
Om du är ny på big data-analys kan mängden apache-verktyg finnas på din radar; Men de olika verktygen kan bli förvirrande och ibland överväldigande.
Det här inlägget kommer att lösa denna förvirring och förklara vad Apache Hive och Impala är och vad som skiljer dem från varandra!
Innehållsförteckning
Apache Hive
Apache Hive är ett SQL-dataåtkomstgränssnitt för Apache Hadoop-plattformen. Hive låter dig fråga, aggregera och analysera data med hjälp av SQL-syntax.
Ett läsåtkomstschema används för data i HDFS-filsystemet, vilket gör att du kan behandla data som med en vanlig tabell eller relations-DBMS. HiveQL-frågor översätts till Java-kod för MapReduce-jobb.
Hive-frågor skrivs i frågespråket HiveQL, som är baserat på SQL-språket men inte har fullt stöd för SQL-92-standarden.
Men detta språk tillåter programmerare att använda sina frågor när det är obekvämt eller ineffektivt att använda HiveQL-funktioner. HiveQL kan utökas med användardefinierade skalära funktioner (UDF), aggregering (UDAF-koder) och tabellfunktioner (UDTF).
Hur fungerar Apache Hive
Apache Hive översätter program skrivna på HiveQL-språk (nära SQL) till en eller flera MapReduce-, Apache Tez- eller Apache Spark-uppgifter. Det här är tre exekveringsmotorer som kan lanseras på Hadoop. Sedan organiserar Apache Hive data i en array för Hadoop Distributed File System-filen (HDFS) för att köra jobben på ett kluster för att producera ett svar.
Apache Hive-tabeller liknar relationsdatabaser, och dataenheter är organiserade från den mest betydande enheten till den mest detaljerade. Databaser är arrayer som består av partitioner, som återigen kan delas upp i ”hinkar”.
Datan är tillgänglig via HiveQL. Inom varje databas är data numrerad och varje tabell motsvarar en HDFS-katalog.
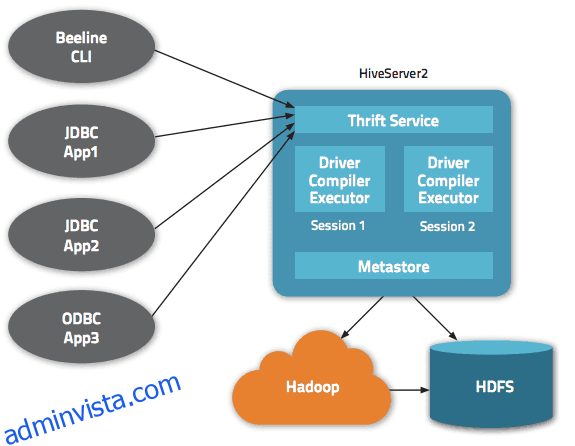
Flera gränssnitt är tillgängliga inom Apache Hive-arkitekturen, såsom webbgränssnitt, CLI eller externa klienter.
Faktum är att ”Apache Hive Thrift”-servern tillåter fjärrklienter att skicka kommandon och förfrågningar till Apache Hive med hjälp av olika programmeringsspråk. Apache Hives centrala katalog är en ”metastore” som innehåller all information.
Motorn som får Hive att fungera kallas ”föraren”. Den kombinerar en kompilator och en optimerare för att bestämma den optimala exekveringsplanen.
Slutligen tillhandahålls säkerhet av Hadoop. Den förlitar sig därför på Kerberos för ömsesidig autentisering mellan klienten och servern. Behörigheten för nyskapade filer i Apache Hive dikteras av HDFS, vilket tillåter användare, grupp eller annan auktorisering.
Funktioner i Hive
- Stöder datormotorn för både Hadoop och Spark
- Använder HDFS och fungerar som datalager.
- Använder MapReduce och stöder ETL
- På grund av HDFS har den feltolerans liknande Hadoop
Apache Hive: Fördelar
Apache Hive är en idealisk lösning för frågor och dataanalys. Det gör det möjligt att få kvalitativa insikter, ger en konkurrensfördel och underlättar lyhördhet för marknadens efterfrågan.
Bland de främsta fördelarna med Apache Hive kan vi nämna användarvänligheten kopplat till dess ”SQL-vänliga” språk. Dessutom snabbar det på den initiala infogningen av data eftersom data inte behöver läsas eller numreras från en disk i det interna databasformatet.
Genom att veta att data lagras i HDFS är det möjligt att lagra stora datamängder på upp till hundratals petabyte data på Apache Hive. Denna lösning är mycket mer skalbar än en traditionell databas. Genom att veta att det är en molntjänst tillåter Apache Hive användare att snabbt starta virtuella servrar baserat på fluktuationer i arbetsbelastningar (dvs. uppgifter).
Säkerhet är också en aspekt där Hive presterar bättre, med sin förmåga att replikera återställningskritiska arbetsbelastningar i händelse av problem. Slutligen är arbetskapaciteten oöverträffad eftersom den kan utföra upp till 100 000 förfrågningar per timme.
