
Grafdatabaser lagrar mycket sammankopplade täta data och processfrågor effektivt. Men vet du när du ska använda vilken grafdatabas? Läs för att lära dig mer.
”Data är den nya oljan.” Tillväxten av alla organisationer är baserad på hur de effektivt lagrar och använder data. 2,5 kvintiljoner byte data genereras varje dag. Så vi behöver feltoleranta system och lager där data kan lagras och hanteras effektivt. Till en början användes relationsdatabaser.
Men allt eftersom tiden gick förändrades mängden och typen av data snabbt. Därför fanns det ett behov av att lagra video, ljud, bilder etc. Detta var startpunkten för utvecklingen av SQL, NoSQL-databaser, Hadoop, grafdatabaser, etc. Var och en har sina egna användningsfall och hanterar olika dataformat. Grafdatabaser utvecklades för att förenkla operationer på data och för effektiv lagring.
Innehållsförteckning
Grafdatabaser
En graf är en datastruktur representerad i form av noder och kanter. En databas är en samling tabeller som lagrar data och relationerna mellan data. En grafdatabas är en databas som lagrar data i noder och de relationer som finns inom data i form av kanter. Grafdatabaser hjälper till att hantera frågor i realtid och hantera många-till-många-relationer mellan enheter effektivt.
Populära grafdatamodeller inkluderar egenskapsgrafer och RDF-grafer. Analyser och sökningar görs oftast med hjälp av egenskapsdiagram. Dataintegration görs med hjälp av RDF-grafer. Skillnaden mellan egenskaps- och RDF-grafer är att RDF-grafer representeras i form av trippel, dvs subjekt, predikat och objekt.
Grafdatabaser lagrar data i noder och förhållandet mellan data i form av kanter mellan noderna. Kanterna i grafen kan vara riktade (enkelriktade) eller oriktade (dubbelriktade).
Frågebehandling sker genom att gå igenom grafen. Graftraversalalgoritmer som hjälper till att hitta vägen från en nod till en annan, avståndet mellan noderna, hitta mönster, slingor i grafen och möjligheten för bildandet av kluster etc. används för att besvara frågor effektivt.
Tillämpningar av grafdatabaser
Grafdatabaser används för att upptäcka bedrägerier. Noderna/entiteterna kan vara personers namn, adresser, födelsedatum, etc., och vissa falska IP-adresser, enhetsnummer etc. När en bedräglig nod interagerar med en icke-bedräglig nod, bildas länkar mellan dem och markeras som misstänksam.
Webbplatser för sociala medier använder grafiska databaser för att visa rekommendationer från de personer vi skulle vilja komma i kontakt med och innehållet vi vill se. Det gör den med hjälp av grafövergångar i databasen.
Nätverkskartläggning och infrastrukturhantering, konfigurationsobjekt etc. lagras och hanteras också effektivt med hjälp av grafdatabaser.
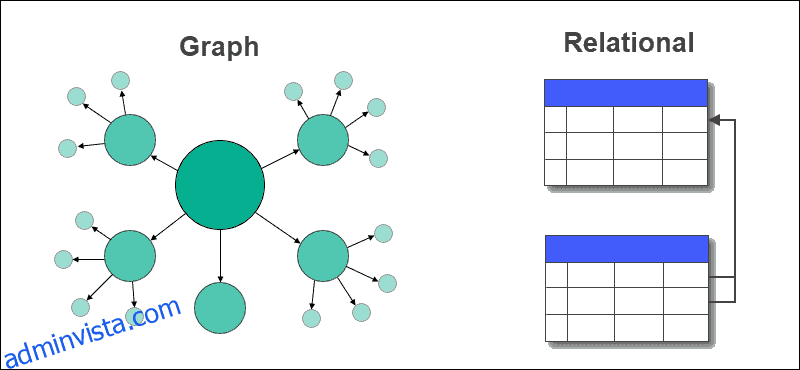
Grafdatabas kontra relationsdatabas
I en grafdatabas ersätts tabeller med rader och kolumner med noder och kanter. Relationerna mellan data lagras på kanter i en grafdatabas.
