Grafdatabaser: En Djupdykning i Deras Användning och Topplösningar
Grafdatabaser är utformade för att effektivt hantera och bearbeta data som är starkt sammankopplade. De utmärker sig i situationer där relationerna mellan datapunkter är lika viktiga som själva datan. Men hur vet man när en grafdatabas är rätt val? Denna artikel ger en översikt över grafdatabaser, deras tillämpningar och jämförelser med traditionella relationsdatabaser, samt presenterar några av de ledande lösningarna på marknaden.
I den digitala tidsåldern beskrivs ofta data som ”den nya oljan”. Organisationers framgång beror i hög grad på deras förmåga att effektivt lagra och använda data. Varje dag genereras enorma mängder data, vilket kräver system som är både feltoleranta och effektiva för lagring och hantering. Inledningsvis var relationsdatabaser det primära valet, men med tiden växte behovet av att hantera andra datatyper, som video, ljud och bilder, vilket ledde till utvecklingen av SQL, NoSQL, Hadoop och grafdatabaser, var och en med sina specifika användningsområden och förmågor att hantera olika dataformat. Grafdatabaser har dykt upp som en lösning för att förenkla hanteringen av data och möjliggöra effektiv lagring.
Grafdatabaser i Detalj
En graf är en datastruktur som består av noder (punkter) och kanter (relationer) mellan dessa noder. En grafdatabas utnyttjar denna struktur för att lagra information, där noder representerar enheter och kanter deras relationer. Denna modell är särskilt användbar för att hantera många-till-många-relationer och göra realtidsfrågor effektivare.
Det finns två huvudsakliga modeller för grafdatabaser: egenskapsgrafer och RDF-grafer. Egenskapsgrafer är vanliga för analys och sökningar, medan RDF-grafer används för dataintegration. RDF-grafer representeras i trippelform, bestående av subjekt, predikat och objekt. I grafdatabaser lagras data i noder, och relationerna mellan dessa data representeras av kanter. Dessa kanter kan vara antingen riktade (enkelriktade) eller oriktade (dubbelriktade).
Frågebehandling i grafdatabaser sker genom att navigera genom grafen. Olika algoritmer används för att hitta vägar mellan noder, mäta avstånd, hitta mönster och identifiera kluster. Dessa algoritmer gör det möjligt att besvara komplexa frågor effektivt.
Tillämpningsområden för Grafdatabaser
Grafdatabaser har en mängd olika användningsområden:
- Bedrägeribekämpning: Genom att kartlägga relationer mellan personer, adresser och IP-adresser kan man identifiera misstänkt aktivitet och upptäcka bedrägerier.
- Sociala medier: Grafdatabaser används för att generera rekommendationer för vänner och innehåll genom att analysera nätverk av användare och deras interaktioner.
- Nätverkskartläggning: De används för att effektivt hantera och lagra information om infrastruktur, konfigurationsobjekt och nätverkstopologier.
Grafdatabaser kontra Relationsdatabaser
En viktig skillnad mellan grafdatabaser och relationsdatabaser ligger i hur data och relationer lagras. I en grafdatabas ersätts tabeller med noder och kanter. Relationerna mellan datapunkter lagras direkt på kanterna. I relationsdatabaser lagras relationer med hjälp av främmande nycklar.
I grafdatabaser är det enklare att hämta data och ställa frågor utan komplicerade sammankopplingar, vilket är en fördel jämfört med relationsdatabaser. Relationsdatabaser är bäst lämpade för transaktioner, medan grafdatabaser excellerar i applikationer med komplexa relationer och stora datamängder. Grafdatabaser är flexibla och stöder strukturerad, semistrukturerad och ostrukturerad data, medan relationsdatabaser kräver ett fast schema. Dessutom anpassar sig grafdatabaser till dynamiska krav, medan relationsdatabaser oftast används för statiska problem.
| Egenskap | Grafdatabas | Relationsdatabas |
| Datastruktur | Noder och kanter | Tabeller med rader och kolumner |
| Relationer | Lagras direkt på kanter | Lagras med främmande nycklar |
| Frågespråk | Enkla frågor utan komplexa kopplingar | Kan kräva komplexa kopplingar |
| Användningsfall | Relationstunga applikationer | Transaktionsorienterade applikationer |
| Datatyper | Strukturerad, semistrukturerad, ostrukturerad | Fast schema |
| Flexibilitet | Dynamisk anpassning | Ofta statisk |
Ledande Grafdatabaslösningar
Här är några av de mest framstående grafdatabaslösningarna:
Cayley
Cayley är en open source-grafdatabas utvecklad under Apache 2.0-licensen. Den är byggd med Go och hanterar länkad data, och utgjorde grunden för Googles Freebase och kunskapsgraf. Cayley stöder flera frågespråk, inklusive MQL och Javascript, med ett Gremlin-baserat grafobjekt.
