Linux filsystem är starkt beroende av inoder. Dessa kritiska delar av filsystemets interna funktioner missförstås ofta. Låt oss utforska vad de är och hur de fungerar.
Filsystemets byggstenar
Ett filsystem behöver lagra filer och kataloger. Filer ordnas i kataloger, som i sin tur kan innehålla underkataloger. Det krävs ett system för att registrera var alla filer finns, deras namn, ägare, rättigheter och annan information. Denna information kallas metadata, eftersom den beskriver annan data.
I Linux ext4 filsystem samverkar inoder och katalogstrukturer för att skapa grunden för att lagra metadata för varje fil och katalog. De gör denna information tillgänglig för alla som behöver den, oavsett om det är kärnan, applikationer eller Linux-verktyg som `ls`, `stat` och `df`.
Inoder och filsystemets storlek
Ett filsystem behöver många strukturer, inte bara ett fåtal. Varje fil och katalog kräver en inod, och eftersom varje fil finns i en katalog, kräver den även en katalogstruktur. Katalogstrukturer kallas även katalogposter eller ”dentries”.
Varje inod har ett unikt inodnummer inom ett filsystem. Samma inodnummer kan förekomma i flera filsystem. Filsystemets ID och inodnummer kombineras för att skapa en unik identifierare oavsett hur många filsystem som är monterade på ett Linux-system.
Det är viktigt att komma ihåg att i Linux monterar man inte en hårddisk eller partition. Istället monterar man filsystemet som finns på partitionen. Därför kan man ha flera filsystem utan att vara medveten om det. Om du har flera hårddiskar eller partitioner på en enhet har du mer än ett filsystem. De kan vara av samma typ, till exempel alla `ext4`, men de är fortfarande distinkta filsystem.
Alla inoder lagras i en tabell. Med hjälp av inodnumret kan filsystemet enkelt räkna ut positionen i inodtabellen där den specifika inoden finns. Det är därför bokstaven ”i” i inod står för index.
Variabeln som lagrar inodnumret är deklarerad som ett 32-bitars osignerat heltal. Detta betyder att det maximala inodnumret är 2^32, vilket motsvarar 4 294 967 295, alltså över 4 miljarder inoder.
Detta är det teoretiska maxvärdet. I praktiken bestäms antalet inoder i ett `ext4` filsystem när det skapas. Standardförhållandet är en inod per 16 KB filsystemkapacitet. Katalogstrukturer skapas vid behov när filer och kataloger skapas.
Med kommandot `df` kan du se hur många inoder ett filsystem har. Genom att använda flaggan `-i` (inoder) kan du få kommandot att visa sin utdata i form av antal inoder.
För att undersöka filsystemet på den första partitionen på den första hårddisken, använder vi följande kommando:
df -i /dev/sda1
Utdata visar följande:
Filsystem: Filsystemet som granskas.
Inoder: Totalt antal inoder i filsystemet.
IUsed: Antal inoder som används.
IFree: Antal lediga inoder.
IUse%: Procentandel använda inoder.
Monterad på: Monteringspunkten för filsystemet.
I detta exempel är 10 procent av inoderna använda. Filer lagras på hårddisken i diskblock. Varje inod pekar på diskblocken som innehåller filens innehåll. Om du har många små filer kan du få slut på inoder innan du får slut på diskutrymme, även om detta är ett ovanligt problem.
Vissa e-postservrar som tidigare lagrade e-postmeddelanden som separata filer (vilket snabbt ledde till många små filer) stötte på detta problem. Problemet löstes dock när dessa system övergick till databaser. Ett genomsnittligt hemdatorsystem kommer inte att få slut på inoder, vilket är tur eftersom man i ett `ext4` filsystem inte kan lägga till fler inoder utan att installera om filsystemet.
För att se storleken på diskblocken i ditt filsystem kan du använda `blockdev`-kommandot med flaggan `–getbsz` (get block size):
sudo blockdev --getbsz /dev/sda

Blockstorleken är 4096 byte.
Låt oss använda flaggan `-B` (blockstorlek) för att ange en blockstorlek på 4096 byte och kontrollera diskanvändningen:
df -B 4096 /dev/sda1

Denna utdata visar följande:
Filsystem: Filsystemet som granskas.
4K-block: Totalt antal 4 KB-block i filsystemet.
Används: Antal använda 4 KB-block.
Tillgänglig: Antal lediga 4 KB-block.
Använd%: Procentandel 4 KB-block som används.
Monterad på: Monteringspunkten för filsystemet.
I exemplet har fillagring (inklusive lagring av inoder och katalogstrukturer) använt 28 procent av utrymmet, medan 10 procent av inoderna har använts. Det är alltså inga problem med utrymme eller inoder.
Inode Metadata
För att se en fils inodnummer använder vi `ls` med flaggan `-i` (inod):
ls -i geek.txt

