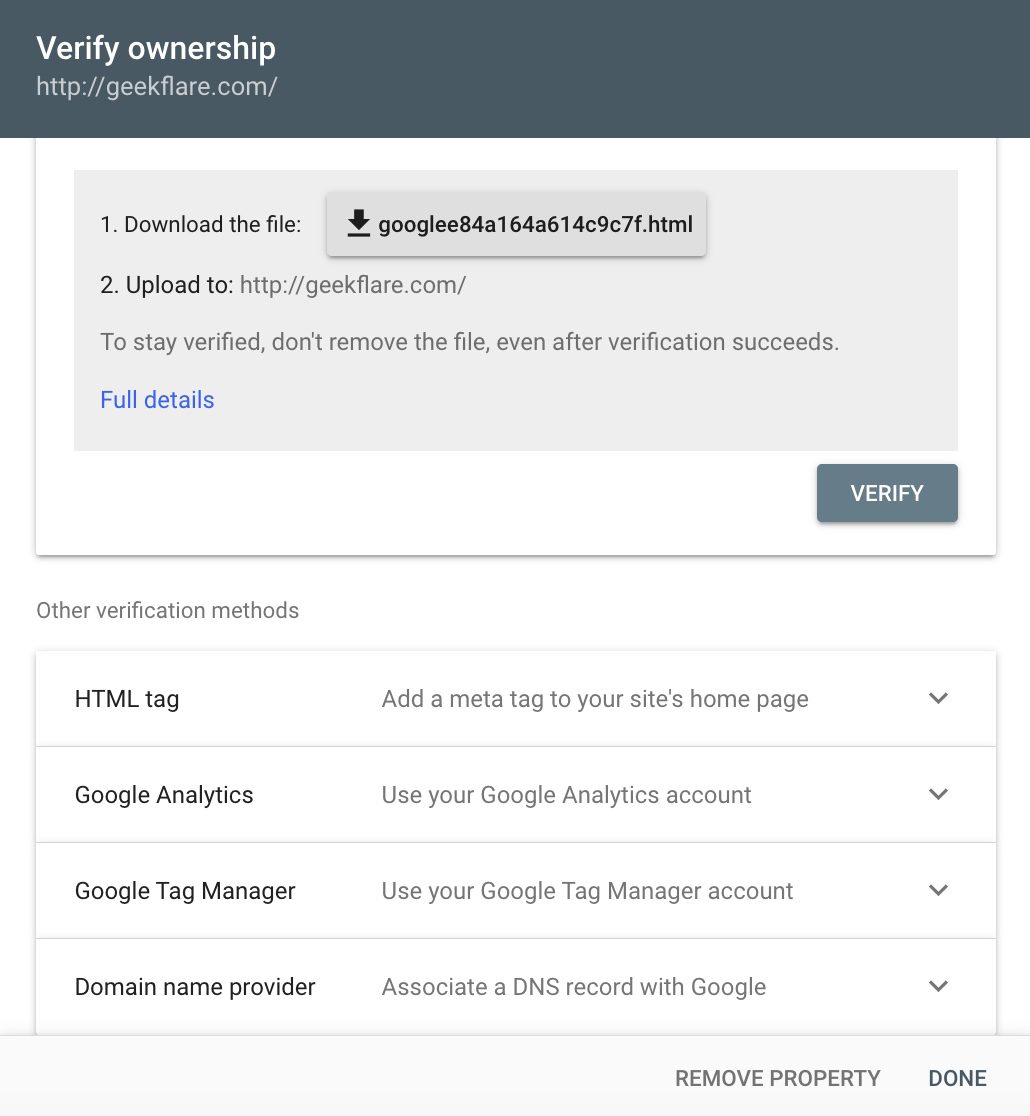
Efter att du har lagt till din webbplats eller webbadress kommer du att behöva verifiera den. Efter verifieringen kan du välja din egendom.
