Viktiga slutsatser
- Generalisering är en central aspekt inom djupinlärning för att säkerställa korrekta förutsägelser med nya data. Nollskottsinlärning underlättar detta genom att göra det möjligt för AI att nyttja existerande kunskap för att göra precisa förutsägelser om nya, tidigare osedda klasser, även utan tillgång till märkt data.
- Nollskottsinlärning speglar hur människor lär sig och hanterar information. Genom att tillhandahålla ytterligare semantisk kontext kan en förtränad modell på ett träffsäkert sätt identifiera nya klasser, likt en människa som kan lära sig känna igen en gitarr med ihålig kropp genom att förstå dess specifika egenskaper.
- Nollskottsinlärning bidrar till att förbättra AI genom att öka generaliseringsförmågan, skalbarheten, minska risken för överanpassning samt vara kostnadseffektiv. Den möjliggör träning på större datamängder, erhållande av mer kunskap genom överföringsinlärning, ger en bättre kontextuell förståelse och minskar behovet av omfattande mängder märkt data. I takt med AI:s utveckling blir nollskottsinlärning allt viktigare för att tackla komplexa problem inom olika områden.
En av de främsta målsättningarna med djupinlärning är att skapa modeller med bred och generaliserad kunskap. Generalisering är av yttersta vikt då den garanterar att modellen har tillägnat sig meningsfulla mönster och kan göra precisa förutsägelser eller beslut när den ställs inför ny eller osedd information. Att träna sådana modeller kräver dock ofta betydande mängder märkt data, vilket kan vara både dyrt, resurskrävande och ibland till och med omöjligt att åstadkomma.
Nollskottsinlärning introduceras för att överbrygga denna utmaning, vilket gör det möjligt för AI att använda befintlig kunskap för att göra ganska korrekta förutsägelser, även om det saknas märkt data.
Vad är nollskottsinlärning?
Nollskottsinlärning är en specifik typ av överföringsinlärningsteknik som går ut på att använda en förutbildad modell för att identifiera nya eller tidigare okända klasser. Detta åstadkoms genom att ge modellen extra information som beskriver de karakteristiska dragen hos den nya klassen.
Genom att dra nytta av en modells allmänna kunskapsbas inom vissa ämnen och ge den ytterligare semantisk information om vad den ska leta efter, kan den med stor sannolikhet identifiera det ämne den har till uppgift att känna igen.
Låt oss ta exemplet med identifiering av en zebra. Om vi inte har tillgång till en modell som kan identifiera zebror, kan vi ta en befintlig modell som tränats på att känna igen hästar och berätta för modellen att hästar med svarta och vita ränder är zebror. När vi sedan testar modellen med bilder av zebror och hästar, finns det en stor chans att modellen identifierar varje djur korrekt.
I likhet med många andra tekniker inom djupinlärning, inspireras nollskottsinlärning av hur människor lär sig och bearbetar data. Människor är i grunden nollskottsinlärare. Om du exempelvis skulle leta efter en gitarr med ihålig kropp i en musikaffär, kanske du skulle ha svårt att hitta en. Men om du får informationen att en ihålig kropp i princip är en gitarr med ett f-format ljudhål på en eller båda sidor, kommer du med stor sannolikhet att kunna hitta en direkt.
För ett praktiskt exempel kan vi använda nollskottsklassificeringsappen från LLM-värdwebbplatsen Hugging Face med öppen källkod och modellen clip-vit-large.
