I takt med att företag skapar allt större mängder data, blir de traditionella metoderna för datalagring allt mer komplexa och kostsamma att underhålla. Data Vault, en relativt ny metod för datalagring, erbjuder en lösning på detta genom att ge ett flexibelt, skalbart och kostnadseffektivt sätt att hantera stora datamängder.
I denna artikel kommer vi att utforska varför Data Vaults ses som framtidens datalagring och varför fler och fler företag väljer denna metod. Vi kommer också att presentera resurser för den som vill fördjupa sig i ämnet!
Vad är Data Vault?
Data Vault är en datalagerteknik särskilt lämpad för agila datalager. Den ger hög flexibilitet för tillägg, en fullständig historik av data över tid, och möjliggör stark parallellisering av dataladdningsprocesserna. Dan Linstedt utvecklade Data Vault-modellering på 1990-talet.
Efter den första publiceringen år 2000, fick den ökad uppmärksamhet 2002 genom en serie artiklar. År 2007 fick Linstedt stöd av Bill Inmon, som beskrev det som det ”optimala valet” för sin Data Vault 2.0-arkitektur.
Den som undersöker begreppet agilt datalager kommer snart att stöta på Data Vault. Det unika med denna teknik är att den är inriktad på företagens behov, då den möjliggör flexibla och enkla anpassningar av ett datalager.
Data Vault 2.0 tar hänsyn till hela utvecklingsprocessen och arkitekturen och består av metod, arkitektur och modell. Fördelen är att detta tillvägagångssätt beaktar alla aspekter av business intelligence med det underliggande datalagret under utvecklingen.
Data Vault-modellen erbjuder en modern lösning för att övervinna begränsningarna med traditionella datamodelleringsmetoder. Med sin skalbarhet, flexibilitet och smidighet ger den en solid grund för att bygga en dataplattform som kan hantera komplexiteten och mångfalden i moderna datamiljöer.
Data Vaults hub-and-spoke-arkitektur och separation av enheter och attribut möjliggör dataintegration och harmonisering över flera system och domäner, vilket underlättar inkrementell och smidig utveckling.
En avgörande roll för Data Vault i att bygga en dataplattform är att etablera en enda källa till sanning för all data. Dess enhetliga syn på data och stöd för att fånga och spåra historiska dataförändringar genom satellittabeller möjliggör efterlevnad, revision, regulatoriska krav och omfattande analys och rapportering.
Data Vaults funktioner för dataintegrering i nästan realtid via deltaladdning underlättar hantering av stora datamängder i snabbt föränderliga miljöer som Big Data och IoT-applikationer.
Data Vault kontra traditionella datalagermodeller
Third-Normal-Form (3NF) är en välkänd traditionell datalagermodell, ofta använd i många större implementeringar. Denna modell överensstämmer med idéerna från Bill Inmon, en av ”grundarna” av datalagerkonceptet.
Inmon-arkitekturen baseras på relationsdatabasmodellen och eliminerar dataredundans genom att dela upp datakällor i mindre tabeller som lagras i datamarts och kopplas samman med hjälp av primär- och sekundärnycklar. Detta säkerställer att data är konsekvent och korrekt genom att upprätthålla regler för referensintegritet.
Målet med normalformuläret var att skapa en fullständig, företagsomfattande datamodell för kärndatalagret. Det har dock problem med skalbarhet och flexibilitet på grund av starkt kopplade datamarts, svårigheter med laddning i nästan realtid, komplexa frågor och top-down-design och implementering.
Kimball-modellen, som används för OLAP (online analytical processing) och datamarts, är en annan känd datalagermodell där faktatabeller innehåller aggregerade data och dimensionstabeller beskriver lagrad data i ett stjärnschema eller snöflingeschema. I denna arkitektur organiseras data i fakta- och dimensionstabeller som är denormaliserade för att förenkla frågor och analys.
Kimball baseras på en dimensionsmodell som är optimerad för frågor och rapportering, vilket gör den idealisk för business intelligence-applikationer. Den har dock haft problem med isolering av ämnesorienterad information, dataredundans, inkompatibla frågestrukturer, skalbarhetssvårigheter, den inkonsekventa granulariteten i faktatabeller, synkroniseringsproblem och behovet av top-down-design med bottom-up-implementering.