En relationsdatabas lagrar relationer mellan tabeller med hjälp av främmande nycklar och andra tabeller. Att extrahera data eller fråga är enkelt och kräver inga komplexa kopplingar i en grafdatabas, men det är inte fallet med relationsdatabaser.
Relationsdatabaser är mest lämpade för användningsfall som involverar transaktioner, medan grafdatabaser är lämpliga för relationstunga och dataintensiva applikationer.
Grafdatabaser stöder strukturerad, semistrukturerad och ostrukturerad data, medan relationsdatabaser måste ha ett fast schema.
Grafdatabaser uppfyller dynamiska krav, medan relationsdatabaser i allmänhet används för kända och statiska problem.
 Graf vs relationsdatabaser
Graf vs relationsdatabaser
Låt oss nu titta på de bästa grafdatabaslösningarna.
Cayley
Cayley är en grafdatabas med öppen källkod utvecklad av Apache 2.0. Den byggdes med hjälp av Go och fungerar på länkad data. Cayley är den databas som används när man bygger Googles Freebase och kunskapsgraf. Den stöder flera frågespråk som MQL och Javascript med ett Gremlin-baserat grafobjekt.
Den är enkel att använda, snabb och har en modulär design. Den kan integrera och interagera med olika backend-butiker som LevelDB, MongoDB och Bolt. Den stöder olika API:er från tredje part skrivna på flera språk som Java, .NET, Rust, Haskell, Ruby, PHP, Javascript och Clojure. Det kan distribueras i Docker och Kubernetes. De nyckelområden där Cayley används är informationsteknologi, datorprogramvara och finansiella tjänster.
Amazon Neptunus
Amazon Neptune är känt för att prestera exceptionellt bra på mycket uppkopplade datauppsättningar. Det är tillförlitligt, säkert, helt hanterat och stöder öppna graf-API:er. Den kan lagra miljarder relationer och fråga data med extremt låg latens på några millisekunder.
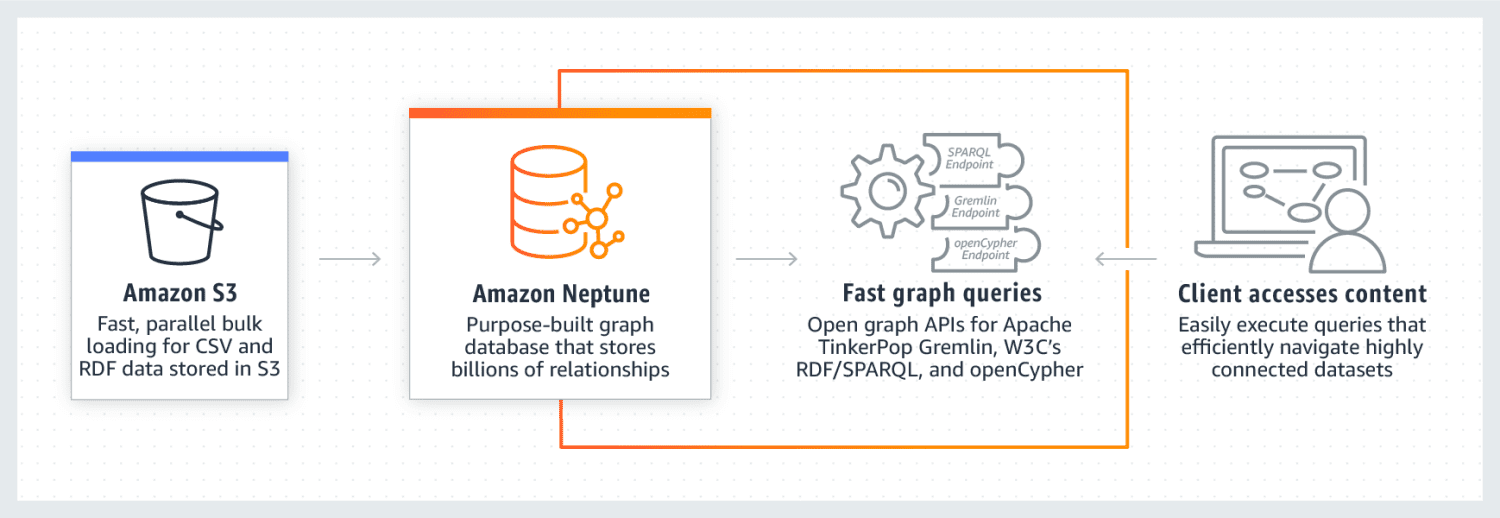
Neptunus grafdatamodell består av fyra positioner, nämligen subjekt (S), predikat (P), objekt (O) och graf (G). Var och en av dessa positioner används för att lagra positionen för källnoden, målnoden, förhållandet mellan dem och deras egenskaper.
