Effektiv Webbskrapning med Google Kalkylark
Webbskrapning, konsten att automatiskt utvinna information från webbplatser, är ett kraftfullt verktyg för dataanalys. Även om manuell dataextraktion är möjlig, är det ofta en tidsödande och besvärlig process. Dedikerade webbskraparverktyg effektiviserar detta arbete, minskar tidsåtgången och sänker kostnaderna.
Överraskande nog kan Google Kalkylark fungera som ett allt-i-ett-verktyg för webbskrapning, tack vare dess inbyggda funktion IMPORTXML. Med denna funktion kan du enkelt hämta data från webbsidor och använda den för analys, rapportering eller andra datadrivna projekt.
Funktionen IMPORTXML i Google Kalkylark
Google Kalkylark inkluderar funktionen IMPORTXML, som låter dig importera data från olika webbformat, såsom XML, HTML, RSS och CSV. Denna funktion är särskilt användbar när du behöver samla in data från webbplatser utan att behöva skriva komplicerad kod.
Den grundläggande syntaxen för IMPORTXML ser ut så här:
=IMPORTXML(url, xpath_query)
- url: Webbadressen till den webbsida du vill hämta data från.
- xpath_query: En XPath-fråga som definierar vilken data du vill extrahera.
XPath (XML Path Language) är ett språk som används för att navigera i XML-dokument, inklusive HTML. Det låter dig ange exakt var i HTML-strukturen den önskade informationen finns. För att kunna utnyttja IMPORTXML effektivt är det viktigt att förstå hur XPath-frågor fungerar.
Grundläggande XPath
XPath erbjuder en rad funktioner och uttryck för att navigera och filtrera data i ett HTML-dokument. En fullständig genomgång av XML och XPath ligger utanför ramen för denna text, men här är några grundläggande XPath-koncept:
- Elementval: Använd / och // för att specificera sökvägar. Till exempel, /html/body/div markerar alla div-element som finns i dokumentets brödtext.
- Attributval: Använd @ för att välja attribut. Till exempel, //@href väljer alla href-attribut på en sida.
- Predikatfilter: Filtrera element med hjälp av hakparenteser ([ ]). Till exempel, /div[@class=”container”] väljer alla div-element som har klassen ”container”.