Cayley är enkel att använda, snabb och har en modulär design. Den kan integreras med olika backend-lager som LevelDB, MongoDB och Bolt. Den stöder olika API:er från tredje part skrivna i språk som Java, .NET, Rust och Javascript. Cayley kan distribueras med Docker och Kubernetes och används flitigt inom IT, mjukvaruutveckling och finansiella tjänster.
Amazon Neptune
Amazon Neptune är en molntjänst som utmärker sig med hantering av stora, sammankopplade datamängder. Den är pålitlig, säker, helt hanterad och stöder öppna graf-API:er. Neptune kan lagra miljarder relationer och svara på frågor med låg latens.
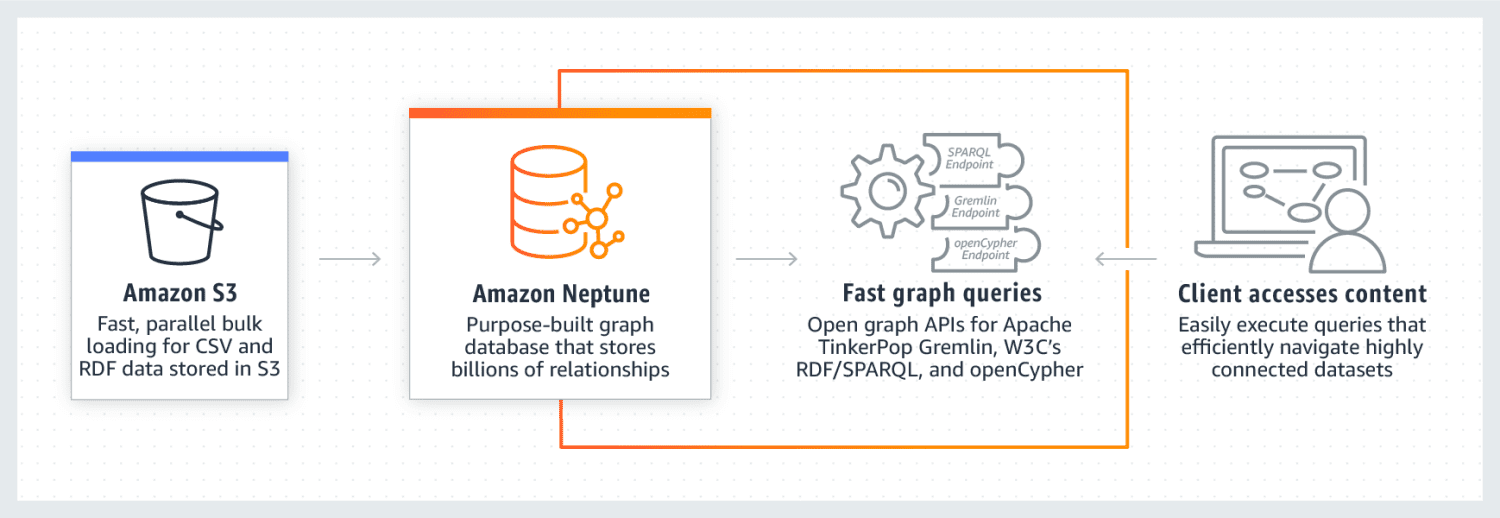
Neptunes datamodell består av fyra element: subjekt (S), predikat (P), objekt (O) och graf (G), som används för att lagra information om källnoder, målnoder, relationerna dem emellan samt deras egenskaper. Neptune använder en cache för att öka prestandan för läsfrågor. Data lagras i DB-kluster, som består av en primär DB-instans och läsrepliker. Neptune erbjuder också robust säkerhet med hjälp av IAM-autentisering, SSL-certifiering och loggövervakning. Data kan enkelt migreras från andra källor till Amazon Neptune, och den erbjuder repliker och säkerhetskopiering för att säkerställa motståndskraft. Företag som använder Neptune inkluderar Herren, Onedot och Hi Platform.
