Linux-swappiness-värdet relaterar inte till mängden RAM som används innan systemet börjar använda swap. Det är en vanlig missuppfattning. Vi kommer nu att förklara den faktiska funktionen.
Avklara missförstånd kring swappiness
Swap är en metod där data från RAM-minnet flyttas till en särskild lagringsplats på hårddisken – antingen en swap-partition eller en swap-fil – för att skapa ledigt RAM-utrymme.
I Linux finns en inställning som kallas swappiness. Det finns mycket förvirring kring vad denna inställning egentligen styr. Den vanligaste felaktiga tolkningen är att swappiness definierar ett tröskelvärde för RAM-användning. När det använda RAM-minnet når detta värde aktiveras swap.
Detta är en felaktig idé som har upprepats så frekvent att den nu betraktas som sanning. Om (nästan) alla andra hävdar att swap fungerar på detta sätt, varför skulle du tro oss när vi säger motsatsen?
Lätt! Vi kommer att bevisa det.
RAM-minnet är indelat i zoner
Linux behandlar inte RAM som en enda stor minnespool. Istället delas det upp i flera olika områden som kallas zoner. Vilka zoner som finns i din dator beror på om det är ett 32-bitars eller 64-bitars system. Här följer en förenklad beskrivning av de möjliga zonerna på en dator med x86-arkitektur.
Direct Memory Access (DMA): Detta motsvarar de lägsta 16 MB av minnet. Zonens namn kommer från att det en gång i tiden fanns datorer som enbart kunde utföra direkt minnesåtkomst till denna del av det fysiska minnet.
Direct Memory Access 32 (DMA32): Trots namnet finns DMA32-zonen bara i 64-bitars Linux. Det utgör de lägsta 4 GB av minnet. Linux som körs på 32-bitarsdatorer kan enbart göra DMA till denna mängd RAM (om de inte använder Physical Address Extension (PAE) kärna), vilket är ursprunget till zonens namn. På 32-bitars datorer kallas denna zon även HighMem.
Normal: På 64-bitarsdatorer är normalt minne allt RAM utöver 4 GB (ungefär). På 32-bitarsmaskiner är det RAM mellan 16 MB och 896 MB.
HighMem: Denna zon finns bara på 32-bitars Linux-datorer. Det är allt RAM över 896 MB, inklusive RAM över 4 GB på datorer med tillräckligt minne.
PAGESIZE-värdet
RAM-minne allokeras i sidor med en bestämd storlek. Denna storlek bestäms av kärnan vid uppstart genom att detektera datorns arkitektur. Vanligtvis är sidstorleken på en Linux-dator 4 KB.
Du kan kontrollera din sidstorlek med kommandot getconf:
getconf PAGESIZE
Zoner är knutna till noder
Zoner är kopplade till noder. Noder är knutna till processorn (CPU). Kärnan försöker allokera minne för en process som körs på en CPU från den nod som är kopplad till den CPU:n.
Konceptet med noder kopplade till processorer gör det möjligt att installera olika minnestyper i avancerade datorer med flera processorer, där man använder sig av Non-Uniform Memory Access-arkitektur.
Detta är avancerad teknik. De flesta Linux-datorer kommer bara ha en enda nod, kallad nod noll. Alla zoner kommer att tillhöra denna nod. Du kan se noderna och zonerna i din dator genom att studera filen /proc/buddyinfo. Vi använder ”less” för att göra detta:
less /proc/buddyinfo

Här är resultatet från en 64-bitarsdator som användes i denna undersökning:
Node 0, zone DMA 1 1 1 0 2 1 1 0 1 1 3 Node 0, zone DMA32 2 67 58 19 8 3 3 1 1 1 17
Det finns bara en nod, nod noll. Denna dator har endast 2 GB RAM, så det finns ingen ”normal” zon. Endast två zoner finns, DMA och DMA32.
Varje kolumn visar antalet tillgängliga sidor av en specifik storlek. För DMA32-zonen, läser du från vänster:
2: Det finns 2 sidor med minnesstorleken 2^(0*PAGESIZE).