Inodnumret för filen är 1441801. Denna inod innehåller metadata för filen och, traditionellt, pekare till diskblocken där filens data lagras. Om filen är fragmenterad, stor eller båda, kan vissa av blocken som inoden pekar på innehålla ytterligare pekare till andra diskblock. Och vissa av dessa block kan också innehålla pekare till en annan uppsättning diskblock. Detta löser problemet med att inoden har en fast storlek och begränsat antal pekare till diskblock.
Den metoden har ersatts av ett nytt schema som använder ”omfattningar”. Dessa registrerar start- och slutblocket för varje sammanhängande blocksekvens som används för att lagra filen. Om filen inte är fragmenterad behöver du bara lagra det första blocket och filens längd. Om filen är fragmenterad måste du lagra det första och sista blocket i varje del av filen. Denna metod är mer effektiv.
För att se om ditt filsystem använder diskblockpekare eller omfattningar kan du undersöka en inod. Detta gör du med kommandot `debugfs` med flaggan `-R` (request) och skicka inoden för filen. `debugfs` använder sedan sitt interna `stat`-kommando för att visa innehållet i inoden. Eftersom inodnummer endast är unika inom ett filsystem måste vi även ange vilket filsystem inoden tillhör.
Så här kan kommandot se ut:
sudo debugfs -R "stat <1441801>" /dev/sda1

`debugfs` hämtar informationen från inoden och visar den i less:
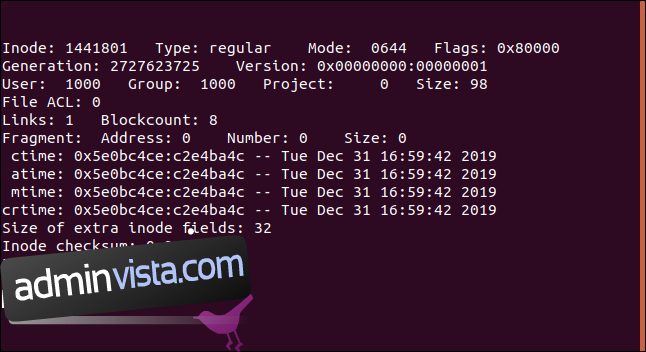
Vi ser följande information:
Inode: Inodnumret vi undersöker.
Typ: Det här är en vanlig fil, inte en katalog eller symbolisk länk.
Läge: Filrättigheterna i oktal.
Flaggor: Indikatorer som representerar olika egenskaper eller funktioner. 0x80000 är ”extents”-flaggan (mer om detta nedan).
Generation: Ett Nätverksfilsystem (NFS) använder detta när någon ansluter till fjärrfilsystem över nätverk. Inod- och generationsnumren används som filhandtag.
Version: Inodeversionen.
Användare: Filens ägare.
Grupp: Filens gruppägare.
Projekt: Ska alltid vara noll.
Storlek: Filens storlek.
Fil ACL: Listan för filåtkomstkontroll. Dessa är gjorda för att du ska kunna ge kontrollerad åtkomst till personer som inte är med i ägargruppen.
Länkar: Antal hårda länkar till filen.
Blockantal: Mängden diskutrymme som tilldelats filen, angiven i 512-byte bitar. Den här filen har tilldelats åtta, vilket är 4096 byte. Vår 98-byte fil tar alltså upp ett enda 4096-byte diskblock.
Fragment: Filen är inte fragmenterad. (Detta är en föråldrad flagga.)
Ctime: Tidpunkten då filen skapades.
Atime: Tidpunkten då filen senast öppnades.
Mtime: Tidpunkten då filen senast ändrades.
Crtime: Tidpunkten då filen skapades.
Storlek på extra inodfält: `ext4` filsystem introducerade möjligheten att allokera en större inod på disken vid formatering. Detta värde är antalet extra byte som inoden använder. Det extra utrymmet kan användas för framtida krav på nya kärnor eller för att lagra utökade attribut.
Inodkontrollsumma: Kontrollsumman för inoden, som gör det möjligt att upptäcka om den är skadad.
Omfattningar: Om omfattningar används (vilket är standard i `ext4`) har metadata om diskblocksanvändning två siffror som anger start- och slutblock för varje del av en fragmenterad fil. Detta är mer effektivt än att lagra varje diskblock som används av varje del av filen. Vi har en omfattning eftersom vår lilla fil ligger inom ett diskblock vid den angivna blockpositionen.
Var är filnamnet?
Vi har nu mycket information om filen, men filnamnet saknas. Det är där katalogstrukturen kommer in. Precis som en fil har en katalog också en inod. Istället för att peka på diskblock med fildata pekar en kataloginod på diskblock som innehåller katalogstrukturer.
Jämfört med en inod innehåller en katalogstruktur en begränsad mängd information om en fil. Den innehåller bara filens inodnummer, namn och namnets längd.
Inoden och katalogstrukturen innehåller all information som du (eller ett program) behöver om en fil eller katalog. Katalogstrukturen finns i ett katalogdiskblock, vilket gör att vi vet vilken katalog filen finns i. Katalogstrukturen ger oss filnamnet och inodnumret. Inoden ger all annan information om filen, som tidsstämplar, behörigheter och var filens data finns.
Kataloginoder
Du kan se inodnumret för en katalog lika enkelt som för en fil.
I följande exempel använder vi `ls` med flaggorna `-l` (långt format), `-i` (inod) och `-d` (katalog) och tittar på arbetskatalogen:
ls -lid work/

