Llama 2, en framstående språkmodell med öppen källkod, har utvecklats av Meta. Denna kraftfulla modell överträffar flera slutna modeller som GPT-3.5 och PaLM 2, och erbjuder tre olika storlekar: 7 miljarder, 13 miljarder och 70 miljarder parametrar.
I den här guiden kommer du att utforska potentialen hos Llama 2 genom att skapa en interaktiv chatbot med hjälp av Streamlit och Llama 2.
Lär känna Llama 2:s egenskaper och fördelar
Hur står sig Llama 2 i jämförelse med sin föregångare, Llama 1?
- Utökad modellstorlek: Llama 2 har en betydligt större modell, med upp till 70 miljarder parametrar, vilket möjliggör en djupare förståelse av språkliga samband.
- Förbättrade samtalsförmågor: Med hjälp av förstärkningsinlärning från mänsklig feedback (RLHF), erbjuder Llama 2 avancerade konversationsfunktioner. Den kan generera text som liknar mänsklig kommunikation, även i komplexa dialoger.
- Snabbare informationsbearbetning: En ny metod, kallad ”grouped-query attention”, accelererar slutledningsprocessen. Detta möjliggör snabbare och effektivare användning av modellen i applikationer som chatbots och virtuella assistenter.
- Ökad effektivitet: Jämfört med Llama 1 är Llama 2 mer resurseffektiv, både när det gäller minne och beräkningskraft.
- Tillgänglighet med öppen källkod: Llama 2 är tillgänglig med öppen källkod och en icke-kommersiell licens, vilket ger forskare och utvecklare frihet att använda och modifiera modellen.
Sammantaget erbjuder Llama 2 betydande förbättringar jämfört med sin föregångare. Dessa förbättringar gör den till ett kraftfullt verktyg för många applikationer, som chatbots, digitala assistenter och avancerad textförståelse.