Apache Impala
Apache Impala är en massivt parallell SQL-frågemotor för interaktiv exekvering av SQL-frågor på data lagrad i Apache Hadoop, skriven i C++ och distribuerad under Apache 2.0-licensen.
Impala kallas också en MPP-motor (Massively Parallel Processing), en distribuerad DBMS och till och med en SQL-on-Hadoop stackdatabas.

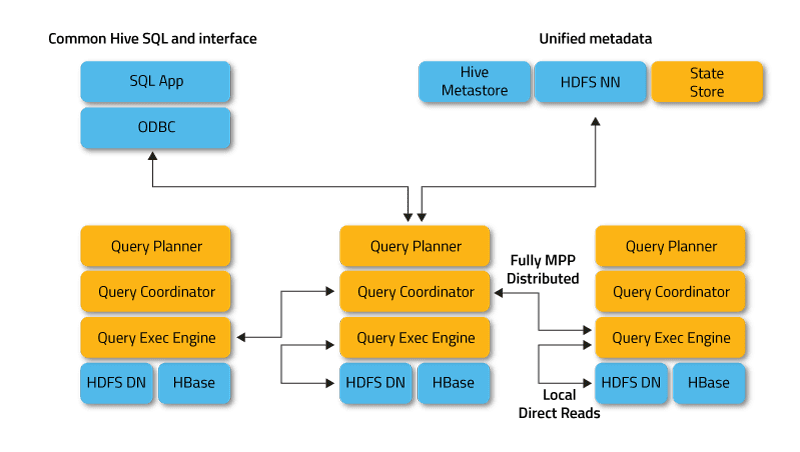
Impala arbetar i distribuerat läge, där processinstanser körs på olika klusternoder, tar emot, schemalägger och koordinerar klientförfrågningar. I det här fallet är parallell exekvering av fragment av SQL-frågan möjlig.
Klienter är användare och applikationer som skickar SQL-frågor mot data lagrade i Apache Hadoop (HBase och HDFS) eller Amazon S3. Interaktion med Impala sker via webbgränssnittet HUE (Hadoop User Experience), ODBC, JDBC och Impala Shells kommandoradsskal.
Impala är infrastrukturellt beroende av ett annat populärt SQL-on-Hadoop-verktyg, Apache Hive, som använder dess metadatalager. Speciellt låter Hive Metastore Impala veta om databasernas tillgänglighet och struktur.
När du skapar, modifierar och tar bort schemaobjekt eller laddar data till tabeller via SQL-satser, sprids motsvarande metadataändringar automatiskt till alla Impala-noder med hjälp av en specialiserad katalogtjänst.
Nyckelkomponenterna i Impala är följande körbara filer:
- Impalad eller Impala daemon är en systemtjänst som schemalägger och kör frågor på HDFS-, HBase- och Amazon S3-data. En impaladprocess körs på varje klusternod.
- Statestore är en namntjänst som håller reda på platsen och statusen för alla impaladinstanser i klustret. En instans av denna systemtjänst körs på varje nod och huvudservern (Name Node).
- Catalog är en metadatakoordinationstjänst som sprider ändringar från Impala DDL- och DML-satser till alla påverkade Impala-noder så att nya tabeller eller nyladdade data omedelbart är synliga för alla noder i klustret. Det rekommenderas att en instans av Catalog körs på samma klustervärd som demonen Statestored.
Hur fungerar Apache Impala
Impala, som Apache Hive, använder ett liknande deklarativt frågespråk, Hive Query Language (HiveQL), som är en delmängd av SQL92, istället för SQL.
Det faktiska utförandet av begäran i Impala är som följer:
Klientapplikationen skickar en SQL-fråga genom att ansluta till valfri impalad genom standardiserade ODBC- eller JDBC-drivrutinsgränssnitt. Den anslutna impaladen blir koordinator för den aktuella begäran.
SQL-frågan analyseras för att bestämma uppgifterna för impalad-instanserna i klustret; sedan byggs den optimala frågeexekveringsplanen.
Impalad får direkt åtkomst till HDFS och HBase med hjälp av lokala instanser av systemtjänster för att tillhandahålla data. Till skillnad från Apache Hive sparar en sådan direkt interaktion avsevärt tid för exekvering av frågor, eftersom mellanliggande resultat inte sparas.
Som svar returnerar varje demon data till den koordinerande impaladen och skickar resultatet tillbaka till klienten.
Funktioner hos Impala
- Stöd för bearbetning i realtid i minnet
- SQL-vänlig
- Stöder lagringssystem som HDFS, Apache HBase och Amazon S3
- Stöder integration med BI-verktyg som Pentaho och Tableau
- Använder HiveQL-syntax
Apache Impala: Fördelar
Impala undviker eventuell startoverhead eftersom alla systemdemonprocesser startas direkt vid uppstart. Det sparar avsevärt tid för exekvering av frågor. En ytterligare ökning av hastigheten på Impala beror på att detta SQL-verktyg för Hadoop, till skillnad från Hive, inte lagrar mellanresultat och kommer direkt åt HDFS eller HBase.
