Under de senaste åren har användningen av Python inom datavetenskap upplevt en remarkabel tillväxt, en trend som fortsätter att accelerera varje dag.
Datavetenskap representerar ett omfattande forskningsområde med flera specialiserade grenar. Dataanalys är utan tvekan ett av de mest avgörande av dessa områden. Oavsett en individs kompetensnivå inom datavetenskap, har det blivit allt viktigare att inneha grundläggande kunskaper inom detta område.
Vad innebär dataanalys?
Dataanalys syftar på processen att rensa och transformera stora mängder ostrukturerad eller oorganiserad data. Huvudmålet är att extrahera relevant insikt och information som kan underlätta välgrundade beslut.
Ett flertal verktyg används för dataanalys, inklusive Python, Microsoft Excel, Tableau och SAS. I denna artikel kommer vi dock att fokusera på hur dataanalys utförs i Python, med särskild uppmärksamhet på användningen av Python-biblioteket Pandas.
Vad är Pandas?
Pandas är ett kostnadsfritt Python-bibliotek med öppen källkod som är avsett för datamanipulation och databearbetning. Det är känt för sin snabbhet och effektivitet, och det tillhandahåller funktioner för att ladda olika typer av data i minnet. Pandas möjliggör omformning, delning, indexering och gruppering av olika datastrukturer.
Datastrukturer i Pandas
Pandas använder sig av tre primära datastrukturer:
Det mest effektiva sättet att förstå förhållandet mellan dessa tre strukturer är att se dem som skiktade: En DataFrame består av flera serier, och en panel består av flera DataFrames.
- En serie är en endimensionell array.
- En kombination av flera serier skapar en tvådimensionell DataFrame.
- En samling av flera DataFrames resulterar i en tredimensionell panel.
Den datastruktur vi kommer att fokusera på i denna artikel är den tvådimensionella DataFramen, som också är det vanligaste sättet att representera data som vi kan stöta på.
Dataanalys med Pandas
För att följa exemplen i denna artikel krävs ingen installation. Vi kommer att använda verktyget Colab, som utvecklats av Google. Colab är en molnbaserad Python-miljö som är speciellt utformad för dataanalys, maskininlärning och AI. Det är i princip en molnbaserad Jupyter Notebook som levereras med nästan alla nödvändiga Python-paket som en dataforskare behöver.
Besök https://colab.research.google.com/notebooks/intro.ipynb. Du borde se en startsida.
I menyn längst upp till vänster, klicka på ”Fil” och sedan på ”Ny anteckningsbok”. En ny Jupyter Notebook-sida ska nu öppnas i din webbläsare. Det första steget är att importera Pandas till vår arbetsmiljö, vilket görs med följande kod:
import pandas as pdI detta exempel kommer vi att använda en datauppsättning med huspriser för vår dataanalys. Du kan ladda ner datauppsättningen här. Vårt första mål är att ladda in denna datauppsättning i vår miljö.
Detta görs med följande kod i en ny cell:
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ', sep=',')Funktionen .read_csv används för att läsa en CSV-fil, och vi inkluderar parametern sep=',' för att ange att filen är kommaseparerad.
Observera att vi lagrar den inlästa CSV-filen i variabeln df.
I Jupyter Notebook behöver vi inte använda funktionen print(). Vi kan helt enkelt skriva in ett variabelnamn i en cell, och Jupyter Notebook kommer att visa dess innehåll.
Testa att skriva df i en ny cell och köra den. Detta kommer att visa alla data i vår datauppsättning som en DataFrame.
Men ibland vill vi inte se alla data; vi kanske bara vill se början eller slutet tillsammans med kolumnnamnen. För att visa de fem första raderna använder vi df.head(), och för att visa de fem sista använder vi df.tail(). Utdata från dessa funktioner ser ut ungefär så här:
Om vi vill utforska relationerna mellan dessa många rader och kolumner, kan vi använda funktionen .describe().
