Hantera åtkomsträttigheter till data i AWS S3
För en tid sedan, när lokala Unix-servrar med stora filsystem var standard, konstruerade företag invecklade system för mapphantering. Dessa system styrde åtkomsten till olika kataloger för olika användare.
Oftast betjänar en organisations plattform en mångfald användargrupper med varierande behov, begränsningar vad gäller sekretess eller specificerad dataindelning. I globala företag kan detta till och med innebära att innehållet måste separeras geografiskt, mellan användare i olika länder.
Andra vanliga scenarier kan vara:
- Dataseparation mellan miljöer för utveckling, testning och produktion.
- Säljinriktat material som inte är avsett för allmän spridning.
- Länderrelaterat juridiskt innehåll som inte ska vara tillgängligt i andra regioner.
- Projektdata där känslig information endast ska vara tillgänglig för en specifik grupp av ledare.
Listan kan bli mycket lång. Det viktiga är att det alltid finns ett behov av att strukturera och hantera åtkomsten till filer och data för alla användare på en given plattform.
Tidigare var detta en rutinåtgärd. Systemadministratören skapade regler, använde ett lämpligt verktyg och mappade sedan användare till grupper. Dessa grupper i sin tur fick tillgång till specifika kataloger eller monteringspunkter, med olika behörigheter som läs- eller läs- och skrivåtkomst.
När vi nu övergår till AWS molnplattformar, är det naturligt att förvänta sig liknande behov av begränsningar av datatillgång. Lösningen måste dock anpassas. Filer finns inte längre fysiskt på Unix-servrar, utan lagras i molnet (där de potentiellt är tillgängliga för hela organisationen och globalt). Innehållet lagras inte heller i traditionella mappar, utan i S3-buckets.
Följande text beskriver en metod för att lösa detta problem. Den baseras på verkliga erfarenheter från ett specifikt projekt.
Enkel men resurskrävande manuell metod
Ett enkelt, men manuellt sätt att hantera detta problem är att:
- Skapa en ny bucket för varje distinkt användargrupp.
- Konfigurera behörigheterna för varje bucket så att endast den avsedda gruppen har tillgång till den.
Denna metod kan fungera för snabba och enkla lösningar. Men det finns några begränsningar att vara medveten om.
Som standard kan endast 100 S3-buckets skapas per AWS-konto. Denna gräns kan ökas till 1000 genom att kontakta AWS support. Om dessa begränsningar inte är ett problem, kan du låta varje användargrupp arbeta i sin egen bucket.
Svårigheter uppstår när användargrupper har tvärfunktionella ansvarsområden, eller när enskilda användare behöver tillgång till data från flera domäner samtidigt. Till exempel:
- Dataanalytiker som utvärderar data från olika områden och regioner.
- Testteam som delar tjänster mellan olika utvecklingsteam.
- Rapporteringsanvändare som bygger instrumentpaneler med data från olika länder i samma region.
Denna lista kan bli lång och företagens behov kan leda till många olika användningsfall.
Ju mer komplex denna lista blir, desto mer komplex blir hanteringen av åtkomsträttigheter. Ytterligare verktyg kan behövas, och det kan till och med krävas en dedikerad resurs (administratör) för att hantera åtkomstlistorna och uppdatera dem vid behov (vilket kan ske ofta, särskilt i stora företag).
Hur kan man uppnå samma sak på ett mer strukturerat och automatiserat sätt?
Om en dedikerad bucket per användargrupp inte fungerar, kommer alla andra lösningar att involvera delade buckets för flera användargrupper. I sådana fall är det nödvändigt att bygga logiken för att tilldela åtkomsträttigheter i ett område som är enkelt att anpassa dynamiskt.
