
Datalager. Datasjö. Sjöhus. Om inget av dessa ord resonerar hos dig åtminstone lite, så är ditt jobb helt klart inte relaterat till data.
Det skulle dock vara en ganska orealistisk utgångspunkt eftersom allt är relaterat till data idag verkar som. Eller hur företagsledarna vill beskriva det:
- Datacentrerad och datadriven verksamhet.
- Data var som helst, när som helst, hur som helst.
Innehållsförteckning
Den viktigaste tillgången
Det verkar som om data har blivit den mest värdefulla tillgången för fler och fler företag. Jag minns att stora företag alltid genererade mycket data, tänk terabyte med ny data varje månad. Det var fortfarande 10-15 år sedan. Men nu kan du enkelt generera den mängden data inom några dagar. Man skulle fråga om det verkligen är nödvändigt, även om det är något innehåll som någon kommer att använda. Och ja, det är det definitivt inte 😃.
Allt innehåll kommer inte att vara till någon nytta, och vissa delar inte ens en enda gång. Ofta bevittnade jag i frontlinjen hur företag genererade en enorm mängd data för att sedan bli värdelösa efter en lyckad laddning.
Men det är inte aktuellt längre. Datalagring – som nu finns i molnet – är billig, datakällorna växer exponentiellt och idag kan ingen förutsäga vad de kommer att behöva ett år senare när nya tjänster är inbyggda i systemet. Vid den tidpunkten kan även den gamla informationen bli värdefull.
Därför är strategin att lagra så mycket data som möjligt. Men också i så effektiv form som möjligt. Så att data inte bara kan sparas effektivt utan också kan sökas, återanvändas eller transformeras och distribueras vidare.
Låt oss ta en titt på tre inbyggda sätt hur man kan åstadkomma detta i AWS:
- Athena Database – billigt och effektivt, men enkelt sätt att skapa en datasjö i molnet.
- Redshift Database – en seriös molnversion av ett datalager som har potential att ersätta majoriteten av de nuvarande lokala lösningarna, utan att kunna komma ikapp den exponentiella tillväxten av data.