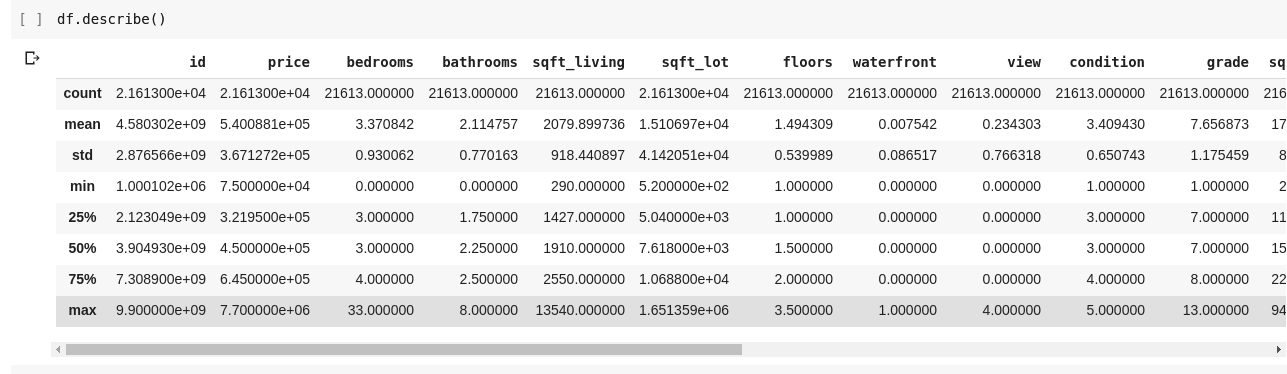
Genom att köra df.describe() får vi följande utdata:
Vi kan se att .describe() ger oss medelvärdet, standardavvikelsen, minimi- och maximivärden samt percentilerna för varje kolumn i DataFrame. Det är ett mycket användbart verktyg.
Vi kan också kontrollera formen på vår 2D DataFrame för att få reda på antalet rader och kolumner med hjälp av df.shape, som returnerar en tupel i formatet (rader, kolumner).
Vi kan också se namnen på alla kolumner i vår DataFrame med df.columns.
Men vad händer om vi bara vill välja ut en viss kolumn och visa dess data? Detta görs på ett sätt som liknar hur man jobbar med dictionaries. Skriv följande kod i en ny cell och kör den:
df['price ']Ovanstående kod visar priskolumnen. Vi kan spara den i en ny variabel:
price = df['price']Nu kan vi utföra alla de DataFrame-åtgärder som vi kan göra på vår prisvariabel, eftersom den är en delmängd av en DataFrame. Vi kan till exempel använda df.head() eller df.shape.
Vi kan också välja flera kolumner genom att skicka en lista med kolumnnamn till df:
data = df[['price ', 'bedrooms']]Ovanstående kod väljer kolumnerna ”price” och ”bedrooms”. Om vi skriver data.head() i en ny cell får vi följande utdata:
De föregående exemplen visar hur vi kan extrahera kolumner. Men vad händer om vi vill extrahera en delmängd av både rader och kolumner från vår datauppsättning? Detta kan göras med .iloc, som indexerar data på ett sätt som liknar Python-listor. Ett exempel kan vara:
df.iloc[50: , 3]Detta returnerar den 3:e kolumnen från den 50:e raden till slutet. Det är ett smidigt sätt att arbeta med data, precis som att slica listor i Python.
Låt oss nu utforska några mer intressanta funktioner. Vår datauppsättning med huspriser innehåller en kolumn som visar priset för varje hus och en annan som visar antalet sovrum. Huspris är en kontinuerlig variabel, och det är ovanligt att två hus har exakt samma pris. Antalet sovrum är å andra sidan en diskret variabel, och det kan finnas flera hus med två, tre, fyra eller fler sovrum.
Antag att vi vill samla alla hus med samma antal sovrum och hitta det genomsnittliga priset för varje grupp. I Pandas är detta relativt enkelt att åstadkomma:
df.groupby('bedrooms ')['price '].mean()Denna kod grupperar DataFrame först baserat på identiskt antal sovrum med hjälp av df.groupby()-funktionen. Sedan specificerar vi att vi bara är intresserade av priskolumnen och använder .mean()-funktionen för att beräkna medelvärdet för varje hus i den gruppen.
Men tänk om vi vill visualisera dessa resultat? Vi kanske vill undersöka hur det genomsnittliga priset varierar beroende på antal sovrum. För att göra det kopplar vi koden till funktionen .plot():
df.groupby('bedrooms ')['price '].mean().plot()Detta ger en visualisering av datan:
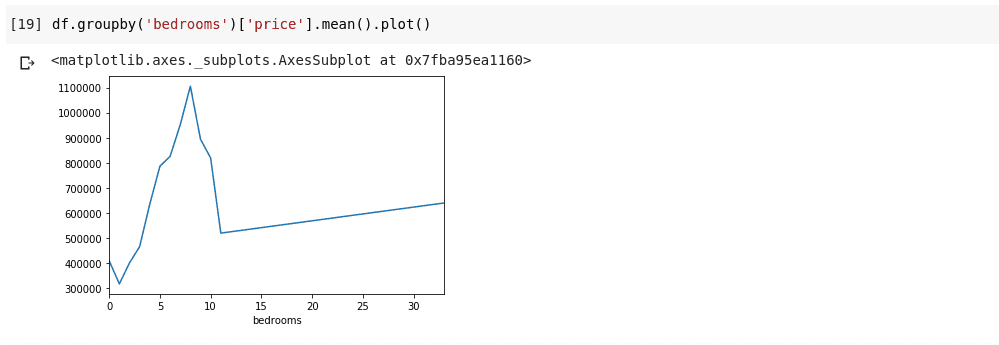
Denna graf visar oss vissa trender i datan. Den horisontella axeln visar olika antal sovrum (Observera att flera hus kan ha samma antal sovrum), och den vertikala axeln visar det genomsnittliga priset för hus med det motsvarande antalet sovrum på den horisontella axeln. Vi kan direkt se att hus med 5 till 10 sovrum kostar betydligt mer än hus med 3 sovrum. Det blir också tydligt att hus med 7 eller 8 sovrum kostar mycket mer än hus med 15, 20 eller till och med 30 rum.
