
Apache Kafka och RabbitMQ är två mycket använda meddelandemäklare som tillåter frikoppling av utbyte av meddelanden mellan applikationer. Vilka är deras viktigaste egenskaper och vad skiljer dem från varandra? Låt oss komma till begreppen.
Innehållsförteckning
RabbitMQ
RabbitMQ är en öppen källkodsförmedlarapplikation för kommunikation och meddelandeutbyte mellan parter. Eftersom den utvecklades i Erlang är den väldigt lätt och effektiv. Språket Erlang har utvecklats av Ericson med fokus på distribuerade system.
Det anses vara en mer traditionell meddelandemäklare. Det är baserat på utgivare-abonnentmönstret, även om det kan behandla kommunikation synkront eller asynkront, beroende på vad som är inställt i konfigurationen. Det säkerställer också leverans och beställning av meddelanden mellan producenter och konsumenter.
Den stöder AMQP, STOMP, MQTT, HTTP och web socket-protokoll. Tre modeller för utbyte av meddelanden: ämne, fanout och direkt:
- Direkt och individuellt utbyte efter ämne eller tema [topic]
- Alla konsumenter som är anslutna till kön får [fanout] meddelande
- Varje konsument får ett meddelande skickat [direct]
Följande är komponenterna i RabbitMQ:
Producenter
Producers är applikationer som skapar och skickar meddelanden till RabbitMQ. De kan vara vilken applikation som helst som kan ansluta till RabbitMQ och publicera meddelanden.
Konsumenter
Konsumenterna är applikationer som tar emot och bearbetar meddelanden från RabbitMQ. De kan vara vilken applikation som helst som kan ansluta till RabbitMQ och prenumerera på meddelanden.
Utbyten
Exchange ansvarar för att ta emot meddelanden från producenter och dirigera dem till lämpliga köer. Det finns flera typer av utbyten, inklusive direkt-, fanout-, ämnes- och rubrikutbyten, var och en med sina egna routingregler.
Köer
Köer är där meddelanden lagras tills de konsumeras av konsumenterna. De skapas av applikationer eller automatiskt av RabbitMQ när ett meddelande publiceras till en börs.
Bindningar
Bindningar definierar förhållandet mellan utbyten och köer. De specificerar routingreglerna för meddelanden, som används av växlar för att dirigera meddelanden till lämpliga köer.
Arkitektur av RabbitMQ
RabbitMQ använder en pull-modell för meddelandeleverans. I denna modell efterfrågar konsumenter aktivt mäklarens meddelanden. Meddelanden publiceras till växlar som ansvarar för att dirigera meddelanden till lämpliga köer baserat på dirigeringsnycklar.
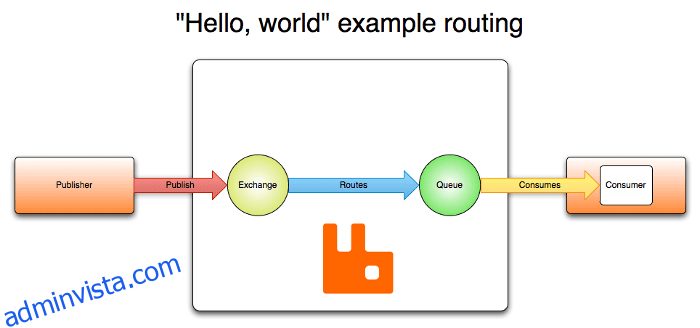
Arkitekturen för RabbitMQ är baserad på en klient-server-arkitektur och består av flera komponenter som samverkar för att tillhandahålla en pålitlig och skalbar meddelandeplattform. AMQP-konceptet tillhandahåller komponenterna Exchanges, Queues, Bindings, såväl som Publishers och Subscribers. Utgivare publicerar meddelanden till börser.
Exchange tar dessa meddelanden och distribuerar dem till 0 till n köer baserat på vissa regler (bindningar). De meddelanden som lagras i köerna kan sedan hämtas av konsumenterna. I en förenklad form görs meddelandehantering i RabbitMQ enligt följande:
 Bildkälla: VMware
Bildkälla: VMware
- Utgivare skickar meddelanden för att utbyta;
- Exchange skickar meddelanden till köer och andra växlar;
- När ett meddelande tas emot skickar RabbitMQ bekräftelser till avsändare;
- Konsumenter upprätthåller beständiga TCP-anslutningar till RabbitMQ och deklarerar vilken kö de tar emot;
- RabbitMQ skickar meddelanden till konsumenter;
- Konsumenter skickar framgångs- eller felbekräftelser om att de tagit emot meddelandet;
- Efter lyckat mottagande tas meddelandet bort från kön.
