Under sommaren 2023 introducerade Meta Llama 2, en uppdaterad version av deras språkmodell. Denna nya iteration är förfinad med 40 % fler tokens jämfört med den ursprungliga Llama-modellen. Dessutom har kontextlängden fördubblats, vilket gör den betydligt mer avancerad än andra modeller med öppen källkod på marknaden. Det snabbaste sättet att använda Llama 2 är genom ett API via en onlineplattform. Men för att få den optimala prestandan är det bäst att installera och köra Llama 2 direkt på din egen dator.
Med detta i åtanke har vi utvecklat en detaljerad guide för hur du använder Text-Generation-WebUI för att lokalt ladda en kvantiserad Llama 2 LLM på din dator.
Varför välja att installera Llama 2 lokalt?
Det finns flera anledningar till varför man kan föredra att köra Llama 2 direkt. Vissa gör det av integritetsskäl, andra för anpassningsmöjligheter och ytterligare andra för offlineanvändning. Om du forskar, finjusterar eller integrerar Llama 2 i dina egna projekt kan det vara mindre lämpligt att använda modellen via ett API. Den stora fördelen med att köra en LLM lokalt på din dator är att minska beroendet av externa AI-verktyg. Du kan använda AI när som helst och var som helst utan att oroa dig för att potentiellt känslig information hamnar hos företag eller andra organisationer.
Med det sagt, låt oss nu gå igenom steg-för-steg-guiden för att installera Llama 2 lokalt.
För att underlätta processen kommer vi att använda ett installationsprogram med ett klick för Text-Generation-WebUI (programmet som används för att ladda Llama 2 med ett grafiskt gränssnitt). Men för att det här installationsprogrammet ska fungera, behöver du först ladda ner och installera Visual Studio 2019 Build Tool, samt de nödvändiga resurserna.
Ladda ner: Visual Studio 2019 (Gratis)
- Fortsätt och ladda ner Community-utgåvan av programmet.
- Installera nu Visual Studio 2019 och öppna programmet. När det är öppet, markera ”Desktop-utveckling med C++” och klicka på installera.
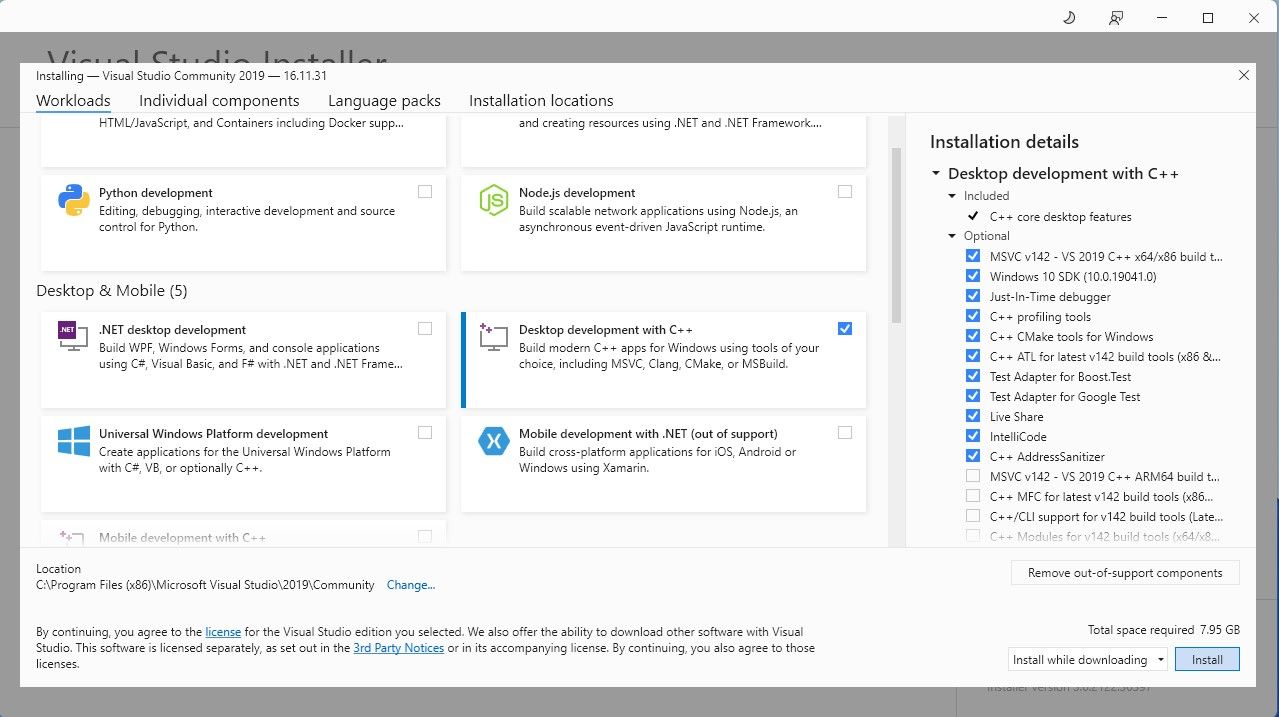
Nu när ”Desktop-utveckling med C++” är installerat är det dags att ladda ner installationsprogrammet för Text-Generation-WebUI med ett klick.
