Utforska datanalys med naturligt språk med PandasAI
Är du fascinerad av möjligheten att analysera data med hjälp av naturligt språk? Dyk in i hur du kan göra det med Python-biblioteket PandasAI.
I en tid där data är av största vikt är det avgörande att kunna förstå och analysera den effektivt. Traditionella metoder för datanalys kan dock vara komplexa och tidskrävande. Här kommer PandasAI in i bilden. Det här biblioteket förenklar dataanalysen genom att låta dig interagera med din data genom att använda naturligt språk.
PandasAI fungerar genom att översätta dina frågor till kod för dataanalys. Det bygger på det välkända Python-biblioteket Pandas. PandasAI är ett Python-bibliotek som utvidgar Pandas funktionalitet med generativa AI-funktioner. Det är avsett att komplettera Pandas, snarare än att ersätta det.
PandasAI introducerar en konversationsaspekt till Pandas (liksom till andra populära datanalysbibliotek), vilket gör att du kan kommunicera med din data genom att använda naturliga språkliga frågor.
Den här guiden leder dig genom stegen för att konfigurera PandasAI, använda det med en verklig datauppsättning, skapa diagram, utforska genvägar och analysera styrkor och begränsningar hos det här kraftfulla verktyget.
När du är klar med den här guiden kommer du att kunna utföra dataanalys enklare och mer intuitivt med hjälp av naturligt språk.
Låt oss tillsammans utforska den spännande världen av datanalys med naturligt språk med PandasAI!
Konfigurera din utvecklingsmiljö
För att börja med PandasAI behöver du först installera PandasAI-biblioteket.
I det här projektet kommer jag att använda en Jupyter Notebook. Du kan dock lika gärna använda Google Colab eller VS Code, beroende på dina behov.
Om du planerar att använda Open AI Large Language Models (LLM) är det också viktigt att installera Open AI Python SDK för en smidig upplevelse.
# Installera PandasAI !pip install pandas-ai # PandasAI använder OpenAIs språkmodeller, så du behöver installera OpenAI Python SDK !pip install openai
Låt oss nu importera alla nödvändiga bibliotek:
# Importera nödvändiga bibliotek import pandas as pd import numpy as np # Importera PandasAI och dess komponenter from pandasai import PandasAI, SmartDataframe from pandasai.llm.openai import OpenAI
En viktig aspekt av datanalys med PandasAI är API-nyckeln. Det här verktyget stöder flera stora språkmodeller (LLM) och LangChain-modeller, som används för att generera kod från naturliga språkfrågor. Detta gör dataanalys mer lättillgänglig och användarvänlig.
PandasAI är mångsidigt och kan hantera flera olika typer av modeller, inklusive Hugging Face-modeller, Azure OpenAI, Google PALM och Google VertexAI. Var och en av dessa modeller tillför sina egna fördelar, vilket förbättrar PandasAIs kapacitet.
Kom ihåg att du behöver lämpliga API-nycklar för att använda dessa modeller. Dessa nycklar autentiserar dina förfrågningar och låter dig utnyttja kraften i dessa avancerade språkmodeller i dina dataanalysuppgifter. Se därför till att ha dina API-nycklar redo när du konfigurerar PandasAI för dina projekt.
Du kan hämta API-nyckeln och spara den som en miljövariabel.
I nästa steg kommer du att lära dig hur man använder PandasAI med olika typer av stora språkmodeller (LLM) från OpenAI och Hugging Face Hub.
Använda stora språkmodeller
Du kan välja en LLM antingen genom att instansiera en och skicka den till SmartDataFrame- eller SmartDatalake-konstruktorn, eller genom att ange en i filen pandasai.json.
Om modellen förväntar sig en eller flera parametrar kan du antingen skicka dem till konstruktorn eller specificera dem i filen pandasai.json under parametern llm_options, enligt följande:
{
"llm": "OpenAI",
"llm_options": {
"api_token": "API_TOKEN_GOES_HERE"
}
}
Hur man använder OpenAI-modeller
För att kunna använda OpenAI-modeller måste du ha en OpenAI API-nyckel. Du kan få en här.