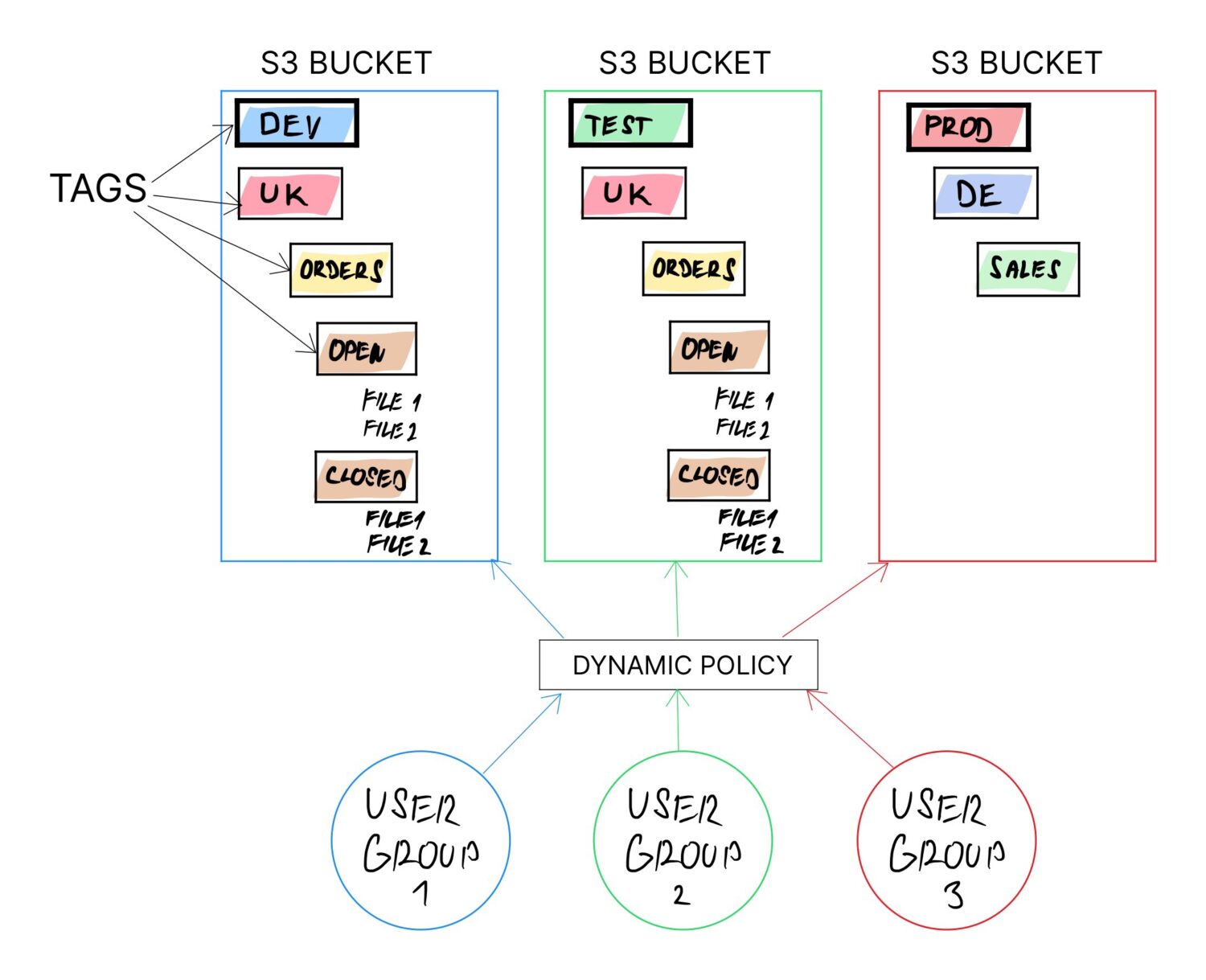
Ett sätt att uppnå detta är genom att använda taggar på S3-buckets. Taggar rekommenderas oavsett (inte minst för att underlätta fakturering). Taggar kan dessutom ändras när som helst.
Om hela logiken baseras på bucket-taggar, och resten av konfigurationen beror på dessa taggvärden, säkerställs dynamiska justeringar. Syftet med bucketen kan enkelt ändras genom att uppdatera taggvärdena.
Vilka taggar ska användas för att detta ska fungera?
Detta beror på det specifika användningsfallet. Exempel:
- Buckets kan behöva separeras baserat på typ av miljö. En tagg kan då vara ”ENV” med värden som ”DEV”, ”TEST”, ”PROD”.
- Separation kan behövas baserat på land. En annan tagg kan vara ”COUNTRY” med motsvarande landsnamn.
- Användare kan separeras baserat på vilken avdelning de tillhör: affärsanalytiker, dataanvändare, dataforskare osv. En tagg kan då vara ”USER_TYPE” med lämpliga värden.