Apache Kafka
Apache Kafka är en distribuerad meddelandelösning med öppen källkod utvecklad av LinkedIn i Scala. Den kan bearbeta meddelanden och lagra dem med en utgivare-abonnentmodell med hög skalbarhet och prestanda.

För att lagra händelserna eller meddelanden som tas emot, fördela ämnena mellan noderna med hjälp av partitioner. Den kombinerar både utgivare-prenumerant- och meddelandekömönster, och den ansvarar också för att säkerställa ordningen på meddelanden för varje konsument.
Kafka är specialiserat på hög datagenomströmning och låg latens för att hantera dataströmmar i realtid. Detta uppnås genom att undvika för mycket logik på serverns (mäklare) sida, samt vissa speciella implementeringsdetaljer.
Till exempel använder Kafka inte RAM alls och skriver data direkt till serverns filsystem. Eftersom all data skrivs sekventiellt uppnås läs-skrivprestanda, vilket är jämförbart med RAM-minnet.
Dessa är huvudkoncepten för Kafka som gör den skalbar, prestanda och feltolerant:
Ämne
Ett ämne är ett sätt att märka eller kategorisera ett meddelande; föreställ dig en garderob med 10 lådor; varje låda kan vara ett ämne, och garderoben är Apache Kafka-plattformen, så förutom att kategorisera den grupperar meddelanden, skulle en annan bättre analogi om ämnet läggas upp i relationsdatabaser.
Producent
Producenten eller producenten är den som ansluter till en meddelandeplattform och skickar ett eller flera meddelanden om ett specifikt ämne.
Konsument
Konsumenten är den person som ansluter till en meddelandeplattform och konsumerar ett eller flera meddelanden om ett specifikt ämne.
Mäklare
Konceptet med en mäklare i Kafka-plattformen är inget annat än praktiskt taget Kafka själv, och det är han som hanterar ämnena och definierar sättet att lagra meddelanden, loggar, etc.
Klunga
Klustret är en uppsättning mäklare som kommunicerar med varandra eller inte för bättre skalbarhet och feltolerans.
Loggfil
Varje ämne lagrar sina poster i ett loggformat, det vill säga på ett strukturerat och sekventiellt sätt; loggfilen är därför filen som innehåller information om ett ämne.
Skiljeväggar
Partitionerna är partitionsskiktet av meddelanden inom ett ämne; denna partitionering säkerställer elasticiteten, feltoleransen och skalbarheten hos Apache Kafka så att varje ämne kan ha flera partitioner på olika platser.
Apache Kafkas arkitektur
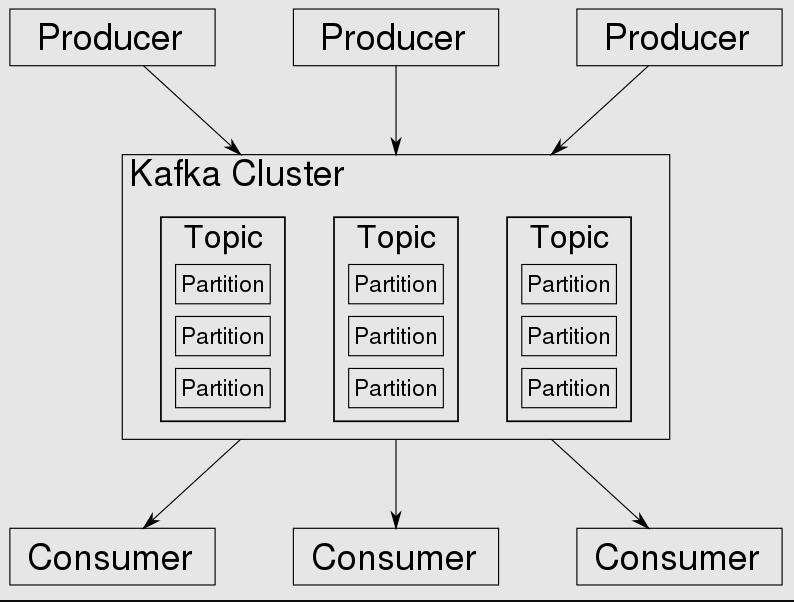
Kafka bygger på en push-modell för meddelandeleverans. Med denna modell skjuts meddelanden i Kafka aktivt till konsumenterna. Meddelanden publiceras till ämnen, som är uppdelade och fördelade över olika mäklare i klustret.