- Databricks – en kombination av en datasjö och datalager till en enda lösning, med lite bonus utöver det hela.
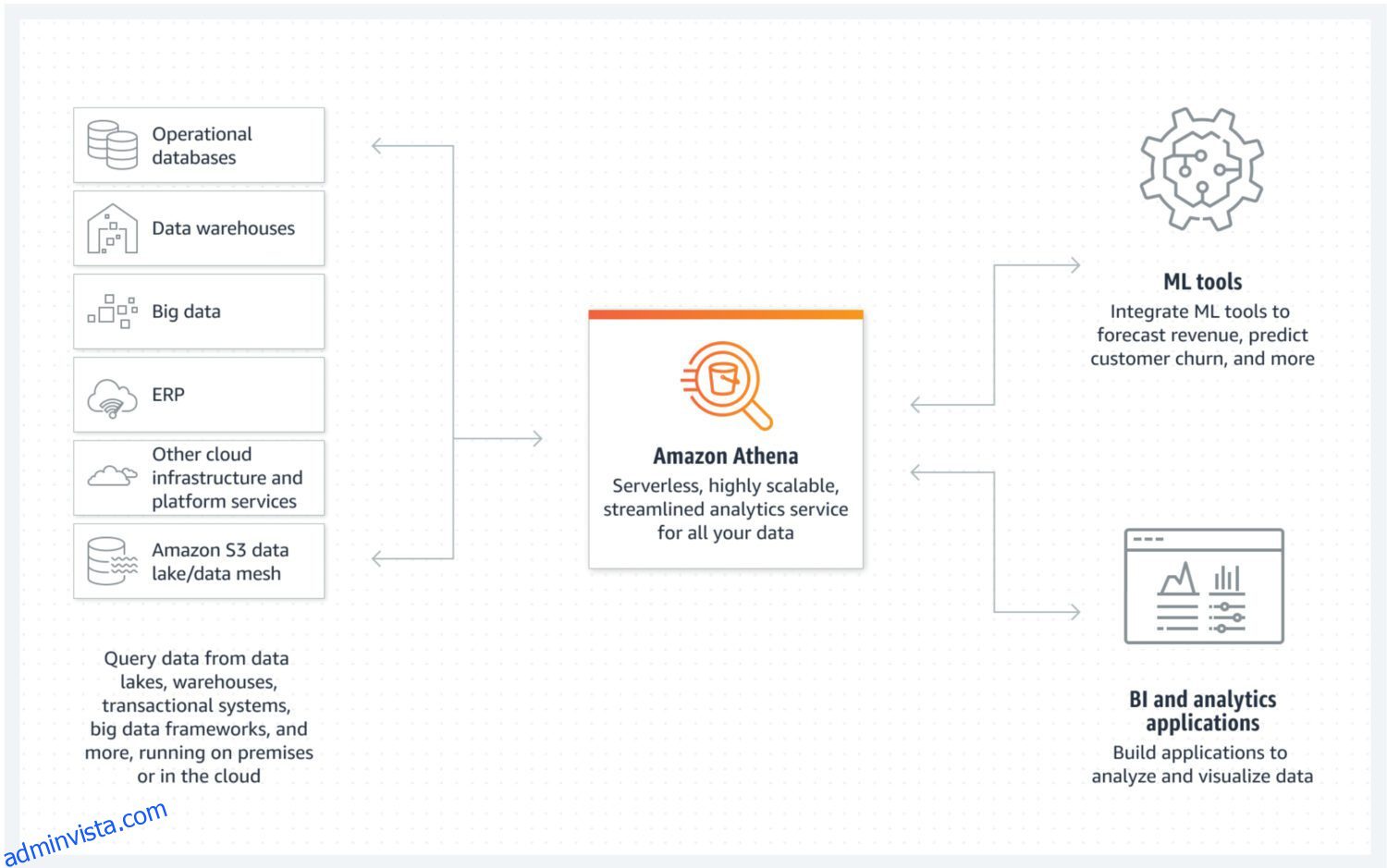
Data Lake av AWS Athena
 Källa: aws.amazon.com
Källa: aws.amazon.com
Datasjön är en plats där du kan lagra inkommande data i ostrukturerad, semistrukturerad eller strukturerad form på ett snabbt sätt. Samtidigt förväntar du dig inte att dessa data ändras när de väl har lagrats. Istället vill du att de ska vara så atomära och oföränderliga som möjligt. Endast detta kommer att säkerställa den största potentialen för återanvändning i senare skeden. Om du skulle förlora den här atomegenskapen hos datan direkt efter den första laddningen i en datasjö, finns det inget sätt att få tillbaka denna förlorade information igen.
AWS Athena är en databas med lagring direkt på S3-buckets och utan serverkluster som körs i bakgrunden. Det betyder att det är en riktigt billig datasjötjänst. Strukturerade filformat som parkett eller CSV-filer (comma-separated value) upprätthåller dataorganisationen. S3-hinken innehåller filerna och Athena hänvisar till dem när processer väljer data från databasen.
Athena stöder inte olika funktioner som annars anses vara standard, såsom uppdateringssatser. Det är därför du måste se Athena som ett mycket enkelt alternativ. Å andra sidan hjälper det dig att förhindra modifiering av din atomära datasjö helt enkelt för att du inte kan 😐.
Den stöder indexering och partitionering, vilket gör den användbar för effektiv exekvering av urvalssatser och skapa logiskt separata databitar (till exempel separerade med datum eller nyckelkolumner). Det kan också skalas horisontellt mycket enkelt, eftersom detta är lika komplicerat som att lägga till nya skopor till infrastrukturen.

För-och nackdelar
Fördelarna att överväga:
- Det faktum att Athena är billigt (som endast består av S3-hinkar och SQL-användningskostnader per användning) ger den största fördelen. Om du vill bygga en prisvärd datasjö i AWS så är det här.