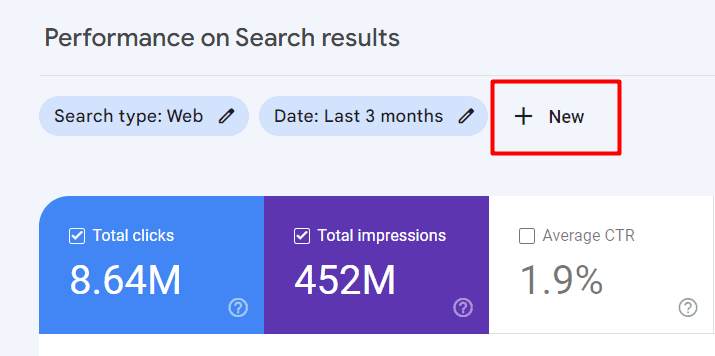
Klicka på ”Prestanda” och sedan på ”Ny” ovanför diagrammet för att använda filteralternativen.
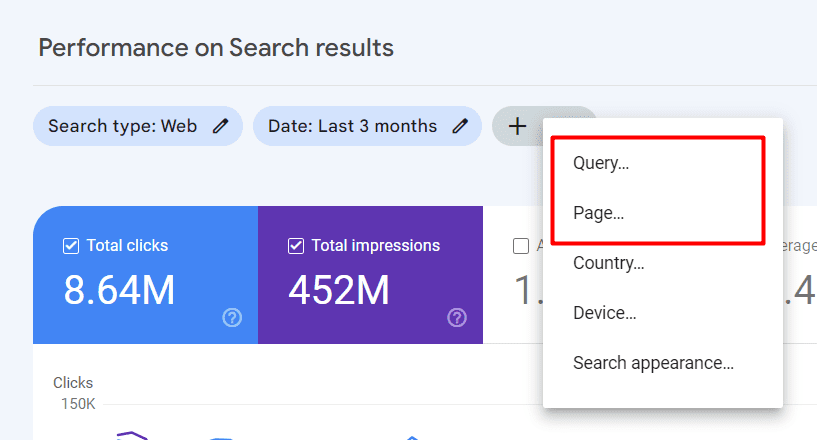
Välj ”Fråga” eller ”Sidor” för att använda REGEX-koder och filtrera resultaten.
REGEX-tecken Förklarade
Det finns flera tecken som används i REGEX för att filtrera frågor och sidor i Google Search Console. Varje tecken har en specifik betydelse i filtret. Genom att lära dig dem kommer det att bli enklare att utföra avancerade analyser i GSC med hjälp av REGEX.
Här är en tabell med några av de vanligaste tecknen och symbolerna som används i REGEX-koder:
| Tecken | Användning | Exempel |
| () | Parenteser används för att gruppera tecken eller uttryck, även kända som fånga grupper. | (Geek) – matchar alla webbsidor med ordet ”Geek”. |
| [] | Klammerparenteser matchar något av tecknen i parentesen. | [xyz] – matchar frågor som innehåller x, y eller z. |
| [^] | Med ett inledande ^ i klammerparentesen, matchar detta allt utom tecknen i parentesen. | [^\mobile] – filtrerar URL:er som inte har ordet ”mobil”. |
| | | ”ELLER”-symbolen som används för att tillämpa val i koden. | Mobil|PC – hämtar alla sidor med antingen ordet ”Mobil” eller ”PC”. |
| ^ | ”Caret”-symbolen som matchar början av en sträng. | ^Mobil – matchar alla webbsidor där ordet ”Mobil” är i början av titeln. |
| $ | Dollarsymbolen matchar slutet av en sträng. | Mobile$ – matchar alla sidor med ordet ”Mobil” i slutet av titeln. |
| . | En punkt matchar ett enskilt tecken. | to. – matchar tex ”top” eller ”tor”. |
| \ | Omvänt snedstreck som används för att hoppa över teckens bokstavliga betydelse. | \d – matchar sidor med siffrorna 0-9. |
| [c-m] | Matchar alla gemener eller versaler som faller mellan c och m. | Mobile[c-m] – matchar sidor som har en kombination av ordet ”mobil” med bokstäver mellan c och m. |
| [3-7] | Matchar nummer som faller mellan 3 och 7. | Mobile[3-7] – matchar sidor som har ordet ”mobil” med nummer mellan 3 och 7. |
| [\w] | Matchar alla ord på webbsidorna. | [\w]*Mobil[\w] – Matchar ord som har ordet ”mobil” med andra tecken runt omkring. |
| [\W] | Matchar allt utom bokstäver och siffror, inklusive blanksteg och specialtecken. | [\W]*Mobil[\W] – Matchar ord som har ordet ”mobil” tillsammans med specialtecken eller mellanslag. |
Med dessa tecken kan du skapa flera koder för att filtrera komplexa frågor i GSC.