Eftersom vi använde `-d` rapporterar `ls` om själva katalogen, inte dess innehåll. Inoden för katalogen är 1443016.
För att göra samma sak för hemkatalogen skriver vi följande:
ls -lid ~

Inoden för hemkatalogen är 1447510 och arbetskatalogen finns i hemkatalogen. Låt oss titta på innehållet i arbetskatalogen. Istället för `-d` (katalog) använder vi `-a` (alla). Detta visar även katalogposter som normalt är dolda.
Vi skriver följande:
ls -lia work/
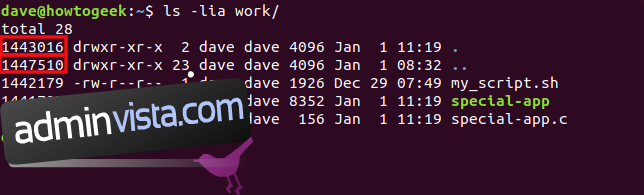
Eftersom vi använde `-a` visas enkelpunkts (.) och dubbelpunkts (..) poster. Dessa representerar katalogen själv (enkelpunkt) och dess överordnade katalog (dubbelpunkt).
Om du tittar på inodnumret för enkelpunktsposten är det 1443016 — samma inodnummer som vi fick när vi tog reda på inodnumret för arbetskatalogen. Dessutom är inodnumret för dubbelpunktsposten samma som inodnumret för hemkatalogen.
Det är därför du kan använda kommandot `cd ..` för att gå uppåt i katalogstrukturen. På samma sätt, när du föregår ett program- eller skriptnamn med `./`, anger du för skalet varifrån programmet eller skriptet ska startas.
Inoder och länkar
Som vi har sett krävs tre komponenter för att ha en korrekt och tillgänglig fil i filsystemet: filen, katalogstrukturen och inoden. Filen är data som lagras på hårddisken, katalogstrukturen innehåller filens namn och dess inodnummer och inoden innehåller filens metadata.
Symboliska länkar är filsystemposter som ser ut som filer, men de är i själva verket genvägar som pekar på en befintlig fil eller katalog. Låt oss se hur de fungerar och hur de tre elementen används för att uppnå detta.
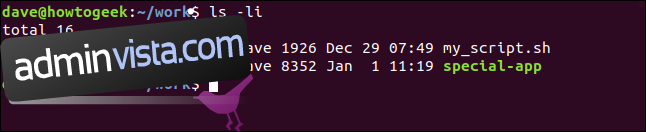
Antag att vi har en katalog med två filer: ett skript och ett program, som visas nedan.
Vi kan använda kommandot `ln` med flaggan `-s` (symbolisk) för att skapa en mjuk länk till skriptfilen:
ln -s my_script.sh geek.sh

Vi har skapat en länk till `my_script.sh` som heter `geek.sh`. Med `ls` kan vi undersöka dessa två skriptfiler:
ls -li *.sh
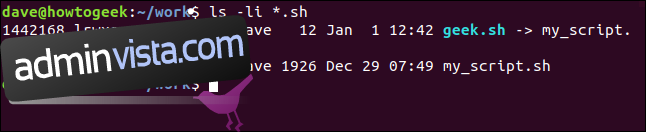
Posten för `geek.sh` visas i blått. Det första tecknet i rättighetsflaggorna är ett ”l” för länk, och `->` pekar på `my_script.sh`. Allt detta indikerar att `geek.sh` är en länk.
Som förväntat har de två skriptfilerna olika inodnummer. Vad som kan vara överraskande är att den mjuka länken, `geek.sh`, inte har samma användarrättigheter som den ursprungliga skriptfilen. Faktum är att behörigheterna för `geek.sh` är mycket mer tillåtande – alla användare har fullständiga rättigheter.
Katalogstrukturen för `geek.sh` innehåller namnet på länken och dess inod. När du försöker använda länken refereras dess inod, precis som en vanlig fil. Länkinoden pekar på ett diskblock, men istället för att innehålla filens data innehåller diskblocket namnet på originalfilen. Filsystemet omdirigerar till originalfilen.
Vi tar bort originalfilen och ser vad som händer om vi försöker visa innehållet i `geek.sh`:
rm my_script.sh
cat geek.sh