Den använder också en cache som påskyndar exekveringen av läsfrågor. Data lagras i form av DB-kluster. Varje kluster består av en primär DB-instans och läsrepliker av DB-instanser. Neptune är mycket säker eftersom den använder IAM-autentisering, SSL-certifiering och loggövervakning. Det är också lätt att migrera data från andra källor till Amazon Neptune. Det säkerställer också motståndskraft genom att skapa repliker och periodiska säkerhetskopior. Vissa företag som använder Neptune inkluderar Herren, Onedot, Juncture och Hi Platform.
Neo4j
Neo4j är en skalbar, säker, on-demand och pålitlig grafdatabas. Neo4j byggdes med Java, med Cypher som frågespråk. Den använder Bolt-protokollet och alla transaktioner sker över en HTTP-slutpunkt. Det är mycket snabbare att svara på frågor jämfört med andra relationsdatabaser. Den har inte överkostnaderna med komplexa kopplingar, och dess optimeringar fungerar bra när datamängden är stor och mycket ansluten. Det erbjuder fördelen med graflagring tillsammans med ACID-egenskaperna i en relationsdatabas.

Neo4j stöder olika språk som Java, .NET, Node.js, Ruby, Python, etc., med hjälp av drivrutiner. Det används också i grafdatavetenskap, analys och maskininlärningsarbetsflöden. Neo4j Aura DB är en feltolerant och fullt hanterad molngrafdatabas. Företag som Microsoft, Cisco, Adobe, eBay, IBM, Samsung, etc., använder Neo4j.
ArangoDB
ArangoDB är en öppen källkodsdatabas med flera modeller. Tillvägagångssättet med flera modeller gör det möjligt för användare att fråga efter data på valfritt frågespråk. Noderna och kanterna på ArangoDB är JSON-dokument. Varje dokument har ett unikt ID. Relationer mellan två noder indikeras i form av kanter, och deras unika ID lagras. Dess goda prestanda beror på närvaron av ett hashindex.

Genomgångar, sammanfogningar och sökningar i databaserna förbättras. Det hjälper till att designa, skala och anpassa till olika arkitekturer. Det spelar en viktig roll i komplexa datavetenskapliga uppgifter som funktionsextraktion och avancerad sökning.
ArrangoDB kan köras i en molnbaserad miljö och är kompatibel med Mac Os, Linux och Windows. LDAP-autentisering, datamaskering och krypteringsalgoritmer säkerställer att databasen är säker. Det används i riskhantering, IAM, bedrägeriupptäckt, nätverksinfrastruktur, rekommendationsmotorer, etc. Accenture, Cisco, Dish och VMware är några organisationer som använder ArangoDB.
DataStax
DataStax är en NoSQL-molndatabas-som-en-tjänst byggd på Apache Cassandra. Den är mycket skalbar och använder molnbaserad arkitektur. Det är pålitligt och säkert. Varje dokument som lagras i en DataStax har ett index som hjälper till med enkel sökning och snabb hämtning av data. Skärvor skapas över indexerade data. Olika datakällor kan användas för att bygga applikationer med Datastax Enterprise-verktyg, Kafka och Docker.