- Funktioner: XPath har funktioner som contains(), starts-with() och text() för att utföra specifika sökningar, till exempel efter textinnehåll eller attributvärden.
Nu när du känner till IMPORTXML-syntaxen och vet vilken webbadress du vill använda och vilket element du vill extrahera, hur hittar du då elementets XPath?
Du behöver inte memorera en webbplats struktur för att använda IMPORTXML. De flesta webbläsare har ett smidigt verktyg som låter dig kopiera XPath för vilket element som helst.
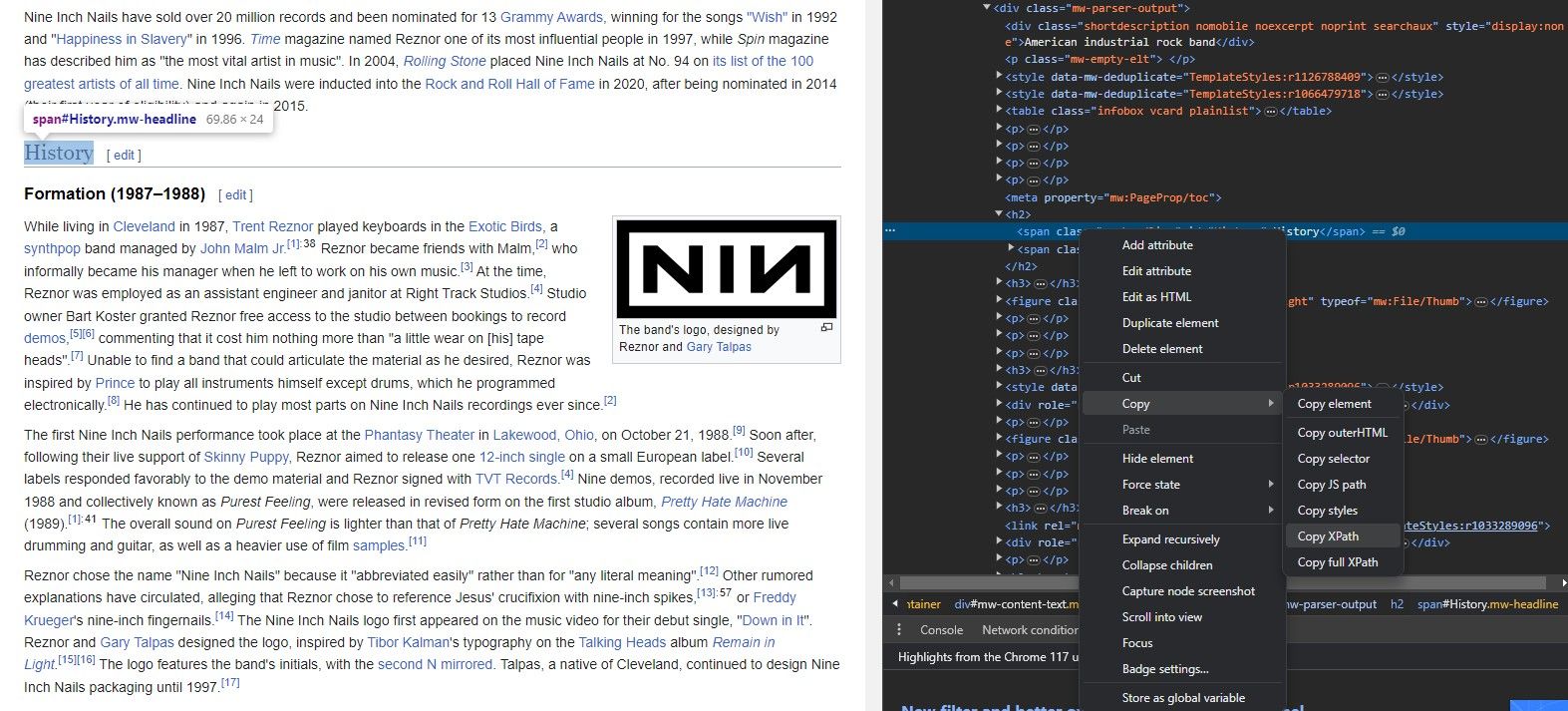
Genom att använda funktionen ”Inspektera element” i webbläsaren kan du enkelt hämta XPath för olika element. Så här gör du:
- Öppna webbsidan i din webbläsare.
- Hitta det element du vill extrahera data från.
- Högerklicka på elementet.
- Välj ”Inspektera element” i menyn. Webbläsaren öppnar då en panel som visar webbsidans HTML-kod. Det valda elementet kommer att vara markerat.
- I panelen ”Inspektera element” högerklickar du på det markerade elementet.
- Välj ”Kopiera XPath” för att kopiera elementets XPath-adress till urklipp.
Nu har du allt du behöver för att använda IMPORTXML och hämta data. Låt oss titta på hur man skrapar länkar.
Skrapa Länkar med IMPORTXML
IMPORTXML kan användas för att hämta olika typer av data, inklusive länkar, videor, bilder och andra element. Länkar är en viktig del av webbanalys, och analys av en webbplats länkar kan ge värdefull information.
Med IMPORTXML kan du snabbt extrahera länkar till Google Kalkylark, vilket gör det möjligt att analysera dem med hjälp av de funktioner som Google Kalkylark erbjuder.
1. Hämta alla länkar
För att skrapa alla länkar från en webbsida, använd följande formel:
=IMPORTXML(url, "//a/@href")
Denna XPath-fråga väljer alla href-attribut, vilket ger dig alla länkar på sidan.
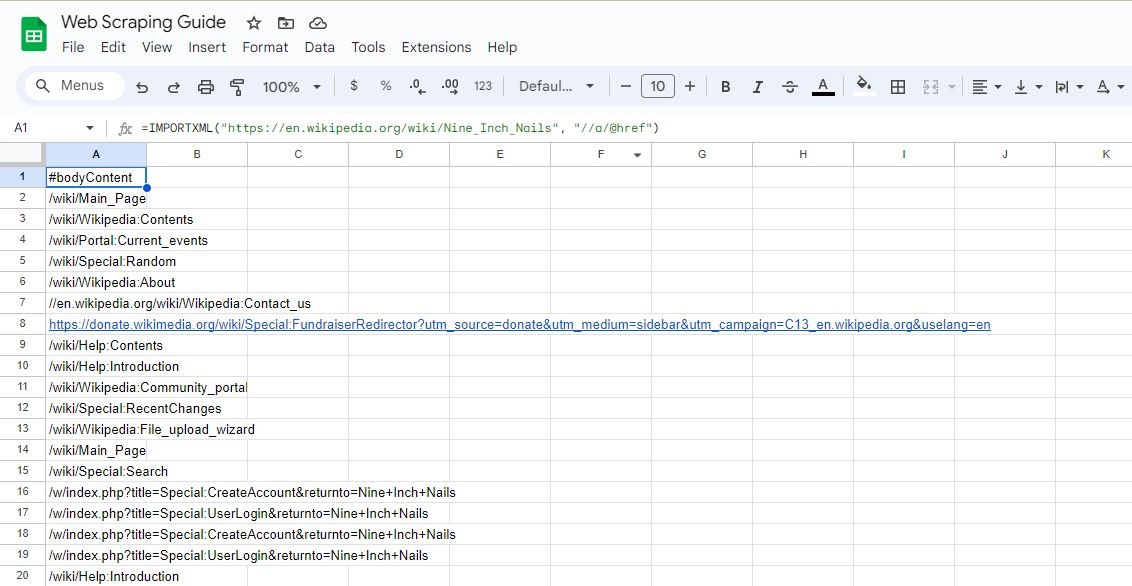
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")
Ovanstående formel skrapar alla länkar från en Wikipedia-artikel.
