

Låt oss ta reda på hur du kan hålla din produktion pålitlig med hjälp av Chaos Engineering-verktyg.
Kaosteknik är en disciplin där du experimenterar med ditt system eller din applikation för att avslöja dess svagheter och kapacitetsfel. Dessa är något som du inte trodde kunde hända när du skapade det. Så, du skulle orsaka att några fel avsiktligt på ditt system visar sina svagheter för att göra korrigeringarna och göra ditt system och din applikation mer motståndskraftig.
Många populära organisationer som Netflix, LinkedIn och Facebook utför kaosteknik för att bättre förstå deras mikrotjänsters arkitektur och distribuerade system. Det hjälper till att hitta nya problem snabbare än verkliga användarklagomål och vidta nödvändiga åtgärder för att rätta till dem. Det är så dessa organisationer kan tjäna miljontals användare, öka deras produktivitet och spara miljontals dollar 🤑.
Fördelar med Chaos Engineering:
- Kontrollera inkomstförluster genom att hitta kritiska problem
- Minskad system- eller applikationsfel
- Bättre användarupplevelse med mindre störningar och hög tjänsttillgänglighet
- Det hjälper dig att lära dig om systemet och få självförtroende.
Hur säker är du på din produktionstillförlitlighet? Är det riktigt katastrofsäkert?
Låt oss ta reda på det med hjälp av följande populära verktyg för kaostestning.
Innehållsförteckning
Kaosnät
Kaosnät är en kaosteknikhanteringslösning som injicerar fel i varje lager av ett Kubernetes-system. Detta inkluderar pods, nätverket, system I/O och kärnan. Chaos Mesh kan automatiskt döda Kubernetes-poddar och simulera latenser. Det kan störa pod-to-pod-kommunikation och simulera läs-/skrivfel. Den kan schemalägga regler för experimenten och definiera deras omfattning. Dessa experiment specificeras med YAML-filer.
Chaos Mesh har en instrumentpanel för att se analyser av experiment. Den körs ovanpå Kubernetes och stöder majoriteten av molnplattformen. Det är öppen källkod och accepterades nyligen som ett CNCF-sandlådeprojekt. Med hjälp av principer för kaosteknik kan du lägga till Chaos Mesh till ditt DevOps-arbetsflöde för att bygga motståndskraftiga applikationer.
Chaos Engineering funktioner:
- Enkelt att distribuera på Kubernetes-kluster utan några ändringar i distributionslogiken
- Inga unika beroenden krävs för distribution
- Definierar kaosobjekt med CustomResourceDefinitions (CRD)
- Tillhandahåller en instrumentpanel för att spåra alla experiment
Kaos ToolKit är ett enkelt verktyg med öppen källkod för Chaos Engineering Experiment Automation.
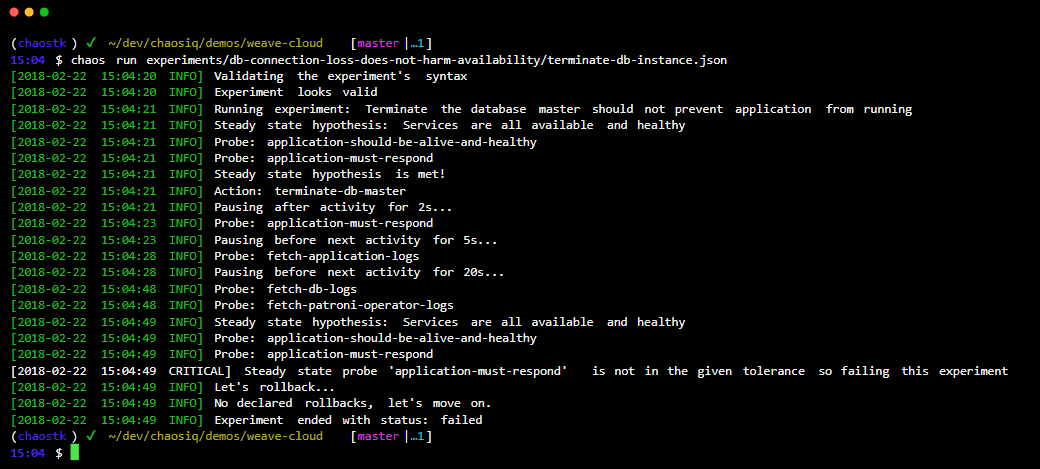
Du integrerar Chaos ToolKit med ditt system med hjälp av en uppsättning drivrutiner eller plugins som stöder AWS, Google Cloud, Slack, Prometheus, etc.