- Som en inbyggd tjänst kan Athena enkelt integrera med andra användbara AWS-tjänster som Amazon QuickSight för datavisualisering eller AWS Glue Data Catalog för att skapa beständig strukturerad metadata.
- Bäst för att köra ad hoc-frågor över en stor mängd strukturerad eller ostrukturerad data utan att underhålla en hel infrastruktur runt den.
Nackdelarna att tänka på:
- Athena är inte särskilt effektiv när det gäller att returnera komplexa urvalsfrågor snabbt, särskilt om frågorna inte följer datamodellens antaganden om hur du designade att begära data från datasjön.
- Detta gör det också mindre flexibelt med hänsyn till eventuella framtida förändringar i datamodellen.
- Athena stöder inte några ytterligare avancerade funktioner direkt, och om du vill att något specifikt ska ingå i tjänsten måste du implementera det ovanpå.
- Om du förväntar dig dataanvändningen av datasjön i något mer avancerat presentationslager, är ofta det enda valet att kombinera det med en annan databastjänst som är mer lämpad för det ändamålet, som AWS Aurora eller AWS Dynamo DB.
Syfte och verklig användningsfall
Välj Athena om målet är att skapa en enkel datasjö utan några avancerade datalagerliknande funktioner. Så, till exempel, om du inte förväntar dig seriösa högpresterande analysfrågor som körs regelbundet över datasjön. Istället är det prioritet att ha en pool av oföränderlig data med enkel förlängning av datalagring.
Du behöver inte längre oroa dig för mycket över bristen på utrymme. Även kostnaden för S3-hinklagring kan minskas ytterligare genom att implementera en datalivscykelpolicy. Detta innebär i grunden att data flyttas över olika typer av S3-hinkar, mer riktade mot arkivändamål med långsammare returtider för intag men lägre kostnader.
En stor egenskap hos Athena är att den automatiskt skapar en fil som består av data som är en del av ett resultat av din SQL-fråga. Du kan sedan ta den här filen och använda den för alla ändamål. Så det är ett bra alternativ om du har många lambdatjänster som vidarebearbetar data i flera steg. Varje lambda-utfall blir automatiskt resultatet i ett strukturerat filformat som indata redo för efterföljande bearbetning.
Athena är ett bra alternativ i situationer när en stor mängd rådata kommer till din molninfrastruktur och du inte behöver bearbeta det vid laddningstillfället. Det betyder att allt du behöver är snabb lagring i molnet i lättförståelig struktur.
Ett annat användningsfall skulle vara att skapa ett dedikerat utrymme för dataarkiveringsändamål för en annan tjänst. I ett sådant fall skulle Athena DB bli en billig säkerhetskopieringsplats för all data du inte behöver just nu, men det kan komma att förändras i framtiden. Vid denna tidpunkt kommer du bara att mata in data och skicka den vidare.
