I dagens informationsintensiva era har manuell datainsamling blivit en ineffektiv metod. Med datorer och internetåtkomst på nästan varje arbetsplats har webben utvecklats till en enorm resurs för data. Därför har webbskrapning framstått som en mer ändamålsenlig och tidsbesparande teknik för att samla in information. Inom webbskrapning är Python, med sitt verktyg Beautiful Soup, en betydande aktör. Denna artikel kommer att guida dig genom installationsprocessen för Beautiful Soup, så att du kan börja använda det för webbskrapning.
Innan du installerar och börjar använda Beautiful Soup, ska vi undersöka varför detta verktyg är så värdefullt.
Vad är Beautiful Soup?
Tänk dig att du forskar om ”COVID:s påverkan på människors hälsa” och har hittat flera webbsidor med relevant data. Men vad händer om webbplatserna inte erbjuder ett enkelt sätt att ladda ner data? Det är här Beautiful Soup kommer in i bilden.
Beautiful Soup är ett kraftfullt Python-bibliotek som är utformat för att extrahera data från webbplatser. Det underlättar hämtningen av information från HTML- och XML-dokument.
Leonard Richardson lanserade idén bakom Beautiful Soup för webbskrapning 2004. Hans bidrag till projektet fortgår än idag. Han annonserar stolt varje ny version av Beautiful Soup via sitt Twitter-konto.
Även om Beautiful Soup för webbskrapning ursprungligen utvecklades med Python 3.8, fungerar det smidigt med både Python 3 och 2.4.
Webbplatser använder ofta captcha-skydd för att skydda sin information från automatiserade verktyg. I dessa fall kan du justera ”user-agent”-huvudet i Beautiful Soup eller använda Captcha-lösnings-API:er för att simulera en legitim webbläsare och kringgå skyddet.
Om du saknar tid att lära dig Beautiful Soup eller vill att skrapningsprocessen ska vara så effektiv som möjligt, bör du överväga att använda ett webbskrapnings-API. Med dessa API:er kan du helt enkelt ange en URL och få tillgång till relevant data direkt.
För programmerare är Beautiful Soup lätt att använda tack vare dess enkla syntax för att navigera på webbsidor och hämta specifik data baserat på villkor. Dessutom är det nybörjarvänligt.
Beautiful Soup är inte det mest avancerade skrapningsverktyget, men det är utmärkt för att extrahera data från filer skrivna i markeringsspråk.
En annan fördel med Beautiful Soup är dess klara och detaljerade dokumentation.
Nu ska vi se hur du enkelt kan installera Beautiful Soup på din dator.
Hur installerar man Beautiful Soup för webbskrapning?
Pip, en enkel Python-pakethanterare som utvecklades 2008, är nu ett standardverktyg för utvecklare för att installera Python-bibliotek och beroenden.
Pip inkluderas som standard i de senaste versionerna av Python. Så om du har en nyare version av Python installerad, är du redo att börja.
Öppna kommandotolken och skriv följande pip-kommando för att direkt installera Beautiful Soup:
pip install beautifulsoup4Du kommer att se något som liknar följande på din skärm.
Se till att du har uppdaterat PIP-installationsprogrammet till den senaste versionen för att undvika vanliga problem.
Kommandot för att uppdatera pip-installationsprogrammet är:
pip install --upgrade pipVi har nu genomfört en betydande del av processen.
Nu när du har Beautiful Soup installerat på din dator, ska vi undersöka hur du kan använda det för webbskrapning.
Hur importerar och använder man Beautiful Soup för webbskrapning?
För att importera Beautiful Soup till ditt Python-skript, skriv följande kommando i din Python-IDE:
from bs4 import BeautifulSoupNu är Beautiful Soup tillgängligt i din Python-fil för webbskrapning.
Låt oss titta på ett kodexempel för att se hur du extraherar önskad information med Beautiful Soup.
Med Beautiful Soup kan vi söka efter specifika HTML-taggar på den aktuella webbsidan och extrahera data som finns i dessa taggar.
I detta exempel kommer jag att använda marketwatch.com, som visar realtidsaktiekurser för olika företag. Låt oss hämta lite data från den webbplatsen för att bekanta oss med Beautiful Soup-biblioteket.
Importera ”requests”-paketet för att kunna hantera HTTP-förfrågningar och ”urllib” för att ladda webbsidan från dess URL.
from urllib.request import urlopen
import requestsLagra webbsidans länk i en variabel så att du enkelt kan komma åt den senare.
url="https://www.marketwatch.com/investing/stock/amzn"Använd sedan metoden ”urlopen” från biblioteket ”urllib” för att lagra HTML-sidan i en variabel. Skicka URL:en till funktionen ”urlopen” och spara resultatet i en variabel.
page = urlopen(url)Skapa ett Beautiful Soup-objekt och analysera den aktuella webbsidan med ”html.parser”.
soup_obj = BeautifulSoup(page, 'html.parser')Nu lagras hela HTML-skriptet för den valda webbsidan i variabeln ”soup_obj”.
