DataFrames: Grunden för Datahantering i R
DataFrames är en central datastruktur i programmeringsspråket R. De utgör ryggraden för all dataanalys och bearbetning, och erbjuder den nödvändiga strukturen, flexibiliteten och de verktyg som krävs för att hantera information effektivt. Deras betydelse sträcker sig över olika discipliner, från statistik och datavetenskap till affärsbeslut som bygger på data.
Genom att strukturera data i tabellform, med rader och kolumner, ger DataFrames det ramverk som krävs för att generera insikter och fatta välunderbyggda beslut. Denna organisering möjliggör en systematisk och effektiv process för dataanalys.
DataFrames i R kan liknas vid tabeller där varje rad representerar en observation, och varje kolumn en specifik variabel. Denna struktur underlättar både organisation och manipulation av data, och kan hantera olika datatyper, inklusive siffror, text och datum. Detta gör dem otroligt mångsidiga.
I den här artikeln kommer vi att utforska betydelsen av dataramar och undersöka hur de skapas med hjälp av `data.frame()`-funktionen.
Vi kommer även att granska metoder för att bearbeta data, skapa dataramar från CSV- och Excel-filer, omvandla andra datastrukturer till dataramar samt använda `tibble`-biblioteket.
Här följer en sammanfattning av varför DataFrames är så viktiga i R:
Vikten av DataFrames

- Strukturerad Databearbetning: DataFrames tillhandahåller ett ordnat och tabellformat för datalagring, vilket förenklar bearbetning och organisation av information.
- Flexibel Hantering av Datatyper: De kan hantera en blandning av olika datatyper, vilket är viktigt vid analys av komplexa datamängder.
- Tydlig Dataorganisation: Varje kolumn representerar en variabel, medan varje rad visar en observation, vilket ökar tydligheten och förståelsen av data.
- Enkel Dataimport och Export: DataFrames stödjer smidig import och export av data från olika filformat, som CSV och Excel, vilket underlättar användningen av externa datakällor.
- Interoperabilitet: De fungerar väl med andra R-paket och verktyg, vilket möjliggör en sömlös integration i R-ekosystemet.
- Effektiv Datamanipulation: Med hjälp av paket som `dplyr`, kan data filtreras, transformerats och sammanfattas effektivt.
- Statistisk Analys: DataFrames är standardformatet för många statistiska analyser i R, vilket underlättar regressionsanalys, hypotesprövning och andra beräkningar.
- Datavisualisering: R:s visualiseringsverktyg, som `ggplot2`, fungerar väl med DataFrames, vilket gör det enkelt att skapa insiktsfulla diagram och grafer.
- Datautforskning: De underlättar datautforskning genom sammanfattande statistik och andra analytiska metoder, vilket hjälper till att förstå data och upptäcka mönster.
Skapa en DataFrame i R
Det finns olika sätt att skapa DataFrames i R. Här presenterar vi några av de mest använda metoderna:
1. Använda Funktionen `data.frame()`
# Ladda det nödvändiga biblioteket om det inte redan är inläst
if (!require("dplyr")) {
install.packages("dplyr")
library(dplyr)
}
# install.packages("dplyr")
library(dplyr)
# Skapa ett slumpmässigt frö för reproducerbarhet
set.seed(42)
# Skapa ett exempel på en försäljnings-DataFrame med produktnamn
sales_data <- data.frame(
OrderID = 1001:1010,
Product = c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven"),
Quantity = sample(1:10, 10, replace = TRUE),
Price = round(runif(10, 100, 2000), 2),
Discount = round(runif(10, 0, 0.3), 2),
Date = sample(seq(as.Date('2023-01-01'), as.Date('2023-01-10'), by="days"), 10)
)
# Visa försäljnings-DataFrame
print(sales_data)
Denna kod kontrollerar först om `dplyr`-biblioteket är tillgängligt, installerar det vid behov och skapar sedan ett slumpmässigt försäljningsdata med hjälp av `data.frame()`. Slutligen skrivs resultatet ut.
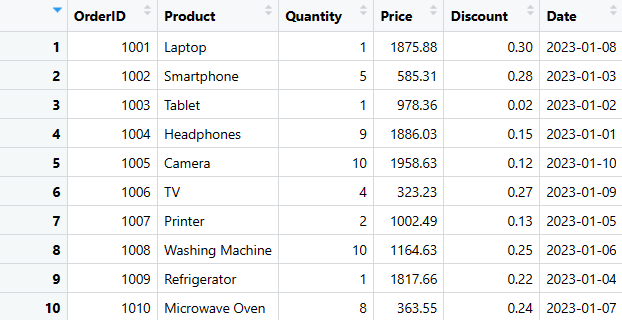
Detta är en enkel metod för att skapa en DataFrame. Vi kommer nu att se hur man extraherar, lägger till och tar bort kolumner och rader, samt hur man sammanfattar data.