Konsumenter kan sedan prenumerera på ett eller flera ämnen och få meddelanden allt eftersom de produceras om dessa ämnen.
I Kafka är varje ämne uppdelat i en eller flera partitioner. Det är i partitionen som händelserna hamnar.
Om det finns mer än en mäklare i klustret, kommer partitionerna att fördelas jämnt över alla mäklare (så långt det är möjligt), vilket gör det möjligt att skala belastningen på att skriva och läsa i ett ämne till flera mäklare samtidigt. Eftersom det är ett kluster körs det med ZooKeeper för synkronisering.
Den tar emot butiker och distribuerar poster. En post är data som genereras av någon systemnod, vilket kan vara en händelse eller information. Det skickas till klustret och klustret lagrar det i en ämnespartition.
Varje post har en sekvensförskjutning, och konsumenten kan styra den förskjutning den förbrukar. Således, om det finns ett behov av att bearbeta ämnet, kan det göras baserat på offset.
 Bildkälla: Wikipedia
Bildkälla: Wikipedia
Logik, såsom hanteringen av det senast lästa meddelande-ID för en konsument eller beslutet om vilken partition nyinkommande data skrivs till, flyttas helt över till klienten (producent eller konsument).
Förutom begreppen producent och konsument finns det också begreppen ämne, partition och replikering.
Ett ämne beskriver en kategori av meddelanden. Kafka uppnår feltolerans genom att replikera data i ett ämne och skala genom att partitionera ämnet över flera servrar.
RabbitMQ vs Kafka
De huvudsakliga skillnaderna mellan Apache Kafka och RabbitMQ beror på fundamentalt olika meddelandeleveransmodeller implementerade i dessa system.
I synnerhet Apache Kafka arbetar efter principen att dra (dra) när konsumenterna själva får de budskap de behöver från ämnet.
RabbitMQ, å andra sidan, implementerar push-modellen genom att skicka de nödvändiga meddelandena till mottagarna. Som sådan skiljer sig Kafka från RabbitMQ på följande sätt:
#1. Arkitektur
En av de största skillnaderna mellan RabbitMQ och Kafka är skillnaden i arkitekturen. RabbitMQ använder en traditionell mäklarbaserad meddelandeköarkitektur, medan Kafka använder en distribuerad strömningsplattformsarkitektur.
RabbitMQ använder också en pull-baserad meddelandeleveransmodell, medan Kafka använder en push-baserad modell.
#2. Sparar meddelanden
RabbitMQ lägger meddelandet i FIFO-kön (First Input – First Output) och övervakar statusen för detta meddelande i kön, och Kafka lägger till meddelandet i loggen (skriver till disk), och lämnar mottagaren att ta hand om det nödvändiga information från ämnet.
RabbitMQ raderar meddelandet efter att det har levererats till mottagaren, medan Kafka lagrar meddelandet tills det är schemalagt att rensa loggen.
Således sparar Kafka nuvarande och alla tidigare systemtillstånd och kan användas som en pålitlig källa för historisk data, till skillnad från RabbitMQ.
#3. Lastbalansering
Tack vare pull-modellen för meddelandeleverans minskar RabbitMQ latensen. Det är dock möjligt för mottagarna att svämma över om meddelanden anländer till kön snabbare än de kan bearbeta dem.
Eftersom i RabbitMQ varje mottagare begär/laddar upp olika antal meddelanden, kan fördelningen av arbetet bli ojämn, vilket kommer att orsaka förseningar och förlust av meddelandeordning under bearbetningen.
För att förhindra detta konfigurerar varje RabbitMQ-mottagare en förhämtningsgräns, en gräns för antalet ackumulerade okvitterade meddelanden. I Kafka utförs lastbalansering automatiskt genom att omfördela mottagare över avsnitt (partition) av ämnet.
#4. Routing
RabbitMQ inkluderar fyra sätt att dirigera till olika växlar för att köa, vilket möjliggör en kraftfull och flexibel uppsättning meddelandemönster. Kafka implementerar bara ett sätt att skriva meddelanden till disk utan routing.