Det är rekommenderat att ange webbsidans URL i en separat cell och sedan hänvisa till den cellen i formeln. Detta håller formeln kort och lättare att hantera. Samma sak kan göras för XPath-frågan.
2. Hämta all länktext
För att hämta texten som är kopplad till länkarna tillsammans med webbadresserna, använd:
=IMPORTXML(url, "//a")
Den här frågan väljer alla element, vilket gör det möjligt att hämta både länktexten och länkens webbadress.
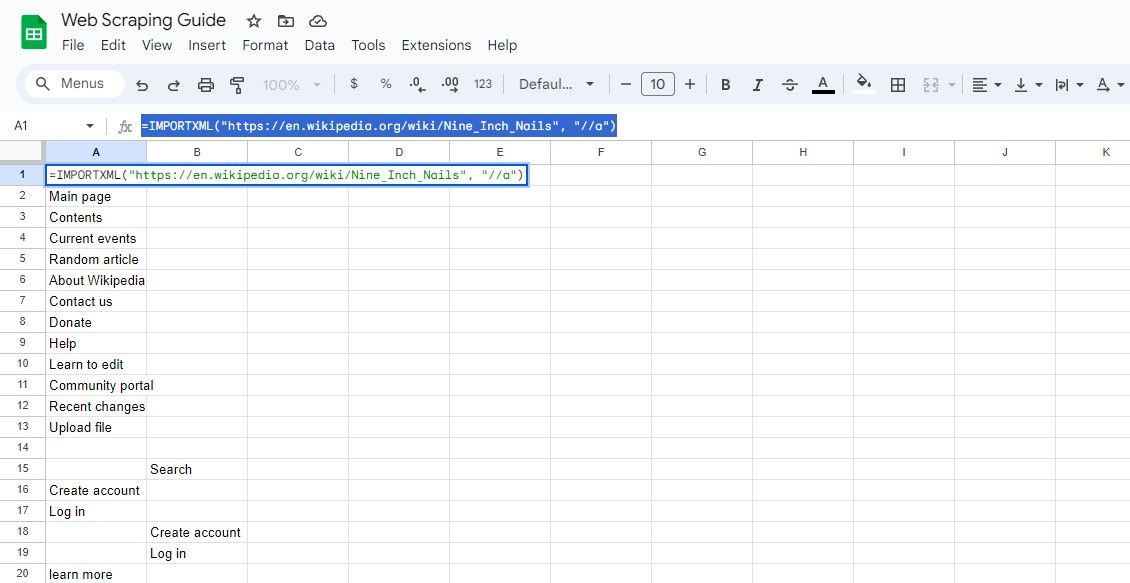
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a")
Formeln ovan hämtar länktexterna från samma Wikipedia-artikel.
Skrapa Specifika Länkar med IMPORTXML
Ibland kan du behöva skrapa specifika länkar baserat på vissa kriterier, som att extrahera länkar som innehåller ett visst sökord eller länkar som finns inom en specifik del av sidan.
Med rätt XPath-kunskaper kan du hitta exakt de element du söker.
1. Hämta länkar med ett visst sökord
För att hämta länkar som innehåller ett specifikt sökord, använd XPath-funktionen contains():
=IMPORTXML(url, "//a[contains(@href, 'sökord')]/@href")
Denna fråga väljer href-attribut för element vars href innehåller det angivna sökordet.