Specifika REGEX-koder i Google Search Console
Du kan skapa unika mönster eller koder med hjälp av metatecken för specifika syften. Här är några exempel som du kan prova i din GSC-portal:
🔶 ^[\w\W\s\S]{70,}$
Denna kod matchar strängar med ord, siffror, specialtecken, blanksteg och nya rader som är minst 70 tecken långa.
Exempel: Används för att verifiera lösenord, sortera produktlistor med utarbetade beskrivningar med mera.
🔶 (\w+\s){6,}\w+
Koden matchar strängar som innehåller minst 6 ord med mellanslag mellan dem.
Exempel: Används för att filtrera artiklar med långa titlar eller kommentarer i sociala medier.
🔶 ^(vem|vad|var|när|varför|hur)[“ “]
Matchar alla frågor som börjar med orden vem, vad, var, när, varför eller hur, följt av ett mellanslag.
Exempel: Används för att förstå marknadstrender och användardiskussioner för att generera innehållsidéer.
🔶 ”vem|vad|var|när|varför|hur”
Matchar strängar som innehåller något av orden vem, vad, var, när, varför eller hur, oavsett var i strängen de förekommer.
Exempel: Används för att filtrera användarinmatningar eller identifiera osäkra påståenden.
🔶 .*
Ett jokertecken som kan matcha vilken sträng som helst.
Exempel: .*Android.* hämtar alla sidor som innehåller ordet ”Android”. Genom att använda .* ensamt får du alla sidor som visats i sökmotorn under en månad.
🔶 [^\/\.\-:0-9A-Za-z_]
Matchar strängar som inte innehåller snedstreck, siffror, punkt, kolon, bindestreck eller alfabet (både stora och små bokstäver).
Exempel: Används för att hitta webbadresser, metabeskrivningar eller innehåll som har specialtecken som &%$@.
🔶 (?i)(((är|är).(varumärke|webbplats|företag)|(varumärke|webbplats|företag).(är|är)).*(avskum|pålitlig))
En kod som är skiftlägesokänslig och matchar frågor som inkluderar orden ”är” eller ”är”, ”varumärke”, ”företag” eller ”webbplats”, samt ”avskum” eller ”pålitlig”.
Exempel: Används för att analysera kundfrågor och avgöra om de är positiva eller negativa.
🔶 (kwd1|kwd2).*
En enkel kod som filtrerar sidor eller frågor med antingen ordet kwd1 eller kwd2, följt av andra tecken.
Exempel: Kan användas för att extrahera sidor med specifika nyckelord.
🔶 (Sökord1 OCH Nyckelord2)
En kod som används för att få sidor som har båda de givna orden i samma sekvens.
Exempel: Kan användas för att få sidor, titlar eller metabeskrivningar med två specifika ord i samma ordning.
🔶 "sökord1 sökord2"
Matchar en fras eller exakt ordning av ord på en webbsida.
Exempel: Används för att hitta sidor med en specifik fras i titeln, beskrivningen eller innehållet.
🔶 (Sökord1 | Nyckelord2)
Visar sidor som har antingen ”Sökord1” eller ”Nyckelord2”, men inte båda.
Exempel: Används för att extrahera sidor som innehåller något av de två eller flera orden åtskilda med piptecken.