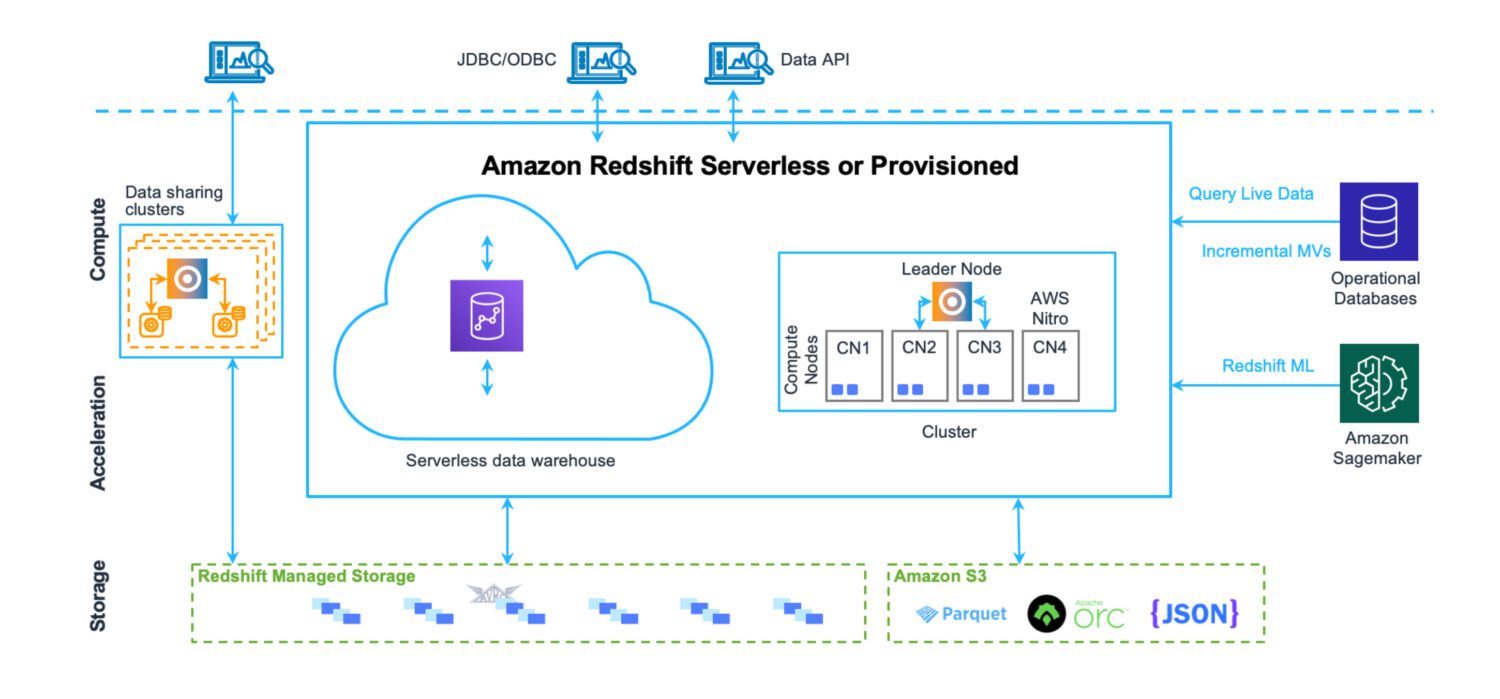
Data Warehouse av AWS Redshift
 Källa: aws.amazon.com
Källa: aws.amazon.com
Ett datalager är en plats där data lagras på ett mycket strukturerat sätt. Lätt att ladda och ta ut. Avsikten är att köra ett stort antal mycket komplexa frågor, förena många tabeller via komplexa kopplingar. Olika analytiska funktioner finns på plats för att beräkna olika statistik över befintlig data. Det slutliga målet är att extrahera framtida förutsägelser och fakta som kan utnyttjas i verksamheten framöver, med hjälp av befintlig data.
Redshift är ett fullfjädrat datalagersystem. Med klusterservrar för att ställa in och skala – horisontellt och vertikalt och ett databaslagringssystem optimerat för snabba komplicerade frågor. Fast idag kan du köra Redshift i serverlöst läge också. Det finns inga filer på S3 eller något liknande. Detta är en standarddatabasklusterserver med sitt eget lagringsformat.
Den har prestandaövervakningsverktyg på plats ur lådan, tillsammans med anpassningsbara instrumentpanelsmått som du kan använda och titta på för att finjustera prestandan för ditt användningsfall. Administrationen är också tillgänglig via separata instrumentpaneler. Det tar lite ansträngning att förstå alla möjliga funktioner och inställningar och hur de påverkar klustret. Men ändå är det ingenstans så komplext som administrationen av Oracle-servrar brukade vara när det gäller de lokala lösningarna.
