Utforska PDF-filer med Python: Extrahera Text, Länkar och Bilder
Python är ett flexibelt och kraftfullt programmeringsspråk, och som Python-utvecklare kommer du ofta i kontakt med olika typer av filer. Att kunna hämta information från dessa filer är en grundläggande färdighet. Ett vanligt filformat som du kan stöta på är Portable Document Format, mer känt som PDF.
PDF-dokument kan innehålla en mängd olika data, inklusive text, bilder och interaktiva länkar. När du utvecklar Python-applikationer kan du behöva extrahera data från PDF-filer för vidare bearbetning. Till skillnad från enklare datastrukturer som listor och ordböcker, kan det initialt verka komplicerat att hantera data som lagras i PDF-dokument.
Lyckligtvis finns det ett antal bibliotek som underlättar arbetet med PDF-filer och gör det möjligt att effektivt extrahera information. Vi ska nu gå igenom hur du kan extrahera text, länkar och bilder med hjälp av Python och några av dessa bibliotek. För att följa med i exemplen, ladda ner en PDF-fil och placera den i samma katalog som din Python-kod.
Extrahera Text med PyPDF2
För att extrahera text från PDF-filer kommer vi att använda PyPDF2, ett kostnadsfritt och öppen källkodsbibliotek. PyPDF2 är mångsidigt och kan användas för att sammanfoga, beskära och manipulera sidor i PDF-filer, samt lägga till metadata och lösenord. Framför allt är det ett användbart verktyg för att extrahera text från PDF-dokument.
Innan du börjar använda PyPDF2, måste du installera det med pip, en pakethanterare för Python. pip gör det enkelt att installera och hantera externa bibliotek på ditt system:
1. Börja med att kontrollera om pip redan är installerat genom att köra följande i terminalen:
pip --version
Om inget versionsnummer visas är pip inte installerat.
2. Om pip saknas, ladda ner installationsskriptet genom att klicka på hämta pip.
Denna länk leder till en sida med skriptet för att installera pip. Högerklicka på sidan och välj ”Spara som” för att ladda ner filen. Filen får som standard namnet get-pip.py.
Öppna terminalen, navigera till katalogen där du sparade get-pip.py och kör följande kommando:
sudo python3 get-pip.py
Detta installerar pip, som visas i terminalens utskrift.
3. Kontrollera att pip har installerats korrekt genom att köra:
pip --version
Om pip fungerar som det ska, ska du nu se ett versionsnummer.

Nu när pip är installerat kan vi fortsätta med PyPDF2.
1. Installera PyPDF2 genom att köra följande kommando i terminalen:
pip install PyPDF2
2. Skapa en ny Python-fil och importera PdfReader från PyPDF2 med följande kod:
from PyPDF2 import PdfReader
PyPDF2 tillhandahåller olika klasser för att arbeta med PDF-dokument. PdfReader-klassen kan bland annat användas för att öppna PDF-filer, läsa innehållet och extrahera text.
3. För att börja hantera en PDF-fil måste du först öppna den. Skapa en instans av PdfReader-klassen och ange sökvägen till din PDF-fil:
reader = PdfReader('games.pdf')
Denna kod skapar en PdfReader-instans som är redo att läsa innehållet i den angivna PDF-filen. Instansen lagras i variabeln ’reader’ som du kan använda för att komma åt olika metoder och egenskaper i PdfReader-klassen.
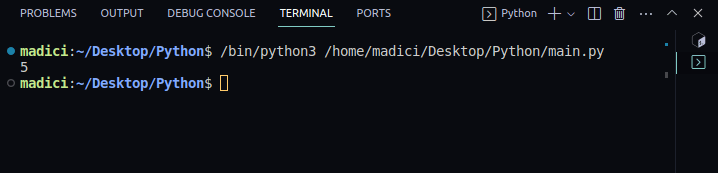
4. För att testa om allt fungerar, skriv ut antalet sidor i PDF-dokumentet med följande:
print(len(reader.pages))
Utskrift:
5
5. Eftersom PDF-filen har fem sidor kan vi komma åt varje sida. Indexeringen börjar från 0, som i många datastrukturer i Python. Den första sidan har alltså index 0. För att hämta den första sidan, lägg till följande rad:
page1 = reader.pages[0]
Detta hämtar den första sidan och lagrar den i variabeln ’page1’.