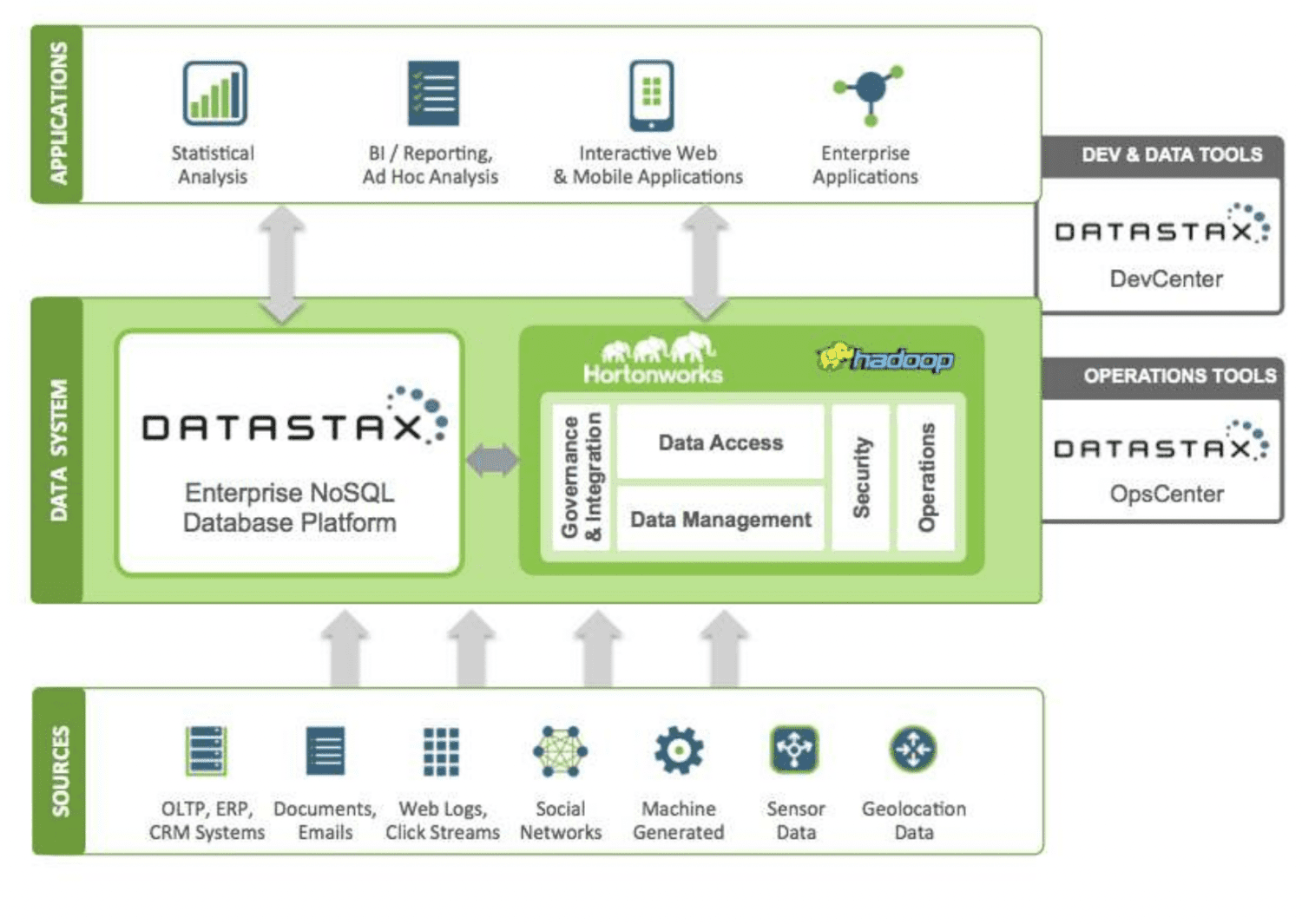
Data som samlas in från källor skickas till ett Hadoop-ekosystem och DataStax. Hadoop hanterar säkerhet, drift, dataåtkomst och hantering genom att interagera med DataStax. Datan förfinas med hjälp av Datastax utvecklings- och driftverktyg.
Den analyserade informationen används sedan för statistisk analys, företagsapplikationer, rapportering etc. Eftersom den är molnbaserad betalar kunderna för det de använder och prissättningen är rimlig. Verizon, CapitalOne, TMobile och Overstock är några företag som använder DataStax.