Även om det finns olika AWS-gränser i Redshift som sätter vissa gränser för hur det ska användas dagligen (till exempel hårda gränser för antalet samtidiga aktiva användare eller sessioner i ett databaskluster), är det faktum att operationer är körs riktigt snabbt hjälper till att komma runt dessa gränser i viss utsträckning.

För-och nackdelar
Fördelarna att överväga:
- Native AWS molndatalagertjänst som är lätt att integrera med andra tjänster.
- En central plats för lagring, övervakning och intag av olika typer av datakällor från väldigt olika källsystem.
- Om du någonsin velat ha ett serverlöst datalager utan infrastruktur för att underhålla det, nu kan du det.
- Optimerad för högpresterande analys och rapportering. Till skillnad från en datasjölösning finns det en stark relationsdatamodell för att lagra all inkommande data.
- Redshift databasmotor har sitt ursprung i PostgreSQL, vilket säkerställer hög kompatibilitet med andra databassystem.
- Mycket användbara COPY- och UNLOAD-satser för att ladda och ta bort data från och till S3-hinkar.
Nackdelarna att tänka på:
- Redshift stöder inte en stor mängd samtidiga aktiva sessioner. Sessionerna kommer att ställas på is och bearbetas sekventiellt. Även om det kanske inte är ett problem i de flesta fall, eftersom operationerna är riktigt snabba, är det en begränsande faktor i system med många aktiva användare.
- Även om Redshift stöder många funktioner som tidigare känts från mogna Oracle-system, är det fortfarande inte på samma nivå. Vissa av de förväntade funktionerna kanske inte finns där (som DB-utlösare). Eller Redshift stöder dem i ganska begränsad form (som materialiserade vyer).
- Närhelst du behöver ett mer avancerat anpassat databearbetningsjobb måste du skapa det från grunden. För det mesta använder du Python eller Javascript-kodspråk. Det är inte lika naturligt som PL/SQL i fallet med Oracle-systemet, där även funktionen och procedurerna använder ett språk som mycket liknar SQL-frågor.
Syfte och verklig användningsfall
Redshift kan vara ditt centrallager för alla olika datakällor som tidigare levde utanför molnet. Det är en giltig ersättning för tidigare Oracles datalagerlösningar. Eftersom det också är en relationsdatabas är migreringen från Oracle till och med en ganska enkel operation.
Om du har några befintliga datalagerlösningar på många ställen som inte är riktigt enhetliga när det gäller tillvägagångssätt, struktur eller en fördefinierad uppsättning gemensamma processer att köra ovanför data, är Redshift ett utmärkt val.
Det ger dig bara en möjlighet att slå samman alla olika datalagersystem från olika platser och länder under ett tak. Du kan fortfarande separera dem per land så att uppgifterna förblir säkra och tillgängliga endast för dem som behöver dem. Men samtidigt kommer det att tillåta dig att bygga en enhetlig lagerlösning som täcker all företagsdata.
Ett annat fall kan vara om målet är att bygga en datalagerplattform med omfattande stöd av självbetjäning. Du kan förstå det som en uppsättning bearbetning som enskilda systemanvändare kan bygga. Men samtidigt är de aldrig en del av den gemensamma plattformslösningen. Det betyder att sådana tjänster förblir tillgängliga endast för skaparen eller gruppen av personer som definieras av den skapade. De kommer inte att påverka resten av användarna på något sätt.
Kolla vår jämförelse mellan Datalake och Datawarehouse.