Data Vault-arkitektur är däremot en hybridmetod som kombinerar aspekter av både 3NF- och Kimball-arkitekturerna. Det är en modell baserad på relationsprinciper, datanormalisering och redundansmatematik som representerar relationer mellan enheter på olika sätt och strukturerar tabellfält och tidsstämplar annorlunda.
I denna arkitektur lagras all data i en rådatavalv eller datasjö, medan bearbetad data lagras i ett normaliserat format i ett affärsvalv som innehåller historisk och kontextspecifik data som kan användas för rapportering.
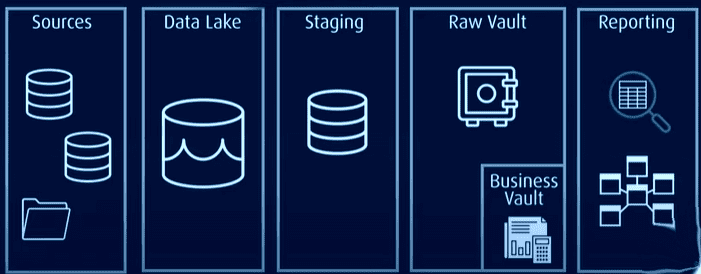
Data Vault hanterar problemen i traditionella modeller genom att vara mer effektiv, skalbar och flexibel. Den möjliggör laddning i nästan realtid, bättre dataintegritet och enkel expansion utan att påverka befintliga strukturer. Modellen kan också utökas utan att migrera de befintliga tabellerna.
| Modellansats | Datastruktur | Designmetod |
| 3NF-modellering | Tabeller i 3NF | Bottom-up |
| Kimball-modellering | Stjärnschema eller snöflingeschema | Top-down |
| Data Vault | Hub-and-Spoke | Bottom-up |
Arkitektur av Data Vault
Data Vault har en hub-and-spoke-arkitektur och består huvudsakligen av tre lager:
Staging Layer: Samlar in rådata från källsystemen, såsom CRM eller ERP
Data Warehouse Layer: När det modelleras som en Data Vault-modell innehåller detta lager:
- Raw Data Vault: lagrar rådata.
- Business Data Vault: inkluderar harmoniserad och transformerad data baserad på affärsregler (valfritt).
- Metrics Vault: lagrar körningsinformation (valfritt).
- Operational Vault: lagrar data som flödar direkt från operativa system till datalagret (valfritt.)
Data Mart Layer: Detta lager modellerar data som stjärnschema och/eller andra modelleringstekniker. Det ger information för analys och rapportering.
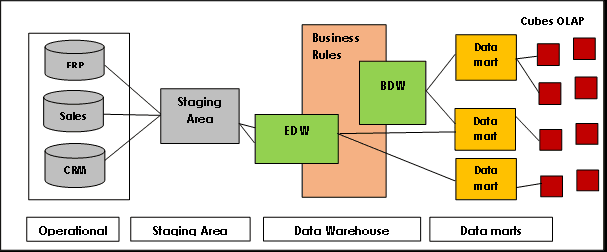 Bildkälla: Lamia Yessad
Bildkälla: Lamia Yessad
Data Vault kräver ingen omstrukturering. Nya funktioner kan byggas parallellt direkt med hjälp av koncepten och metoderna i Data Vault, och befintliga komponenter påverkas inte. Ramverk kan göra arbetet betydligt enklare: de skapar ett lager mellan datalagret och utvecklaren och minskar därmed komplexiteten i implementeringen.
Komponenter i Data Vault
Under modelleringen delar Data Vault in all information som hör till objektet i tre kategorier – i motsats till klassisk tredje normalformsmodellering. Denna information lagras sedan strikt åtskild. Funktionsområdena kan kartläggas i Data Vault i så kallade hubbar, länkar och satelliter:
#1. Hubbar
Hub är kärnan i ett affärskoncept, som kund, säljare, försäljning eller produkt. En navtabell skapas kring affärsnyckeln (butiksnamn eller plats) när en ny instans av den affärsnyckeln först introduceras i datalagret.