Neo4j
Neo4j är en skalbar, säker och pålitlig grafdatabas byggd i Java med Cypher som frågespråk. Den använder Bolt-protokollet och hanterar transaktioner via en HTTP-slutpunkt. Neo4j ger snabbare svar på frågor jämfört med traditionella relationsdatabaser, utan de komplexa kopplingar som dessa kräver. Optimeringen fungerar bra även med stora och sammankopplade datamängder. Neo4j kombinerar fördelarna med graflagring med ACID-egenskaperna hos en relationsdatabas.

Neo4j stöder olika språk som Java, .NET och Python via drivrutiner och används också inom dataanalys, grafdatavetenskap och maskininlärning. Neo4j Aura DB är en feltolerant molngrafdatabas. Företag som Microsoft, Cisco och Adobe använder Neo4j.
ArangoDB
ArangoDB är en open source-databas med flera modeller som tillåter användare att ställa frågor med olika frågespråk. Noder och kanter representeras som JSON-dokument. Relationer mellan noder lagras som kanter och deras unika ID:n. ArangoDB erbjuder bra prestanda tack vare sitt hashindex.

ArangoDB förbättrar genomgångar, sammanfogningar och sökningar i databaser, vilket gör det möjligt att designa, skala och anpassa olika arkitekturer. Det spelar en viktig roll i komplexa dataanalysuppgifter. ArangoDB kan köras i molnet och är kompatibelt med Mac OS, Linux och Windows. LDAP-autentisering, datamaskering och krypteringsalgoritmer bidrar till att säkerställa databasens säkerhet. ArangoDB används inom riskhantering, bedrägeriupptäckt, nätverksinfrastruktur och rekommendationsmotorer. Användare av ArangoDB inkluderar Accenture och Cisco.
DataStax
DataStax är en NoSQL-molndatabas-som-en-tjänst baserad på Apache Cassandra. Den är skalbar och använder en molnbaserad arkitektur som gör den pålitlig och säker. DataStax lagrar dokument med index för snabb datahämtning och skapar skärvor över indexerad data. Applikationer kan byggas med hjälp av olika datakällor och DataStax Enterprise-verktyg, Kafka och Docker.
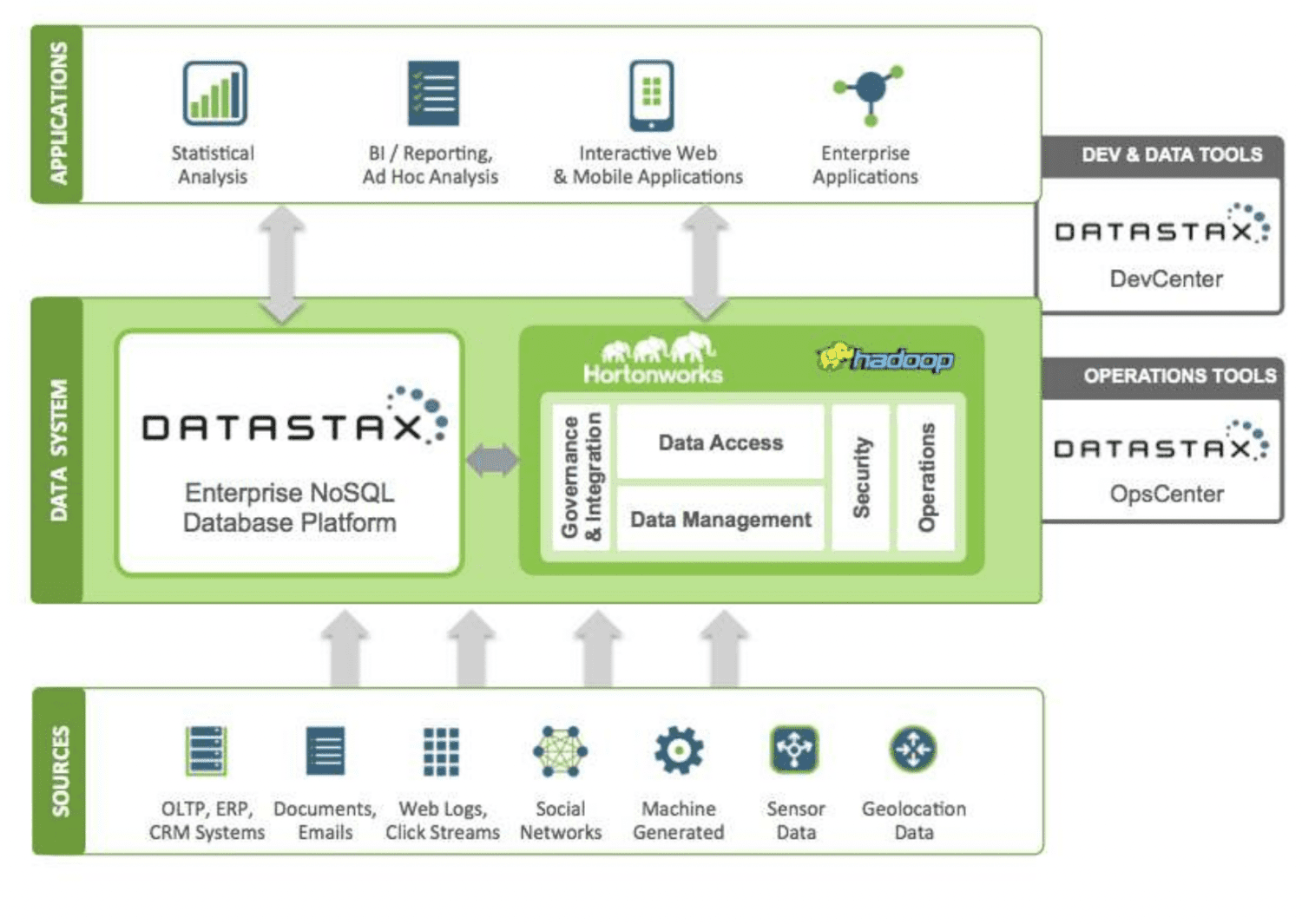