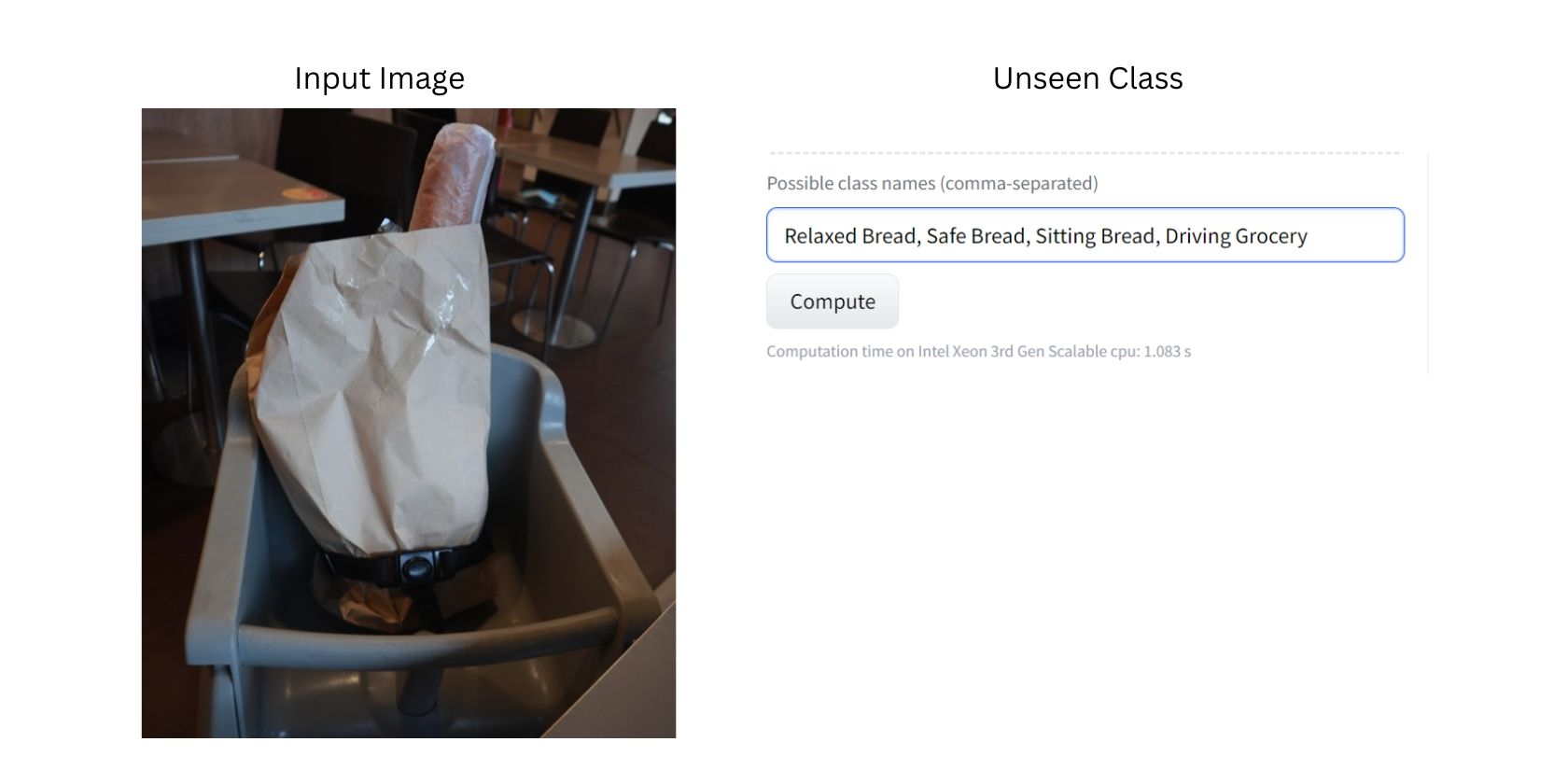
Bilden visar bröd i en matkasse som är fastspänd i en barnstol. Eftersom modellen tränats på en stor mängd bilder kan den med största sannolikhet känna igen alla objekt på bilden, såsom bröd, matvaror, stolar och säkerhetsbälten.
Nu vill vi att modellen ska klassificera bilden med hjälp av tidigare okända klasser. I det här fallet skulle de nya klasserna kunna vara ”Avslappnat bröd”, ”Säkert bröd”, ”Sittande bröd”, ”Kör matvaror” och ”Säker matvara”.
Det är viktigt att notera att vi medvetet har använt ovanliga okända klasser och bilder för att illustrera effektiviteten hos nollskottsklassificering på en bild.
