
När man tittar på företagets mjukvaruutveckling från första raden i två decennier, är den obestridliga trenden under de senaste åren tydlig – att flytta databaser till molnet.
Jag var redan involverad i några migreringsprojekt, där målet var att föra in den befintliga databasen på plats till Amazon Web Services (AWS) molndatabas. Medan du från AWS dokumentationsmaterial kommer att lära dig hur enkelt detta kan vara, är jag här för att berätta att genomförandet av en sådan plan inte alltid är lättsamt, och det finns fall där det kan misslyckas.
I det här inlägget kommer jag att täcka den verkliga upplevelsen för följande fall:
- Källan: Även om det i teorin inte spelar någon roll vad din källa är (du kan använda ett mycket liknande tillvägagångssätt för de flesta av de mest populära databaserna), var Oracle det valda databassystemet i stora företag under många år, och det är där mitt fokus kommer att ligga.
- Målet: Ingen anledning att vara specifik på den här sidan. Du kan välja vilken måldatabas som helst i AWS, och tillvägagångssättet kommer fortfarande att passa.
- Läget: Du kan ha en fullständig uppdatering eller inkrementell uppdatering. En batchdataladdning (käll- och måltillstånd är försenade) eller (nästan) realtidsdataladdning. Båda kommer att beröras här.
- Frekvensen: Du kanske vill ha en engångsmigrering följt av en fullständig byte till molnet eller kräva en viss övergångsperiod och att ha data uppdaterade på båda sidor samtidigt, vilket innebär att du utvecklar daglig synkronisering mellan lokal och AWS. Den förra är enklare och är mycket mer meningsfull, men den senare efterfrågas oftare och har mycket fler brytpunkter. Jag kommer att täcka båda här.
Innehållsförteckning
Problembeskrivning
Kravet är ofta enkelt:
Vi vill börja utveckla tjänster inom AWS, så kopiera all vår data till ”ABC”-databasen. Snabbt och enkelt. Vi måste använda data i AWS nu. Senare kommer vi att ta reda på vilka delar av DB-designer som ska ändras för att matcha våra aktiviteter.
Innan du går vidare finns det något att tänka på:
- Hoppa inte in i tanken att ”bara kopiera vad vi har och ta itu med det senare” för snabbt. Jag menar, ja, det här är det enklaste du kan göra, och det kommer att göras snabbt, men det här har potential att skapa ett så grundläggande arkitektoniskt problem som kommer att vara omöjligt att fixa senare utan allvarlig omstrukturering av majoriteten av den nya molnplattformen . Föreställ dig bara att molnets ekosystem är helt annorlunda än det lokala. Flera nya tjänster kommer att introduceras med tiden. Naturligtvis kommer människor att börja använda samma mycket olika. Det är nästan aldrig en bra idé att replikera det lokala tillståndet i molnet på ett 1:1-sätt. Det kan vara i just ditt fall, men se till att dubbelkolla detta.
- Ifrågasätt kravet med några meningsfulla tvivel som:
- Vem kommer att vara den typiska användaren som använder den nya plattformen? När det är på plats kan det vara en transaktionsanvändare. i molnet kan det vara en datavetare eller datalageranalytiker, eller så kan datans huvudanvändare vara en tjänst (t.ex. Databricks, Glue, maskininlärningsmodeller, etc.).
- Förväntas de vanliga dagliga jobben stanna kvar även efter övergången till molnet? Om inte, hur förväntas de förändras?
- Planerar du en betydande ökning av data över tid? Troligtvis är svaret ja, eftersom det ofta är den enskilt viktigaste anledningen till att migrera in i molnet. En ny datamodell ska vara redo för det.
- Räkna med att slutanvändaren tänker på några allmänna, förväntade frågor som den nya databasen kommer att få från användarna. Detta kommer att definiera hur mycket den befintliga datamodellen ska ändras för att förbli prestandarelevant.
Ställer in migreringen
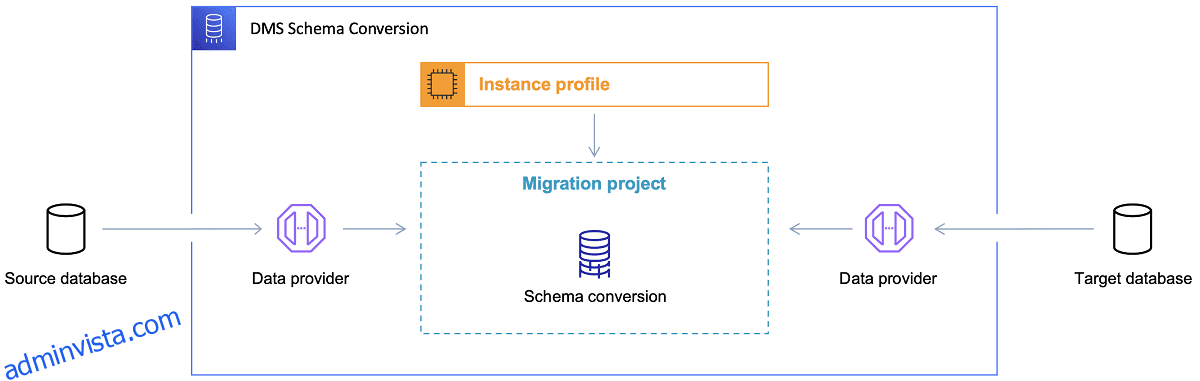
När måldatabasen väl har valts och datamodellen har diskuterats på ett tillfredsställande sätt, är nästa steg att bekanta sig med AWS Schema Conversion Tool. Det finns flera områden där detta verktyg kan användas:
 Referens: AWS-dokumentation
Referens: AWS-dokumentation
Nu finns det några tips för att använda Schema Conversion Tool.
