Modern datahantering: Datasjöar kontra Datalager
I dagens affärsvärld kretsar mycket kring data. Företag söker ständigt efter effektiva metoder för att utvinna och analysera information från en mängd olika källor, med målet att öka intäkter och vinster. En avgörande fråga är var man säkrast lagrar och integrerar denna mångfaldiga data för att maximera dess potential.
Datasjöar och datalager är två populära alternativ för hantering av stora datamängder. De skiljer sig dock åt i hur data samlas in, lagras och används. Låt oss utforska dessa skillnader närmare.
Vad utmärker en Datasjö?
En datasjö fungerar som en centraliserad lagringsplats där data från flera källor, i olika format (strukturerad eller ostrukturerad), lagras i sitt ursprungliga skick. Det liknar en behållare med rådata, vars potentiella användning ännu inte är helt definierad. Företag lagrar här data som kan vara användbar för framtida analyser.
Viktiga egenskaper hos en datasjö:
- Den innehåller en blandning av användbar och mindre relevant data, vilket kräver betydande lagringsutrymme.
- Den lagrar både realtidsdata och batchdata, t.ex. data från IoT-enheter, sociala medier eller molnapplikationer, samt data från traditionella databaser.
- Den har en platt arkitektur utan fördefinierad struktur.
- Eftersom data inte bearbetas omedelbart krävs noggrann styrning och underhåll för att undvika att den förvandlas till ett ”dataträsk”.
Hur hämtar man då snabbt data från ett sådant omfattande och potentiellt oorganiserat lager? Datasjöar använder metadata-taggar och identifierare för detta ändamål.
Vad kännetecknar ett Datalager?
Ett datalager är ett mer strukturerat och organiserat arkiv med data som är redo för analys. Data från olika källor, strukturerad, semistrukturerad eller ostrukturerad, samlas in, integreras, rensas, sorteras, omvandlas och anpassas för att kunna användas effektivt.
Ett datalager innehåller stora mängder historisk och aktuell data, ofta bearbetad för att lösa ett specifikt affärsproblem. Denna information är värdefull för Business Intelligence-system (BI) i syfte att analysera, rapportera och generera insikter.
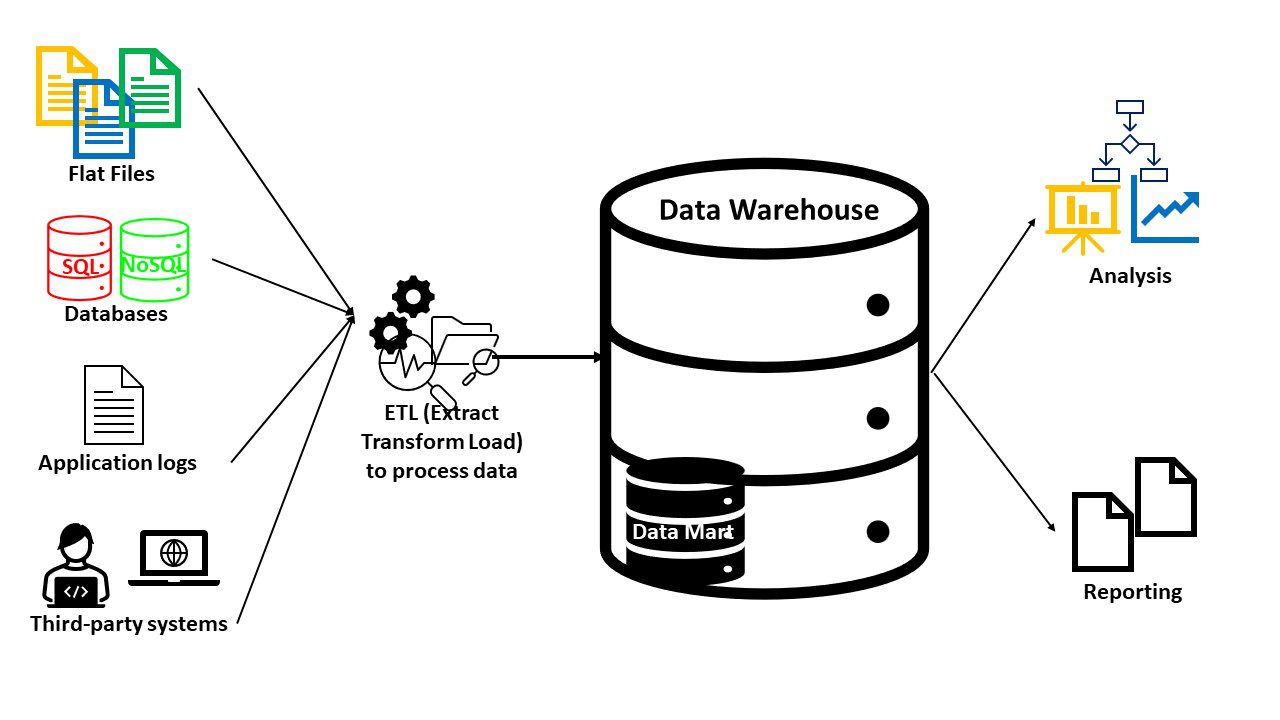
Ett datalager består vanligtvis av:
- En databas (SQL eller NoSQL) för att lagra och hantera data.