Steg 2: Installera Text-Generation-WebUI
Installationsprogrammet för Text-Generation-WebUI med ett klick är ett skript som automatiskt skapar de nödvändiga mapparna, konfigurerar Conda-miljön och installerar alla nödvändiga komponenter för att köra en AI-modell.
För att installera skriptet, ladda ner installationsprogrammet genom att klicka på ”Kod” > ”Ladda ner ZIP”.
Ladda ner: Text-Generation-WebUI Installer (Gratis)
- När du har laddat ner filen, packa upp ZIP-filen till en valfri plats och öppna sedan den extraherade mappen.
- Bläddra ner i mappen och leta efter lämpligt startprogram för ditt operativsystem. Kör programmet genom att dubbelklicka på motsvarande skript.
- Om du använder Windows, välj batchfilen ”start_windows”.
- För macOS, välj shell-skriptet ”start_macos”.
- För Linux, välj shell-skriptet ”start_linux”.
- Ditt antivirusprogram kan eventuellt ge en varning. Det är normalt. Varningen är en falsk positiv varning som visas när man kör en batchfil eller ett skript. Klicka på ”Kör ändå”.
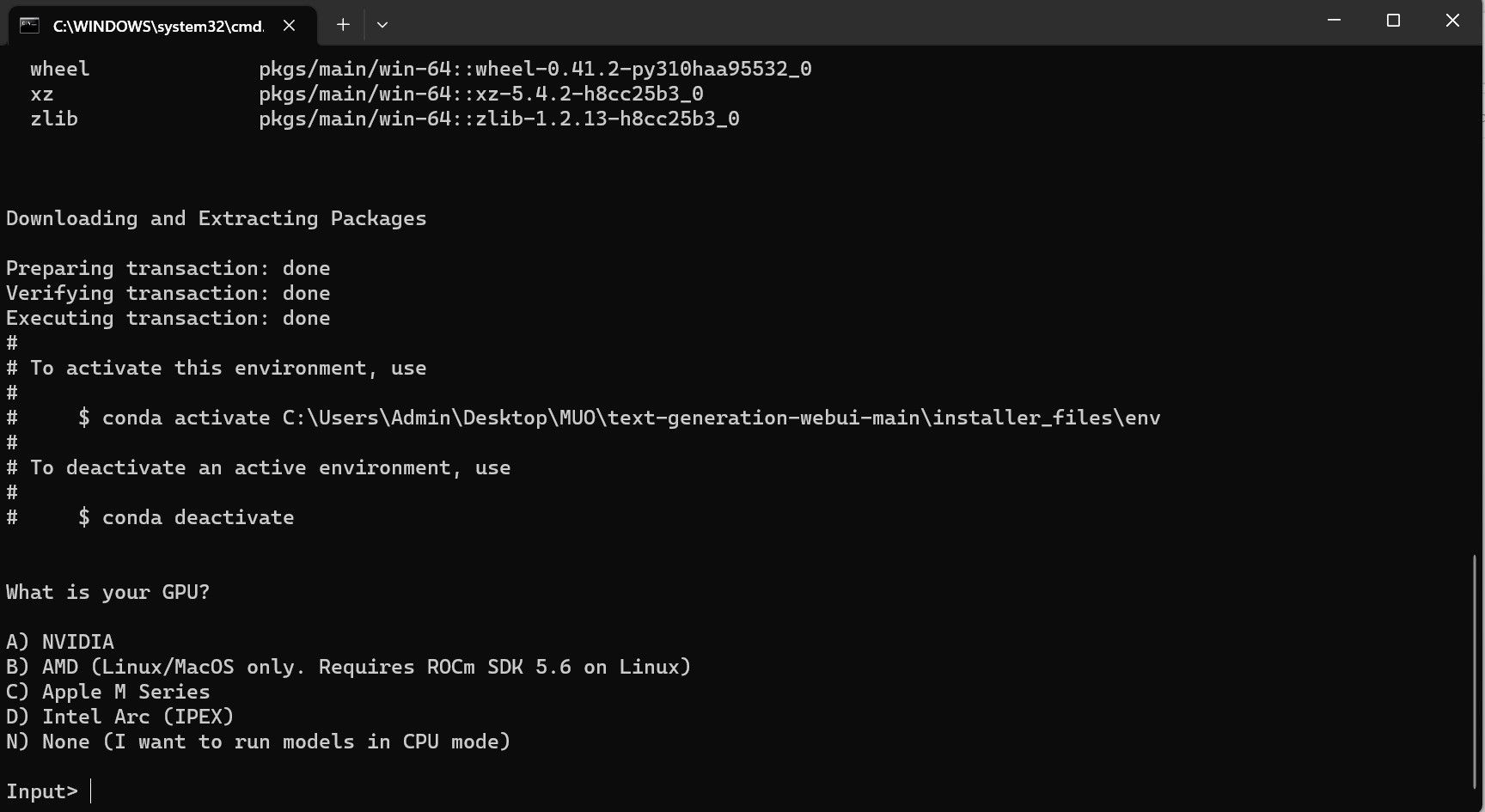
- Ett terminalfönster öppnas och installationen startar. Installationen pausar tillfälligt och frågar vilken typ av GPU du använder. Välj den typ av GPU som är installerad på din dator och tryck på ”Enter”. Om du inte har ett dedikerat grafikkort, välj ”Ingen (jag vill köra modeller i CPU-läge)”. Kom ihåg att körning i CPU-läge är mycket långsammare jämfört med att köra modellen med en dedikerad GPU.
- När installationen är klar kan du starta Text-Generation-WebUI lokalt. Det gör du genom att öppna din webbläsare och ange den angivna IP-adressen i adressfältet.
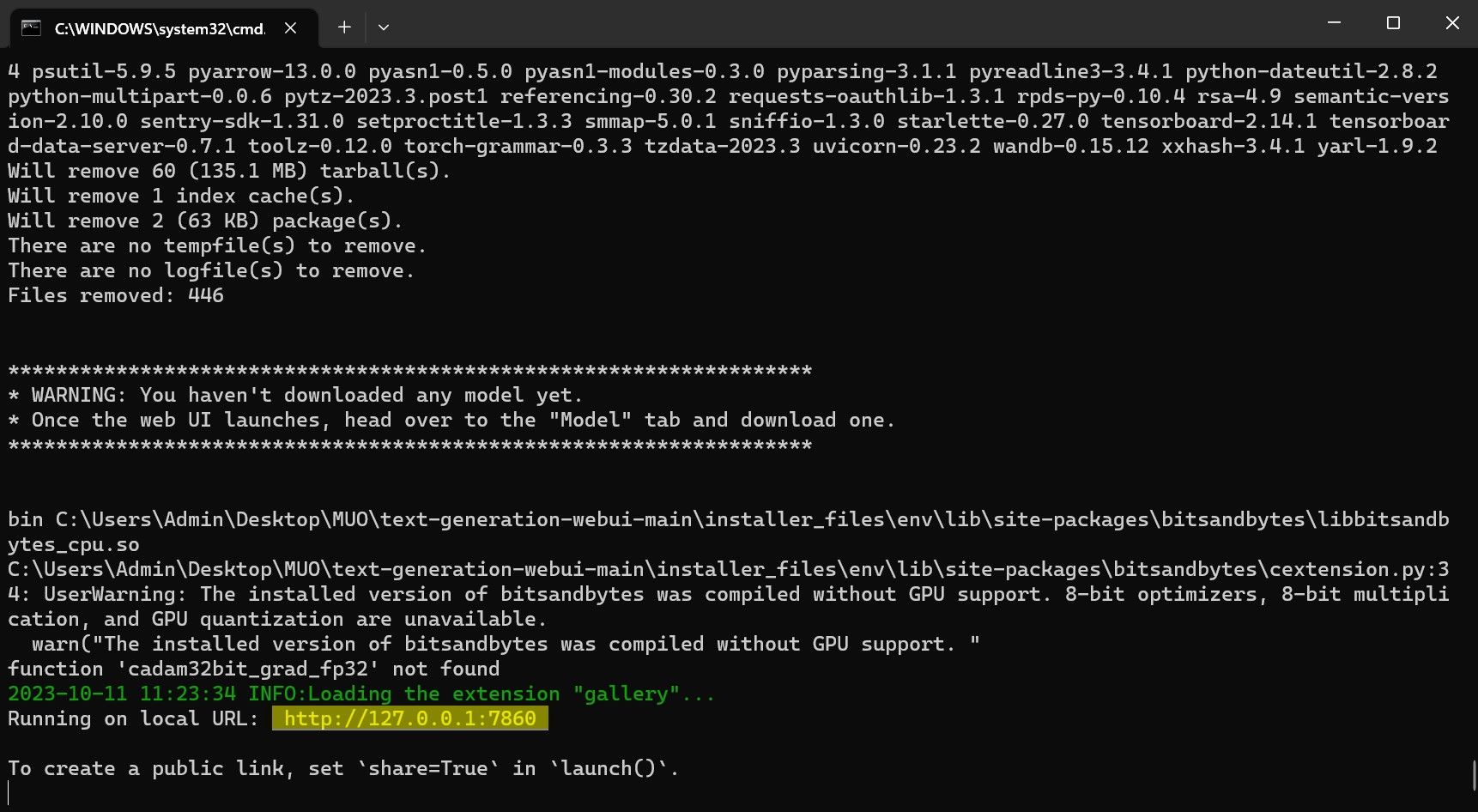
- WebUI är nu redo att användas.
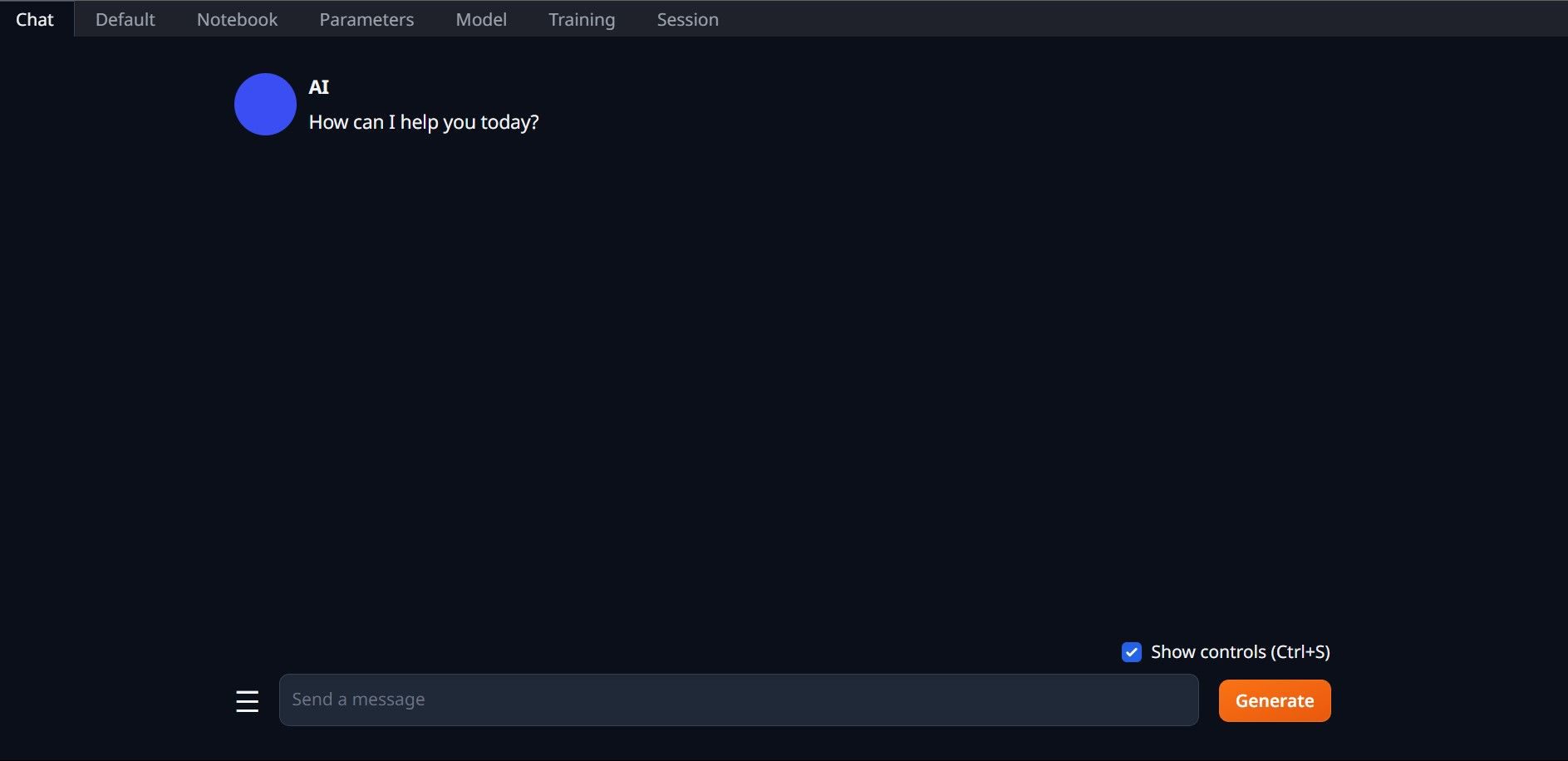
Programmet är dock bara en modell-lastare. Nu måste vi ladda ner Llama 2 för att kunna starta den i programmet.
Steg 3: Ladda ner Llama 2-modellen
Det finns flera faktorer att tänka på när du bestämmer vilken version av Llama 2 du ska använda. Dessa inkluderar parametrar, kvantisering, hårdvaruoptimering, storlek och användningsområde. All denna information finns i modellens namn.
