Federerad inlärning representerar en revolutionerande metod för datainsamling och träning av maskininlärningsmodeller, som bryter mot traditionella tillvägagångssätt.
Genom federerad inlärning skapas möjligheter för en mer kostnadseffektiv maskininlärningsutveckling samtidigt som dataintegriteten respekteras. Den här artikeln ger en grundlig genomgång av vad federerad inlärning innebär, dess funktionssätt, tillämpningar och tillgängliga ramverk.
Vad är Federated Learning?
 Källa: Wikipedia
Källa: Wikipedia
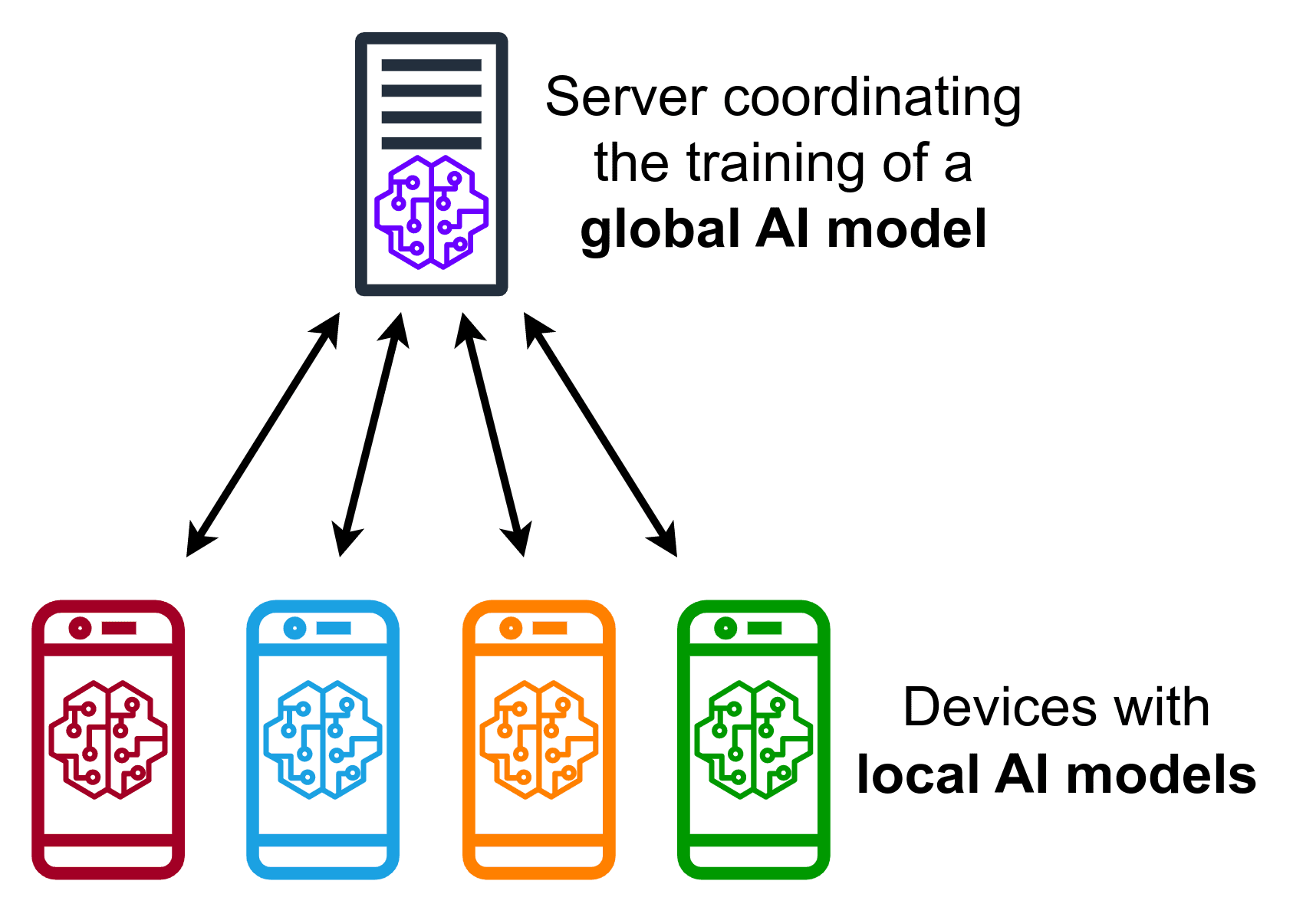
Federerad inlärning utgör en paradigmväxling i hur maskininlärningsmodeller tränas. I traditionell maskininlärning samlas data från olika källor in i ett centralt datalager. Utifrån detta centraliserade datalager tränas maskininlärningsmodeller för att sedan göra prediktioner. Federated Learning fungerar på ett annat sätt. Istället för att centralisera data, tränar klienterna modellerna direkt med sina egna data, vilket garanterar att deras privata information förblir skyddad.
Läs också: En genomgång av de mest framstående maskininlärningsmodellerna
Hur fungerar federerat lärande?
Federerad inlärning bygger på en serie stegvisa processer som tillsammans skapar en modell. Dessa steg benämns inlärningsrundor. En typisk inlärningsprocess itererar genom dessa rundor, vilket kontinuerligt förbättrar modellen. Varje inlärningsrunda omfattar följande nyckelsteg.