6. För att extrahera texten från den första sidan, använd följande:
textPage1 = page1.extract_text()
Detta extraherar texten från den första sidan och sparar den i variabeln ’textPage1’. Texten från PDF-filens första sida är nu tillgänglig via denna variabel.
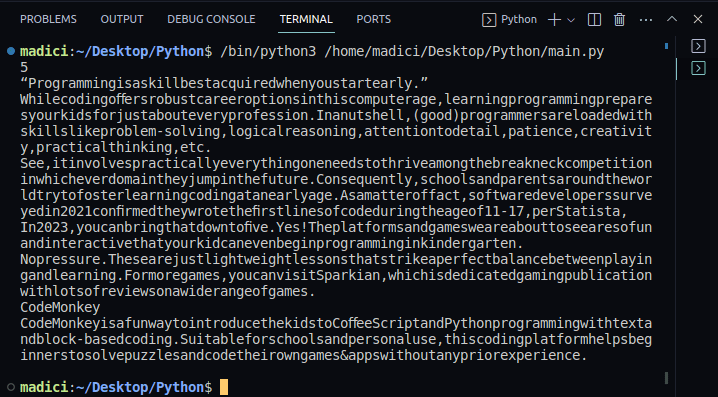
7. För att bekräfta att texten har extraherats, skriv ut innehållet i ’textPage1’. Här är den kompletta koden som även skriver ut texten på första sidan:
from PyPDF2 import PdfReader
reader = PdfReader('games.pdf')
print(len(reader.pages))
page1 = reader.pages[0]
textPage1 = page1.extract_text()
print(textPage1)
Utskrift:
Extrahera Länkar med PyMuPDF
För att extrahera länkar från PDF-filer kommer vi att använda PyMuPDF, ett annat kraftfullt Python-bibliotek för att analysera, konvertera och manipulera data i PDF-dokument. Du bör ha Python 3.8 eller senare för att använda PyMuPDF. För att börja:
1. Installera PyMuPDF med följande kommando:
pip install PyMuPDF
2. Importera PyMuPDF i din Python-fil:
import fitz
3. Öppna PDF-filen du vill extrahera länkar från:
doc = fitz.open("games.pdf")
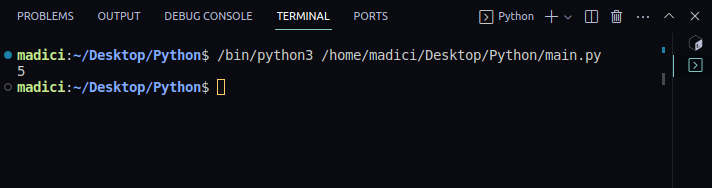
4. Skriv ut antalet sidor i dokumentet:
print(doc.page_count)
Utskrift:
5
5. För att extrahera länkar från en specifik sida måste vi ladda den. Använd följande kommando, där du ersätter 0 med sidnumret du vill ladda:
page = doc.load_page(0)
För att extrahera länkar från den första sidan, använder vi index 0. Kom ihåg att indexering börjar från noll.
6. Extrahera länkar från sidan:
links = page.get_links()
Alla länkar på den angivna sidan kommer att lagras i variabeln ’links’.
7. För att visa innehållet i ’links’, skriv ut den:
print(links)
Utskrift:
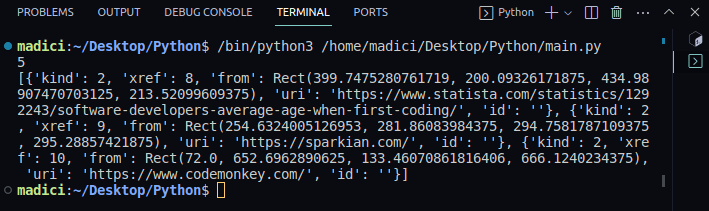
Variabeln ’links’ innehåller en lista med ordböcker. Varje länk på sidan representeras av en ordbok, där den faktiska länken lagras under nyckeln ”uri”.