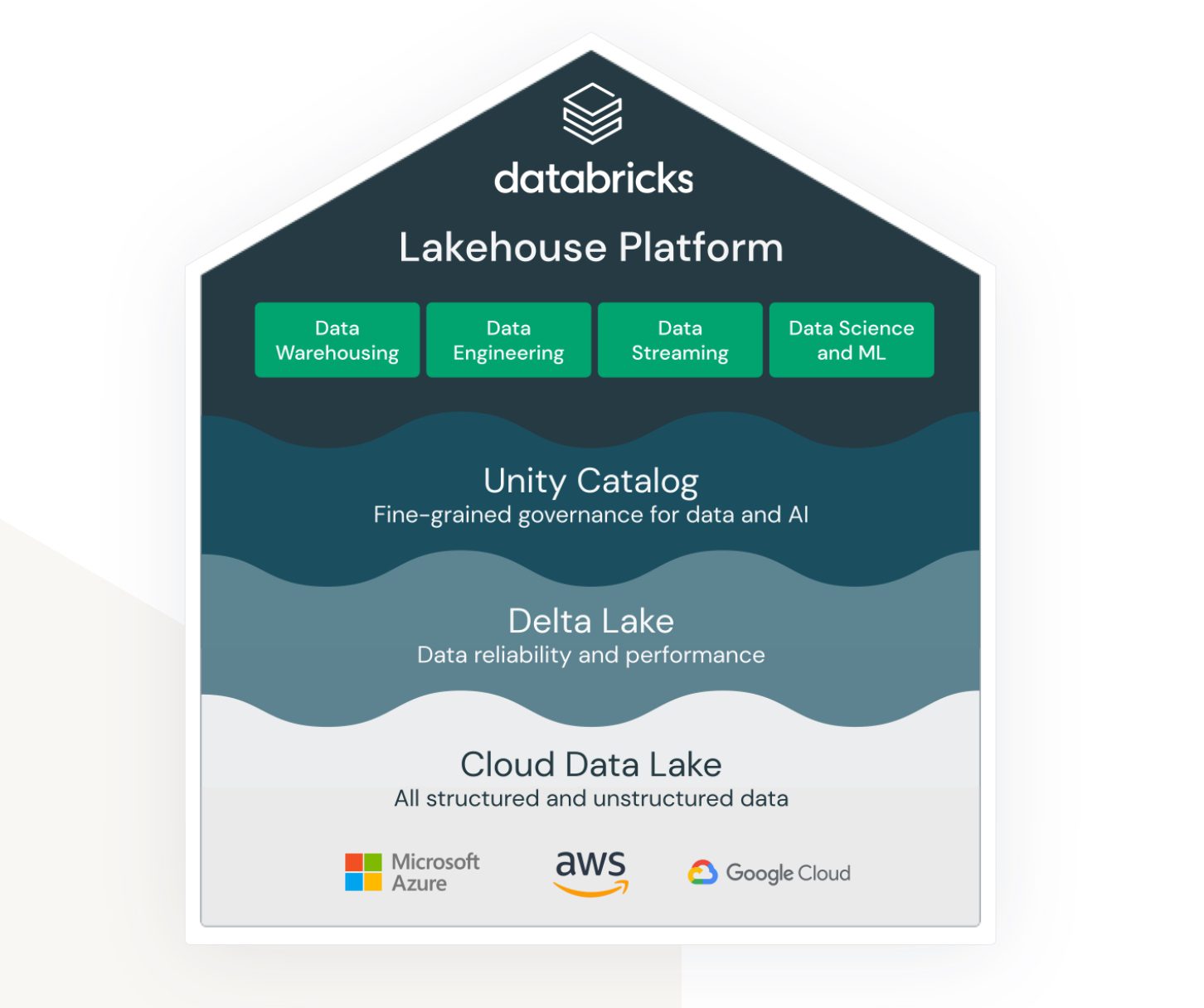
Lakehouse av Databricks på AWS
 Källa: databricks.com
Källa: databricks.com
Lakehouse är en term som verkligen är bunden till Databricks-tjänsten. Även om det inte är en inbyggd AWS-tjänst, lever och fungerar den inom AWS-ekosystemet väldigt bra och ger olika alternativ för hur man kan ansluta och integrera med andra AWS-tjänster.
Databricks syftar till att koppla samman (tidigare) mycket distinkta områden:
- En lösning för datasjölagring av ostrukturerad, semistrukturerad och strukturerad data.
- En lösning för datalagerstrukturerad och snabbt åtkomlig frågedata (även kallad Delta Lake).
