Datahantering: En Översikt
Datahantering spelar en central roll i en datadriven process. Det säkerställer att organisationer får tillgång till relevant information vid rätt tidpunkt. Detta möjliggör en djupare förståelse av verksamhetens resultat och banar väg för förbättringar.
Dagens organisationer genererar dagligen enorma mängder data som kan vara av betydande värde.
Genom att analysera denna information kan företag få värdefulla insikter som underlättar mer välgrundade och datadrivna beslut.
Denna data är också avgörande för att förstå kundbeteenden, förutse marknadsutvecklingen, planera strategier och identifiera framtida trender.
För att dra nytta av dessa möjligheter är det viktigt att kunna utvinna, analysera och enkelt komma åt datan från en central plats.
Det är här datahantering kommer in i bilden.
Genom att extrahera data från olika källor möjliggörs analys och identifiering av insikter som kan användas för att driva tillväxt.
Den här artikeln utforskar begreppet datahantering, dess olika typer, stegvisa processer, arkitektur, användningsområden, fördelar, bästa praxis och utmaningar.
Låt oss börja!
Vad är Datahantering?
Datahantering är processen att samla in data från en eller flera källor och överföra den till ett datalager för omedelbar användning. Det är en av de viktigaste delarna i arbetsflödet för dataanalys.

Data kan samlas in i omgångar eller strömmas i realtid. När data har flyttats till önskad plats, lagras den korrekt och är redo för analys.
Datakällor kan inkludera datasjöar, databaser, IoT-enheter, SaaS-applikationer, lokala databaser och andra plattformar som kan innehålla relevant information.
Datahantering är en process som innebär att data hämtas från en källa, bearbetas och överförs till en plats där företaget kan använda, komma åt och analysera informationen.
Detta möjliggör för organisationer att fatta välgrundade beslut baserade på den ökande komplexiteten och mängden data som genereras dagligen.
När data samlas in, behåller den sitt ursprungliga och råa format, likt källan. Transformation av data till ett läsbart format kan utföras vid behov för att säkerställa kompatibilitet med olika applikationer.
Huvudsyftet med datahantering är att flytta stora mängder data från en plats till en annan effektivt med hjälp av automatiserad mjukvara. Det fokuserar på datainsamling, inte transformation. Det är ett viktigt verktyg för många organisationer, som hjälper dem att hantera sitt dataflöde.
Det finns olika metoder för att samla in data. Beroende på specifika behov och designkrav kan du välja den metod som passar bäst för dig.
Hur Fungerar Datahantering?
Datahantering samlar in data från de platser där den ursprungligen lagrades eller skapades. Datan laddas eller överförs sedan till en angiven destination. Hanteringsprocessen kan innefatta lättare transformationer för att filtrera eller optimera data innan den skickas till en meddelandekö, ett datalager eller en destination.
Den kan också utföra mer komplexa transformationer, som sortering, sammanslagning och aggregering, anpassade för specifika applikationer, rapporter och analyssystem genom ytterligare pipelines.
För att förstå den stegvisa processen för datahantering är det nödvändigt att titta på dess arkitektur.
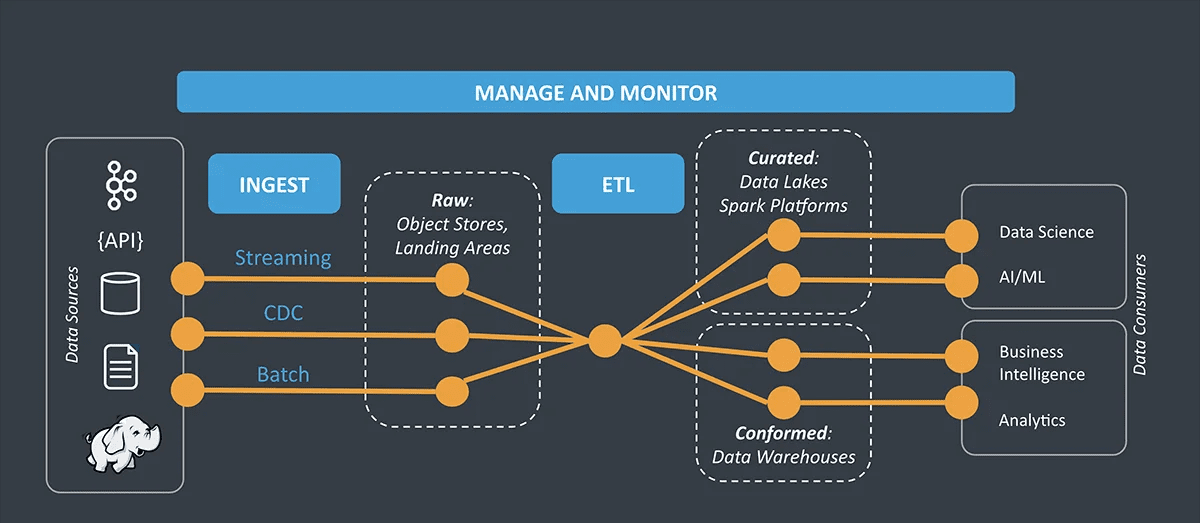 Källa: StreamSets
Källa: StreamSets
Arkitektur för Datahantering
Arkitekturen för datahantering beskriver dataflödet genom följande lager:
- Datainsamlingslager: Detta lager samlar in data från olika källor och lagrar den i ditt datalager. Det definierar hur data överförs eller tolkas för de andra lagren. Det hjälper också till att strukturera datan för analytisk bearbetning.