Hubben innehåller ingen beskrivande information och inga FK:er. Den består endast av affärsnyckeln, med en lagergenererad sekvens av ID- eller hash-nycklar, laddningsdatum/tidsstämpel och postkälla.
#2. Länkar
Länkar etablerar relationer mellan affärsnycklarna. Varje post i en länk modellerar nm-relationer för valfritt antal hubbar. Det gör att datavalvet kan reagera flexibelt på förändringar i källsystemens affärslogik, till exempel förändringar i relationernas kardinalitet. Precis som hubben innehåller länken ingen beskrivande information. Den består av sekvens-ID:n för de hubbar som den refererar till, ett lagergenererat sekvens-ID, laddningsdatum/tidsstämpel och postkälla.
#3. Satelliter
Satelliter innehåller beskrivande information (kontext) för en affärsnyckel som lagras i en hubb eller en relation som lagras i en länk. Satelliter fungerar som ”endast infoga”, vilket innebär att hela datahistoriken lagras i satelliten. Flera satelliter kan beskriva en enda affärsnyckel (eller relation). En satellit kan dock bara beskriva en nyckel (hubb eller länk).
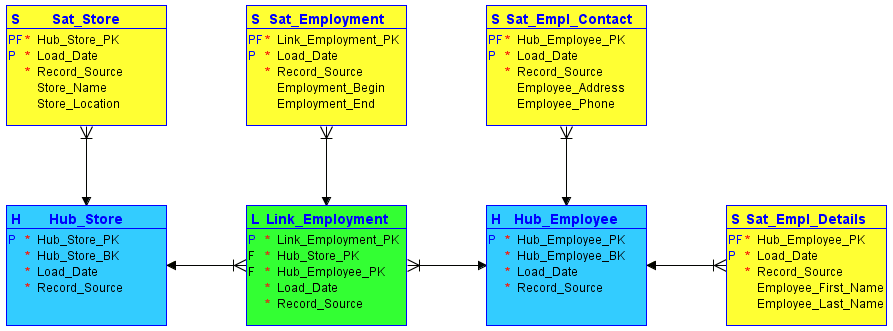 Bildkälla: Carbidfischer
Bildkälla: Carbidfischer
Hur man bygger en datavalvmodell
Att bygga en Data Vault-modell omfattar flera steg, som alla är avgörande för att säkerställa att modellen är skalbar, flexibel och kan möta verksamhetens behov:
#1. Identifiera enheter och attribut
Identifiera affärsenheterna och deras motsvarande attribut. Detta innebär ett nära samarbete med affärsintressenter för att förstå deras krav och den data de behöver fånga in. När dessa enheter och attribut har identifierats, separera dem i hubbar, länkar och satelliter.
#2. Definiera entitetsrelationer och skapa länkar
När du har identifierat enheterna och attributen definieras relationerna mellan enheterna och länkarna skapas för att representera dessa relationer. Varje länk tilldelas en affärsnyckel som identifierar relationen mellan enheterna. Satelliterna läggs sedan till för att fånga enheternas attribut och relationer.
#3. Upprätta regler och standarder
Efter att ha skapat länkar bör en uppsättning regler och standarder för datavalvmodellering upprättas för att säkerställa att modellen är flexibel och kan hantera förändringar över tid. Dessa regler och standarder bör ses över och uppdateras regelbundet för att säkerställa att de förblir relevanta och anpassade till verksamhetens behov.
#4. Fyll i modellen
När modellen har skapats bör den fyllas i med data med hjälp av en inkrementell laddningsmetod. Det innebär att data laddas in i hubbar, länkar och satelliter med hjälp av deltaladdningar. Deltaladdningar används för att säkerställa att endast de ändringar som gjorts av data laddas, vilket minskar tiden och resurserna som krävs för dataintegrering.
#5. Testa och validera modellen
Slutligen bör modellen testas och valideras för att säkerställa att den uppfyller affärskraven och är skalbar och flexibel nog att hantera framtida förändringar. Regelbundet underhåll och uppdateringar bör utföras för att säkerställa att modellen förblir i linje med affärsbehoven och fortsätter att ge en enhetlig bild av data.