- Verktyg för datatransformation och analys.
- BI-verktyg för datautvinning, statistisk analys, rapportering och visualisering.
Eftersom datalager har ett tydligt syfte innehåller de relevant data för specifika användningsområden. Avancerade verktyg kan även läggas till för funktioner som artificiell intelligens och rumslig analys. Datalager som skapats för specifika områden kallas ibland för ”datamarts”.
Viktiga Skillnader mellan Datasjöar och Datalager
Sammanfattningsvis innehåller en datasjö rådata utan ett definierat syfte, medan ett datalager innehåller data som är förberedd för analys i sin mest optimala form.
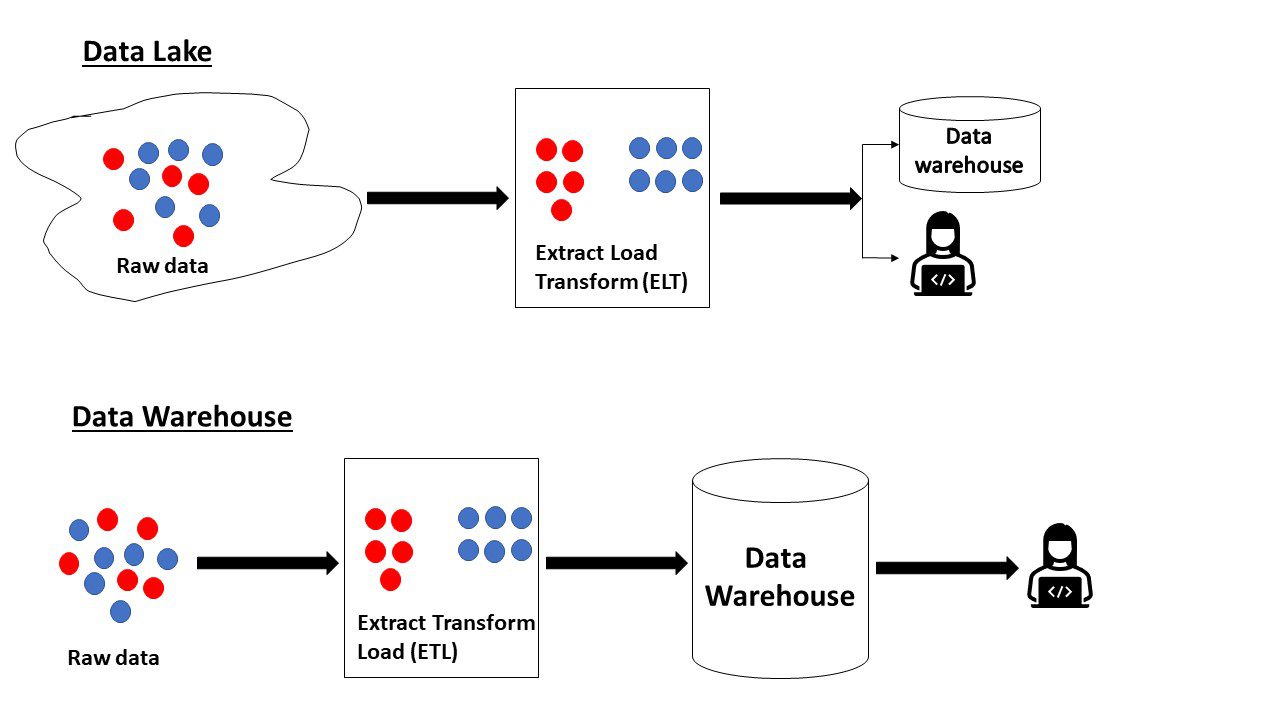 Datasjö vs. Datalager
Datasjö vs. Datalager
Här följer en tabell som sammanfattar viktiga skillnader:
| Datasjö | Datalager | |
| Datatyp | Rådata i olika format från flera källor. | Strukturerad data för analys och rapportering. |
| Schemaläggning | Schema skapas vid läsning (schema-on-read). | Schema definieras vid skrivning (schema-on-write). |
| Datatillägg | Ny data kan läggas till enkelt. | Ändringar i data kräver mer tid och ansträngning. |
| Underhåll | Kräver uppdatering och styrning för relevans. | Kräver inte specifikt underhåll, är redo för användning. |
| Datavolym | Hanterar stora volymer data (petabyte). | Vanligtvis mindre volymer än en datasjö (terabyte). |
| Användningsområden | Används av dataforskare för avancerad analys, AI, prediktioner m.m. | Används av analytiker för transaktionsbearbetning, rapportering och visualisering. |
| Datalagringstid | Data kan lagras under lång tid för framtida analyser. | Data rensas regelbundet för att hålla sig relevant. |
| Kostnad | Låg kostnad för lagring, men bearbetning kan vara dyrt. | Lagring och bearbetning är mer kostsamt, kräver noggrann planering. |
| Databas | Kan använda både relations- och icke-relationsdatabaser. | Använder vanligtvis relationsdatabaser. |
Användningsområden för Datasjöar och Datalager
Datasjöar kan verka som ett mer flexibelt och kostnadseffektivt alternativ, men datalager är idealiskt när man behöver mer strukturerad data för specifik analys.
Exempel på användningsområden för datasjöar:
#1. Supply Chain och Logistik
Stora datamängder i datasjöar möjliggör prediktiv analys för transport och logistik. Företag kan planera sin verksamhet, spåra lager i realtid och optimera kostnader.
#2. Hälso- och Sjukvård
Datasjöar innehåller all tidigare och aktuell information om patienter. Det är värdefullt för forskning, identifiering av mönster, förbättrad behandling och automatiserad diagnostik.