Chaos ToolKit funktioner:
- Tillhandahåller deklarativt Open API för att skapa kaosexperiment oberoende av en leverantör eller teknik
- Kan enkelt bäddas in i CICD-pipelines för automatisering
- Ger kommersiellt och företagsstöd även genom ChaosIQ
ChaosKube
Som du kan gissa på namnet är det för Kubernetes.
Chaoskube är ett kaosverktyg med öppen källkod som dödar slumpmässiga poddar med jämna mellanrum i Kubernetes-klustret. Det hjälper dig att förstå hur ditt system kommer att reagera när podden misslyckas. Som standard dödar den en pod i valfritt namnområde var tionde minut. Du kan filtrera målpodarna i Chaoskube med hjälp av namnutrymmen, etiketter, anteckningar etc. Det kan enkelt installeras med Chaoskube.

Kaosapa
Kaosapa är ett verktyg som används för att kontrollera molnsystemens motståndskraft genom att medvetet skapa misslyckanden för dessa system att förstå deras reaktion. Netflix skapade den för att testa dess AWS-infrastrukturens motståndskraft och återställningsförmåga. Den fick namnet Chaos Monkey eftersom den skapar förstörelse som en vild och beväpnad apa för att testa misslyckandena.
Det var också Chaos Monkey, som födde den nya ingenjörspraktiken Chaos Engineering. Det skapades på principen att det är bättre att misslyckas upprepade gånger för att undvika ett allvarligt misslyckande plötsligt.
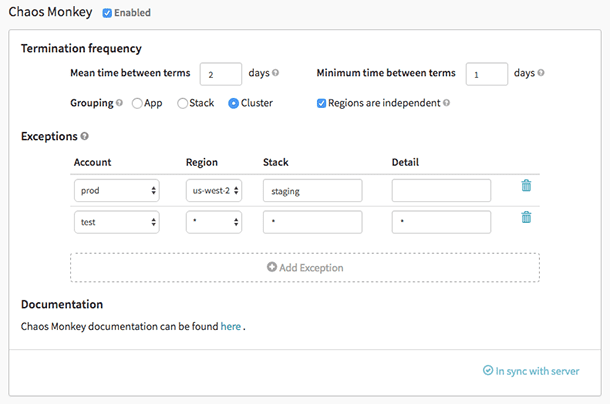
Chaos Monkey funktioner:
- Det hjälper dig att förbereda dig för slumpmässiga instansfel.
- Uppmuntrar redundans för oväntade misslyckanden
- Använder Spinnaker för att möjliggöra cross-cloud-kompatibilitet
- Ger konfigurerbart schema för att simulera fel
- Integrerad med govendor för att lägga till nya beroenden till kaosapan
Simmy
Simmy är ett kaosverktyg för felinjektion som integreras med Polly resilience-projektet för .NET. Det låter dig skapa kaosinjektionspolicyer genom Polly, där du kör dina koder. Den erbjuder olika policyer såsom undantagspolicy för att injicera undantag i systemet, beteendepolicy för att injicera något nytt beteende, etc. Dessa policyer är utformade för att injicera beteendet slumpmässigt.