För det första bör det nästan aldrig vara fallet att använda utdata direkt. Jag skulle se det mer som referensresultat, varifrån du ska göra dina justeringar baserat på din förståelse och syfte med data och hur data kommer att användas i molnet.
För det andra, tidigare valdes tabellerna troligen ut av användare som förväntade sig snabba korta resultat om någon konkret datadomänenhet. Men nu kan uppgifterna väljas för analytiska ändamål. Till exempel kommer databasindex som tidigare arbetade i den lokala databasen nu vara oanvändbara och definitivt inte förbättra prestandan för DB-systemet relaterat till denna nya användning. På samma sätt kanske du vill partitionera data annorlunda på målsystemet, som det var tidigare på källsystemet.
Det kan också vara bra att överväga att göra några datatransformationer under migreringsprocessen, vilket i princip innebär att ändra måldatamodellen för vissa tabeller (så att de inte längre är 1:1-kopior). Senare kommer omvandlingsreglerna att behöva implementeras i migreringsverktyget.
Om käll- och måldatabaserna är av samma typ (t.ex. Oracle on-premise vs. Oracle i AWS, PostgreSQL vs. Aurora Postgresql, etc.), är det bäst att använda ett dedikerat migreringsverktyg som konkret databas stöder inbyggt ( t.ex. export och import av datapumpar, Oracle Goldengate, etc.).
Men i de flesta fall kommer käll- och måldatabasen inte att vara kompatibla, och då är det självklara valet AWS Database Migration Service.
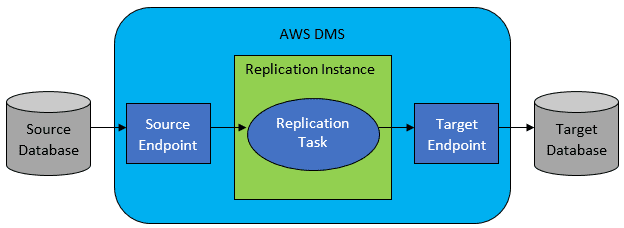 Referens: AWS-dokumentation
Referens: AWS-dokumentation
AWS DMS tillåter i princip att konfigurera en lista med uppgifter på tabellnivå, som kommer att definiera:
- Vilken är den exakta källdatabasen och tabellen att ansluta till?
- Uttalandets specifikationer som kommer att användas för att erhålla data för måltabellen.
- Transformationsverktyg (om några), som definierar hur källdata ska mappas till måltabelldata (om inte 1:1).
- Vilken är den exakta måldatabasen och tabellen att ladda data till?
Konfigurationen av DMS-uppgifter görs i något användarvänligt format som JSON.
Nu i det enklaste scenariot är allt du behöver göra att köra distributionsskripten på måldatabasen och starta DMS-uppgiften. Men det finns mycket mer i det.
Engångsfull datamigrering

Det enklaste fallet att utföra är när begäran är att flytta hela databasen en gång till målmolndatabasen. Då kommer i princip allt som krävs att göra se ut så här:
Om konfigurationen av DMS görs bra, kommer inget dåligt att hända i detta scenario. Varje enskild källtabell kommer att plockas upp och kopieras över till AWS-måldatabasen. Det enda problemet kommer att vara utförandet av aktiviteten och att se till att storleken är rätt i varje steg så att den inte misslyckas på grund av otillräckligt lagringsutrymme.
Inkrementell daglig synkronisering

Det är här saker och ting börjar bli komplicerade. Jag menar, om världen skulle vara idealisk, så skulle den förmodligen fungera bra hela tiden. Men världen är aldrig idealisk.
DMS kan konfigureras för att fungera i två lägen:
- Full belastning – standardläge som beskrivs och används ovan. DMS-uppgifterna startas antingen när du startar dem eller när de är schemalagda att starta. När det är klart är DMS-uppgifterna gjorda.
- Change Data Capture (CDC) – i det här läget körs DMS-uppgiften kontinuerligt. DMS skannar källdatabasen efter en ändring på tabellnivå. Om ändringen sker försöker den omedelbart replikera ändringen i måldatabasen baserat på konfigurationen i DMS-uppgiften relaterad till den ändrade tabellen.