När du har en API-nyckel kan du använda den för att instansiera ett OpenAI-objekt:
#Vi har importerat alla nödvändiga bibliotek i föregående steg
llm = OpenAI(api_token="my-api-key")
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Glöm inte att ersätta ”my-api-key” med din faktiska API-nyckel.
Alternativt kan du ställa in miljövariabeln OPENAI_API_KEY och instansiera OpenAI-objektet utan att skicka API-nyckeln:
# Ställ in miljövariabeln OPENAI_API_KEY
llm = OpenAI() # du behöver inte skicka API-nyckeln, den läses från miljövariabeln
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Om du ansluter via en explicit proxy kan du specificera openai_proxy när du instansierar OpenAI-objektet eller ställa in miljövariabeln OPENAI_PROXY.
Viktigt att notera: När du använder PandasAI-biblioteket för dataanalys med din API-nyckel är det viktigt att du håller koll på din tokenanvändning för att hantera kostnader.
Hur gör man det? Kör helt enkelt följande tokenräknare för att få en tydlig bild av din tokenanvändning och tillhörande kostnader. På så sätt kan du effektivt hantera dina resurser och undvika obehagliga överraskningar på din faktura.
Du kan beräkna antalet tokens som används av en prompt på följande sätt:
"""Exempel på hur man använder PandasAI med en pandas dataframe"""
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
from pandasai.helpers.openai_info import get_openai_callback
import pandas as pd
llm = OpenAI()
# conversational=False ska visa lägre användning och kostnad
df = SmartDataframe("data.csv", {"llm": llm, "conversational": False})
with get_openai_callback() as cb:
response = df.chat("Beräkna summan av BNP för nordamerikanska länder")
print(response)
print(cb)
Du får ett resultat som det här:
# Summan av BNP för nordamerikanska länder är 19 294 482 071 552. # Använda tokens: 375 # Prompt-tokens: 210 # Kompletteringstoken: 165 # Totalkostnad (USD): $ 0.000750
Glöm inte att notera din totala kostnad om du har begränsade krediter!
Hur man använder Hugging Face-modeller
För att kunna använda HuggingFace-modeller måste du ha en HuggingFace API-nyckel. Du kan skapa ett HuggingFace-konto här och få en API-nyckel här.
När du har en API-nyckel kan du använda den för att instansiera en av HuggingFace-modellerna.
För närvarande stöder PandasAI följande HuggingFace-modeller:
- Starcoder: bigcode/starcoder
- Falcon: tiiuae/falcon-7b-instruct
from pandasai.llm import Starcoder, Falcon
llm = Starcoder(api_token="min-huggingface-api-nyckel")
# eller
llm = Falcon(api_token="min-huggingface-api-nyckel")
df = SmartDataframe("data.csv", config={"llm": llm})
Alternativt kan du ställa in miljövariabeln HUGGINGFACE_API_KEY och instansiera HuggingFace-objektet utan att skicka API-nyckeln:
from pandasai.llm import Starcoder, Falcon
llm = Starcoder() # du behöver inte skicka API-nyckeln, den läses från miljövariabeln
# eller
llm = Falcon() # du behöver inte skicka API-nyckeln, den läses från miljövariabeln
df = SmartDataframe("data.csv", config={"llm": llm})
Starcoder och Falcon är båda LLM-modeller som finns tillgängliga på Hugging Face.
Vi har nu konfigurerat vår miljö och utforskat hur man använder både OpenAI- och Hugging Face LLM-modeller. Låt oss fortsätta vår dataanalysresa.
Vi kommer att använda datamängden Big Mart Sales, som innehåller information om försäljningen av olika produkter i olika butiker som tillhör Big Mart. Datamängden har 12 kolumner och 8 524 rader. Du hittar länken i slutet av artikeln.