8. För att få de faktiska länkarna, iterera genom listan och skriv ut länkarna som lagras under nyckeln ”uri”. Här är hela koden:
import fitz
doc = fitz.open("games.pdf")
print(doc.page_count)
page = doc.load_page(0)
links = page.get_links()
#print(links)
for obj in links:
print(obj["uri"])
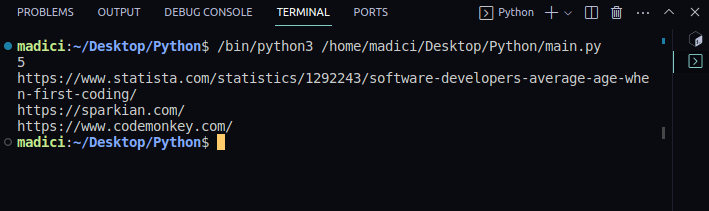
Utskrift:
5 https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/
9. För att göra koden mer återanvändbar kan vi definiera funktioner för att extrahera alla länkar och för att skriva ut dem. På så vis kan vi enkelt återanvända koden på olika PDF-filer. Här är den modifierade koden:
import fitz
def extract_link(path_to_pdf):
links = []
doc = fitz.open(path_to_pdf)
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
page_links = page.get_links()
links.extend(page_links)
return links
def print_all_links(links):
for link in links:
print(link["uri"])
all_links = extract_link("games.pdf")
print_all_links(all_links)
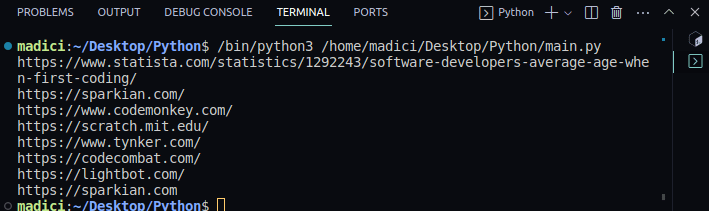
Utskrift:
https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/ https://scratch.mit.edu/ https://www.tynker.com/ https://codecombat.com/ https://lightbot.com/ https://sparkian.com
Funktionen ’extract_link()’ tar in sökvägen till en PDF-fil, itererar genom alla sidor och extraherar länkarna. Resultatet lagras i variabeln ’all_links’. Funktionen ’print_all_links()’ itererar genom denna lista och skriver ut varje länk.
Extrahera Bilder med PyMuPDF och PIL
Vi fortsätter använda PyMuPDF, och nu även Python Imaging Library (PIL), för att extrahera bilder från PDF-filer. PIL underlättar bildhantering och io-modulen hjälper oss med binär data.
1. Importera biblioteken:
import fitz
from io import BytesIO
from PIL import Image
2. Öppna PDF-filen:
doc = fitz.open("games.pdf")
3. Ladda den första sidan:
page = doc.load_page(0)
4. PyMuPDF identifierar bilder med ett korsreferensnummer (xref). För att få dessa xref-nummer använder vi ’get_images()’:
image_xref = page.get_images() print(image_xref)
Utskrift:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')]
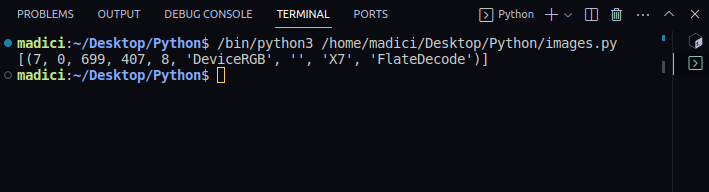
Resultatet är en lista med tupler, där varje tuppel representerar en bild. Det första elementet i tuppeln är xref-numret. I det här fallet är xref för bilden på första sidan 7.