Innan vi fortsätter, låt oss undersöka källkoden för den valda webbsidan för att lära oss mer om dess HTML-struktur och -taggar.
Högerklicka var som helst på webbsidan. Du kommer att se ett ”inspektera”-alternativ som visas nedan.
Klicka på ”inspektera” för att se källkoden.
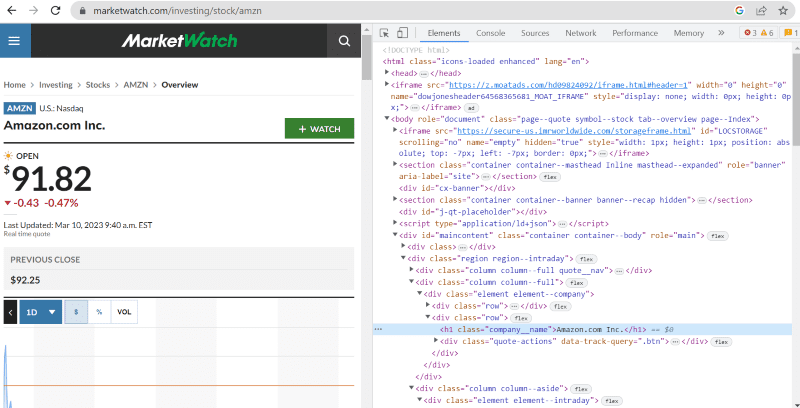
I källkoden ovan kan du se taggar, klasser och annan specifik information om alla element som visas på webbsidans gränssnitt.
Metoden ”find” i Beautiful Soup gör det möjligt för oss att söka efter specifika HTML-taggar och extrahera data. För att göra detta anger vi klassnamnet och taggarna till metoden, vilket extraherar relevant data.
Till exempel har ”Amazon.com Inc.” som visas på webbsidan klassnamnet: ”company__name” som är taggat under ”h1”. Vi kan ange denna information i ”find”-metoden för att extrahera det relevanta HTML-kodavsnittet till en variabel.
name = soup_obj.find('h1', attrs={'class': 'company__name'})Låt oss skriva ut HTML-skriptet som lagras i variabeln ”name” och den önskade texten på skärmen.
print(name)
print(name.text)
Du kan nu se den extraherade informationen på skärmen.
Webbskrapning av IMDb-webbplatsen
Många av oss kollar upp filmbetyg på IMDb innan vi bestämmer oss för att se en film. I den här demonstrationen ska vi skapa en lista över de högst rankade filmerna för att bekanta oss med webbskrapning med Beautiful Soup.
Steg 1: Importera Beautiful Soup och biblioteket för ”requests”.
from bs4 import BeautifulSoup
import requestsSteg 2: Tilldela webbadressen vi vill skrapa till en variabel som heter ”url” för enkel åtkomst i koden.
Paketet ”requests” används för att hämta HTML-sidan från webbadressen.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')Steg 3: I följande kodsnutt analyserar vi HTML-sidan för den angivna URL:en och skapar ett Beautiful Soup-objekt.
soup_obj = BeautifulSoup(url.text, 'html.parser')Variabeln ”soup_obj” innehåller nu hela HTML-skriptet för den valda webbsidan, som visas i följande bild.
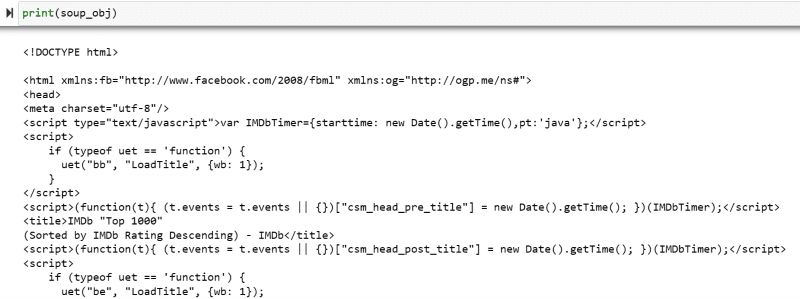
Låt oss inspektera webbsidans källkod för att hitta HTML-skriptet för de data vi vill skrapa.
Håll muspekaren över det element du vill extrahera. Högerklicka på det och välj alternativet ”inspektera” för att visa källkoden för det specifika elementet. Följande bilder kommer att hjälpa dig.