Dataanalys med PandasAI
Nu när vi har installerat och importerat alla nödvändiga bibliotek, låt oss ladda vår datamängd.
Ladda datamängden
Du kan antingen välja en LLM genom att instansiera en och skicka den till SmartDataFrame. Du hittar länken till datamängden i slutet av artikeln.
#Ladda datamängden från enheten path = r"D:\Pandas AI\Train.csv" df = SmartDataframe(path)
Använd OpenAIs LLM-modell
Efter att ha laddat in vår data kommer jag att använda OpenAIs LLM-modell för att använda PandasAI.
llm = OpenAI(api_token="API_Key") pandas_ai = PandasAI(llm, conversational=False)
Bra! Låt oss testa några prompts.
Visa de första 6 raderna i vår datamängd
Låt oss ladda de första 6 raderna genom att ange instruktioner:
Result = pandas_ai(df, "Visa de första 6 raderna i tabellform") Result
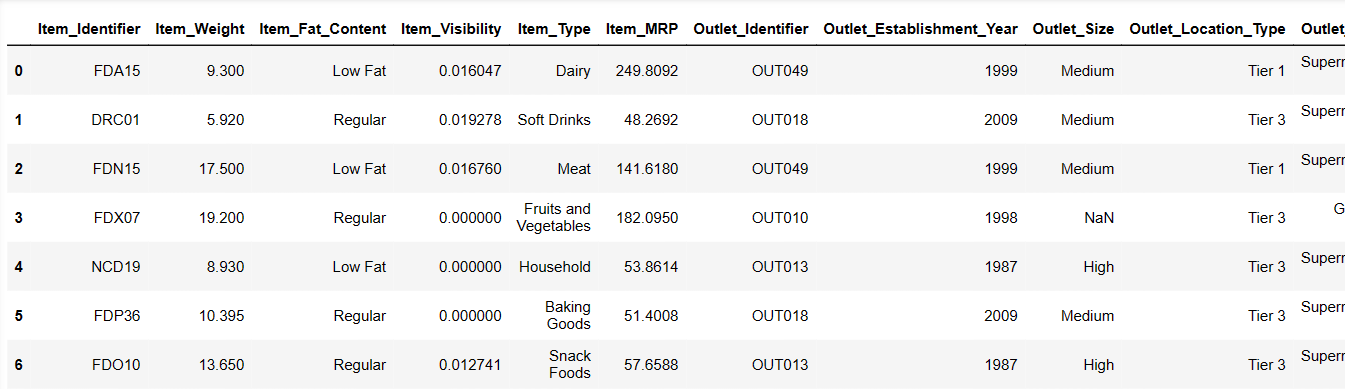 De första 6 raderna från datamängden
De första 6 raderna från datamängden
Det gick snabbt! Låt oss utforska vår datamängd.
Generera beskrivande statistik för DataFrame
# För att få beskrivande statistik Result = pandas_ai(df, "Visa beskrivningen av data i tabellform") Result
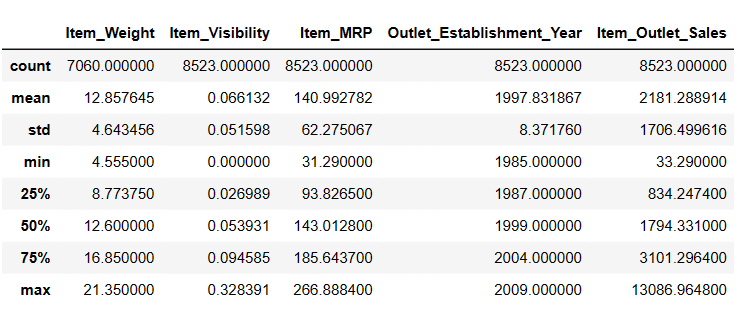 Beskrivning
Beskrivning
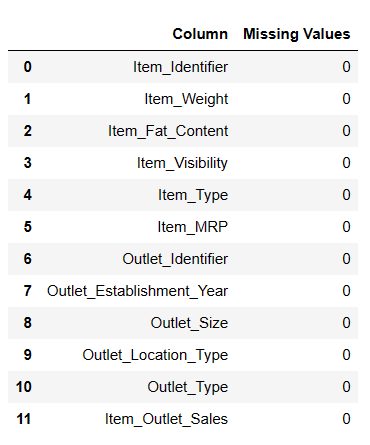
Det finns 7060 värden i Item_Weight. Det kan saknas några värden.