- Databehandlingslager: Det här lagret tar emot data från föregående lager för att bearbeta överföringen. Det definierar destinationen för datan och grupperar den därefter.
- Datalagringslager: När data har grupperats lagras den på en lämplig plats för vidare användning.
- Datafrågelager: Detta är det analytiska lagret där data kan frågas för att få ut värdefulla insikter.
- Datavisualiseringslager: I detta sista lager presenteras datan i ett begripligt och visuellt format för att underlätta analys.
Fördelar med Datahantering

Här är några av fördelarna med datahantering:
- Tillgänglighet: Med en implementerad datahanteringsprocess blir data lättillgänglig för hela organisationen. Eftersom informationen samlas in från olika källor och överförs till en gemensam plats, kan alla med behörighet enkelt få tillgång till datan för analys.
- Enhetlighet: God datahantering förbättrar datakvaliteten genom att omvandla olika datatyper till en enhetlig form. Det underlättar bearbetning och förståelse av data för framtida analyser.
- Ökad produktivitet: Datahantering möjliggör ökad produktivitet genom effektiv användning av data. Detta gör dataingenjörer mer flexibla och ger dem möjlighet att skala verksamheten.
- Förbättrat beslutsfattande: Genom datahantering får organisationer tillgång till realtidsdata som kan leda till bättre och mer välgrundade beslut. Det möjliggör även analys för att fatta taktiska beslut, spåra KPI:er och identifiera potentiella mål.
- Förbättrad användarupplevelse: Organisationer kan använda aktuell data för att ge sina kunder en bättre upplevelse. Datadriven analys möjliggör utveckling av effektiva verktyg och applikationer för kunder.
Typer av Datahantering
Det finns tre huvudtyper av datahantering: batchbearbetning, realtidsdatahantering och lambda-baserad datahantering. Valet av metod beror till stor del på företagets verksamhet, IT-infrastruktur, budget, tidslinje och mål. Företag väljer modell och verktyg baserat på de datakällor som används.
Låt oss gå in på djupet och undersöka varje typ mer detaljerat.
#1. Batchbearbetning
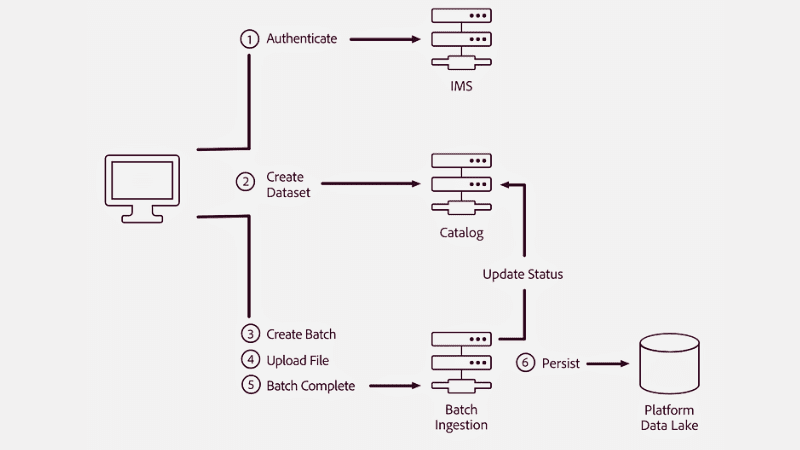 Källa: Adobe Experience League
Källa: Adobe Experience League
Detta är den vanligaste metoden för datahantering. Hanteringslagret samlar och grupperar data från olika källor i steg. Sedan överförs datan i omgångar till en applikation, ett system eller en plats där den behövs.