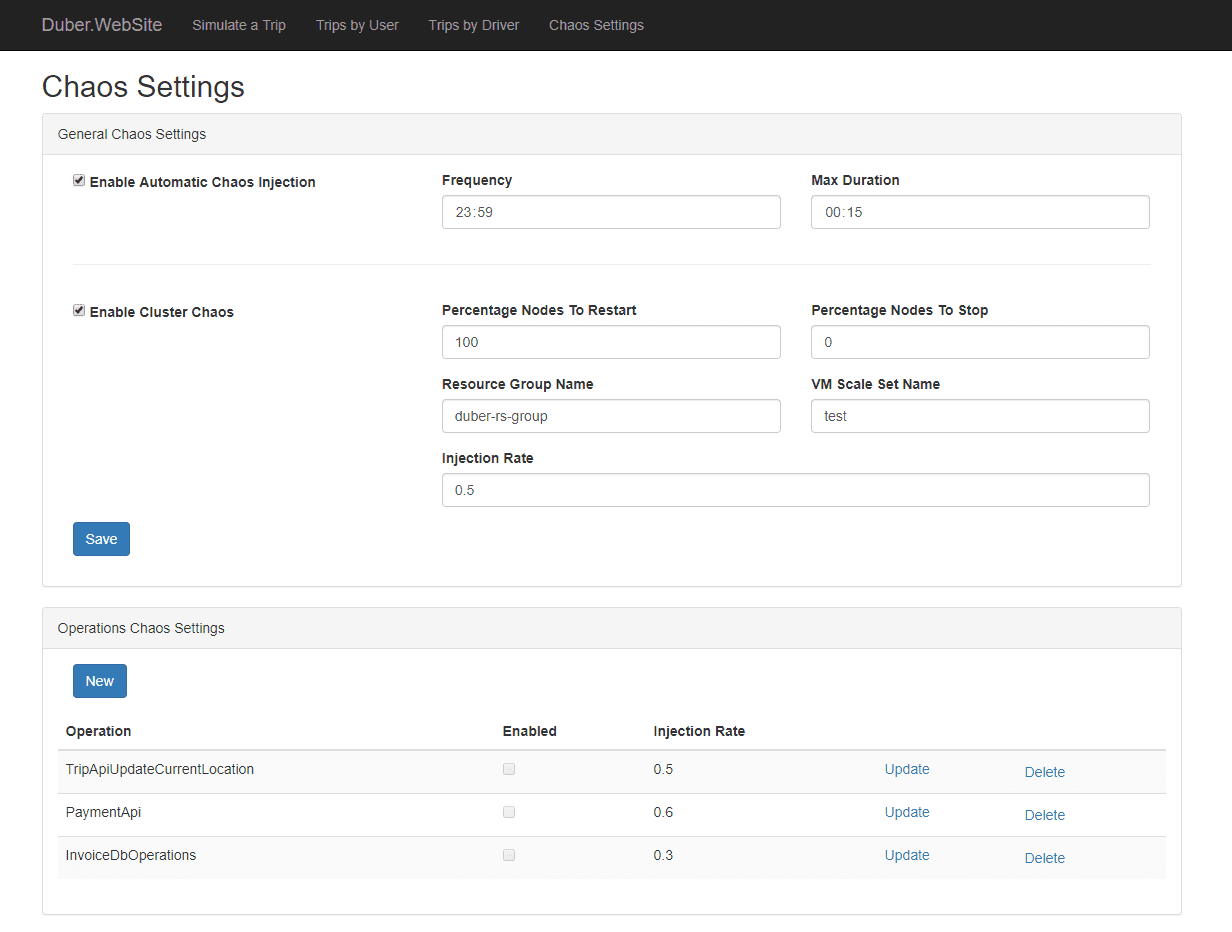
Simmy funktioner:
- Tillhandahåller Monkey-policyer eller Chaos-policyer för att skapa kaos
- Lätt att testa eventuella beroendefel
- Det hjälper till att snabbt återgå till arbetsmodellen och kontrollerar sprängradien.
- Den är färdig i produktionsklass.