- En lösning som stöder analys och maskininlärning över datasjön.
- Datastyrning för alla områden ovan med centraliserad administration och out-of-the-box verktyg för att stödja produktiviteten för olika typer av utvecklare och användare.
Det är en vanlig plattform som dataingenjörer, SQL-utvecklare och dataforskare för maskininlärning kan använda samtidigt. Var och en av grupperna har också en uppsättning verktyg som de kan använda för att utföra sina uppgifter.
Så Databricks siktar på en jack-of-all-trades-lösning, och försöker kombinera fördelarna med datasjön och datalagret till en enda lösning. Utöver det ger den verktygen för att testa och köra maskininlärningsmodeller direkt över redan byggda datalager.

För-och nackdelar
Fördelarna att överväga:
- Databricks är en mycket skalbar dataplattform. Den skalas beroende på arbetsbelastningens storlek, och den gör det till och med automatiskt.
- Det är en samarbetsmiljö för datavetare, dataingenjörer och affärsanalytiker. Att ha möjligheten att göra allt detta i samma utrymme och tillsammans är en stor fördel. Inte bara ur ett organisatoriskt perspektiv, utan det hjälper också till att spara en annan kostnad som annars behövs för separata miljöer.
- AWS Databricks integreras sömlöst med andra AWS-tjänster, som Amazon S3, Amazon Redshift och Amazon EMR. Detta tillåter användare att enkelt överföra data mellan tjänster och dra nytta av hela utbudet av AWS molntjänster.
Nackdelarna att tänka på:
- Databricks kan vara komplicerade att konfigurera och hantera, särskilt för användare som är nya inom big data-behandling. Det kräver en betydande nivå av teknisk expertis för att få ut det mesta av plattformen.
- Även om Databricks är kostnadseffektivt när det gäller sin prissättningsmodell, kan det fortfarande vara dyrt för storskaliga databearbetningsprojekt. Kostnaden för att använda plattformen kan snabbt öka, särskilt om användare behöver skala upp sina resurser.
- Databricks tillhandahåller en rad förbyggda verktyg och mallar, men detta kan också vara en begränsning för användare som behöver fler anpassningsalternativ. Plattformen kanske inte är lämplig för användare som kräver mer flexibilitet och kontroll över sina arbetsflöden för big data-bearbetning.
Syfte och verklig användningsfall
AWS Databricks lämpar sig bäst för stora företag med en mycket stor mängd data. Här kan det täcka kravet att ladda och kontextualisera olika datakällor från olika externa system.
Ofta är kravet att tillhandahålla data i realtid. Detta innebär att från det att data dyker upp i källsystemet ska processerna hämtas omedelbart och bearbeta och lagra data i Databricks omedelbart eller med bara minimal fördröjning. Om fördröjningen är något över en minut anses det vara nära realtidsbearbetning. I vilket fall som helst är båda scenarierna ofta möjliga med Databricks-plattformen. Detta beror främst på den omfattande mängden adaptrar och realtidsgränssnitt som ansluter till olika andra inbyggda AWS-tjänster.
Databricks kan också enkelt integreras med Informatica ETL-system. Närhelst organisationssystemet redan använder Informaticas ekosystem i stor utsträckning, ser Databricks ut som ett bra kompatibelt tillägg till plattformen.
Slutord
Eftersom datavolymen fortsätter att växa exponentiellt är det bra att veta att det finns lösningar som kan hantera det effektivt. Det som en gång var en mardröm att administrera och underhålla kräver nu väldigt lite administrationsarbete. Teamet kan fokusera på att skapa värde ur datan.
Beroende på dina behov, välj bara den tjänst som kan hantera det. Medan AWS Databricks är något som du förmodligen kommer att behöva hålla fast vid efter att beslutet är taget, är de andra alternativen ganska mer flexibla, även om de är mindre kapabla, särskilt deras serverlösa lägen. Det är ganska lätt att migrera till en annan lösning senare.