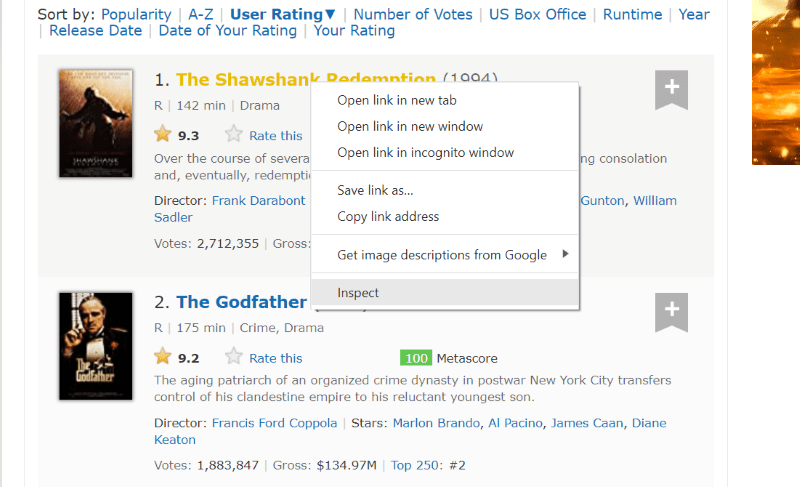
Klassen ”lister-list” innehåller all relaterad information om de högst rankade filmerna som underavdelningar i på varandra följande div-taggar.
I HTML-skriptet för varje filmkort, under klassen ”lister-item mode-advanced”, finns en ”h3”-tagg som lagrar filmens namn, rankning och utgivningsår, markerat i bilden nedan.
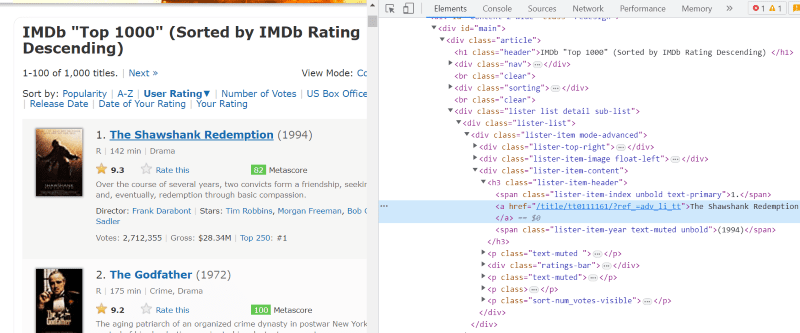
Notera: Metoden ”find” i Beautiful Soup söker efter den första taggen som matchar det angivna inmatningsnamnet. Till skillnad från ”find” söker metoden ”find_all” efter alla taggar som matchar den angivna inmatningen.
Steg 4: Använd metoderna ”find” och ”find_all” för att spara HTML-skriptet för varje films namn, rankning och utgivningsår i en listvariabel.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')Steg 5: Gå igenom listan över filmer som lagras i variabeln ”top_movies” och extrahera namn, rankning och utgivningsår för varje film i textformat från dess HTML-skript med hjälp av koden nedan.
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")I skärmdumpen nedan kan du se listan över filmer med deras namn, rankning och utgivningsår.
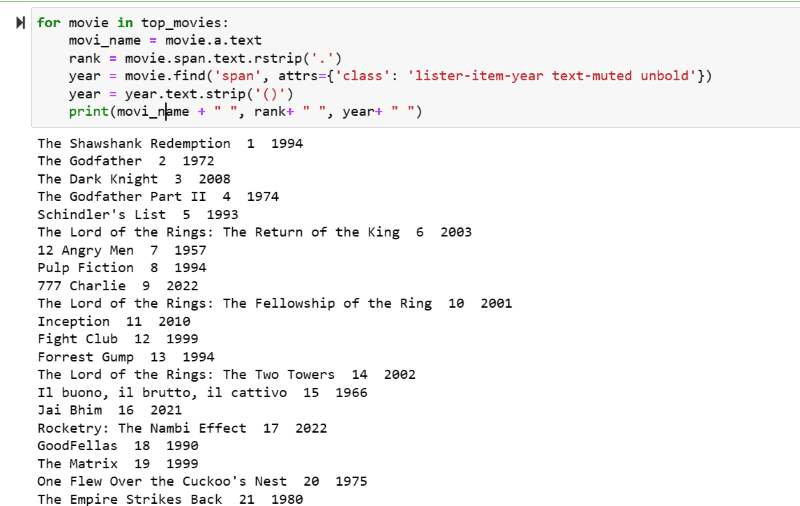
Du kan enkelt överföra den utskrivna informationen till ett Excel-ark med hjälp av Python-kod och använda det för din analys.
Slutord
Den här guiden hjälper dig att installera Beautiful Soup för webbskrapning. Dessutom bör de skrapningsexempel jag har visat hjälpa dig att komma igång med Beautiful Soup.
Eftersom du är intresserad av att installera Beautiful Soup för webbskrapning, rekommenderar jag starkt att du läser den här informativa guiden för att lära dig mer om webbskrapning med Python.