- Det kan också definiera fel baserat på externa faktorer (till exempel fel på grund av global konfiguration)
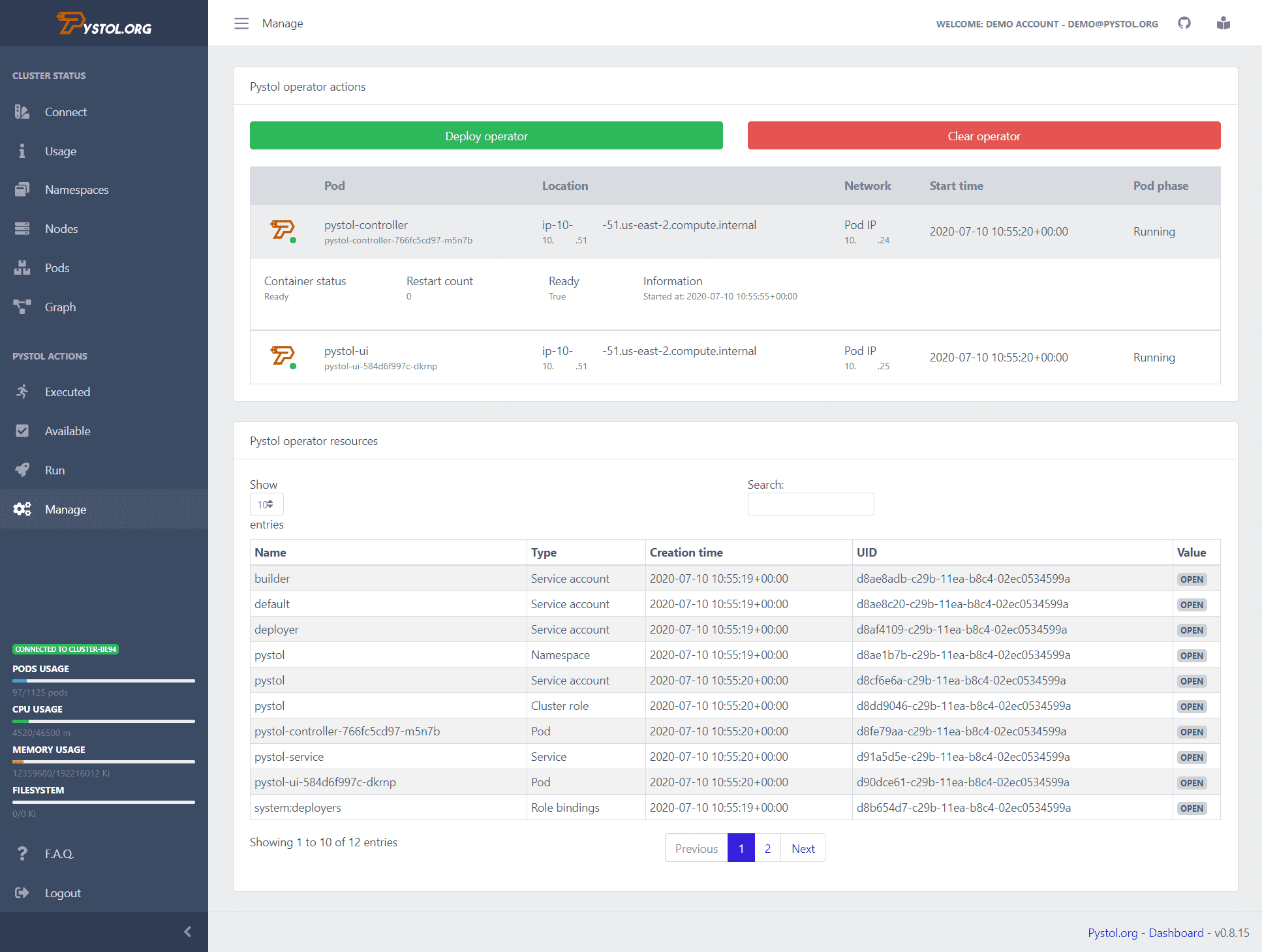
Pystol
Pystol är ett verktyg som används för att injicera felaktiga injektioner i molnbaserade miljöer. Den tittar på händelser i ETCD genom Kubernetes-operatörer. När en felinjiceringsåtgärd utförs skapar operatörerna pods och kör några Ansible-samlingar. Så utvecklare behöver inte skriva sina egna åtgärder för att utföra.
Pystol tillhandahåller färdiga åtgärder för att testa systemet. Ändå, om en utvecklare vill skapa en ny åtgärd, kan det göras med GoLang och Python.
Den tillhandahåller en kontinuerlig integrationsinstrumentpanel för att ge en sammanfattning av alla jobboperationer. Du kan köra Pystol lokalt eller distribuera den i en container med hjälp av dess docker-avbildning. Pystol tillhandahåller två gränssnitt, ett är webbgränssnitt och det andra är via CLI. Uppenbarligen är webbgränssnittet ett bättre alternativ.
Muxy
Muxy är en proxy för att testa din motståndskraft och feltoleransmönster för verkliga distribuerade systemfel. Den kan manipulera transportnivå (lager 4), TCP-sessionsnivå (lager 5) och HTTP-protokollnivå (lager 7).