Förbereda en Streamlit-miljö för chatbotutveckling
För att starta utvecklingen av din chatbot, behöver du först skapa en isolerad utvecklingsmiljö, fri från potentiella konflikter med befintliga projekt på din dator.
Börja med att skapa en virtuell miljö med hjälp av Pipenv enligt följande:
pipenv shell
Installera därefter de nödvändiga biblioteken för att bygga chatboten:
pipenv install streamlit replicate
Streamlit är ett open-source-ramverk som gör det enkelt att skapa webbapplikationer för maskininlärning och dataanalys. Replicate är en molnbaserad plattform som ger tillgång till en mängd stora maskininlärningsmodeller för implementering.
Skaffa din Llama 2 API-token från Replicate
För att få en API-token från Replicate, behöver du först skapa ett konto på Replicate med ditt GitHub-konto.
När du har tillgång till din instrumentpanel, gå till Utforska och sök efter ”Llama 2 chat” för att hitta ”llama-2–70b-chat” modellen.
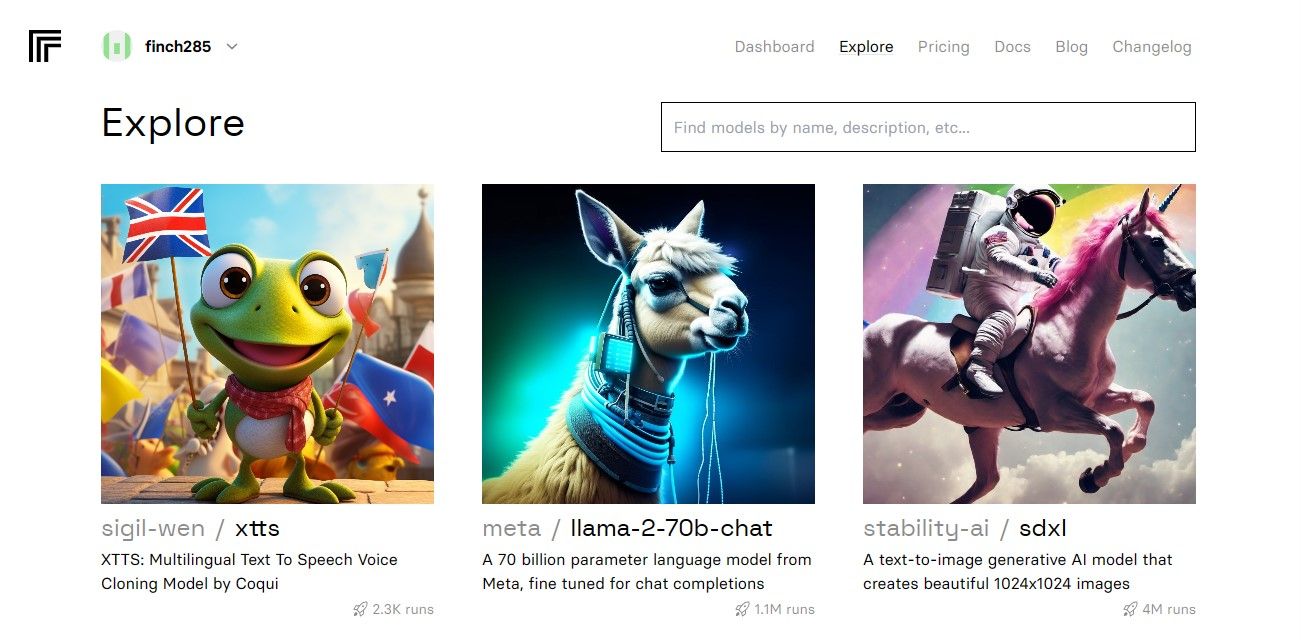
Klicka på ”llama-2–70b-chat” för att se Llama 2 API-slutpunkterna. Klicka sedan på ”API”-knappen i modellens meny och välj ”Python” på höger sida. Detta ger dig tillgång till din API-token som du kan använda i dina Python-applikationer.
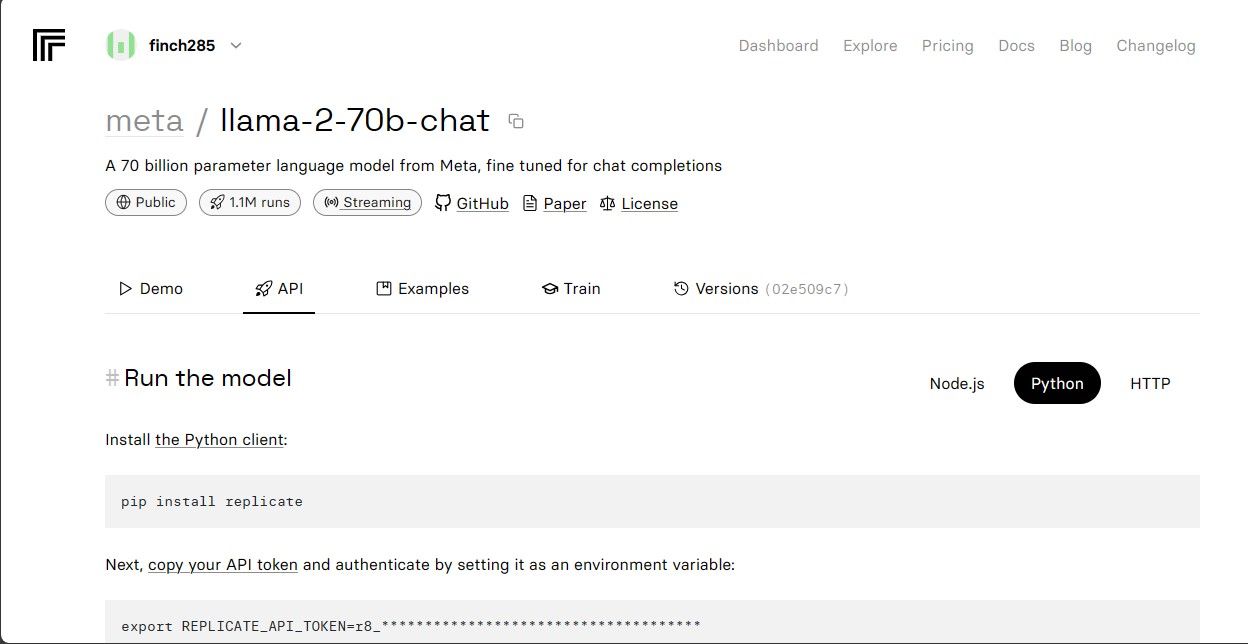
Kopiera din REPLICATE_API_TOKEN och spara den på ett säkert ställe för framtida användning.
Skapa chatboten
Börja med att skapa en Python-fil (llama_chatbot.py) och en .env-fil för att lagra dina API-nycklar. Skriv koden för din chatbot i llama_chatbot.py och lagra känslig information i .env-filen.