67: Det finns 67 sidor med minnesstorleken 2^(1*PAGE_SIZE).
58: Det finns 58 sidor med minnesstorleken 2^(2*PAGESIZE).
Och så vidare, hela vägen upp till …
17: Det finns 17 sidor med minnesstorleken 2^(512*PAGESIZE).
Huvudsyftet med att granska denna information är att förstå förhållandet mellan noder och zoner.
Filstödda och anonyma sidor
Minnesmappning använder sig av sidtabellposter för att hålla koll på vilka minnessidor som används och för vad.
Minnesmappningar kan vara:
Filstödda: Filstödda mappningar innehåller data som har lästs från en fil. Det kan vara vilken typ av fil som helst. Det viktigaste att komma ihåg är att om systemet frigör detta minne och behöver hämta datan igen, kan den läsas in från filen en gång till. Om datan har ändrats i minnet, måste dessa ändringar skrivas till filen på hårddisken innan minnet kan frigöras. Annars skulle ändringarna gå förlorade.
Anonyma: Anonymt minne är en minnesmappning utan en fil eller enhet som backar upp det. Dessa sidor kan innehålla minne som program begär för att lagra data, eller för saker som stacken och heapen. Eftersom det inte finns någon fil bakom denna typ av data, måste en särskild plats reserveras för att lagra anonym data. Den platsen är swap-partitionen eller swap-filen. Anonym data skrivs till swap innan anonyma sidor frigörs.
Enhetsstödda: Enheter nås genom blockenhetsfiler som kan behandlas som om de vore filer. Data kan läsas från dem och skrivas till dem. En enhetsstödd minnesmappning har data från en enhet lagrad i sig.
Delade: Flera sidtabellposter kan peka på samma RAM-sida. Genom att komma åt minnesplatserna via någon av dessa mappningar visas samma data. Olika processer kan kommunicera effektivt med varandra genom att ändra data i dessa delade minnesplatser. Delade, skrivbara mappningar är ett vanligt sätt att uppnå högpresterande kommunikation mellan processer.
Copy-on-write: Copy-on-write är en ”lat” allokeringsteknik. Om en kopia av en resurs som redan finns i minnet efterfrågas, tillgodoses begäran genom att en mappning returneras till den ursprungliga resursen. Om en av processerna som ”delar” resursen försöker skriva till den, måste resursen kopieras i minnet för att tillåta ändringarna att göras i den nya kopian. Minnesallokeringen sker alltså endast vid första skrivningen.
För swap är det bara de två första typerna av minnesmappningar vi behöver fokusera på: filstödda och anonyma sidor.
Swap-processen
Här är beskrivningen av swappiness från Linux-dokumentationen på GitHub:
”Denna parameter används för att bestämma hur aggressivt (sic) kärnan ska swappa minnessidor. Högre värden ökar aggressiviteten, lägre värden minskar swap-användningen. Ett värde på 0 instruerar kärnan att inte initiera swap förrän mängden lediga och filstödda sidor är mindre än högvattenmärket i en zon.”
Det låter som om swappiness ökar eller minskar hur kraftigt swap används. Intressant nog verkar det som att om du sätter swappiness till noll stängs inte swap av. Det instruerar istället kärnan att inte använda swap förrän vissa villkor är uppfyllda. Swap kan fortfarande förekomma.
Låt oss undersöka djupare. Här är definitionen och standardvärdet för vm_swappiness i kärnans källkodsfil vmscan.c:
/*
* Från 0 .. 100. Högre betyder mer swappy.
*/
int vm_swappiness = 60;
Swappiness-värdet kan variera från 0 till 100. Återigen verkar kommentaren antyda att swappiness-värdet påverkar hur mycket swap som sker, där ett högre värde leder till mer swap.
Längre ner i källkodsfilen ser vi att en variabel med namnet swappiness får ett värde som returneras av funktionen mem_cgroup_swappiness(). Ytterligare granskning av källkoden visar att värdet som returneras av denna funktion är vm_swappiness. Så variabeln swappiness är nu satt till samma värde som vm_swappiness hade.
int swappiness = mem_cgroup_swappiness(memcg);
Och lite längre ner i samma källkodsfil ser vi detta:
/*
* Med swappiness på 100 har anonym och fil samma prioritet.