#3. Strömmande Data och IoT
Datasjöar kan kontinuerligt ta emot realtidsdata för analys, rapportering och upptäckt av avvikande aktiviteter.
Exempel på användningsområden för datalager:
#1. Finans
Ett företags finansiella data är väl lämpad för ett datalager. Anställda kan få tillgång till organiserad information för att hantera ekonomi, risker och strategiska beslut.
#2. Marknadsföring och Kundsegmentering
Datalager skapar en pålitlig källa för kunddata. Företag kan analysera detta för att förstå kundbeteende, anpassa erbjudanden och segmentera kunder.
#3. Företagsrapporter och Dashboards
Många företag använder datalager för att hämta data om kunder, både externa och interna. Uppgifterna är alltid relevanta och tillförlitliga för att skapa rapporter och visualiseringar.
#4. Migrering av Data från Äldre System
Med hjälp av ETL-funktioner i datalager kan företag omvandla data från äldre system till ett användbart format. Det gör det möjligt att analysera historiska trender och fatta korrekta affärsbeslut.
Exempel på Verktyg för Datasjöar
Några ledande leverantörer av datasjölösningar:
- Microsoft Azure – Erbjuder lagring och analys av stora datamängder och enkel optimering.
- Google Cloud – Kostnadseffektiv hantering av enorma datamängder och integration med analysverktyg.
- MongoDB Atlas – En fullt hanterad datasjö med kostnadseffektiva metoder för datalagring.
- Amazon S3 – AWS-molnet erbjuder verktyg för att bygga en flexibel, säker och kostnadseffektiv datasjö.
Exempel på Verktyg för Datalager
Några av de främsta leverantörerna av datalagerlösningar:
- SAV – Ger användare tillgång till data från flera källor och delning av insikter för snabbare beslut.
- ClicData – Säkerställer dataintegritet och tillhandahåller realtids-API:er för uppdaterad data.
- Amazon Redshift – Ett populärt datalager som använder SQL för att analysera data från olika källor.
- IBM Db2 lager – Erbjuder inhouse- och molnlösningar med integration av AI för analys.
- Oracle Cloud Data Warehouse – Använder en minnesbaserad databas och ger möjlighet till grafisk analys och maskininlärning.
Avslutande Tankar
Både datasjöar och datalager har sina egna fördelar och idealiska användningsområden. Datasjöar är skalbara och flexibla, medan datalager erbjuder tillförlitlig och strukturerad information. Datalager är ett väletablerat koncept, medan datasjöar är en mer modern lösning som snabbt vinner popularitet.