Data från olika källor skickas till Hadoop-ekosystemet och DataStax. Hadoop hanterar säkerhet, drift och datahantering i samverkan med DataStax. Data förfinas sedan med hjälp av DataStax utvecklings- och driftverktyg. Den analyserade informationen används för rapportering och affärsapplikationer. Eftersom DataStax är molnbaserat betalar kunderna för det de använder, vilket gör prissättningen rimlig. Företag som Verizon, CapitalOne och TMobile använder DataStax.
OrientDB
OrientDB är en grafdatabas som effektivt hanterar data och hjälper till att skapa visuella representationer. Det är en grafdatabas med flera modeller byggd i Java. Den lagrar data i nyckel-värdepar, dokument och objektmodeller. OrientDB består av en grafredigerare, ett studiofrågeverktyg och en kommandoradskonsol.
Grafredigeraren används för att visualisera och interagera med data, medan studiofrågeverktyget kör frågor och visar resultaten i både tabell- och bildformat. Kommandoradskonsolen används för att ställa frågor. OrientDB har en distribuerad arkitektur med flera servrar som kan hantera både läs- och skrivoperationer. Replikservrar används för läs- och frågeoperationer. Den stöder indexering och är ACID-kompatibel. Comcast Corporation och Blackfriars Group använder OrientDB.
Dgraph
Dgraph är en molngrafdatabas som stöder GraphQL, utvecklad med Go. Den minimerar nätverksanrop och latens genom att maximera samtidig frågebehandling. Dgraphs sömlösa integration med GraphQL förenklar utvecklingen av backend-applikationer.

En GraphQL-mutation skickas genom en Lambda-funktion som interagerar med databasen och en datapipeline. Den är horisontellt skalbar, vilket innebär att resurser kan utökas vid behov. Dgraph erbjuder funktioner som JWT-baserad auktorisering och datavisualisering. Intuit och intel är några organisationer som använder Dgraph.
Tigergraph
Tigergraph är en grafdatabas utvecklad i C++. Den är skalbar och utför avancerad analys av sammankopplad data. Den använder en inbyggd grafstruktur och en grafbearbetningsmotor. Databasen lagras på disk och i minne, med CPU-cache för snabb datahämtning. Den använder Map Reduce för parallell databearbetning.