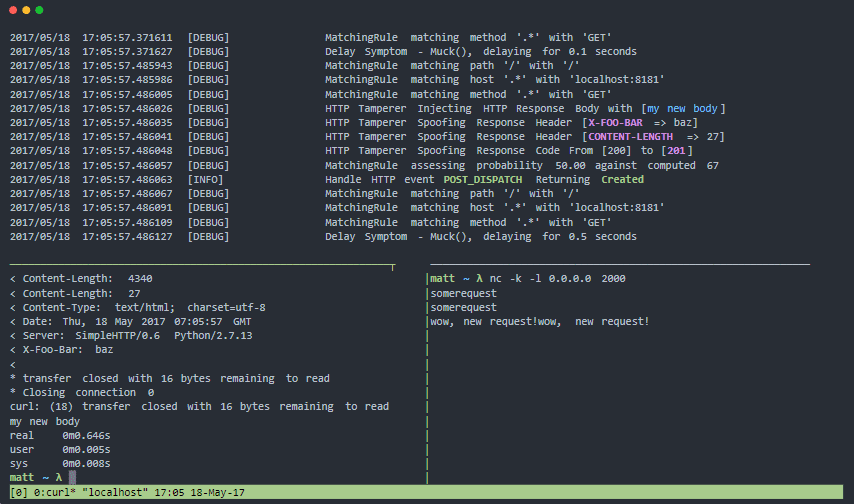
Muxy funktioner:
- Modulär arkitektur och lätt att bygga ut
- Har officiell hamnarcontainer
- Lätt att installera, inga beroenden krävs.
- Idealisk för kontinuerlig testning av spänst
- Simulerar problem med nätverksanslutning för distribuerade system och mobila enheter
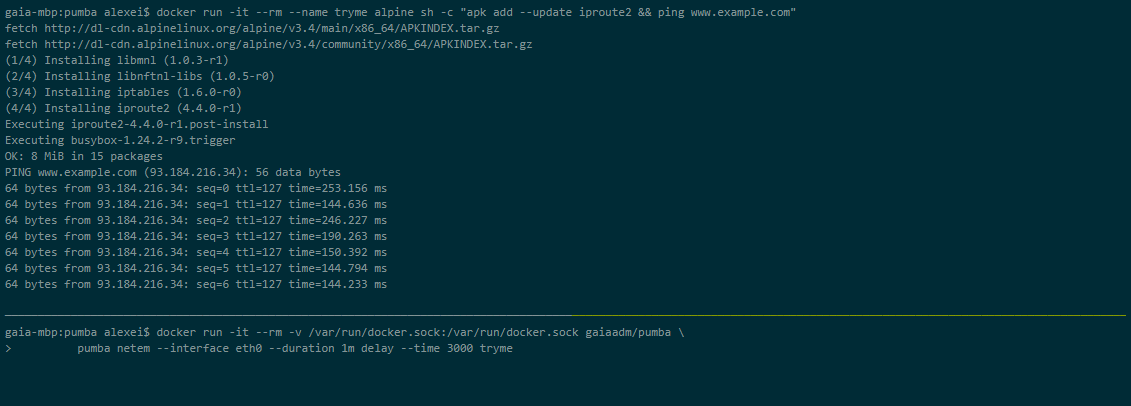
Pumba
Pumba är ett kommandoradsverktyg som utför kaostestning för hamnarcontainrar. Med Pumba kraschar du medvetet applikationens dockningsbehållare för att se hur systemet reagerar. Du kan också utföra stresstester på containerresurserna som CPU, minne, filsystem, input/output, etc.
Du kan också köra Pumba på ett Kubernetes-kluster. Du måste använda DaemonSets för att distribuera Pumba på Kubernetes-noder. Du kan använda flera Pumba-behållare för att köra flera Pumba-kommandon i samma DaemonSet.
ChaosBlade
ChaosBlade är ett verktyg med öppen källkod för att injicera experiment i systemen av Alibaba. Den testar alla misslyckanden som Alibaba har mött under de senaste tio åren och tillämpar bästa praxis för att undvika dem. Det följer kaostekniska principer för att kontrollera feltoleransen hos distribuerade system.