Hitta saknade värden
Det finns två sätt att hitta saknade värden med PandasAI.
#Hitta saknade värden Result = pandas_ai(df, "Visa de saknade värdena i tabellform") Result
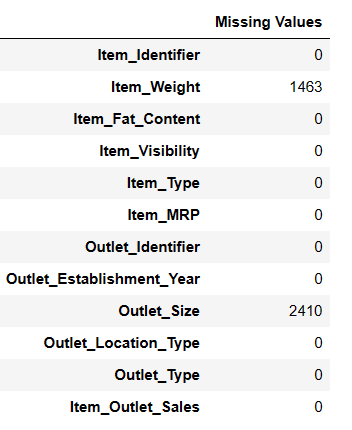 Hitta saknade värden
Hitta saknade värden
# Genväg för datarensning
df = SmartDataframe('data.csv')
df.clean_data()
Den här genvägen rensar data i dataramen.
Låt oss nu fylla i de saknade värdena.
Fyll i saknade värden
#Fyll i saknade värden result = pandas_ai(df, "Fyll Item Weight med medianen och Item outlet size nullvärden med läget och Visa de saknade värdena i tabellform") result
 Fyllda null-värden
Fyllda null-värden
Detta är en användbar metod för att fylla i null-värden, men jag stötte på vissa problem när jag fyllde i null-värden.
# Genväg för att fylla i null-värden
df = SmartDataframe('data.csv')
df.impute_missing_values()
Den här genvägen tillskriver saknade värden i dataramen.
Ta bort null-värden
Om du vill ta bort alla null-värden från din df kan du testa den här metoden.
result = pandas_ai(df, "Ta bort rader med saknade värden med inplace=True") result
Dataanalys är avgörande för att identifiera trender, både kortsiktiga och långsiktiga, vilket kan vara ovärderligt för företag, regeringar, forskare och privatpersoner.
Låt oss försöka hitta en övergripande försäljningstrend under de år som har gått sedan butiken etablerades.
Hitta försäljningstrenden
#hitta trenden i försäljningen result = pandas_ai(df, "Vad är den övergripande trenden i försäljningen under åren sedan butiken etablerades?") result
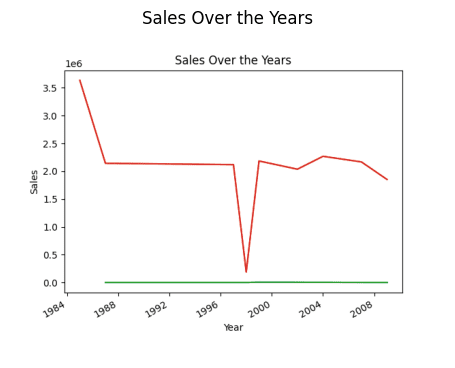 Försäljning under året (Linjediagram)
Försäljning under året (Linjediagram)
Den initiala handläggningen var lite långsam, men efter att ha startat om kärnan och kört allt gick det snabbare.
# Genväg till att rita linjediagram
df.plot_line_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Den här genvägen ritar ett linjediagram över dataramen.
Du kanske undrar varför det finns en nedgång i trenden. Det beror på att vi inte har data från 1989 till 1994.
Hitta året med högst försäljning
Nu ska vi ta reda på vilket år som hade högst försäljning.
# hitta året med högst försäljning result = pandas_ai(df, "Förklara vilka år som hade högst försäljning") result

Så året med den högsta försäljningen är 1985.