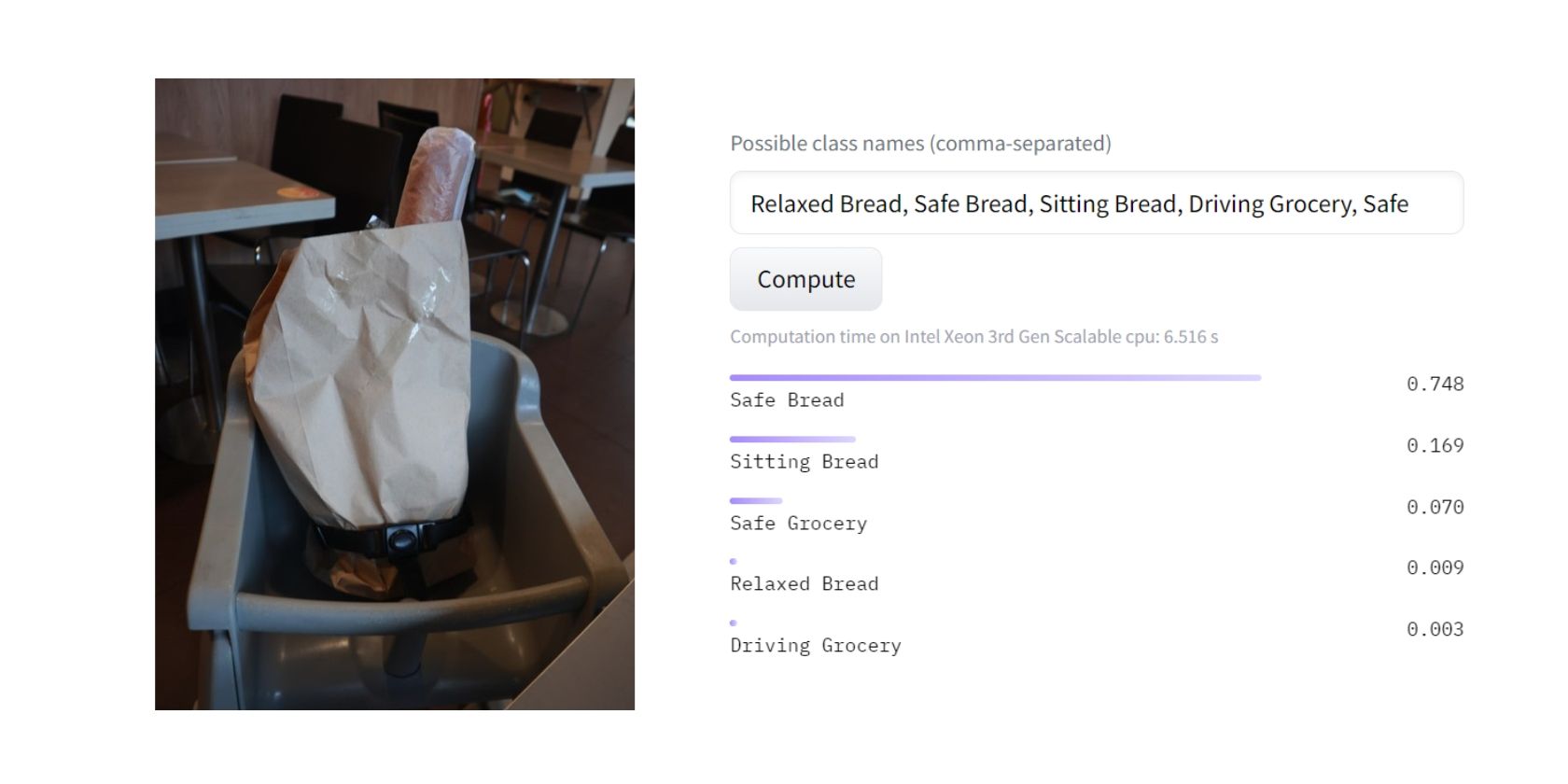
Efter att modellen analyserat bilden, kunde den med cirka 80% säkerhet fastställa att den mest passande klassificeringen var ”Säkert bröd”. Detta beror troligen på att modellen anser att en barnstol signalerar säkerhet i större utsträckning än sittande, avkoppling eller bilkörning.