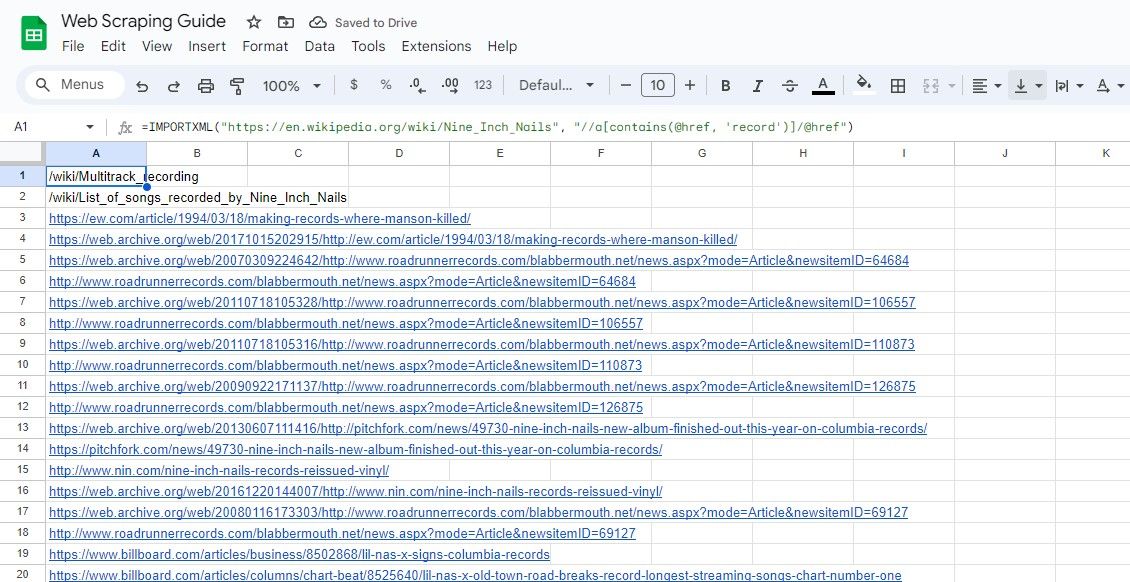
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")
Formeln ovan skrapar alla länkar som innehåller ordet ”record” i sin text från en Wikipedia-artikel.
2. Hämta länkar inom en sektion
För att hämta länkar från en viss sektion på en sida, specificera sektionens XPath. Till exempel:
=IMPORTXML(url, "//div[@class="section"]//a/@href")
Denna fråga väljer href-attribut för element inom div-element som har klassen ”section”.
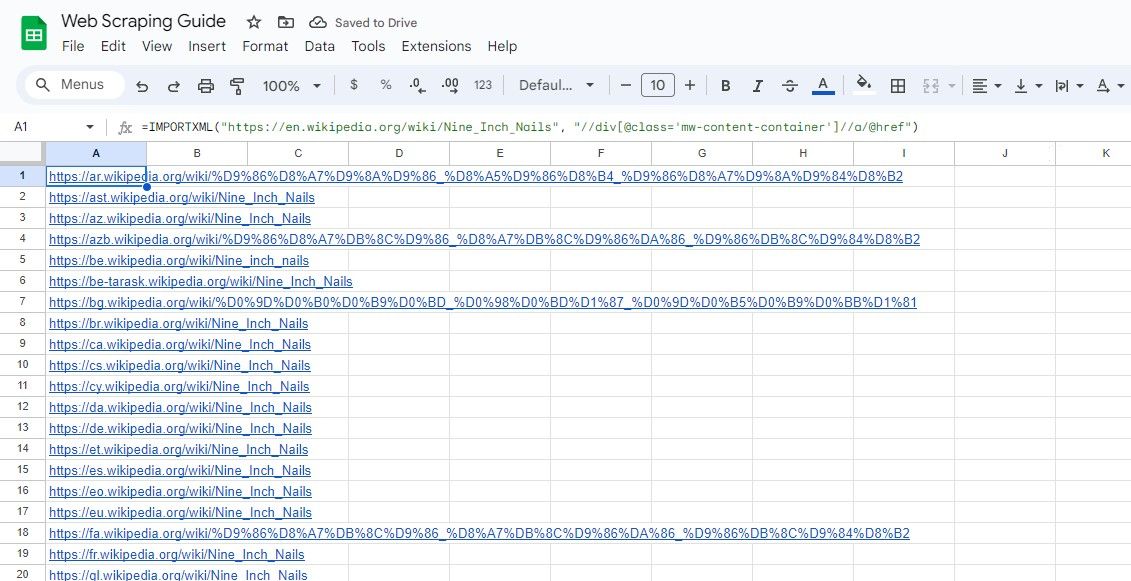
På samma sätt väljer följande formel alla länkar inom div-element som har klassen ”mw-content-container”:
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//div[@class="mw-content-container"]//a/@href")
Det är värt att notera att IMPORTXML kan användas för mer än bara webbskrapning. Du kan använda andra funktioner i IMPORT-familjen för att importera datatabeller från webbplatser till Google Kalkylark.
Även om Google Kalkylark och Excel delar många funktioner är IMPORT-familjen unik för Google Kalkylark. Du måste utforska andra metoder för att importera data från webbplatser till Excel.
Enklare Webbskrapning med Google Kalkylark
Webbskrapning med Google Kalkylark och funktionen IMPORTXML är ett tillgängligt och mångsidigt sätt att hämta data från webbplatser.
Genom att bemästra XPath och lära dig att skapa effektiva frågor kan du fullt utnyttja potentialen hos IMPORTXML och få värdefulla insikter från webbresurser. Kom igång med din webbskrapning och ta din webbanalys till nästa nivå!