Jag vill dock ta reda på vilken artikeltyp som genererar den högsta genomsnittliga försäljningen och vilken som genererar den lägsta genomsnittliga försäljningen.
Högsta och lägsta genomsnittliga försäljning
# hitta högsta och lägsta genomsnittliga försäljning result = pandas_ai(df, "Vilken artikeltyp genererar den högsta genomsnittliga försäljningen och vilken genererar den lägsta?") result

Stärkelsebaserade livsmedel har den högsta genomsnittliga försäljningen och andra har den lägsta genomsnittliga försäljningen. Om du inte vill att andra ska ha den lägsta försäljningen kan du förbättra deras effektivitet enligt dina behov.
Utmärkt! Nu vill jag ta reda på fördelningen av försäljningen mellan de olika butikerna.
Fördelning av försäljning på olika butiker
Det finns fyra typer av butiker: Stormarknad typ 1/2/3 och livsmedelsbutiker.
# fördelning av försäljningen på olika butikstyper sedan etableringen response = pandas_ai(df, "Visualisera fördelningen av försäljningen på olika butikstyper sedan etableringen med hjälp av ett stapeldiagram, plot size=(13,10)") response
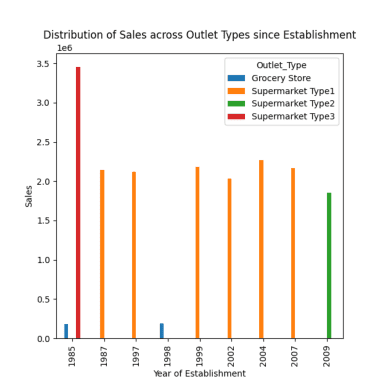 Fördelning av försäljning på olika butiker
Fördelning av försäljning på olika butiker
Som vi har sett i tidigare prompts inträffade toppförsäljningen 1985, och det här diagrammet visar att den högsta försäljningen 1985 kom från stormarknader av typ 3.
# Genväg till att rita stapeldiagram
df = SmartDataframe('data.csv')
df.plot_bar_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Den här genvägen ritar ett stapeldiagram över dataramen.
# Genväg till att rita histogram
df = SmartDataframe('data.csv')
df.plot_histogram(column = 'a')
Den här genvägen ritar ett histogram av dataramen.
Låt oss nu ta reda på vad som är den genomsnittliga försäljningen för artiklar med ”Low Fat” och ”Regular” fettinnehåll.
Hitta genomsnittlig försäljning för artiklar med fettinnehåll
# hitta indexet för en rad med hjälp av värdet i en kolumn result = pandas_ai(df, "Vad är den genomsnittliga försäljningen för artiklar med 'Low Fat' och 'Regular' fettinnehåll?") result
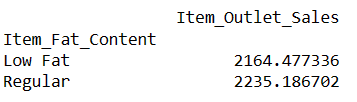
Genom att skriva sådana här uppmaningar kan du jämföra två eller fler produkter.
Genomsnittlig försäljning för varje artikeltyp
Jag vill jämföra alla produkter med deras genomsnittliga försäljning.
#Genomsnittlig försäljning för varje artikeltyp result = pandas_ai(df, "Vad är den genomsnittliga försäljningen för varje artikeltyp under de senaste 5 åren?, använd ett cirkeldiagram, size=(6,6)") result
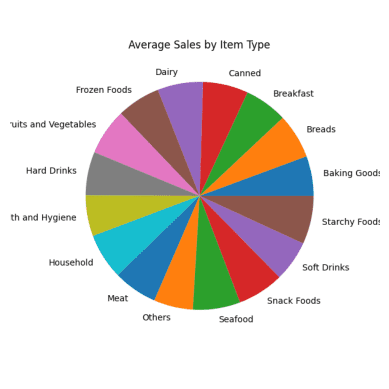 Genomsnittlig försäljning Cirkeldiagram
Genomsnittlig försäljning Cirkeldiagram
Alla delar av cirkeldiagrammet ser likadana ut eftersom de har nästan samma försäljningssiffror.