I llama_chatbot.py, importera de nödvändiga biblioteken:
import streamlit as st
import os
import replicate
Definiera sedan de globala variablerna för ”llama-2–70b-chat” modellen:
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default="")
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default="")
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default="")
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default="")
I .env-filen, lägg till din Replicate-token och modellens slutpunkter i följande format:
REPLICATE_API_TOKEN='Din_Replicate_Token'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
Klistra in din Replicate-token och spara .env-filen.
Designa chatbotens samtalsprocess
Skapa en grundläggande instruktion för Llama 2 modellen, anpassad till den roll du vill att den ska spela. I det här fallet ska modellen fungera som en hjälpsam assistent:
PRE_PROMPT = "Du är en hjälpsam assistent. Du svarar inte som 'Användare' eller låtsas vara 'Användare'. Du svarar endast en gång som Assistent."
Konfigurera sidans utseende för din chatbot:
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
Skapa en funktion för att hantera sessionens initiala tillstånd och lagring av variabler:
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPTdef setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Välj en LLaMA2-modell:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
Funktionen hanterar variabler som ”chat_dialogue”, ”pre_prompt”, ”llm”, ”top_p”, ”max_seq_len” och ”temperature” i sessionen. Den hanterar även valet av Llama 2-modellen baserat på användarens preferenser.
Skapa en funktion som visar innehållet i sidopanelen i Streamlit-applikationen:
def render_sidebar():
st.sidebar.header("LLaMA2 Chatbot")
st.session_state['temperature'] = st.sidebar.slider('Temperatur:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Max Sekvenslängd:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Prompt innan chatten startar. Redigera här om du vill:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
Den här funktionen hanterar visningen av rubriken och justerbara inställningar för Llama 2 chatbot.
Skapa funktionen som visar chatthistoriken i Streamlit-applikationens huvudområde:
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
Denna funktion itererar genom ”chat_dialogue” som lagras i sessionstillståndet och visar varje meddelande med motsvarande roll (användare eller assistent).
Hantera användarens input med hjälp av följande funktion:
def handle_user_input():
user_input = st.chat_input(
"Skriv din fråga här för att chatta med LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
Den här funktionen ger användaren ett inmatningsfält där de kan skriva meddelanden och frågor. När användaren skickar meddelandet, läggs meddelandet till ”chat_dialogue” i sessionstillståndet med användarrollen.
Skapa en funktion som genererar svar från Llama 2-modellen och visar dem i chattområdet:
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "User" if dict_message["role"] == "user" else "Assistant"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Assistant: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
Funktionen skapar en sammanfattning av konversationshistoriken med både användar- och assistentmeddelanden innan funktionen ”debounce_replicate_run” anropas för att hämta assistentens svar. Svaret uppdateras kontinuerligt i användargränssnittet för en smidig chattupplevelse.
Skapa huvudfunktionen som ansvarar för att rendera hela Streamlit-applikationen:
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
Den här funktionen anropar alla definierade funktioner i en logisk ordning för att konfigurera sessionstillståndet, visa sidopanelen och chatthistoriken, hantera användarinput och generera assistentsvar.
Skapa en funktion som anropar ”render_app”-funktionen och startar applikationen när skriptet körs:
def main():
render_app()if __name__ == "__main__":
main()
Din applikation ska nu vara redo att köras.
Hantera API-anrop
Skapa en fil med namnet utils.py i din projektmapp och lägg till följande funktion:
import replicate
import time
last_call_time = 0
debounce_interval = 2def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("Senaste anropstid: ", last_call_time)current_time = time.time()
elapsed_time = current_time - last_call_timeif elapsed_time < debounce_interval:
print("Avvisar anropet")
return "Hej! Dina förfrågningar är för snabba. Vänta ett par" \
" sekunder innan du skickar en ny förfrågan."last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Assistant: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
Denna funktion implementerar en ”debounce”-mekanism för att undvika att användares snabba inmatning orsakar för frekventa API-anrop.