- Parametrar: Antalet parametrar som används för att träna modellen. Fler parametrar ger mer avancerade modeller, men det påverkar också prestandan.
- Användning: Kan vara antingen ”standard” eller ”chatt”. En chattmodell är optimerad för att användas som en chatbot som ChatGPT, medan standardmodellen är mer allmän.
- Hårdvaruoptimering: Avser vilken typ av hårdvara som är bäst lämpad för att köra modellen. GPTQ innebär att modellen är optimerad för att köras på ett dedikerat grafikkort, medan GGML är optimerad för att köras på en CPU.
- Kvantisering: Anger precisionen i vikter och aktiveringar i en modell. För inferens är en precision på q4 optimal.
- Storlek: Avser den specifika modellens filstorlek.
Observera att namnen kan vara organiserade på olika sätt och att informationen inte alltid är identisk. Den här typen av namngivningskonvention är dock ganska vanlig i HuggingFace Model-biblioteket, så det är fortfarande bra att förstå.

I det här exemplet kan modellen identifieras som en medelstor Llama 2-modell som tränats med 13 miljarder parametrar, optimerad för chatt-inferens med hjälp av ett dedikerat grafikkort.
För de som kör med ett dedikerat grafikkort, välj en GPTQ-modell, medan de som kör på en CPU bör välja GGML. Om du vill chatta med modellen som med ChatGPT, välj en chattmodell, men om du vill experimentera med modellens fulla kapacitet, använd standardmodellen. När det gäller parametrar, kom ihåg att användning av större modeller ger bättre resultat, men också minskar prestandan. Jag rekommenderar att börja med en 7B-modell. När det gäller kvantisering, använd q4, eftersom det är lämpligt för inferens.
Ladda ner: GGML (Gratis)
Ladda ner: GPTQ (Gratis)
Nu när du vet vilken version av Llama 2 du behöver, fortsätt och ladda ner den modell du vill använda.
I mitt fall, eftersom jag kör det här på en ultrabook, kommer jag att använda en GGML-modell som är finjusterad för chatt, llama-2-7b-chat-ggmlv3.q4_K_S.bin.