Överföringen av data baseras på aktivering av politiska förhållanden, triggerhändelser, en analog ordning eller schemaläggning. Batchbearbetning är användbar för organisationer som regelbundet behöver samla in specifik data för aktiviteter som tidrapportering och rapportgenerering.
Denna metod är vanligtvis billigare och anses i många fall vara en äldre strategi.
#2. Realtidsdatahantering
Realtidsdatahantering kallas även för strömbehandling. Det innebär insamling och överföring av data från en källa till en destination i realtid. Det sker ingen gruppering; istället hämtas, laddas och bearbetas datan så snart hanteringslagret hittar ny data.
En vanlig lösning för att implementera realtidsdatahantering är Change Data Structure (CDC). Denna typ av datahantering är dock dyrare än batchhantering. Det beror på att källor måste övervakas kontinuerligt för att upptäcka ny data och säkerställa att den återspeglas korrekt i den angivna plattformen.
Om kostnadsdelen inte är en begränsning är den här metoden mycket användbar för företag som vill köra analyser med färsk data för att fatta operativa beslut.
Realtidsdatahantering är till exempel det bästa alternativet för att fatta beslut om aktiemarknaden. Denna metod är också lämplig för att övervaka infrastruktur.
#3. Lambda-baserad Datahantering
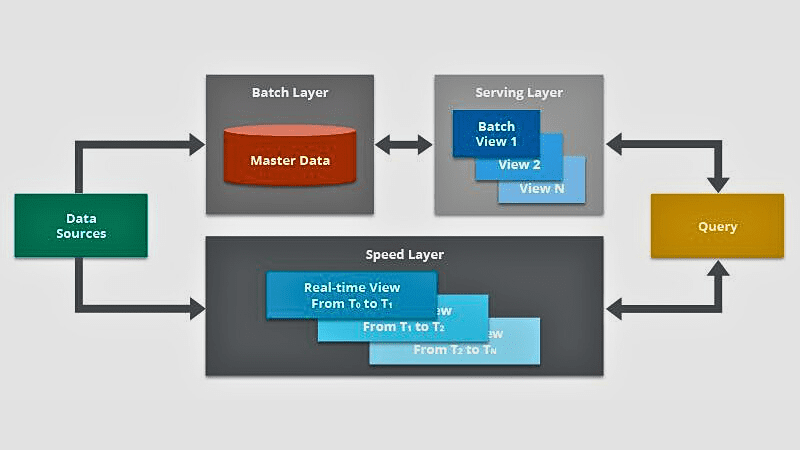 Källa: Hasselcast
Källa: Hasselcast
Denna metod kombinerar batchbearbetning och realtidsdatahantering.
Batchbearbetning används för att samla data i omgångar, medan realtidsdatahantering ger en annan infallsvinkel till tidskänslig information. Lambda-baserad datahantering delar in datan i mindre steg, vilket gör den effektiv för olika applikationer som kräver strömmande data.
Användningsområden för Datahantering
Organisationer över hela världen använder datahanteringsprocesser som en viktig del av datapipelines i sina verksamheter.
- Internet of Things (IoT): Datahantering används i många IoT-system för att samla in och omvandla data från olika anslutna enheter.
- Big Data Analytics: Big data-analys är ett vanligt behov för alla organisationer. Hantering av stora datamängder från många källor är därför nödvändigt för big data-analys, där data bearbetas med distribuerade system som Spark eller Hadoop.
- Bedrägeriupptäckt: Organisationer använder datahanteringsprocessen för att upptäcka bedrägerier genom att importera och omvandla data från olika källor, som kundbeteende, dataflöden från tredje part och transaktioner.
- E-handel: E-handelsföretag använder datahanteringsprocessen för att ta emot data från flera källor, som kundtransaktioner, produktkataloger, webbplatsanalyser och mer. Detta ger dem rätt data i realtid, som underlättar tillväxt.
- Personalisering: Datahanteringsprocessen kan användas för att ge personliga upplevelser eller rekommendationer till användare genom att extrahera data från olika källor, som kundinteraktioner, sociala medier, webbplatsanalys, etc.
- Hantering av försörjningskedjan: För att hantera en försörjningskedja behöver organisationer data från lager, logistik och leverantörer. Datahantering samlar in och bearbetar denna data från flera källor för att underlätta effektiv hantering av försörjningskedjan.
- Sentiment- och sociala medieanalys: Realtidsdatahantering hjälper företag att övervaka sociala medier, identifiera trender och analysera varumärkessentiment genom att samla in data från olika källor. Detta leder till förbättrade kundrelationer, utveckling av marknadsstrategier och effektiva marknadsföringsstrategier.