Imponerande! Jag skulle personligen instämma i modellens resultat. Men exakt hur kom modellen fram till detta resultat? Här kommer en övergripande bild av hur nollskottsinlärning fungerar.
Hur fungerar nollskottsinlärning?
Nollskottsinlärning möjliggör för en förutbildad modell att identifiera nya klasser utan tillgång till märkt data. I sin mest grundläggande form består nollskottsinlärning av tre steg:
1. Förberedelse
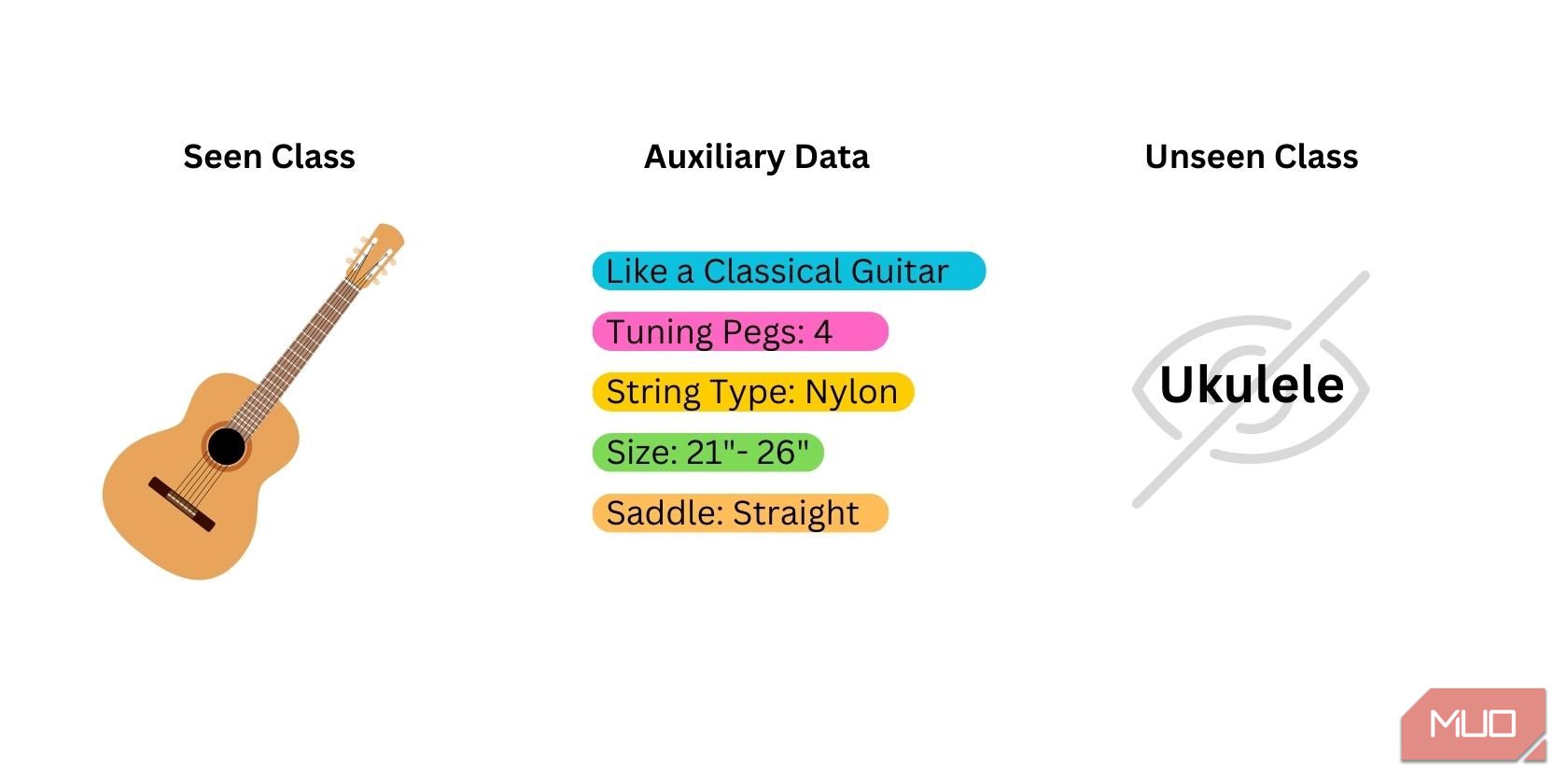
Nollskottsinlärning inleds med att förbereda tre typer av data:
- Sedda klasser: Den data som använts för att träna den förutbildade modellen. Modellen är redan bekant med dessa klasser. De bästa modellerna för nollskottsinlärning är de som tränats på klasser som är nära relaterade till den nya klass som modellen ska identifiera.