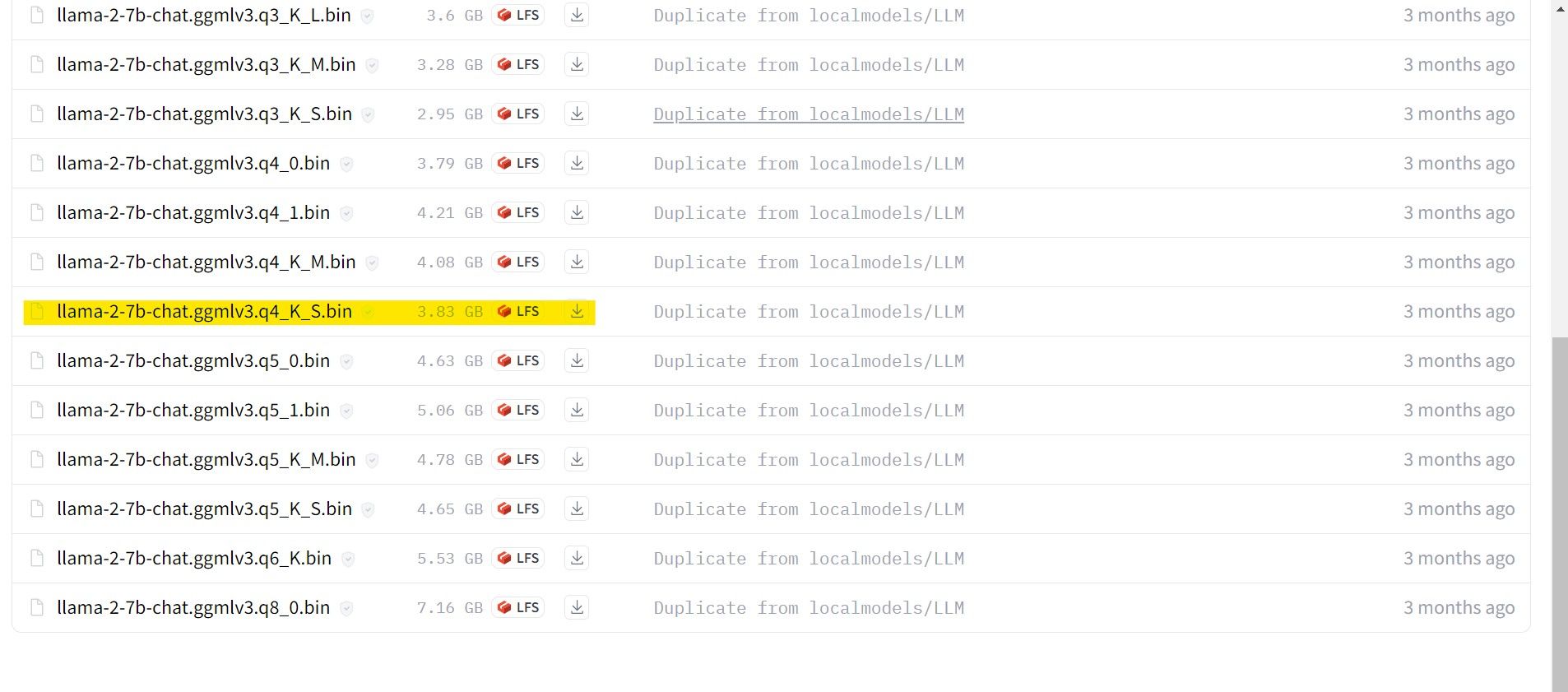
När nedladdningen är klar, placera modellen i mappen ”text-generation-webui-main > models”.