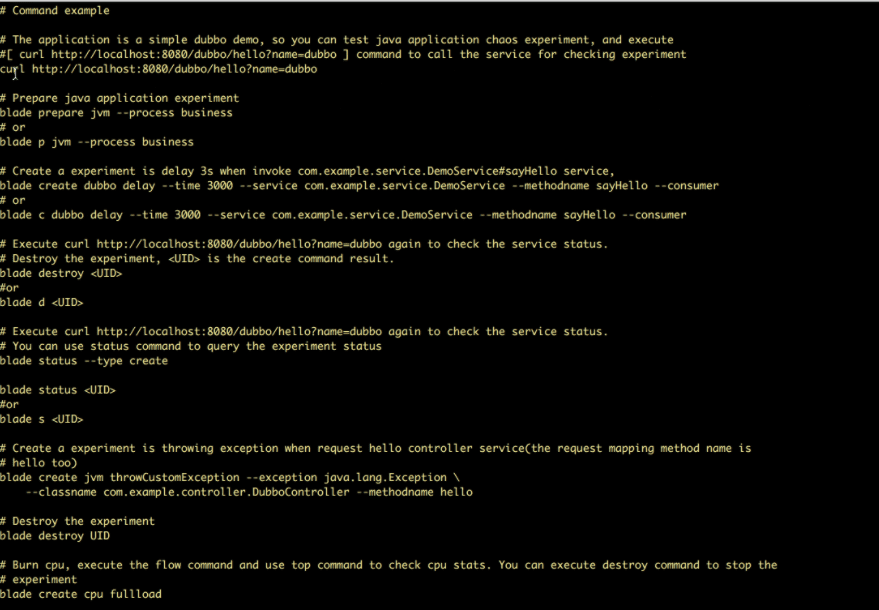
ChaosBlade funktioner:
- Tillhandahåller experimentella scenarier för flera resurser som CPU, nätverk, minne, disk, etc.
- Tillhandahåller experimentella scenarier för noder, nätverk och poddar på Kubernetes-plattformen
- Ger lättanvända CLI-kommandon för att utföra experiment
Lackmus
Lackmus följer molnbaserade kaostekniska principer. Lakmusverktygets uppdrag är att leverera ett komplett ramverk för att hitta svagheter i dina Kubernetes-system och dina körande applikationer på Kubernetes.
Den har en kaosoperatör och CRD:erna (CustomResourceDefinitions) runt det, vilket tillåter plug-and-play-möjlighet. Det handlar om att sätta in din kaoslogik i en dockar-bild, kasta in den i ett lackmusramverk och få dem orkestrerade med hjälp av CRD:erna.

Lakmusfunktioner:
- Hjälper Site Reliability-ingenjörer och utvecklare att hitta svagheter i Kubernetes-systemet
- Ger färdiga att använda generiska experiment
- Tillhandahåller Chaos API för hantering av kaosarbetsflöden
- Litmus SDK stöder Go, Python och Ansible för att skapa dina egna experiment.
Gremlin
Gremlin hjälper ingenjörer att bygga mer motståndskraftig programvara. Det ger en plattform för att köra kaostekniska experiment säkert, säkert och enkelt.

Du kan eftertänksamt injicera fel i värdar eller behållare med gremlin oavsett var de är, oavsett om det är det offentliga molnet eller ditt eget datacenter.