- Osedda/nya klasser: Data som aldrig använts under modellens träning. Denna data måste sammanställas manuellt eftersom den inte kan erhållas från modellen.
- Semantiska/hjälpdata: Ytterligare information som hjälper modellen att identifiera den nya klassen. Det kan vara i form av ord, fraser, ordbäddningar eller klassnamn.
2. Semantisk kartläggning
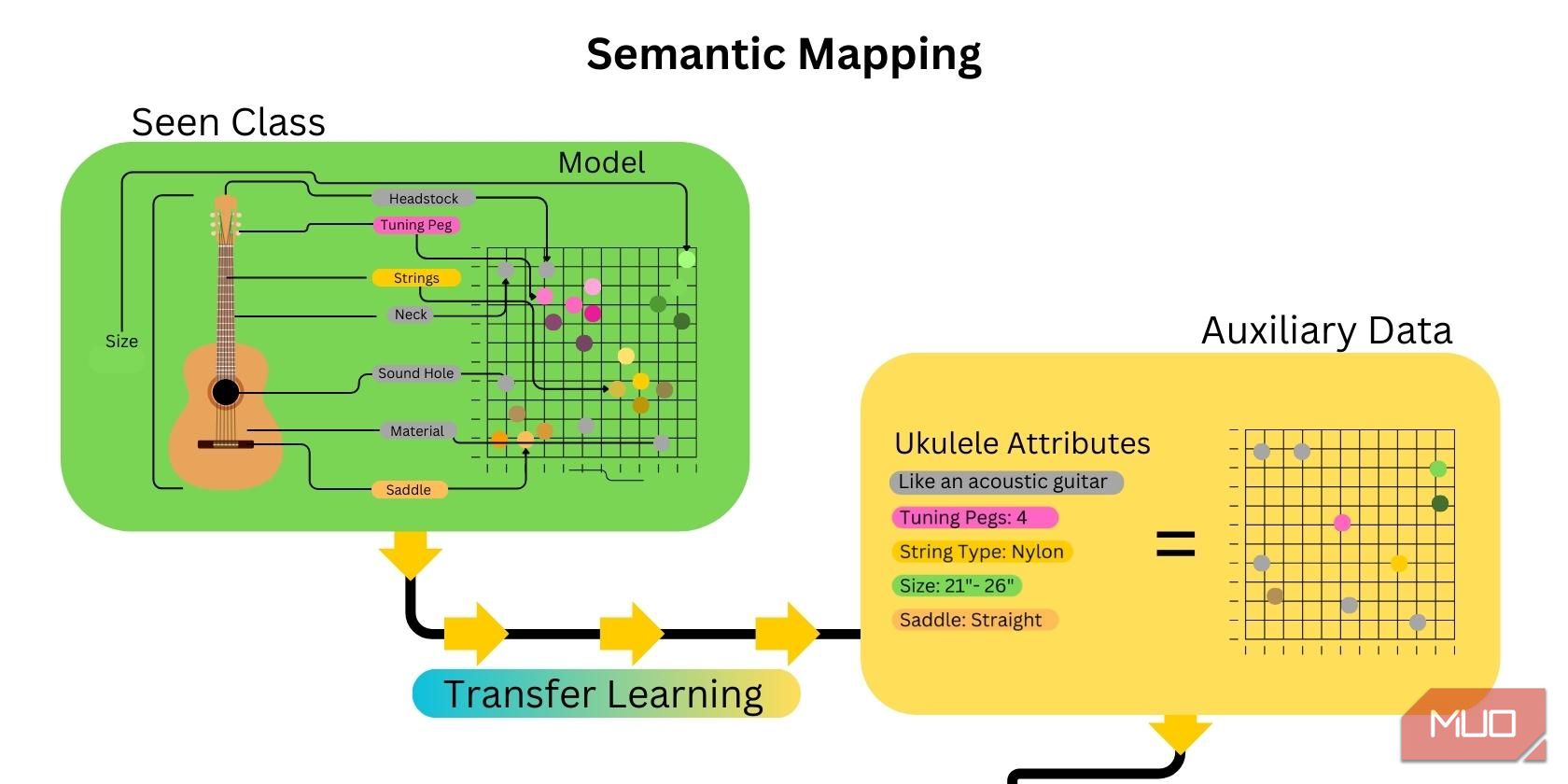
Nästa steg är att kartlägga egenskaperna hos den osedda klassen. Detta görs genom att skapa ordbäddningar och generera en semantisk karta som kopplar attributen eller egenskaperna hos den osedda klassen till den tillhandahållna hjälpdatan. Överföringsinlärning inom AI gör processen betydligt snabbare, eftersom många attribut relaterade till den osedda klassen redan har kartlagts.
3. Slutledning
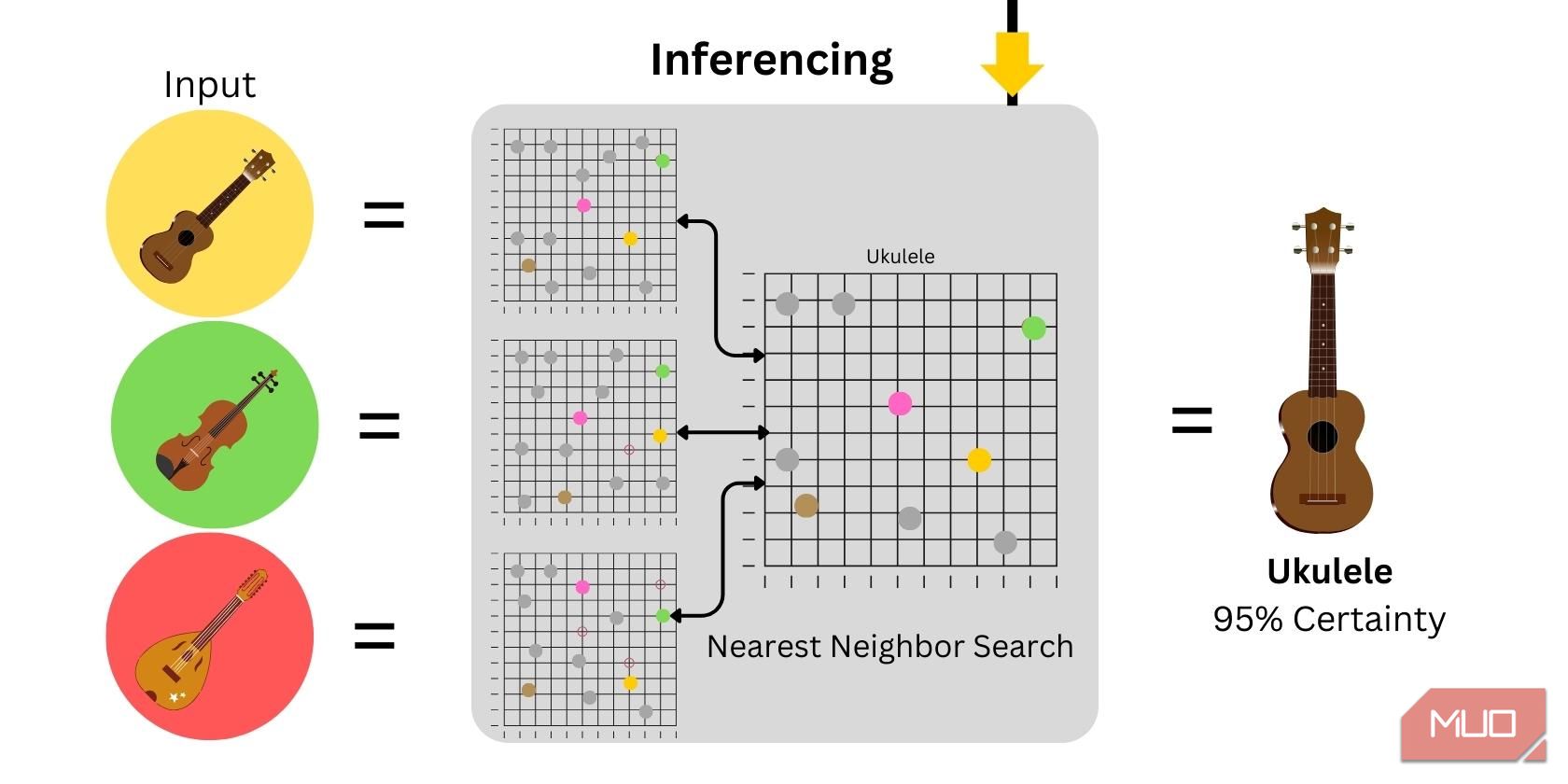
Slutledning innebär att modellen används för att generera förutsägelser eller resultat. Vid nollskottsklassificering genereras ordbäddningar utifrån den givna bildinmatningen, som sedan plottas och jämförs med hjälpdatan. Säkerhetsnivån beror på likheten mellan indata och den tillhandahållna hjälpdatan.