#5. Meddelandebeställning
RabbitMQ låter dig upprätthålla relativ ordning i godtyckliga uppsättningar (grupper) av händelser, och Apache Kafka ger ett enkelt sätt att upprätthålla ordning med skalbarhet genom att skriva meddelanden sekventiellt till en replikerad logg (ämne).
FunktionKaninMQKafka Arkitektur Sparar meddelanden på en disk som är ansluten till mäklaren Distribuerad strömningsplattformsarkitekturLeveransmodellPullbaseradPush-baseradSpara meddelandenKan inte spara meddelanden Underhåller beställningar genom att skriva till ett ämneLastbalansering Konfigurerar en förhämtningsgräns Utförs automatiskt RoutingInkluderar endast 4 sätt att ruttna i ordningsföljd för att beställa en ruttbeställning. till ämneExterna processerKräver inte Kräver att köra Zookeeper-instansPluginsFlera pluginsHar begränsat pluginstöd
RabbitMQ och Kafka är båda mycket använda meddelandesystem, var och en med sina egna styrkor och användningsfall. RabbitMQ är ett flexibelt, pålitligt och skalbart meddelandesystem som utmärker sig vid meddelandeköer, vilket gör det till ett idealiskt val för applikationer som kräver pålitlig och flexibel meddelandeleverans.
Å andra sidan är Kafka en distribuerad strömningsplattform som är designad för realtidsbearbetning med hög genomströmning av stora datamängder, vilket gör den till ett utmärkt val för applikationer som kräver realtidsbearbetning och analys av data.
Huvudsakliga användningsfall för RabbitMQ:
E-handel

RabbitMQ används i e-handelsapplikationer för att hantera dataflödet mellan olika system, såsom lagerhantering, orderhantering och betalningshantering. Den kan hantera stora volymer meddelanden och se till att de levereras tillförlitligt och i rätt ordning.
Sjukvård
Inom vårdbranschen används RabbitMQ för att utbyta data mellan olika system, såsom elektroniska journaler (EPJ), medicintekniska produkter och kliniska beslutsstödsystem. Det kan hjälpa till att förbättra patientvården och minska fel genom att säkerställa att rätt information är tillgänglig vid rätt tidpunkt.
Finansiella tjänster
RabbitMQ möjliggör meddelanden i realtid mellan system, såsom handelsplattformar, riskhanteringssystem och betalningsgateways. Det kan hjälpa till att säkerställa att transaktioner behandlas snabbt och säkert.
IoT-system
RabbitMQ används i IoT-system för att hantera dataflödet mellan olika enheter och sensorer. Det kan hjälpa till att säkerställa att data levereras säkert och effektivt, även i miljöer med begränsad bandbredd och intermittent anslutning.
Kafka är en distribuerad streamingplattform designad för att hantera stora mängder data i realtid.
Huvudsakliga användningsfall för Kafka
Analyser i realtid

Kafka används i realtidsanalysapplikationer för att bearbeta och analysera data när den genereras, vilket gör det möjligt för företag att fatta beslut baserat på uppdaterad information. Den kan hantera stora mängder data och skala för att möta behoven hos även de mest krävande applikationerna.
Loggaggregering
Kafka kan samla loggar från olika system och applikationer, vilket gör det möjligt för företag att övervaka och felsöka problem i realtid. Den kan också användas för att lagra loggar för långsiktig analys och rapportering.
Maskininlärning
Kafka används i maskininlärningsapplikationer för att strömma data till modeller i realtid, vilket gör det möjligt för företag att göra förutsägelser och vidta åtgärder baserat på uppdaterad information. Det kan hjälpa till att förbättra noggrannheten och effektiviteten hos modeller för maskininlärning.
Min åsikt om både RabbitMQ och Kafka
Nackdelen med RabbitMQs breda och varierande möjligheter för flexibel hantering av meddelandeköer är ökad resursförbrukning och följaktligen prestandaförsämring under ökad belastning. Eftersom detta är arbetssättet för komplexa system är Apache Kafka i de flesta fall det bästa verktyget för att hantera meddelanden.
Till exempel, i fallet med att samla in och aggregera många händelser från dussintals system och tjänster, med hänsyn till deras georeservation, klientmätvärden, loggfiler och analyser, med utsikten att öka informationskällorna, kommer jag att föredra att använda Kafka, men om du befinner dig i en situation där du bara behöver snabba meddelanden kommer RabbitMQ att göra jobbet bra!
Du kan också läsa hur du installerar Apache Kafka i Windows och Linux.