Inlärningsresurser för datavalv
Att bemästra Data Vault kan ge värdefulla färdigheter och kunskaper som är mycket eftertraktade i dagens datadrivna branscher. Här är en omfattande lista över resurser, inklusive kurser och böcker, som kan hjälpa dig att lära dig mer om Data Vault:
#1. Modellera Data Warehouse med Data Vault 2.0

Denna Udemy-kurs är en omfattande introduktion till Data Vault 2.0-modelleringsmetoden, agil projektledning och Big Data-integration. Kursen täcker grunderna i Data Vault 2.0, inklusive dess arkitektur och lager, affärs- och informationsvalv och avancerade modelleringstekniker.
Den lär dig hur du designar en Data Vault-modell från grunden, konverterar traditionella modeller som 3NF och dimensionella modeller till Data Vault och förstår principerna för dimensionsmodellering i Data Vault. Kursen kräver grundläggande kunskaper om databaser och SQL-grunder.
Med ett högt betyg på 4,4 av 5 och över 1700 recensioner är denna bästsäljande kurs lämplig för alla som vill bygga en stark grund i Data Vault 2.0 och Big Data-integration.
#2. Datavalvsmodellering förklaras med användningsfall

Den här Udemy-kursen syftar till att guida dig i att bygga en Data Vault Model med hjälp av ett praktiskt affärsexempel. Den fungerar som en nybörjarguide till Data Vault-modellering och täcker nyckelbegrepp som lämpliga scenarier för att använda Data Vault-modeller, begränsningarna för konventionell OLAP-modellering och ett systematiskt tillvägagångssätt för att konstruera en Data Vault-modell. Kursen är tillgänglig för personer med minimal databaskunskap.
#3. Data Vault Guru: en pragmatisk guide
Data Vault Guru av Patrick Cuba är en omfattande guide till datavalvmetodologin, som erbjuder en unik möjlighet att modellera företagets datalager med hjälp av automatiseringsprinciper liknande de som används vid leverans av programvara.
Boken ger en översikt över modern arkitektur och en grundlig guide om hur man levererar en flexibel datamodell som anpassar sig till förändringar i företaget, datavalvet.
Dessutom utökar boken datavalvets metodik genom att tillhandahålla automatisk tidslinjekorrigering, granskningsspår, metadatakontroll och integration med agila leveransverktyg.
#4. Bygga ett skalbart datalager med Data Vault 2.0
Den här boken ger läsarna en omfattande guide för att skapa ett skalbart datalager från början till slut med hjälp av Data Vault 2.0-metoden.
Boken täcker alla väsentliga aspekter av att bygga ett skalbart datalager, inklusive Data Vault-modelleringstekniken, som är utformad för att förhindra typiska datalagerfel.
Boken innehåller många exempel för att hjälpa läsarna att förstå begreppen tydligt. Med sina praktiska insikter och verkliga exempel är den här boken en viktig resurs för alla som är intresserade av datalagring.
#5. Elefanten i kylskåpet: guidade steg för att lyckas med datavalv
The Elephant in the Fridge av John Giles är en praktisk guidebok som syftar till att hjälpa läsare att nå framgång i Data Vault genom att börja med verksamheten och sluta med verksamheten.
Boken fokuserar på betydelsen av företagsontologi och affärsidémodellering och ger steg-för-steg vägledning om hur man tillämpar dessa koncept för att skapa en solid datamodell.
Genom praktiska råd och exempelmönster ger författaren en tydlig och okomplicerad förklaring av komplexa ämnen, vilket gör boken till en utmärkt guide för dem som är nya i Data Vault.
Slutord
Data Vault representerar framtiden för datalager och erbjuder företag betydande fördelar när det gäller flexibilitet, skalbarhet och effektivitet. Den är särskilt väl lämpad för företag som behöver ladda stora datamängder snabbt och de som vill utveckla sina Business Intelligence-applikationer på ett agilt sätt.
Dessutom kan företag som har en befintlig siloarkitektur dra stor nytta av att implementera ett uppströms kärndatalager med Data Vault.
Du kanske också är intresserad av att lära dig mer om datalinjen.