Hur förbättrar nollskottsinlärning AI?
Nollskottsinlärning bidrar till att förbättra AI-modeller genom att adressera flera utmaningar inom maskininlärning, inklusive:
- Förbättrad generalisering: Genom att minska beroendet av märkt data kan modeller tränas på större datamängder, vilket resulterar i förbättrad generalisering och gör modellen mer robust och pålitlig. Med mer erfarenhet och ökad generaliseringsförmåga kan det till och med vara möjligt för modeller att lära sig sunt förnuft snarare än att endast analysera information på ett konventionellt sätt.
- Skalbarhet: Modeller kan kontinuerligt tränas och utöka sin kunskap genom överföringsinlärning. Företag och oberoende forskare har möjlighet att kontinuerligt förbättra sina modeller för att göra dem mer kapabla i framtiden.
- Minskad risk för överanpassning: Överanpassning kan uppstå om en modell tränas på en liten datamängd som inte är tillräckligt varierad för att representera alla potentiella indata. Att träna modellen med nollskottsinlärning minskar risken för överanpassning genom att främja en djupare kontextuell förståelse för ämnen.
- Kostnadseffektivt: Att producera stora mängder märkt data kan vara både tids- och resurskrävande. Genom att använda nollskottsöverföringsinlärning kan en robust modell tränas på betydligt kortare tid och med mindre mängd märkt data.
I takt med att AI utvecklas kommer tekniker som nollskottsinlärning att bli allt viktigare.
Framtiden för nollskottsinlärning
Nollskottsinlärning har utvecklats till en viktig komponent inom maskininlärning. Den gör det möjligt för modeller att känna igen och klassificera nya klasser utan att ha genomgått explicit träning för dessa. Med pågående framsteg inom modellarkitektur, attributbaserade metoder och multimodal integration, kan nollskottsinlärning i hög grad bidra till att göra modeller mer anpassningsbara för att hantera komplexa utmaningar inom robotik, hälsovård och datorseende.