# Genväg till att rita cirkeldiagram
df.plot_pie_chart(labels = ['a', 'b', 'c'], values = [1, 2, 3])
Den här genvägen ritar ett cirkeldiagram över dataramen.
Topp 5 mest sålda artikeltyper
Även om vi redan har jämfört alla produkter baserat på genomsnittlig försäljning vill jag nu identifiera de fem bästa artiklarna med högst försäljning.
#Hitta de 5 bästa säljande artiklarna result = pandas_ai(df, "Vilka är de 5 bäst säljande artikeltyperna baserat på genomsnittlig försäljning? Skriv i tabellform") result
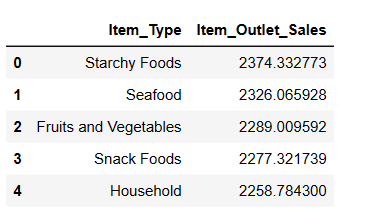
Som väntat är stärkelsebaserade livsmedel den bäst säljande artikeln baserat på genomsnittlig försäljning.
Topp 5 sämst säljande artikeltyper
result = pandas_ai(df, "Vilka är de 5 sämst säljande artikeltyperna baserat på genomsnittlig försäljning?") result
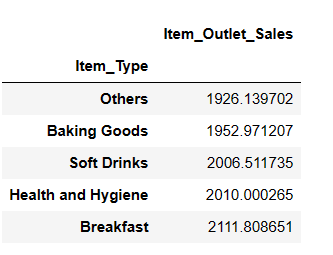
Du kanske blir förvånad över att se läskedrycker i kategorin sämst säljande. Det är dock viktigt att notera att dessa uppgifter endast gäller fram till 2008 och att läskedryckernas trend fick fart några år senare.
Försäljning av produktkategorier
Här använde jag ordet ”produktkategori” i stället för ”artikeltyp”, och PandasAI skapade fortfarande diagrammet, vilket visar att verktyget förstår liknande ord.
result = pandas_ai(df, "Visa ett staplat stapeldiagram i stor storlek över försäljningen av de olika produktkategorierna för det senaste räkenskapsåret") result
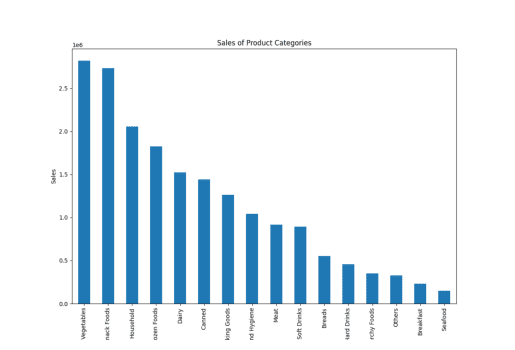 Försäljning av artikeltyp
Försäljning av artikeltyp
Du hittar våra återstående genvägar här.
Du kanske märker att när vi skriver en prompt och ger instruktioner till PandasAI så ger verktyget resultat baserat enbart på den specifika prompten. Det analyserar inte dina tidigare prompter för att ge mer exakta svar.
Men med hjälp av en chattagent kan du också uppnå denna funktionalitet.
Chattagent
Med chattagenten kan du delta i dynamiska konversationer där agenten behåller sitt sammanhang under hela diskussionen. Detta gör att du kan ha mer interaktiva och meningsfulla utbyten.
Nyckelfunktioner som möjliggör denna interaktion inkluderar kontextbevarande, där agenten minns konversationshistoriken, vilket möjliggör sömlösa, kontextmedvetna interaktioner. Du kan använda förtydligande frågor för att begära förtydliganden om alla aspekter av konversationen, vilket säkerställer att du fullt ut förstår informationen som tillhandahålls.
Dessutom är metoden ”Förklara” tillgänglig för att få detaljerade förklaringar om hur agenten kom fram till en viss lösning eller ett visst svar, vilket ger transparens och insikt i agentens beslutsprocess.