Dessutom genererar Impala programkod vid körning och inte vid kompilering, som Hive gör. En bieffekt av Impalas höghastighetsprestanda är dock minskad tillförlitlighet.
I synnerhet, om datanoden går ner under exekveringen av en SQL-fråga, kommer Impala-instansen att starta om, och Hive kommer att fortsätta att behålla en anslutning till datakällan, vilket ger feltolerans.
Andra fördelar med Impala inkluderar inbyggt stöd för ett säkert nätverksautentiseringsprotokoll Kerberos, prioritering och möjligheten att hantera kön av förfrågningar och stöd för populära Big Data-format som LZO, Avro, RCFile, Parquet och Sequence.
Hive vs Impala: likheter
Hive och Impala distribueras fritt under Apache Software Foundation-licensen och hänvisar till SQL-verktyg för att arbeta med data som lagras i ett Hadoop-kluster. Dessutom använder de också det distribuerade HDFS-filsystemet.
Impala och Hive implementerar olika uppgifter med gemensamt fokus på SQL-bearbetning av stora data lagrade i ett Apache Hadoop-kluster. Impala tillhandahåller ett SQL-liknande gränssnitt som låter dig läsa och skriva Hive-tabeller, vilket möjliggör enkelt datautbyte.
Samtidigt gör Impala SQL-operationer på Hadoop ganska snabba och effektiva, vilket gör det möjligt att använda detta DBMS i Big Data-analysforskningsprojekt. När det är möjligt arbetar Impala med en befintlig Apache Hive-infrastruktur som redan används för att exekvera långvariga SQL-batchfrågor.
Impala lagrar också sina tabelldefinitioner i en metastore, en traditionell MySQL- eller PostgreSQL-databas, dvs på samma plats där Hive lagrar liknande data. Det tillåter Impala att komma åt Hive-tabeller så länge som alla kolumner använder Impalas stödda datatyper, filformat och komprimeringscodec.
Hive vs Impala: skillnader

Programmeringsspråk
Hive är skrivet i Java, medan Impala är skrivet i C++. Impala använder dock även vissa Java-baserade Hive UDF:er.
Användningsfall
Dataingenjörer använder Hive i ETL-processer (Extract, Transform, Load), till exempel för långvariga batchjobb på stora datamängder, till exempel i reseaggregatorer och flygplatsinformationssystem. I sin tur är Impala främst avsedd för analytiker och datavetare och används främst i uppgifter som business intelligence.
Prestanda
Impala exekverar SQL-frågor i realtid, medan Hive kännetecknas av låg databehandlingshastighet. Med enkla SQL-frågor kan Impala köra 6-69 gånger snabbare än Hive. Men Hive hanterar komplexa frågor bättre.
Latens/genomströmning
Genomströmningen av Hive är betydligt högre än för Impala. Funktionen LLAP (Live Long and Process), som möjliggör frågecachning i minnet, ger Hive bra prestanda på låg nivå.
LLAP inkluderar långsiktiga systemtjänster (demoner), som låter dig interagera direkt med HDFS-datanoder och ersätta den tätt integrerade DAG-frågestrukturen (Directed acyclic graph) – en grafmodell som aktivt används i Big Data-beräkningar.
Feltolerans
Hive är ett feltåligt system som bevarar alla mellanresultat. Det påverkar också skalbarheten positivt men leder till en minskning av databehandlingshastigheten. I sin tur kan Impala inte kallas en feltolerant plattform eftersom den är mer minnesbunden.
Kodkonvertering
Hive genererar frågeuttryck vid kompilering, medan Impala genererar dem vid körning. Hive kännetecknas av ett ”kallstartsproblem” första gången applikationen startas; frågor konverteras långsamt på grund av behovet av att upprätta en anslutning till datakällan.
Impala har inte den här typen av startkostnader. De nödvändiga systemtjänsterna (demoner) för bearbetning av SQL-frågor startas vid uppstart, vilket påskyndar arbetet.
Stöd för lagring
Impala stöder formaten LZO, Avro och Parkett, medan Hive fungerar med vanlig text och ORC. Båda stöder dock formaten RCFIle och Sequence.
Apache HiveApache ImpalaLanguage JavaC++ Use CasesData EngineeringAnalys och analysPrestandaHög för enkla frågor Jämförelsevis låg LatencyMer latens på grund av cachingMindre latent FeltoleransMer tolerant på grund av MapReduceMindre tolerant på grund av MPPConversionstartFasterZO, Avancerad omvandling och avstötning på grund av kallt O, Av.
Slutord
Hive och Impala tävlar inte utan kompletterar varandra effektivt. Även om det finns betydande skillnader mellan de två, finns det också ganska mycket gemensamt och att välja den ena framför den andra beror på data och specifika krav i projektet.
Du kan också utforska direkta jämförelser mellan Hadoop och Spark.
.