Den symboliska länken är bruten och omdirigeringen misslyckas.
Vi skapar nu en hård länk till applikationsfilen:
ln special-app geek-app

För att undersöka inoderna för dessa två filer skriver vi:
ls -li
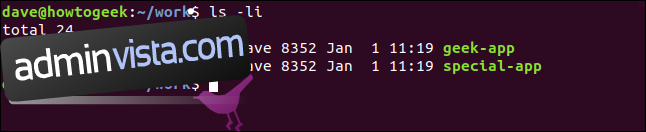
Båda ser ut som vanliga filer. Inget i `geek-app` indikerar att det är en länk, till skillnad från hur `ls` listade `geek.sh`. Dessutom har `geek-app` samma användarrättigheter som originalfilen. Det som är överraskande är att båda applikationerna har samma inodnummer: 1441797.
Katalogposten för `geek-app` innehåller namnet ”geek-app” och ett inodnummer, men det är samma inodnummer som originalfilen. Vi har alltså två filsystemposter med olika namn som pekar på samma inod. Det kan vara hur många poster som helst som pekar på samma inod.
Vi använder programmet `stat` för att undersöka målfilen:
stat special-app
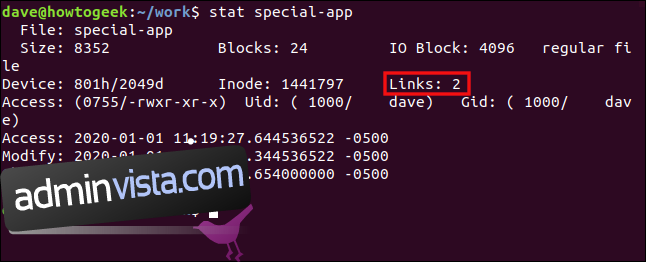
Vi ser att två hårda länkar pekar på den här filen. Detta lagras i inoden.
I följande exempel tar vi bort originalfilen och försöker använda länken med ett hemligt lösenord:
rm special-app
./geek-app correcthorsebatterystaple

Överraskande nog fungerar applikationen som förväntat. Hur är det möjligt? Det fungerar eftersom när du tar bort en fil blir inoden ledig och kan återanvändas. Katalogstrukturen markeras med ett inodnummer på noll, och diskblocken är tillgängliga för en annan fil som kan lagras i utrymmet.
Om antalet hårda länkar till inoden är större än ett minskas antalet med ett, och inodnumret för katalogstrukturen för den borttagna filen sätts till noll. Filinnehållet på hårddisken och inoden är fortfarande tillgängliga för befintliga hårda länkar.
Vi använder `stat` igen, den här gången på `geek-app`:
stat geek-app
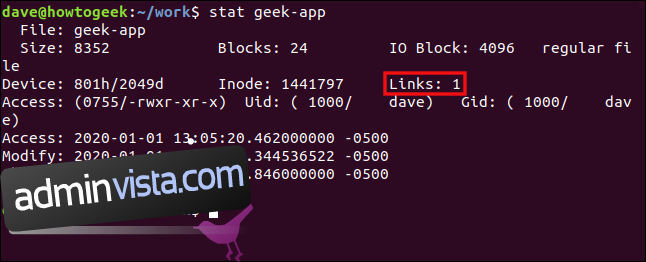
Detaljerna hämtas från samma inod (1441797) som i föregående `stat`-kommando. Antalet länkar har minskat med ett.
Eftersom vi har en hård länk till denna inod skulle filen verkligen raderas om vi tog bort `geek-app`. Filsystemet frigör inoden och markerar katalogstrukturen med en inod på noll. En ny fil kan sedan skriva över data på hårddisken.
Inode Overhead
Detta är ett smart system, men det finns en del overhead. För att läsa en fil måste filsystemet göra allt följande:
Hitta rätt katalogstruktur
Läs inodnumret
Hitta rätt inod
Läs inodinformationen
Följ antingen inodlänkarna eller omfattningarna till relevanta diskblock
Läs fildata
Det krävs lite extra arbete om data inte är sammanhängande.
Tänk dig arbetet som krävs för att `ls` ska göra en lång lista med många filer. Det är mycket fram och tillbaka bara för att få informationen som behövs för att generera utdata.
Naturligtvis försöker Linux cacha filer så mycket som möjligt för att snabba upp filsystemets åtkomst. Det hjälper mycket, men ibland, som med alla filsystem, kan overheaden bli uppenbar.
Nu vet du varför.