Extrahera Kolumner
Vi kan extrahera kolumner på två sätt:
- Genom att använda indexering för att hämta de tre sista kolumnerna.
- Genom att använda $-operatorn för att få tillgång till enskilda kolumner efter namn.
Låt oss granska båda metoderna:
# Extrahera de tre sista kolumnerna (Discount, Price och Date) från sales_data
last_three_columns <- sales_data[, c("Discount", "Price", "Date")]
# Visa de extraherade kolumnerna
print(last_three_columns)
############################################# ELLER #########################################################
# Extrahera de tre sista kolumnerna (Discount, Price och Date) med $-operatorn
discount_column <- sales_data$Discount
price_column <- sales_data$Price
date_column <- sales_data$Date
# Skapa en ny DataFrame med de extraherade kolumnerna
last_three_columns <- data.frame(Discount = discount_column, Price = price_column, Date = date_column)
# Visa de extraherade kolumnerna
print(last_three_columns)
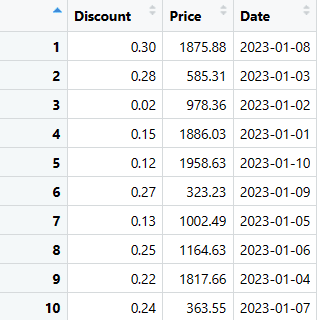
Båda dessa kodsnuttar ger samma resultat, där de tre kolumnerna extraheras från originaldataramen.
För att extrahera rader kan du använda följande metod:
# Extrahera specifika rader (raderna 3, 6 och 9) från last_three_columns selected_rows <- last_three_columns[c(3, 6, 9), ] # Visa de valda raderna print(selected_rows)
Du kan också extrahera rader som uppfyller specifika villkor:
# Extrahera och ordna rader som uppfyller de angivna villkoren selected_rows <- sales_data %>% filter(Discount < 0.3, Price > 100, format(Date, "%Y-%m") == "2023-01") %>% arrange(OrderID) %>% select(Discount, Price, Date) # Visa de valda raderna print(selected_rows)
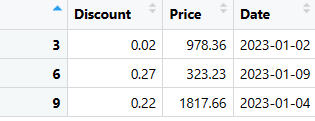
Nu ska vi se hur man lägger till och tar bort rader och kolumner i dataramen.
Lägg till en ny rad
För att lägga till en ny rad, använd funktionen `rbind()`:
# Skapa en ny rad som en dataram
new_row <- data.frame(
OrderID = 1011,
Product = "Coffee Maker",
Quantity = 2,
Price = 75.99,
Discount = 0.1,
Date = as.Date("2023-01-12")
)
# Använd rbind() för att lägga till den nya raden i DataFramen
sales_data <- rbind(sales_data, new_row)
# Visa den uppdaterade dataramen
print(sales_data)
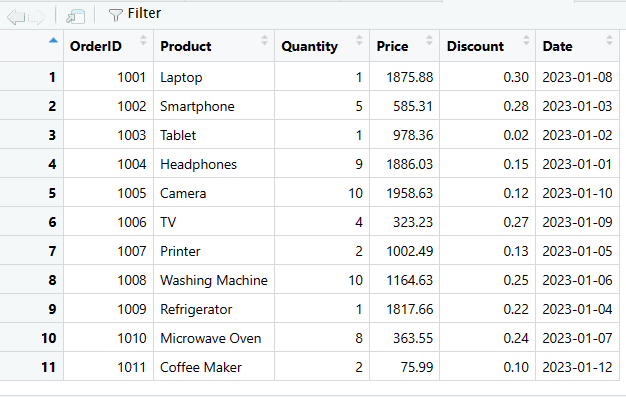
Lägg till en ny kolumn
För att lägga till en ny kolumn, tilldela den helt enkelt till dataramen, så som i exemplet där vi lägger till ”PaymentMethod”:
# Skapa en ny kolumn "PaymentMethod" med värden för varje rad
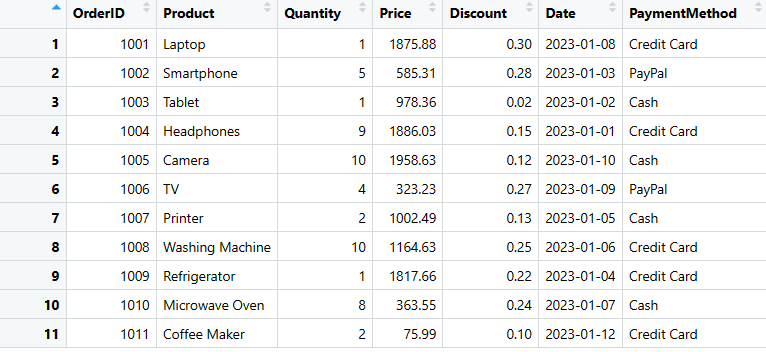
sales_data$PaymentMethod <- c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
# Visa den uppdaterade dataramen
print(sales_data)
Ta bort rader
Använd följande metod för att ta bort rader baserat på ett villkor, till exempel `OrderID`:
# Identifiera raden som ska tas bort med dess OrderID row_to_delete <- sales_data$OrderID == 1010 # Använd den identifierade raden för att utesluta den och skapa en ny DataFrame sales_data <- sales_data[!row_to_delete, ] # Visa den uppdaterade dataramen utan den borttagna raden print(sales_data)
Ta bort kolumner
Använd `dplyr`-paketet för att ta bort kolumner:
# install.packages("dplyr")
library(dplyr)
# Ta bort "Discount"-kolumnen med select()
sales_data <- sales_data %>% select(-Discount)
# Visa den uppdaterade dataramen utan "Discount"-kolumnen
print(sales_data)
Sammanfatta data
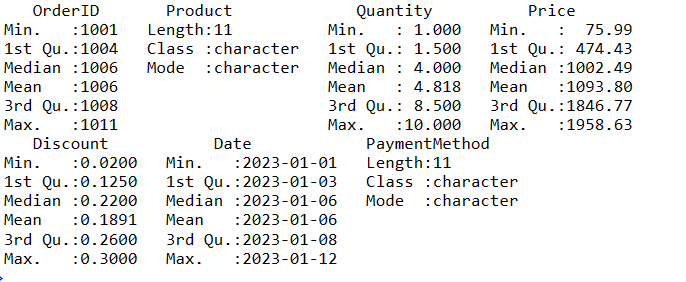
För att få en sammanfattning av datan, använd funktionen `summary()`:
# Hämta en sammanfattning av datan data_summary <- summary(sales_data) # Visa sammanfattningen print(data_summary)
Dessa steg ger en översikt över hur du kan bearbeta data i en DataFrame.
Låt oss nu gå vidare till nästa metod för att skapa en DataFrame.
2. Skapa en R DataFrame från en CSV-fil
Du kan använda `read.csv()` för att skapa en DataFrame från en CSV-fil:
# Läs in CSV-filen till en DataFrame
df <- read.csv("my_data.csv")
# Visa de första raderna i dataramen
head(df)
Denna funktion läser data från en CSV-fil och skapar en motsvarande DataFrame. Du kan även använda `readr`-paketet, som är snabbare:
# Installera och ladda readr-paketet om det inte redan är installerat
if (!requireNamespace("readr", quietly = TRUE)) {
install.packages("readr")
}
library(readr)
# Läs CSV-filen till en DataFrame
df <- read_csv("data.csv")
# Visa de första raderna i dataramen
head(df)
3. Använda Funktionen `as.data.frame()`
Funktionen `as.data.frame()` kan användas för att konvertera andra datastrukturer, som listor eller matriser, till DataFrames. Här följer ett exempel:
# Skapa en kapslad lista
data_list <- list(
OrderID = 1001:1011,
Product = c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven", "Coffee Maker"),
Quantity = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Price = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Discount = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
)
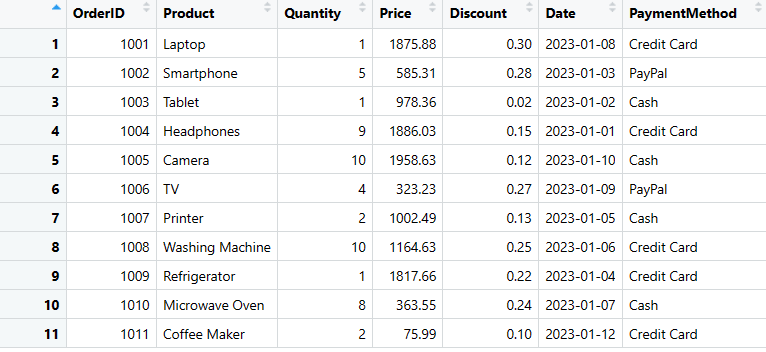
# Konvertera den kapslade listan till en DataFrame
sales_data <- as.data.frame(data_list)
# Visa dataramen
print(sales_data)
Detta är användbart för att konvertera befintliga data till DataFrames.
4. Från en Befintlig DataFrame
Du kan skapa en ny DataFrame genom att välja rader eller kolumner från en befintlig med hjälp av indexering:
# Välj rader och kolumner
sales_subset <- sales_data[c(1, 3, 4), c("Product", "Quantity")]
# Visa den valda delmängden
print(sales_subset)
Denna kod skapar en `sales_subset` baserat på den tidigare `sales_data`.