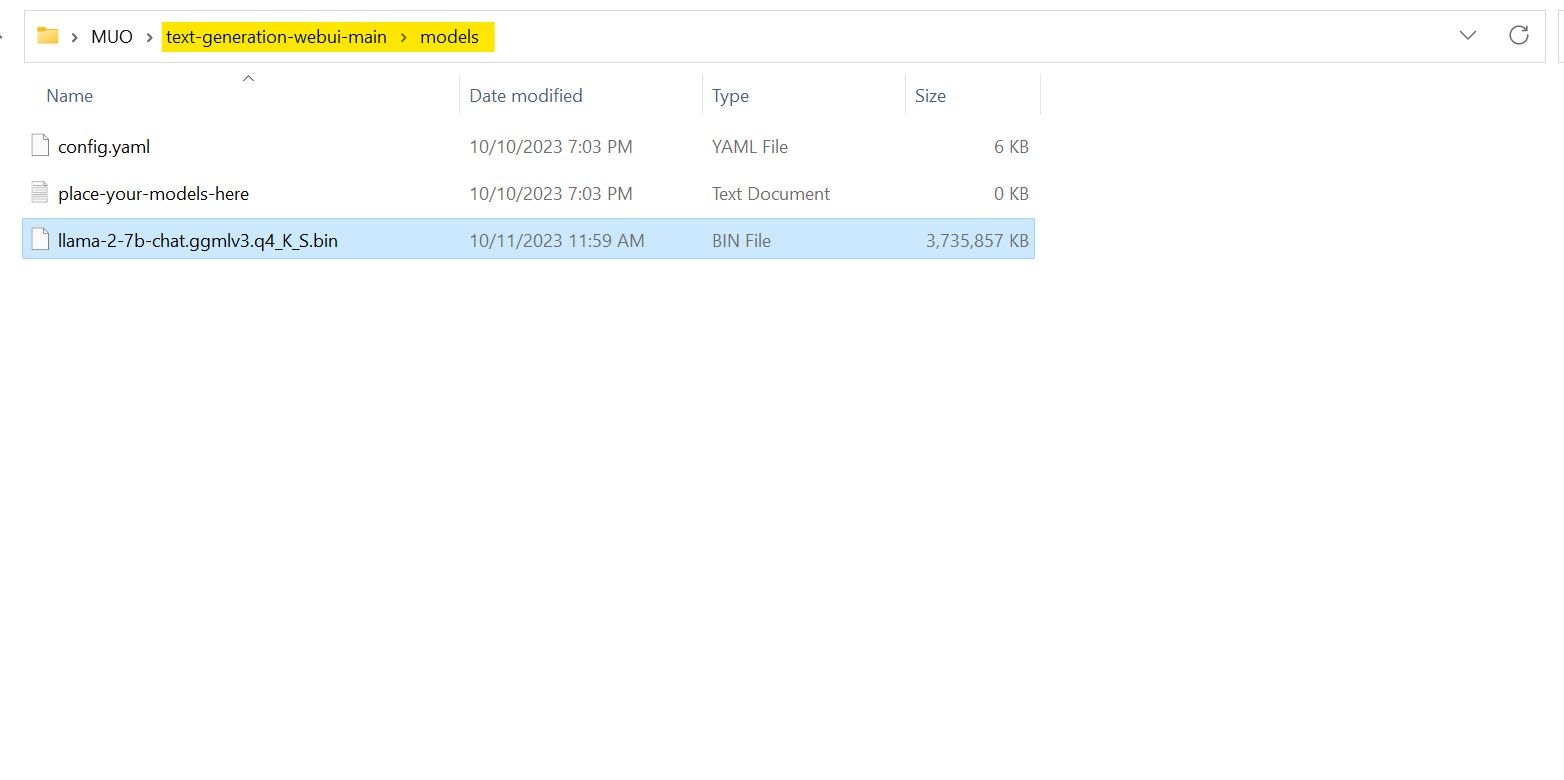
Nu när du har laddat ner din modell och placerat den i rätt mapp, är det dags att konfigurera modell-lastaren.
Steg 4: Konfigurera Text-Generation-WebUI
Låt oss nu gå vidare till konfigurationsfasen.
- Öppna Text-Generation-WebUI igen genom att köra filen ”start_(ditt operativsystem)” (se tidigare steg).
- Klicka på ”Modell” i flikarna högst upp i gränssnittet. Klicka på uppdateringsknappen i rullgardinsmenyn ”Modell” och välj din modell.
- Klicka sedan på rullgardinsmenyn ”Modell-lastare” och välj ”AutoGPTQ” för de som använder en GTPQ-modell, och ”ctransformers” för de som använder en GGML-modell. Klicka slutligen på ”Ladda” för att ladda din modell.