- Det kan också vara önskvärt att definiera en fast mappstruktur för användargrupper, till exempel: ”data/import”, ”data/bearbetad”, ”data/fel”. Detta kan också styras med taggar.
Helst ska taggarna vara logiskt kombinerbara för att skapa en mappstruktur i bucketen.
Taggarna kan kombineras för att skapa en mappstruktur för olika typer av användare, från olika länder och med fördefinierade importmappar:
- /<ENV>/<USER_TYPE>/<COUNTRY>/<UPLOAD>
Genom att ändra värdet på <ENV> kan taggens syfte ändras (om den ska användas i test-, utvecklings- eller produktionsmiljön).
Detta möjliggör att samma bucket används av många olika användare. Buckets har inte uttryckligen stöd för mappar, men de stöder ”etiketter”. Dessa etiketter fungerar som undermappar eftersom användarna måste navigera genom dem för att nå sin data (precis som med undermappar).
När taggarna är definierade i en användbar form, är nästa steg att skapa S3-bucketpolicyer som använder taggarna.
Om policyerna använder taggnamn, skapas ”dynamiska policyer”. Detta innebär att policyn fungerar olika för buckets med olika taggvärden som policyn refererar till som platshållare.
Detta steg kräver viss anpassad kodning av de dynamiska policyerna, men Amazon AWS policyredigeringsverktyg kan underlätta processen.
I policyn måste konkreta åtkomsträttigheter definieras för bucketen, inklusive åtkomstnivå (läs- eller skrivrättigheter). Logiken läser taggarna på bucketen och bygger upp mappstrukturen (skapar etiketter baserat på taggarna). Beroende på taggarnas värden skapas undermappar och nödvändiga behörigheter tilldelas.
En dynamisk policy kan användas för många buckets. Den fungerar olika för varje bucket, men den kommer alltid att agera i enlighet med taggvärdena. Detta är en effektiv metod för att hantera åtkomsträttigheter på ett organiserat och centraliserat sätt för många buckets. Varje bucket följer samma struktur och används av alla användare i organisationen.
Automatisera introduktionen av nya enheter
När dynamiska policyer är definierade och tillämpade på befintliga buckets, kan användarna börja använda samma buckets utan risk för att användare från olika grupper får tillgång till innehåll de inte ska se.
Användare med bredare åtkomst får också enkelt tillgång till data, eftersom allt lagras i samma bucket.
Det sista steget är att göra introduktionen av nya användare, buckets och taggar så enkel som möjligt. Detta kräver viss anpassad kod, som inte behöver vara komplex, förutsatt att introduktionsprocessen har tydliga regler som kan kapslas in i en enkel algoritm (vilket visar att processen är logisk och inte kaotisk).
Detta kan vara så enkelt som ett skript som körs med AWS CLI, med parametrar som behövs för att integrera en ny enhet i plattformen. Det kan även vara en serie CLI-skript som körs i specifik ordning, till exempel:
- create_new_bucket(<ENV>,<ENV_VALUE>,<COUNTRY>,<COUNTRY_VALUE>, ..)
- create_new_tag(<bucket_id>,<tag_name>,<tag_value>)
- update_existing_tag(<bucket_id>,<tag_name>,<tag_value>)
- create_user_group(<användartyp>,<land>,<env>)
- etc.
Du förstår poängen. 😃
Ett proffstips 👨💻
Dynamiska policyer kan användas för att tilldela åtkomsträttigheter inte bara till mappstrukturer, utan även till specifika tjänster och användargrupper automatiskt!
Detta kräver att tagglistan utökas och att dynamiska policyer tilldelas som ger tillgång till specifika tjänster för specifika grupper.
En användargrupp kanske även behöver tillgång till en specifik databasserver. Detta kan uppnås genom dynamiska policyer som använder bucket-information, särskilt om åtkomst till tjänsterna är rollbaserad. Lägg till en del i den dynamiska policykoden som bearbetar taggar gällande databaskluster och tilldela policyåtkomsträttigheter direkt till DB-klustret och användargruppen.
På detta sätt kommer introduktionen av en ny användargrupp att hanteras med en enda dynamisk policy. Eftersom policyn är dynamisk kan den återanvändas för många grupper som följer samma mönster (även om de inte nödvändigtvis använder samma tjänster).
Du kan även titta närmare på dessa AWS S3-kommandon för att hantera buckets och data.