Orientera DB
OrientDB är en grafdatabas som hanterar data effektivt och hjälper till att skapa visuella representationer för att visa upp data. Det är en grafdatabas med flera modeller och byggdes med Java. Den lagrar data i form av nyckel-värdepar, dokument, objektmodeller etc. Den består av tre viktiga komponenter: grafredigerare, studiofråga och kommandoradskonsol.
En grafredigerare används för att visualisera och interagera med data. Studios frågegränssnitt används för att köra frågor och ge utdata direkt i bild- och tabellformat. Kommandoradskonsolen används för att fråga data från OrientDB. Den har en distribuerad arkitektur med flera servrar som kan utföra läs- och skrivoperationer. Replikservrar används för att utföra läs- och frågeoperationer. Den stöder indexering och är också ACID-kompatibel. Några av företagen som använder OrientDB är Comcast Corporation och Blackfriars Group.
Dgraph
Dgraph är en molngrafdatabas som stöder GraphQL. Den byggdes med hjälp av Go. Det minimerar nätverksanropen och minskar latensen genom att maximera samtidig frågebehandling. Den sömlösa integrationen av Dgraph med GraphQL hjälper till att enkelt utveckla GraphQL backend-applikationer.

En GraphQL-mutation skickas genom en Lambda-funktion som interagerar med databasen och en datapipeline. Detta förenklar frågebehandlingen. Det är horisontellt skalbart, vilket innebär att antalet resurser ökar med ökande frågor och data. Den tillhandahåller olika funktioner som JWT-baserad auktorisering, datavisualiserare, molnautentisering, säkerhetskopiering av data, etc. Vissa organisationer som använder Dgraph inkluderar Intuit, intel och Factset.