Information som denna illustrerar varför dataanalys är så värdefullt. Vi kan extrahera insikter från data som annars skulle vara svåra att upptäcka.
Hantering av saknad data
Antag att jag genomför en undersökning med flera frågor. Jag delar en länk till undersökningen med tusentals människor för att samla in deras feedback. Mitt mål är att genomföra en dataanalys baserad på dessa data för att få fram värdefulla insikter.
En del respondenter kan känna sig obekväma med att svara på vissa frågor och lämna dem tomma. Det här kan bli ett problem om undersökningen samlar in numeriska data, eftersom saknade värden kan leda till felaktigheter i den slutgiltiga analysen. Jag måste hitta ett sätt att hitta och ersätta dessa saknade värden med rimliga alternativ.
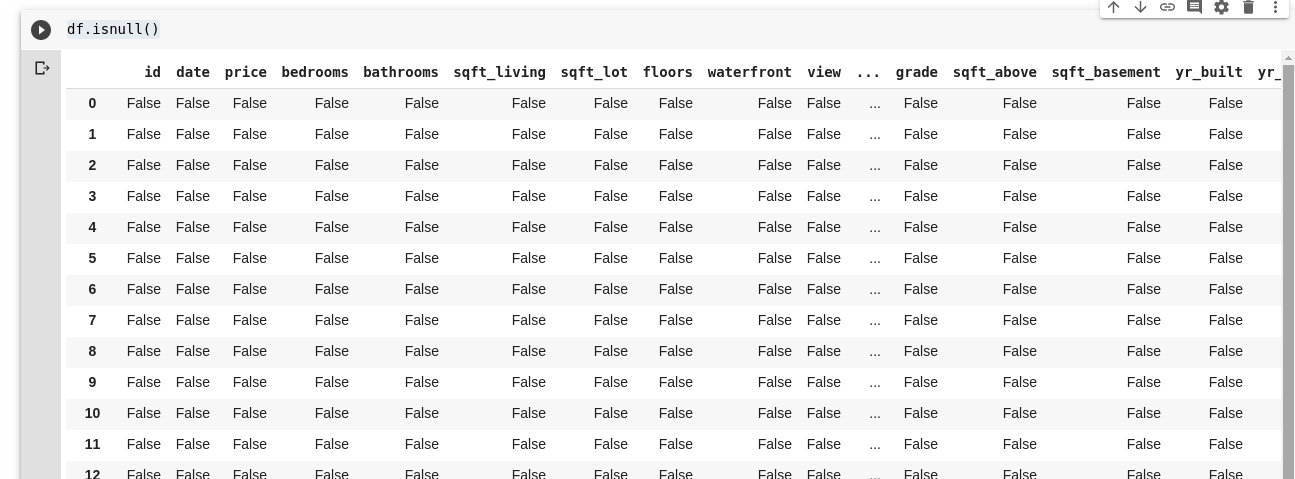
Pandas tillhandahåller funktionen isnull() för att hitta saknade värden i en DataFrame.
isnull()-funktionen kan användas på följande sätt:
df.isnull()Detta returnerar en DataFrame med booleska värden som indikerar om datan på en specifik plats saknas eller inte. Utdata ser ut ungefär så här:
Vi behöver kunna ersätta dessa saknade värden. Vanligtvis väljer man att ersätta dem med antingen noll, medelvärdet av all data, eller medelvärdet av närliggande data, beroende på dataforskarens preferenser och syftet med analysen.
För att fylla i alla saknade värden i en DataFrame använder vi funktionen .fillna():
df.fillna(0)I detta exempel fyller vi alla tomma datapunkter med värdet noll. Vi kan ersätta dem med valfritt värde vi önskar.
Vikten av dataanalys kan inte underskattas. Den låter oss dra slutsatser direkt från våra data. Dataanalys kallas ofta den ”nya oljan” för den digitala ekonomin.
Alla exempel i denna artikel finns tillgängliga här.
För att lära dig mer om dataanalys, kan du kolla in denna onlinekurs om dataanalys med Python och Pandas.