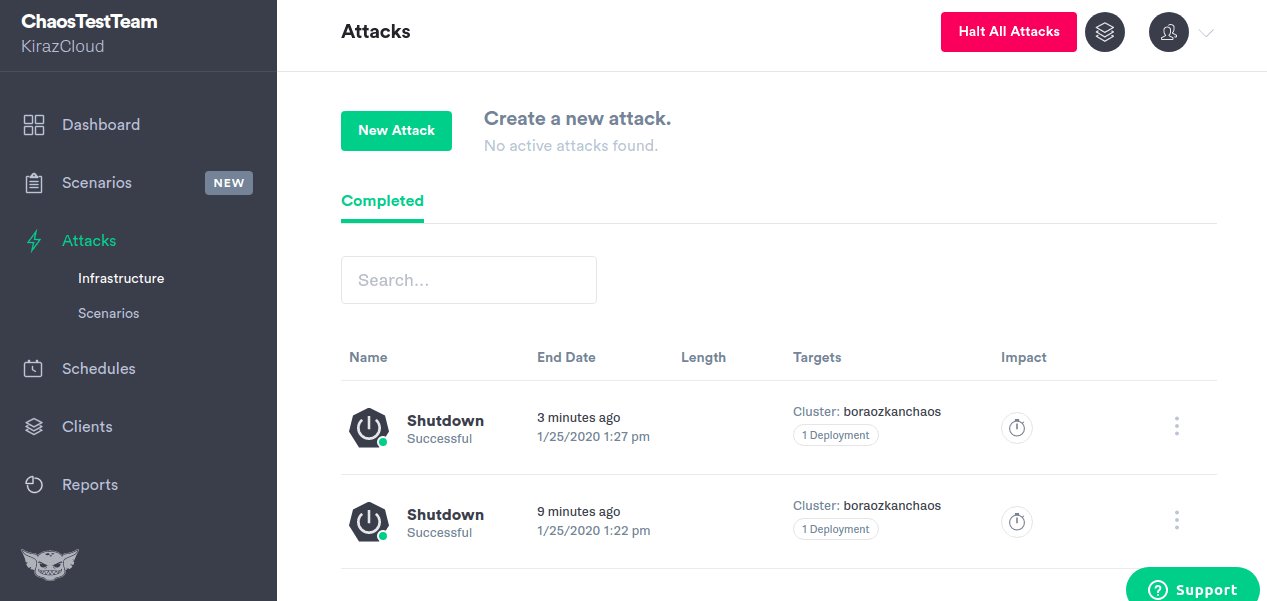
Gremlin har:
- Installerar lättviktsmedel på dina värdar eller behållare för att injicera fel
- Ger 10+ olika infrastrukturattacklägen
- State gremlins låter dig manipulera systemtiden, stänga av eller starta om värdar och döda processorer.
- Nätverksgremlins kan injicera latens för att införa paketförlust eller släppa trafiken.
- Gremlins Alfi-biblioteksattacker kan konfigureras, startas och stoppas via webbappen. API eller CLI
- Låter dig rikta in den sprängradie du vill attackera exakt
- Låter dig stoppa alla attacker och rulla tillbaka systemet till ett stabilt tillstånd
Steadybit
Steadybit syftar till att minska stilleståndstiden proaktivt och ger insyn i systemproblem. Du kan köra det här verktyget lokalt på din infrastruktur eller moln som en tjänst (SaaS).
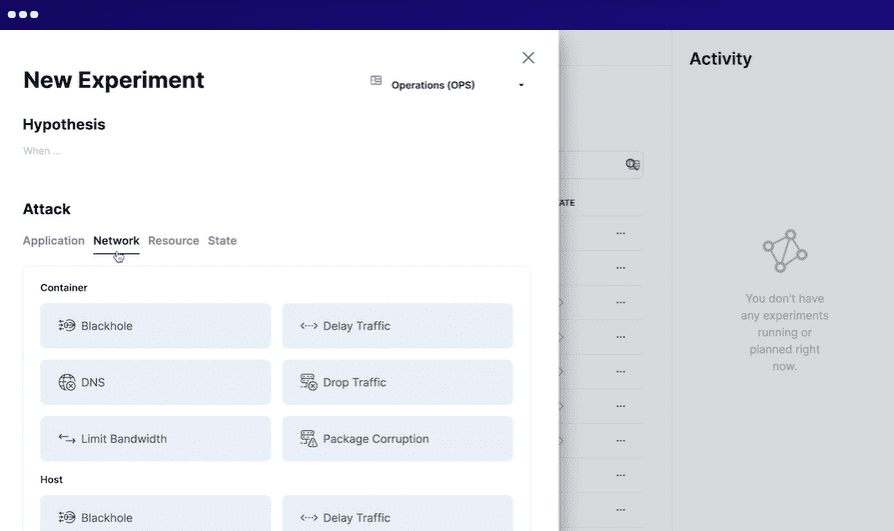
För att använda Steadybit definierar du situationen, simulerar experimenten, utför de simulerade experimenten i produktionen och automatiserar alla experiment. Den kör intelligenta agenter på ditt system för att upptäcka potentiella problem och svagheter. Den integreras med flera system med lätthet.
Slutsats
Fortsätt och var modig nog att tillämpa kaostekniska principer och testa din produktion med de ovan nämnda verktygen. Dessa verktyg hjälper dig att hitta flera oidentifierade svagheter i ditt system, och det hjälper dig att göra ditt system mer motståndskraftigt.