Importera sedan ”debounce_replicate_run”-funktionen till din llama_chatbot.py-fil enligt följande:
from utils import debounce_replicate_run
Kör nu applikationen:
streamlit run llama_chatbot.py
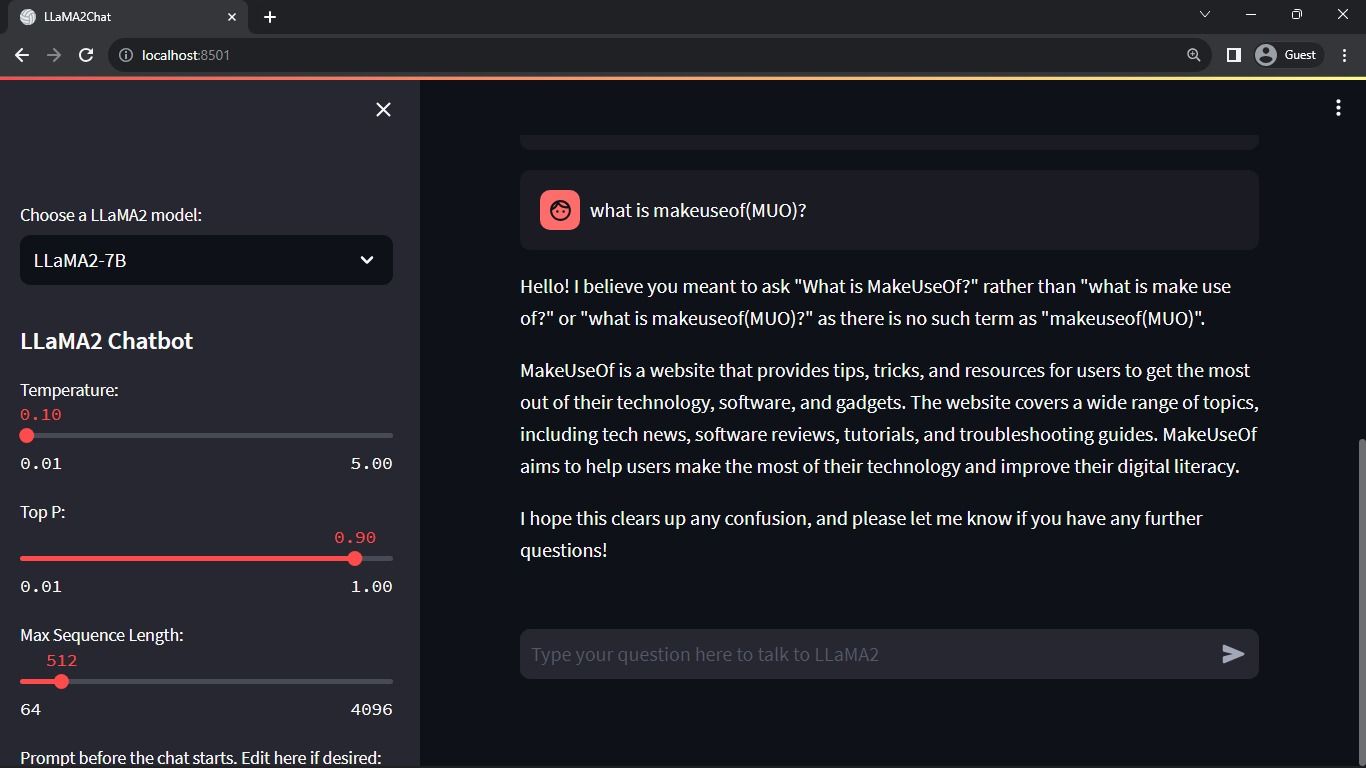
Förväntat resultat:
Resultatet visar en interaktion mellan modellen och en användare.
Användningsområden för Streamlit och Llama 2 chatbots i verkligheten
Några exempel på verkliga applikationer av Llama 2:
- Chatbots: Användbart för att skapa chattbottar som kan genomföra verklighetstrogna konversationer om olika ämnen.
- Virtuella assistenter: Kan användas för att utveckla virtuella assistenter som kan förstå och svara på mänskliga språkfrågor.
- Språköversättning: Möjligt att använda modellen för språköversättningsuppgifter.
- Textsammanfattning: Kan sammanfatta stora textstycken till kortare, mer lättförståeliga sammanfattningar.
- Forskning: Llama 2 kan användas för forskning genom att besvara frågor inom ett brett spektrum av ämnen.
Framtiden för AI
Med slutna modeller som GPT-3.5 och GPT-4 kan det vara svårt för mindre aktörer att skapa betydande applikationer med hjälp av LLM eftersom tillgång till GPT-modellens API kan vara dyrt.
Tillgängliggörandet av avancerade språkmodeller som Llama 2 för utvecklingscommunityn är början på en ny era inom AI. Detta kommer att stimulera kreativitet och innovation i utvecklingen av applikationer, vilket i sin tur påskyndar kapplöpningen mot att uppnå artificiell superintelligens (ASI).