Starta gärna konversationer, begär förtydliganden och utforska förklaringar för att förbättra din interaktion med chattagenten!
from pandasai import Agent
agent = Agent(df, config={"llm": llm}, memory_size=10)
result = agent.chat("Vilka är de 5 artiklarna med högsta MRP?")
result
Till skillnad från en SmartDataFrame eller en SmartDatalake kommer en agent att hålla koll på konversationens tillstånd och kommer att kunna svara på konversationer med flera svängar.
Låt oss gå vidare till fördelar och begränsningar med PandasAI
Fördelar med PandasAI
Att använda Pandas AI ger flera fördelar som gör det till ett värdefullt verktyg för dataanalys, till exempel:
- Tillgänglighet: PandasAI förenklar dataanalys och gör det tillgängligt för en bredare användargrupp. Vem som helst, oavsett teknisk bakgrund, kan använda det för att utvinna insikter från data och besvara affärsfrågor.
- Naturliga språkfrågor: Möjligheten att ställa frågor direkt och få svar från data med hjälp av naturliga språkfrågor gör datautforskning och analys mer användarvänlig. Den här funktionen gör att även icke-tekniska användare kan interagera med data effektivt.
- Agentchattfunktion: Chattfunktionen gör att användare kan interagera med data interaktivt, medan agentchattfunktionen utnyttjar tidigare chatthistorik för att ge kontextmedvetna svar. Detta främjar en dynamisk och konversationsbaserad metod för dataanalys.
- Datavisualisering: PandasAI tillhandahåller en rad datavisualiseringsalternativ, inklusive värmekartor, spridningsdiagram, stapeldiagram, cirkeldiagram, linjediagram med mera. Dessa visualiseringar hjälper till att förstå och presentera datamönster och trender.
- Tidsbesparande genvägar: Tillgången till genvägar och tidsbesparande funktioner effektiviserar dataanalysprocessen, vilket hjälper användarna att arbeta mer effektivt och ändamålsenligt.
- Filkompatibilitet: PandasAI stöder olika filformat, inklusive CSV, Excel, Google Sheets med mera. Den här flexibiliteten tillåter användare att arbeta med data från en mängd olika källor och format.
- Anpassade uppmaningar: Användare kan skapa anpassade uppmaningar med enkla instruktioner och Python-kod. Den här funktionen ger användarna möjlighet att anpassa sin interaktion med data för att passa specifika behov och frågor.
- Spara ändringar: Möjligheten att spara ändringar som görs i dataramar säkerställer att ditt arbete bevaras, och du kan återkomma och dela din analys när som helst.
- Anpassade svar: Alternativet att skapa anpassade svar gör det möjligt för användare att definiera specifika beteenden eller interaktioner, vilket gör verktyget ännu mer mångsidigt.
- Modellintegration: PandasAI stöder olika språkmodeller, inklusive Hugging Face-modellerna, Azure, Google Palm, Google VertexAI och LangChain. Den här integrationen förbättrar verktygets kapacitet och möjliggör avancerad bearbetning och förståelse av naturligt språk.
- Inbyggt LangChain-stöd: Det inbyggda stödet för LangChain-modeller utökar utbudet av tillgängliga modeller och funktioner, vilket ytterligare förbättrar djupet i analysen och de insikter som kan dras från data.
- Förståelse av namn: PandasAI visar förmågan att förstå sambandet mellan kolumnnamn och verklig terminologi. Till exempel, även om du använder termer som ”produktkategori” i stället för ”artikeltyp” i dina prompts, kan verktyget fortfarande ge relevanta och korrekta resultat. Den här flexibiliteten i att känna igen synonymer och kartlägga dem till lämpliga datakolumner förbättrar användarvänligheten och verktygets anpassningsförmåga till naturliga språkfrågor.
Även om PandasAI erbjuder flera fördelar kommer verktyget också med vissa begränsningar och utman