När du väljer CDC måste du göra ännu ett val – nämligen hur CDC kommer att extrahera deltaändringarna från källdatabanken.
#1. Oracle Redo Logs Reader
Ett alternativ är att välja inbyggd databas redo-loggläsare från Oracle, som CDC kan använda för att få de ändrade data, och, baserat på de senaste ändringarna, replikera samma ändringar på måldatabasen.
Även om detta kan se ut som ett självklart val om man hanterar Oracle som källa, finns det en hake: Oracle redo logs reader använder källan Oracle-klustret och påverkar därför direkt alla andra aktiviteter som körs i databasen (det skapar faktiskt direkt aktiva sessioner i databasen).
Ju fler DMS-uppgifter du har konfigurerat (eller ju fler DMS-kluster parallellt), desto mer kommer du förmodligen att behöva utöka Oracle-klustret – i princip, justera den vertikala skalningen av ditt primära Oracle-databaskluster. Detta kommer säkert att påverka de totala kostnaderna för lösningen, i ännu högre grad om den dagliga synkroniseringen är på väg att stanna kvar i projektet under en lång tid.
#2. AWS DMS Log Miner
Till skillnad från alternativet ovan är detta en inbyggd AWS-lösning för samma problem. I det här fallet påverkar DMS inte källan för Oracle DB. Istället kopierar den Oracles redo-loggar till DMS-klustret och gör all bearbetning där. Även om det sparar Oracle-resurser, är det den långsammare lösningen, eftersom fler operationer är inblandade. Och dessutom, som man lätt kan anta, är den anpassade läsaren för Oracle redo loggar förmodligen långsammare i sitt jobb som den infödda läsaren från Oracle.
Beroende på storleken på källdatabasen och antalet dagliga förändringar där, i bästa fall, kan du i bästa fall sluta med inkrementell synkronisering av data från den lokala Oracle-databasen till AWS molndatabas nästan i realtid.
I alla andra scenarier kommer det fortfarande inte att vara nära realtidssynkronisering, men du kan försöka komma så nära den accepterade fördröjningen som möjligt (mellan källa och mål) genom att ställa in käll- och målkluster prestandakonfiguration och parallellitet eller experimentera med mängden DMS-uppgifter och deras fördelning mellan CDC-instanserna.
Och du kanske vill lära dig vilka ändringar av källtabeller som stöds av CDC (som tillägg av en kolumn, till exempel) eftersom inte alla möjliga ändringar stöds. I vissa fall är det enda sättet att ändra måltabellen manuellt och starta om CDC-uppgiften från början (förlora all befintlig data i måldatabasen på vägen).
När saker och ting går fel, oavsett vad

Jag lärde mig detta på den hårda vägen, men det finns ett specifikt scenario kopplat till DMS där löftet om daglig replikering är svårt att uppnå.
DMS kan endast bearbeta redo-loggarna med viss definierad hastighet. Det spelar ingen roll om det finns fler instanser av DMS som utför dina uppgifter. Ändå läser varje DMS-instans bara redo-loggarna med en enda definierad hastighet, och var och en av dem måste läsa dem hela. Det spelar till och med ingen roll om du använder Oracle redo logs eller AWS log miner. Båda har denna gräns.
Om källdatabasen innehåller ett stort antal ändringar inom en dag som Oracles redo-loggar blir riktigt stora (som 500 GB+ stora) varje dag, kommer CDC helt enkelt inte att fungera. Replikeringen kommer inte att slutföras före dagens slut. Det kommer att ta med obearbetat arbete till nästa dag, där en ny uppsättning ändringar som ska replikeras redan väntar. Mängden obearbetad data kommer bara att växa från dag till dag.
I det här specifika fallet var CDC inte ett alternativ (efter många prestandatester och försök vi utförde). Det enda sättet att säkerställa att åtminstone alla deltaförändringar från den aktuella dagen kommer att replikeras samma dag var att närma sig det så här:
- Separera riktigt stora bord som inte används så ofta och replikera dem bara en gång i veckan (t.ex. under helger).
- Konfigurera replikering av inte-så-stora-men-fortfarande-stora tabeller att delas mellan flera DMS-uppgifter; en tabell migrerades så småningom av 10 eller fler separata DMS-uppgifter parallellt, vilket säkerställer att datauppdelningen mellan DMS-uppgifterna är distinkt (anpassad kodning involverad här) och exekvera dem dagligen.
- Lägg till fler (upp till 4 i det här fallet) instanser av DMS och dela upp DMS-uppgifterna jämnt mellan dem, vilket betyder inte bara efter antalet tabeller utan också efter storleken.
I grund och botten använde vi full load-läget för DMS för att replikera daglig data eftersom det var det enda sättet att uppnå åtminstone samma dag datareplikering.
Ingen perfekt lösning, men den finns fortfarande kvar, och även efter många år fungerar den fortfarande på samma sätt. Så, kanske inte så dålig lösning trots allt. 😃