5. Från en Vektor
Du kan även skapa en DataFrame från en vektor genom att skapa separata vektorer för varje kolumn och sedan använda `data.frame()`:
# Skapa vektorer för varje kolumn
OrderID <- 1001:1011
Product <- c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven", "Coffee Maker")
Quantity <- c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2)
Price <- c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99)
Discount <- c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1)
Date <- as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12"))
PaymentMethod <- c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
# Skapa dataramen med data.frame()
sales_data <- data.frame(
OrderID = OrderID,
Product = Product,
Quantity = Quantity,
Price = Price,
Discount = Discount,
Date = Date,
PaymentMethod = PaymentMethod
)
# Visa dataramen
print(sales_data)
Detta skapar en strukturerad DataFrame från individuella vektorer.
6. Från en Excel-fil
För att läsa en Excel-fil, använd `readxl`-paketet och dess funktion `read_excel()`:
# Ladda readxl-biblioteket library(readxl) # Ange sökväg till Excel-filen excel_file_path <- "your_file.xlsx" # Ersätt med den faktiska sökvägen # Läs Excel-filen och skapa en DataFrame data_frame_from_excel <- read_excel(excel_file_path) # Visa DataFramen print(data_frame_from_excel)
7. Från en Textfil
Använd `read.table()` för att importera en textfil. Ange filnamn och avgränsare:
# Ange filnamn och avgränsare file_name <- "your_text_file.txt" # Ersätt med den faktiska sökvägen delimiter <- "\t" # Ersätt med aktuell avgränsare # Skapa en DataFrame med read.table() data_frame_from_text <- read.table(file_name, header = TRUE, sep = delimiter) # Visa DataFrame print(data_frame_from_text)
8. Använda Tibble
Du kan skapa en tibble med hjälp av `tidyverse`-biblioteket och dess `tibble()`-funktion:
# Ladda tidyverse-biblioteket
library(tidyverse)
# Skapa en tibble med vektorer
sales_data <- tibble(
OrderID = 1001:1011,
Product = c("Laptop", "Smartphone", "Tablet", "Headphones", "Camera", "TV", "Printer", "Washing Machine", "Refrigerator", "Microwave Oven", "Coffee Maker"),
Quantity = c(1, 5, 1, 9, 10, 4, 2, 10, 1, 8, 2),
Price = c(1875.88, 585.31, 978.36, 1886.03, 1958.63, 323.23, 1002.49, 1164.63, 1817.66, 363.55, 75.99),
Discount = c(0.3, 0.28, 0.02, 0.15, 0.12, 0.27, 0.13, 0.25, 0.22, 0.24, 0.1),
Date = as.Date(c("2023-01-08", "2023-01-03", "2023-01-02", "2023-01-01", "2023-01-10", "2023-01-09", "2023-01-05", "2023-01-06", "2023-01-04", "2023-01-07", "2023-01-12")),
PaymentMethod = c("Credit Card", "PayPal", "Cash", "Credit Card", "Cash", "PayPal", "Cash", "Credit Card", "Credit Card", "Cash", "Credit Card")
)
# Visa den skapade tibblen
print(sales_data)
Tibbles är en modernare variant av DataFrames med mer informativ utskrift.
Effektiv Användning av DataFrames i R
För att arbeta effektivt med DataFrames, följ dessa tips:
- Se till att data är ren och välstrukturerad innan du skapar DataFrames.
- Använd lämpliga datatyper för kolumner.
- Använd indexering och delmängder för att arbeta med specifika delar av data.
- Undvik `attach()` och `detach()`.
- Använd vektoriserade operationer istället för loopar.
- Undvik kapslade loopar.
- Överväg `data.table` eller `dtplyr` för stora dataset.
- Använd datahanteringspaket som `dplyr`, `tidyr` och `data.table`.
- Minimera användningen av globala variabler.
- Använd `group_by()` och `summarize()` i `dplyr` för aggregerade beräkningar.
- Överväg parallell bearbetning för stora dataset.
- Använd `readr` eller `data.table::fread` för snabbare dataimport.
- För stora dataset, använd databassystem eller specialiserade format som Feather, Arrow eller Parquet.
Sammanfattning
Det finns flera sätt att skapa DataFrames i R. Vi har utforskat flera metoder, inklusive `data.frame()`, import från CSV och Excel, konvertering av andra datastrukturer och användning av `tibble`-biblioteket. Dessa metoder ger en bra grund för att effektivt hantera och analysera data i R.
Du kanske även vill undersöka de bästa IDE:erna för R-programmering. Här finns mer information.