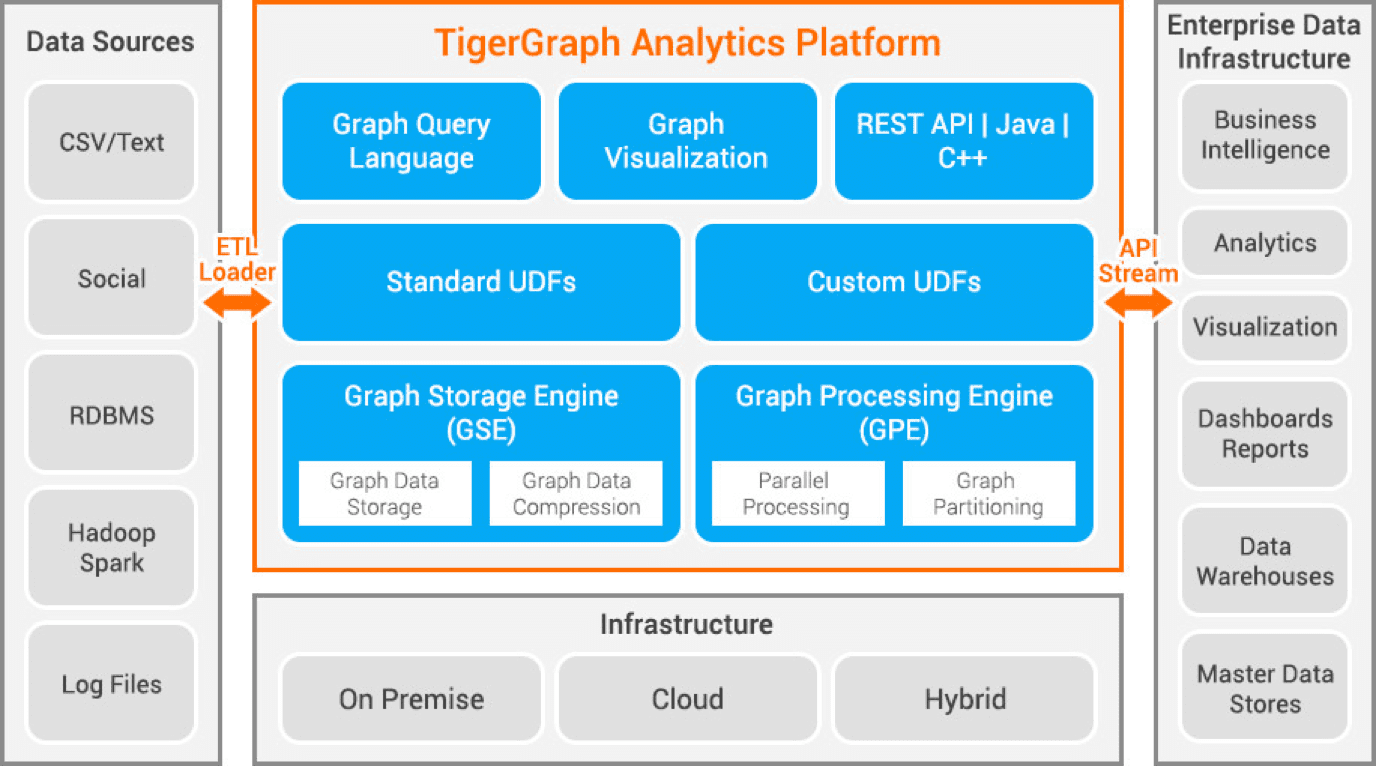
Tigergraph erbjuder snabba och skalbara lösningar för parallella beräkningar och uppdateringar i realtid. Den använder datakomprimeringstekniker och partitionerar data över servrar automatiskt. Tigergraph används för bedrägeriupptäckt inom olika branscher samt för att förbättra hälsovården. JPMorgan Chase och Intuit är bland de organisationer som använder Tigergraph.
AllegroGraph
AllegroGraph använder entity-event kunskapsgrafteknik för analys och beslutsfattande baserat på sammankopplad och komplex data. Data lagras i JSON- och JSON-LD-format i grafens noder. Den använder REST-protokollarkitektur och kan hantera stora datamängder genom att dela upp data och sprida det över flera kunskapsbasförråd.