5. Hämta xref-värdet:
xref_value = image_xref[0][0] print(xref_value)
Utskrift:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')] 7
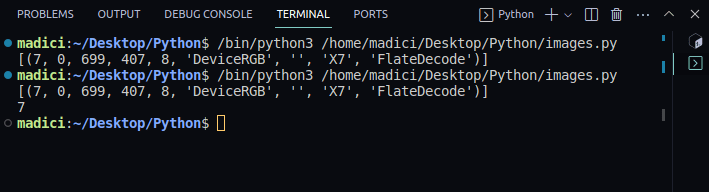
6. Använd ’extract_image()’ för att extrahera bilden:
img_dictionary = doc.extract_image(xref_value)
Funktionen returnerar en ordbok med information om bilden, inklusive dess binära data.
7. Hämta filändelsen för bilden, lagrad under nyckeln ”ext”:
img_extension = img_dictionary["ext"] print(img_extension)
Utskrift:
png
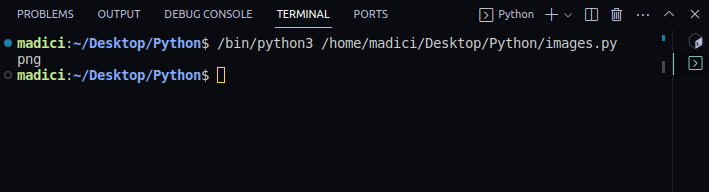
8. Extrahera den binära bilddatan, lagrad under nyckeln ”image”:
img_binary = img_dictionary["image"]
9. Skapa ett BytesIO-objekt och initiera det med den binära datan. Detta objekt kan användas av PIL för att hantera bilden:
image_io = BytesIO(img_binary)
10. Öppna och analysera bilddata med PIL:
image = Image.open(image_io)
11. Ange sökvägen där du vill spara bilden:
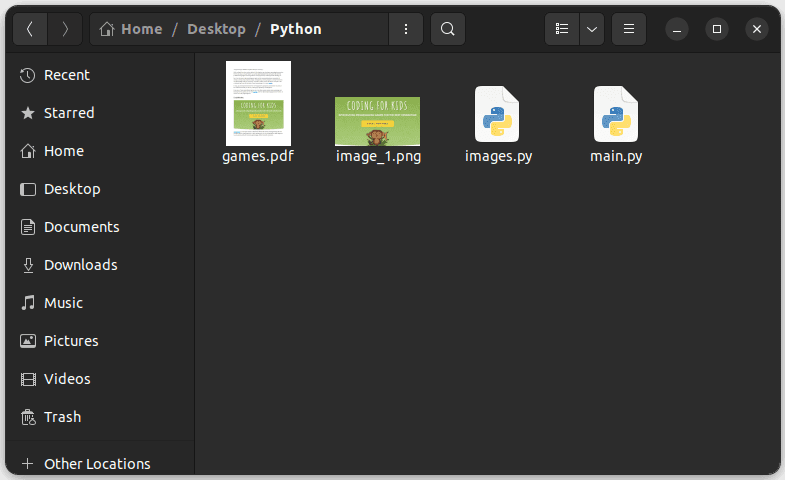
output_path = "image_1.png"
Den extraherade bilden kommer att sparas i samma katalog som Python-filen med namnet ”image_1.png”.
12. Spara bilden och stäng BytesIO-objektet:
image.save(output_path) image_io.close()
Hela koden:
import fitz
from io import BytesIO
from PIL import Image
doc = fitz.open("games.pdf")
page = doc.load_page(0)
image_xref = page.get_images()
xref_value = image_xref[0][0]
img_dictionary = doc.extract_image(xref_value)
img_extension = img_dictionary["ext"]
img_binary = img_dictionary["image"]
image_io = BytesIO(img_binary)
image = Image.open(image_io)
output_path = "image_1.png"
image.save(output_path)
image_io.close()
När du kör koden och kontrollerar katalogen, bör du hitta den extraherade bilden ”image_1.png”.
Slutsats
För att ytterligare utveckla dina färdigheter, försök att modifiera och generalisera koden för att göra den mer återanvändbar. På så sätt kan du använda samma kod för att extrahera all text, länkar och bilder från olika PDF-filer. Lycka till med programmeringen!
Du kan också utforska några av de bästa PDF-API:erna för alla företagsbehov.