Tigergraf
Tigergraph är en databas för fastighetsdiagram utvecklad med C++. Den är mycket skalbar och utför avancerad analys på mycket ansluten data. Den använder en inbyggd grafstruktur för lagring av data och en grafbearbetningsmotor för att bearbeta data. Databasen lagras på disk och i minne och använder även en CPU-cache för snabb hämtning. Den använder Map Reduce-funktionen för parallell databehandling.
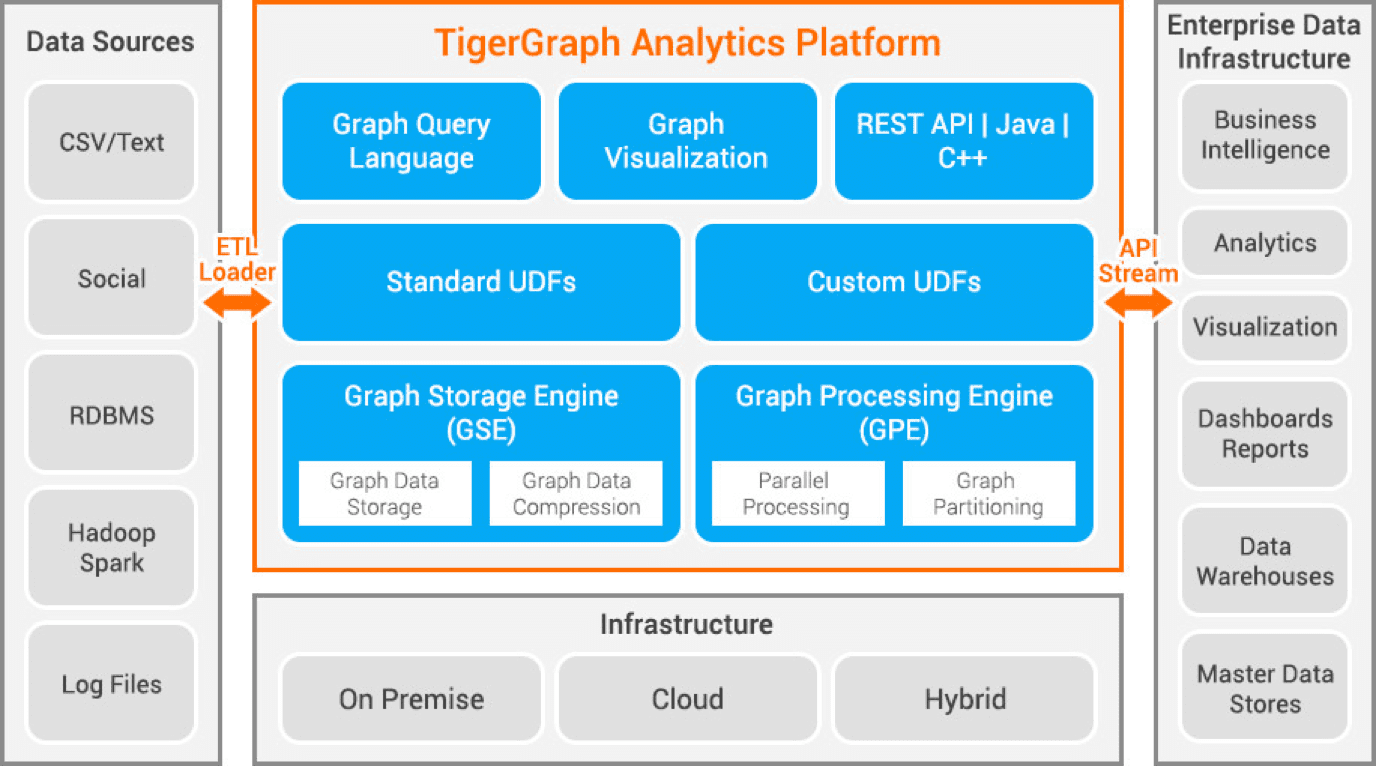
Det är extremt snabbt och skalbart. Den gör parallella beräkningar och ger uppdateringar i realtid. Den använder datakomprimeringstekniker och komprimerar data med 10x. Det partitionerar data över servrar automatiskt, vilket sparar användaren den tid och ansträngning som krävs för att skära data manuellt. Det används för att upptäcka bedrägerier i hushåll, försörjningskedjan och förbättra hälsovården. JPMorgan Chase, Intuit och United Health Group är några organisationer som använder Tigergraph.
AllegroGraph
AllegroGraph använder entity-event kunskapsgrafteknik för att utföra analyser och beslut på mycket anslutna, komplexa och täta data. Data lagras i JSON- och JSON-LD-format i grafens noder. Den använder REST-protokollarkitekturen. Den hanterar också extremt stora datamängder genom att dela data baserat på specifika kriterier och sprida den över flera kunskapsbasförråd.
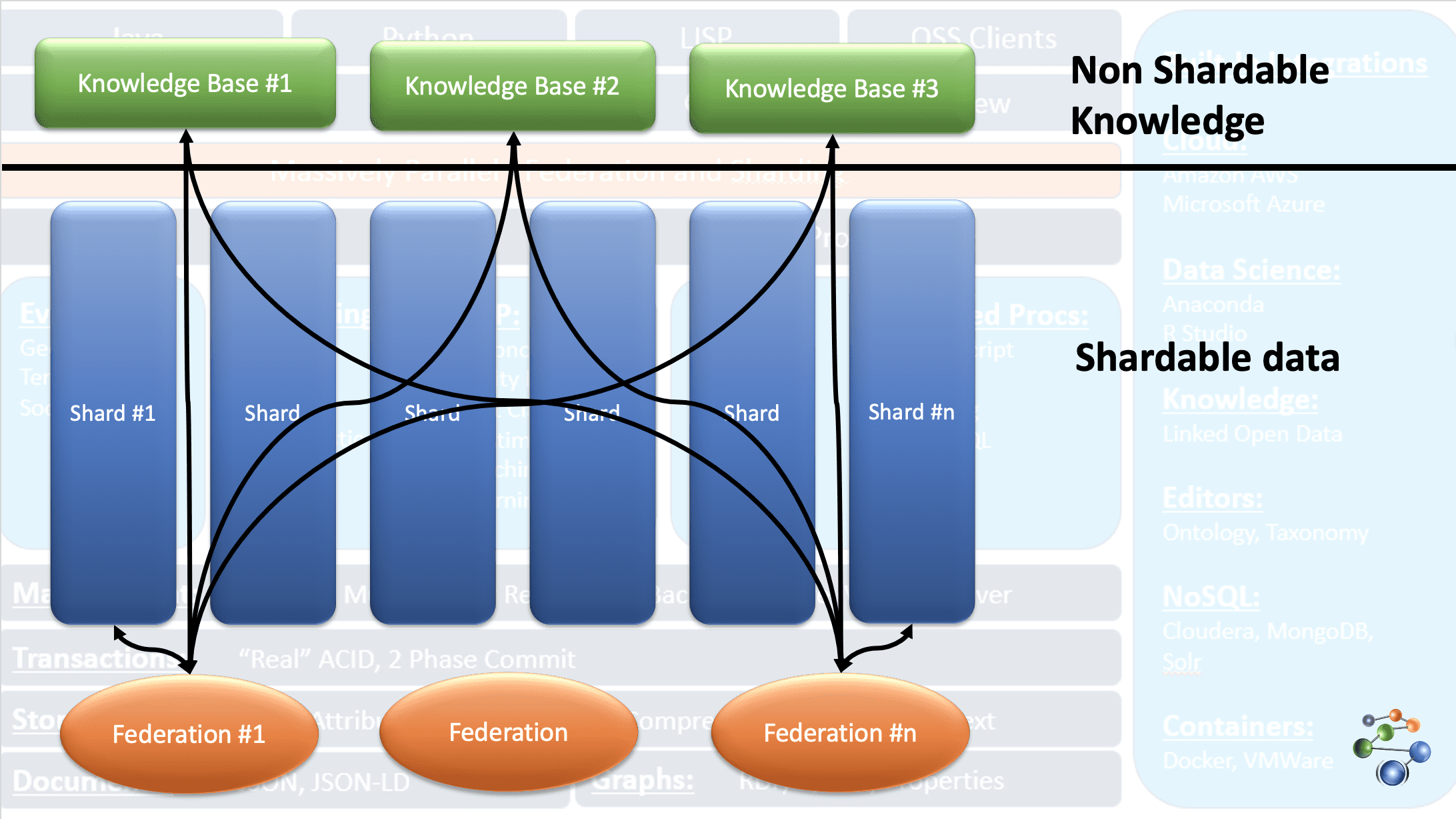
Detta är möjligt på grund av FedShard-funktionen i AllegroGraph-databasen. Utförandet av förfrågningar sker genom att kombinera federationerna med kunskapsbaserade arkiv. Den stöder XML-schematyper och använder trippelindex. Den lagrar geospatiala data som latituder och longituder och tidsdata som datum, tidsstämpel, etc. Den är också kompatibel med Windows, Mac och Linux. Det används i bedrägeriupptäckt, hälsovård, enhetsidentifiering, riskförutsägelse, etc.