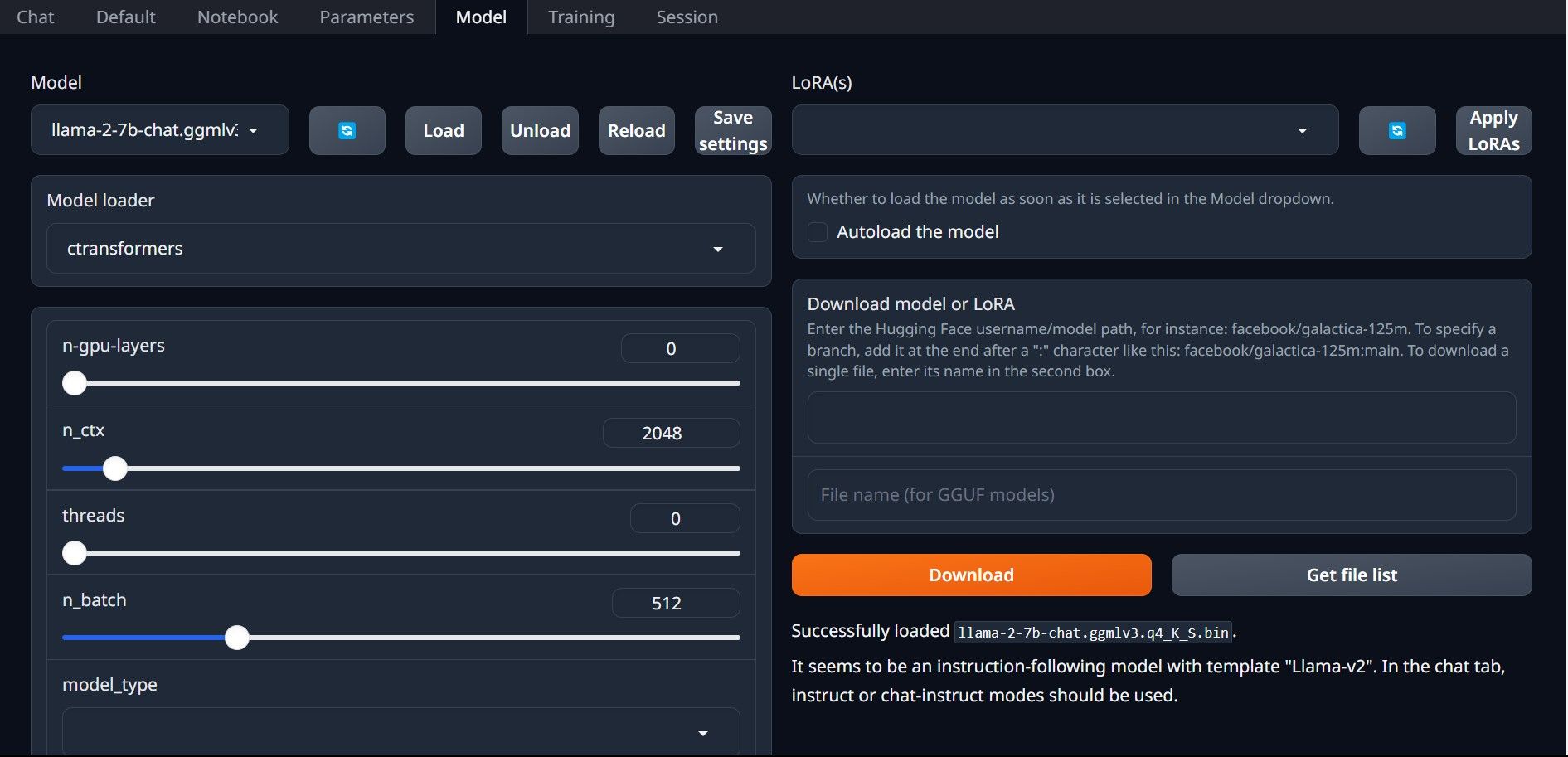
- För att använda modellen, öppna fliken ”Chat” och börja testa den.
Grattis, du har nu framgångsrikt laddat Llama 2 på din lokala dator!
Utforska andra LLM:er
Nu när du vet hur du kör Llama 2 direkt på din dator med Text-Generation-WebUI, bör du även kunna köra andra LLM:er utöver Llama. Kom ihåg namnkonventionerna för modeller och att endast kvantiserade versioner av modeller (vanligtvis q4 precision) kan laddas på vanliga datorer. Många kvantiserade LLM:er finns tillgängliga på HuggingFace. Om du vill utforska andra modeller, sök efter ”TheBloke” i HuggingFaces modellbibliotek, där du hittar många tillgängliga modeller.