Utmaningar

Det finns en del utmaningar i datahanteringsprocessen:
- Skalbarhet: Det kan vara svårt att skala en stor datamängd vid hantering av data från flera olika källor. Den mängd data som bearbetas kräver vertikal eller horisontell skalning av infrastrukturen, vilket kan leda till komplikationer.
- Datakvalitet: Datakvaliteten är en stor utmaning vid datahantering. Det går inte alltid att garantera att den data som erhålls har hög kvalitet.
- Olika ekosystem: Det finns många datakällor och typer, vilket kan göra det svårt för team att utveckla en robust hanteringsmodell. Vissa verktyg stöder bara grundläggande teknik, vilket tvingar organisationer att använda flera verktyg som kräver olika färdigheter.
- Kostnad: Hanteringskostnaden är direkt proportionell mot datamängden. När datavärdet växer ökar även de totala hanteringskostnaderna. För att samla in all data behövs fler servrar och lagringssystem, vilket leder till ökade kostnader.
- Säkerhet: Eftersom data lagras på flera platser under hanteringen är den utsatt för säkerhetsrisker. Detta gör processen sårbar, vilket kan leda till säkerhetsbrott. Därför har organisationer svårt att upprätthålla standarder och regler under processen.
- Dataintegration: Det kan vara svårt att integrera data från tredjepartskällor med hanteringsprocessen. Det krävs därför ett verktyg som möjliggör integrering av data.
- Otillförlitlighet: Om data hanteras felaktigt kan det leda till opålitlig anslutning. Detta resulterar i avbrott i kommunikationen och förlust av data.
Bästa Praxis
Låt oss diskutera några metoder för dataintegration som kan förbättra företagets resultat.
Automatiserad Datahantering
Automatiserad datahantering kan lösa många utmaningar som uppstår med manuell hantering. Det underlättar omvandling av rådata till användbar information, särskilt när data kommer från olika källor.
Organisationer kan använda verktyg för datahantering för att automatisera återkommande processer för datainsamling. Detta underlättar bättre analyser och rapportering samtidigt som risken för mänskliga fel minskar.
Skapa Data-SLA
Data-SLA (Service Level Agreement) kräver:
- Vilket affärsbehov som ska tillgodoses
- Vilka förväntningar ett företag har på datan
- När data kan leva upp till förväntningarna
- Vem som drabbas om SLA inte uppfylls
- Hur man vet när SLA uppfylls och vad som händer om det inte gör det
Datahanteringsmetoden ger därmed tillgång till all nödvändig data för att effektivt skapa data-SLA.
Nätverksbandbredd
Datahanteringsprocessen kan utformas för att hantera nätverksbandbredd effektivt.
Trafiken är inte alltid konstant; den kan öka eller minska beroende på sociala och fysiska parametrar. Nätverkets bandbredd beror också på mängden data som ska hanteras vid en viss tidpunkt.
Heterogena System och Teknologier

En organisation måste kontrollera om datahanteringsprocessen är kompatibel med tredjepartsverktyg, applikationer och olika operativsystem.
Stöd för Opålitlig Data
Datahanteringsprocessen tar emot data från olika källor och format, som ljudfiler, loggfiler, bilder och mycket mer.
Olika format kräver olika hastigheter, vilket innebär att ett opålitligt nätverk kan göra hela processen opålitlig. Organisationer måste utforma en datahanteringsprocess som stöder alla format utan att vara otillförlitlig.
Hög Precision
Datahanteringen är direkt proportionell mot granskningsbar data. Den kräver en väl utformad process som kan anpassa sig till kraven.
Strömmande Data
Företag behöver datahanteringsprocesser i realtid och batchbearbetning för att förbättra sina tjänster och maximera effektiviteten.
Frikoppling av Databaser

Vissa organisationer, särskilt stora, integrerar sin analysdatabas direkt med den operativa databasen. Genom att frikoppla de analytiska och operativa databaserna kan organisationer lösa potentiella problem.
Slutsats
Datahantering ger omedelbara insikter som kan hjälpa till att förstå aktuella marknadstrender, bibehålla låg latens och utvärdera kundupplevelser. Datahanteringsprocessen består av olika lager, från datainsamling till visualisering och analys.
Med datahantering kan organisationer enkelt förbättra effektiviteten, utföra snabbare bedrägeriupptäckter, få realtidsanalyser och initiera proaktivt underhåll. Företag kan även använda datahantering i realtid för att få tillgång till aktuell information, vilket ger dem en konkurrensfördel och underlättar välgrundade beslut.
Du kan även läsa mer om dataorkestrering.