🔶 (Sökord1)\b(Sökord2)\b
Hämtar sidor med två ord utan andra ord, siffror eller tecken mellan dem.
Exempel: Används för att identifiera sidor som har två separata ord i följd.
🔶 (Sökord1)\w+(Sökord2)
Hämtar sidor med två ord med ett eller flera tecken emellan, oavsett om det är i titel, beskrivning eller innehåll.
Exempel: Används för att hitta sidor som innehåller två specifika ord var som helst.
🔶 (Sökord)\bfras
Matchar strängar med ordet inom parentes följt av ordfrasen, utan några tecken mellan orden.
Exempel: Används för att hitta sidor som har givna ord i följd, t.ex. ”sökordsfras”.
🔶 a-url.|.b-url.|.c-url.|.e-url.|.f-url.|.g-url.|.h-url.|.i-url.|.j -url.|.k-url.|.l-url.|.m-url.|.n-url.|.o-url.|.p-url.|.
Filtrerar bort strängar med en av de listade webbadresserna.
Exempel: Används för att få sidor med specifika webbadresser i titeln eller artikeln.
🔶 ^(äpple|boll|katt|ankfarm)$
Matchar början av en sträng med något av de givna orden, utan några andra tecken.
Exempel: Används för att få information om sidor som har specifika nyckelord i början.
🔶 .*\/\$
Fångar upp alla strängar som slutar med ett snedstreck.
Exempel: Används för att hitta sidor vars URL slutar med ett snedstreck.
🔶 .(bästa|topp|vs|recension).*
Matchar strängar som börjar med en punkt och har något av de givna orden, följt av andra tecken.
Exempel: Används för kommersiella rapporter för att förstå marknadstrender.
🔶 (köp|billigt|pris|köp|beställ).*
Matchar strängar med något av de givna orden, följt av andra tecken.
Exempel: Används för att hitta transaktionssökningar eller frågor relaterade till produkter.
🔶 (ansikte(b|be)ook) 🔶 (f(a|e)ce(b|be)ook 🔶 (fa(c|s)(e|i)bok)
Matchar olika stavningar av ordet ”facebook”.
Exempel: Används för att hitta potentiella felstavningar i webbsidorna.
🔶 .wp-.
Matchar strängar som har en punkt, följt av ”wp-”, följt av andra tecken.
Exempel: Används för att extrahera sidor med WordPress-webbadresser.
🔶 .*/url-1/.* kontra .*/url-2/.*
Hämtar två specifika webbadresser för att jämföra deras statistik.
Exempel: Används för att jämföra trafik och antal användare mellan två webbsidor.
Andra Ovanliga REGEX-koder
🔺 (?i)\bsökord\b
Matchar strängar med ordet ”sökord”, oavsett om det är med stora eller små bokstäver.
🔺 ”fras”
Matchar sidor som innehåller den specifika ordfrasen.
🔺 \w{5}
Matchar frågor med 5 tecken.
🔺 \d{3}
Matchar frågor med exakt 3 siffror.
🔺 ([^” “]*)
Matchar strängar som inte har några tecken inom citattecken.
🔺 (?i)\b(sökord1|sökord2|sökord3)\b
Matchar strängar som har något av de givna orden, oavsett om de är skrivna med stora eller små bokstäver.
🔺 \W+
Matchar valfritt antal icke-ordtecken, vanligtvis specialtecken.
🔺 \d{3,5}
Matchar alla strängar som har mellan 3 och 5 siffror.
🔺 \b\w+\b
Matchar valfritt antal ordtecken med ordgränser.
Slutsats
Med introduktionen av REGEX-koder har Googles sökmotor blivit en kraftfull källa till information. Förståelsen för kodernas struktur är nyckeln till att extrahera de analytiska rapporterna som behövs för att optimera en webbplats.
Skapa flera REGEX-koder i din GSC-panel för att få specifik information om din webbplats prestanda och använd den för att förbättra dina resultat.
Utforska också Googles sökfunktioner för att förbättra dina online-sökningsfärdigheter.