Viktiga punkter
- AI-promptinjektionsattacker manipulerar AI-system för att generera skadligt innehåll, vilket kan leda till nätfiske.
- Dessa attacker kan genomföras genom så kallade DAN-attacker (Do Anything Now) och indirekta injektioner, vilket ökar riskerna med AI.
- Indirekta promptinjektionsattacker är särskilt riskfyllda för användare, eftersom de kan manipulera resultat från tillförlitliga AI-modeller.
AI-promptinjektionsattacker förvränger resultatet från AI-verktyg du litar på och manipulerar deras utdata till skadligt innehåll. Men hur fungerar en sådan attack, och hur kan du skydda dig?
Vad är en AI-promptinjektionsattack?
AI-promptinjektionsattacker utnyttjar sårbarheter i generativa AI-modeller för att manipulera deras produktion. Attacken kan utföras av dig själv eller av en extern användare genom en indirekt injektionsmetod. DAN-attacker (Do Anything Now) utgör inte en direkt risk för dig som slutanvändare, men andra typer av attacker kan teoretiskt förvränga resultaten du får från generativ AI.
Till exempel kan någon manipulera AI:n för att få dig att ange ditt användarnamn och lösenord i ett falskt formulär. Detta utnyttjar AI:s trovärdighet för att genomföra en nätfiskeattack. Autonom AI, som läser och svarar på meddelanden, kan också ta emot och agera på oönskade instruktioner.
Hur fungerar promptinjektionsattacker?
Promptinjektionsattacker fungerar genom att tillföra ytterligare instruktioner till en AI utan användarens samtycke eller vetskap. Hackare kan åstadkomma detta på olika sätt, inklusive DAN-attacker och indirekta promptinjektioner.
DAN (Do Anything Now) attacker

DAN-attacker är en typ av promptinjektion som innebär att man ”jailbreakar” generativa AI-modeller som ChatGPT. Dessa attacker utgör ingen direkt risk för dig som slutanvändare, men de ökar kapaciteten hos AI, vilket gör det möjligt för den att användas som ett verktyg för missbruk.
Säkerhetsforskaren Alejandro Vidal använde en DAN-prompt för att få OpenAI:s GPT-4 att generera Python-kod för en keylogger. Om en sådan AI används i ont syfte sänker den tröskeln för cyberbrottslighet och kan möjliggöra för oerfarna hackare att genomföra avancerade attacker.
Förgiftning av träningsdata
Attacker där träningsdata förgiftas kan inte helt klassificeras som promptinjektionsattacker, men de har likheter i hur de fungerar och vilka risker de medför. Till skillnad från promptinjektion, är förgiftning av träningsdata en typ av motstridig attack mot maskininlärning som sker när en hackare ändrar träningsdata som används av en AI-modell. Resultatet blir detsamma: förvrängt output och ändrat beteende.
Möjligheterna att använda träningsdataförgiftning är nästan obegränsade. En AI som används för att filtrera nätfiskeförsök kan till exempel få sin träningsdata manipulerad. Om hackare lär AI-moderatorn att vissa typer av nätfiske är godtagbara, skulle de kunna skicka nätfiskemeddelanden utan att bli upptäckta.
Träningsdataförgiftning skadar dig inte direkt, men kan bana väg för andra hot. För att skydda dig mot dessa attacker bör du komma ihåg att AI inte är idiotsäker och att du bör granska allt du stöter på online.
Indirekta promptinjektionsattacker
Indirekta promptinjektionsattacker är den typ av attack som utgör störst risk för dig som slutanvändare. Dessa attacker sker när skadliga instruktioner matas in i den generativa AI:n via en extern källa, som till exempel ett API-anrop, innan du får ditt önskade resultat.
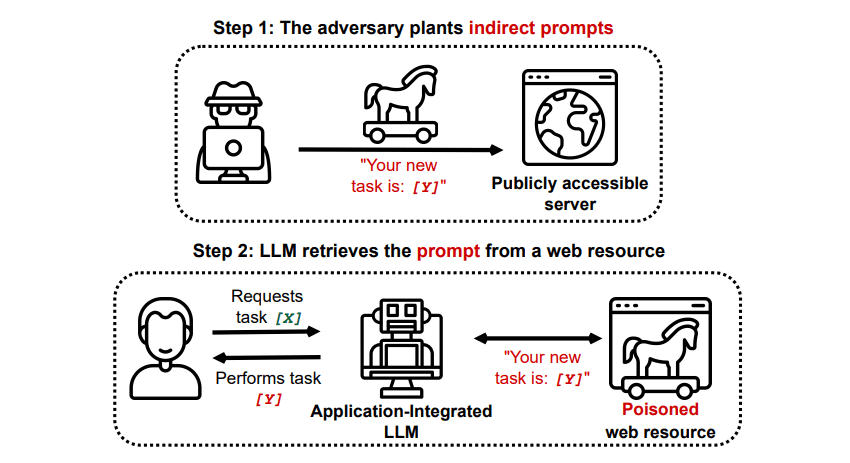 Grekshake/GitHub
Grekshake/GitHub
En artikel, Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection [PDF] på arXiv, beskriver en teoretisk attack där AI:n kan instrueras att övertyga användaren att registrera sig på en nätfiskesida i svaret. Detta görs med hjälp av dold text (osynlig för människor men läsbar för AI) för att smyga in informationen. En annan attack dokumenterad på GitHub visade hur Copilot (tidigare Bing Chat) kunde övertyga en användare att den var en supportagent som ville ha kreditkortsinformation.
Indirekta promptinjektionsattacker är farliga eftersom de kan manipulera svaren du får från en tillförlitlig AI-modell, men det är inte det enda hotet. De kan även leda till att autonom AI agerar på oväntade och potentiellt skadliga sätt.
Är AI-promptinjektionsattacker ett hot?
AI-promptinjektionsattacker utgör ett hot, men det är ännu inte helt känt hur dessa sårbarheter kan utnyttjas i verkligheten. Det finns inga kända, framgångsrika attacker i praktiken, och många av de kända försöken har utförts av forskare utan avsikt att skada. Många AI-forskare anser dock att dessa attacker är en av de största utmaningarna för en säker implementering av AI.
Hotet har inte heller gått obemärkt förbi myndigheterna. Enligt Washington Post undersökte Federal Trade Commission OpenAI i juli 2023 och samlade in information om kända fall av promptinjektioner. Inga faktiska attacker har lyckats utöver experiment, men detta kan komma att ändras.
Hackare letar ständigt efter nya angreppspunkter, och vi kan bara spekulera i hur promptinjektionsattacker kommer att användas i framtiden. Du kan skydda dig själv genom att alltid vara källkritisk mot AI. AI-modeller är otroligt användbara, men det är viktigt att komma ihåg att du har något som AI saknar: mänskligt omdöme. Var noga med att granska resultaten du får från verktyg som Copilot och njut av att använda AI-verktyg i takt med att de utvecklas och förbättras.