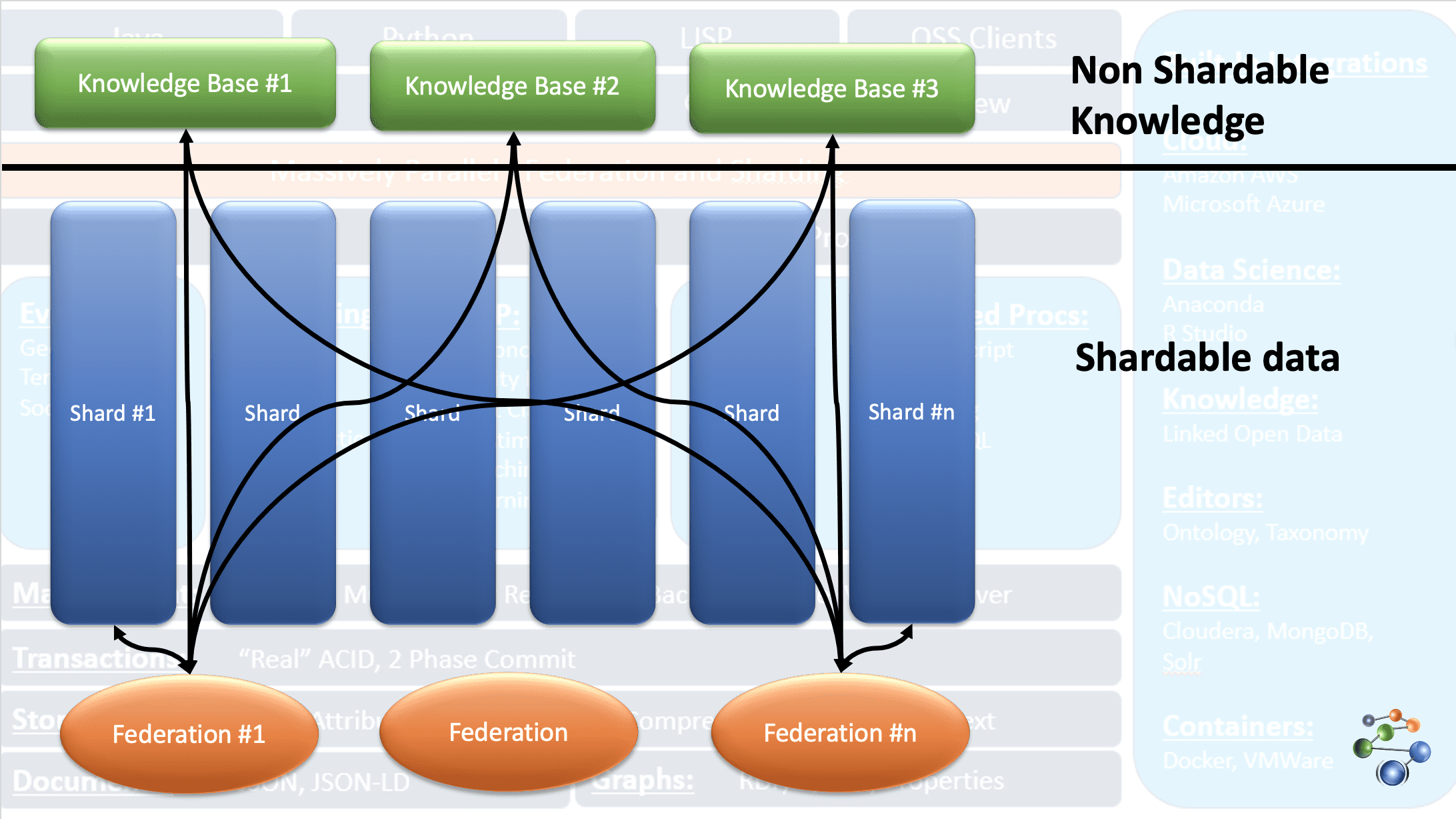
Detta är möjligt tack vare FedShard-funktionen i AllegroGraph. Frågor utförs genom att kombinera federationer med kunskapsbaserade arkiv. AllegroGraph stöder XML-schematyper och använder trippelindex. Den lagrar geografisk data samt tidsdata. Den är kompatibel med Windows, Mac och Linux. AllegroGraph används för bedrägeriupptäckt, hälsovård och riskbedömning.
Stardog
Stardog är en grafdatabas som tillåter datavirtualisering och länkar data från olika datalager utan att behöva kopiera data till en ny plats. Stardog bygger på RDF-öppna standarder och stöder strukturerad, semistrukturerad och ostrukturerad data. Denna virtualisering ger flexibilitet och är unik då Stardog kombinerar kunskapsgrafer och virtualisering.
Stardog använder en inferensmotor som drivs av AI för att bearbeta och leverera frågeresultat effektivt. Den är en ACID-kompatibel databas som hanterar komplexa frågor med sin avancerade arkitektur. Den används för IT Asset Management och dataanalys. Cisco och NASA är några av de företag som använder Stardog.
Sammanfattning
Grafdatabaser är kraftfulla verktyg för att hantera och lagra data där relationerna är centrala. De är skalbara, säkra och kan integreras med många tredjepartsverktyg, API:er och språk. Med sin förmåga att förenkla komplexa sammankopplingar till enkla frågor, spelar de en allt större roll i hanteringen av data, särskilt inom områden som IoT och Big Data. Grafdatabaser kommer att fortsätta att utvecklas och utöka sina användningsområden i framtiden.