En typisk inlärningsrunda
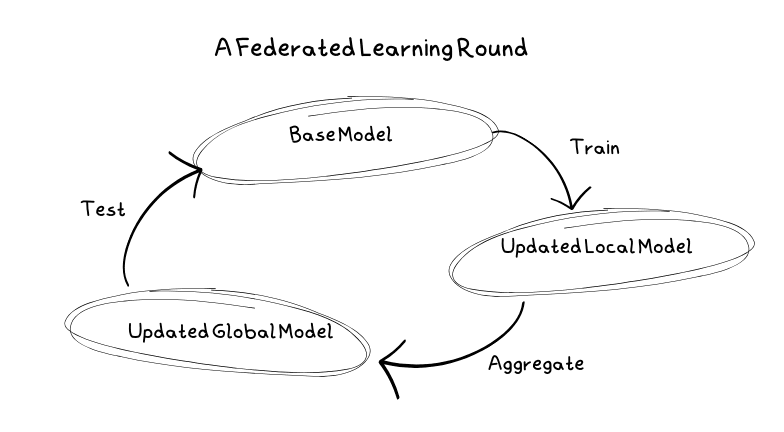
Först väljer servern ut den modell som ska tränas, samt hyperparametrar som antalet rundor, vilka klientnoder som ska användas och hur stor andel av noderna som ska aktiveras i varje runda. Samtidigt initieras modellen med grundläggande parametrar för att etablera en basmodell.
Därefter erhåller klienterna kopior av basmodellen för att påbörja träningen. Dessa klienter kan vara allt från mobila enheter till persondatorer eller servrar. De tränar modellen med sina egna lokala data, vilket förhindrar att känslig data delas med servern.
Efter att klienterna har tränat modellen lokalt, returneras uppdateringarna till servern. Servern sammanställer alla mottagna uppdateringar genom att beräkna ett genomsnitt. Det kan hända att vissa klienter inte skickar in sina uppdateringar, exempelvis på grund av opålitlighet. I dessa fall hanterar servern eventuella fel.
Innan en ny basmodell kan tas i bruk måste den testas. Eftersom servern inte lagrar någon data, skickas den uppdaterade modellen tillbaka till klienterna för testning mot deras lokala data. Om modellen presterar bättre än den tidigare basmodellen, godkänns den och tas i bruk.
Här är en användbar resurs om hur federerad inlärning fungerar, skapad av Federated Learning-teamet på Google AI.
Centraliserad vs. Federerad vs. Heterogen
I ett system som kallas Centralized Federated Learning, finns en central server som styr inlärningsprocessen.
Motsatsen till detta är decentraliserad federerad inlärning, där klienterna interagerar och samordnar sig direkt med varandra, utan en central server.
Ytterligare en variant är Heterogenous Learning, där klienterna inte nödvändigtvis använder samma modellarkitektur.
Fördelar med Federated Learning
- Den främsta fördelen med federerad inlärning är dess förmåga att skydda privat data. Klienter delar inte med sig av själva datan utan endast resultatet av sin träning. Det går också att implementera protokoll för att aggregera resultat så att de inte kan spåras tillbaka till en specifik klient.
- Federerad inlärning minskar även nätverkets bandbredd eftersom ingen rådata överförs mellan klienterna och servern. Istället skickas endast tränade modeller.
- Ytterligare en fördel är de reducerade kostnaderna för träningsmodeller. Det finns inte längre ett behov av dyr träningshårdvara, eftersom utvecklarna istället använder klienternas enheter. Dessutom belastas inte klienternas enheter i någon större utsträckning eftersom datamängderna är små.
Nackdelar med Federated Learning
- Modellens framgång är beroende av att ett stort antal noder deltar. Vissa av dessa noder kontrolleras inte av utvecklaren, vilket gör att deras tillgänglighet inte kan garanteras. Det kan leda till att träningstillfällena blir opålitliga.
- Klienterna som används för att träna modellerna är sällan avancerade grafikkort, utan vanliga enheter som mobiltelefoner. Även tillsammans kan dessa enheter sakna den datorkraft som finns i dedikerade GPU-kluster.
- Federerad inlärning utgår även från antagandet att alla klienter är pålitliga och arbetar för det gemensamma bästa. Det finns dock risk att vissa klienter genererar dåliga uppdateringar som kan orsaka avvikelser i modellens resultat.
Tillämpningar av Federated Learning
Federerad inlärning möjliggör maskininlärning med bibehållen integritet, vilket är värdefullt i många situationer, som till exempel:
- Förutsägelse av nästa ord på tangentbordet i smartphones.
- IoT-enheter som kan träna modeller lokalt anpassade till deras specifika omgivning och behov.
- Läkemedels- och hälsovårdssektorn.
- Försvarsindustrin kan också dra nytta av att träna modeller utan att dela känslig information.
Ramar för federerat lärande
Det finns ett stort antal ramverk för att implementera federerad inlärning. Några av de mest populära är NVFlare, FATE, Flower och PySft. Läs den här guiden för en ingående jämförelse av olika tillgängliga ramverk.
Slutsats
Denna artikel har introducerat federerad inlärning, dess arbetsmekanismer, samt fördelar och nackdelar med att tillämpa det. Vi har även berört några av de populäraste tillämpningsområdena samt ramverk som används för att implementera federerad inlärning i praktiken.
Läs vidare om de bästa MLOps-plattformarna för att träna dina maskininlärningsmodeller.