Stardog
Stardog är en grafdatabas som utför grafdatavirtualisering och länkar data från datalager och datasjöar utan att fysiskt kopiera data till en ny lagringsplats. Stardog bygger på RDF öppna standarder. Den stöder strukturerad, semistrukturerad och ostrukturerad data. Denna typ av materialisering gjord av Stardog erbjuder flexibilitet. Det är den enda grafdatabasen som kombinerar kunskapsgrafer och virtualisering.
Stardog använder en inferensmotor som drivs av AI för att effektivt bearbeta och tillhandahålla frågeutdata. Det är en ACID-kompatibel grafdatabas. Samtidig läsning och skrivning stöds. Den hanterar komplexa frågor med lätthet på grund av den ”state-of-the-art” arkitekturen. Den används inom IT Asset Management, datahantering & analys och ger hög tillgänglighet. Vissa företag som använder Stardog är Cisco, eBay, NASA och Finra.
Slutord
Grafdatabaser hjälper till att enkelt söka efter många-till-många-relationer och lagra data effektivt. De är skalbara, säkra och kan integreras med många tredjepartsverktyg, API:er och språk. De senaste åren har de integrerats med molnet och ger den bästa prestandan.
De förenklar komplexa sammanfogningar till enkla frågor, vilket gör det till en enkel uppgift för utvecklarna. Dataintensiva uppgifter som IoT och Big Data är också grafdatabaser. Dessa kommer att fortsätta att utvecklas och kommer säkert att expandera till andra användningsfall i framtiden.