* Denna skanningsprioritet är i princip den omvända av IO-kostnaden.
*/
anon_prio = byte;
fil_prio = 200 – anon_prio;
Detta är intressant. Två olika värden beräknas utifrån swappiness. Variablerna anon_prio och file_prio får dessa värden. När den ena ökar, minskar den andra, och vice versa.
Linux swappiness-värdet specificerar alltså förhållandet mellan två värden.
Det gyllene snittet
Filstödda sidor innehåller data som är enkla att hämta om minnet frigörs. Linux kan bara läsa filen igen. Som vi har nämnt, om fildata har ändrats i RAM, måste dessa ändringar skrivas till filen innan filsidan kan frigöras. Hur som helst kan filsidan i RAM återställas genom att läsa datan från filen. Så varför bry sig om att lagra dessa sidor i swap-partitionen eller swap-filen? Om du behöver informationen igen kan du lika gärna läsa tillbaka den från originalfilen istället för en redundant kopia i swap. Filsidor lagras alltså inte i swap. De lagras tillbaka i originalfilen.
Med anonyma sidor finns det ingen underliggande fil kopplad till värdena i minnet. Värdena på dessa sidor har skapats dynamiskt. Du kan inte läsa in dem från en fil. Det enda sättet som anonyma sidminnesvärden kan återställas är att lagra datan någonstans innan minnet frigörs. Och det är det swap gör. Den lagrar anonyma sidor som du kan behöva komma åt igen.
Men notera att för både fil- och anonyma sidor kan en diskoperation krävas för att frigöra minnet. Om fil- eller anonyma siddata har ändrats sedan de senast skrevs till filen eller swap, krävs en filsystemskrivning. Att hämta data kräver en läsning från filsystemet. Båda typerna av återanvändning av sidor är kostsamma. Att försöka minska diskaktiviteten genom att minimera swap av anonyma sidor ökar bara mängden diskaktivitet som krävs för att hantera filsidor som skrivs till och läses från filer.
Som du ser i det sista kodavsnittet, finns det två variabler. En kallad file_prio för ”filprioritet” och en annan som heter anon_prio för ”anonym prioritet”.
Variabeln anon_prio sätts till Linux swappiness-värde.
Värdet file_prio sätts till 200 minus anon_prio-värdet.
Dessa variabler har värden som samverkar. Om båda är inställda på 100 är de lika. För alla andra värden kommer anon_prio att minska från 100 till 0, och file_prio kommer att öka från 100 till 200. De två värdena matas in i en komplex algoritm som avgör om Linux-kärnan prioriterar återvinning (frigörande) av fil- eller anonyma sidor.
Du kan tänka dig att file_prio representerar systemets benägenhet att frigöra filsidor och anon_prio som systemets benägenhet att frigöra anonyma sidor. Dessa värden definierar inte någon form av trigger eller tröskel för när swap ska användas. Det bestäms på annat håll.
Men när minne behöver frigöras, tas dessa två variabler – och förhållandet mellan dem – i beaktande av återvinnings- och swap-algoritmerna för att bestämma vilka sidtyper som kan frigöras. Och det påverkar om den tillhörande diskaktiviteten kommer att hantera filer för filsidor eller swap för anonyma sidor.
När aktiveras swap faktiskt?
Vi har fastställt att Linux-swappiness-värdet indikerar en preferens för vilken typ av minnessidor som ska skannas för möjlig återvinning. Men vad bestämmer när swap ska aktiveras?
Varje minneszon har ett högvattensmärke och ett lågvattensmärke. Dessa är systemberäknade värden. De representerar procentandelar av RAM-minnet i varje zon. Det är dessa värden som används som tröskelvärden för att aktivera swap.
För att kontrollera dina hög- och lågvattensmärken, använd kommandot ”less” för att granska filen /proc/zoneinfo:
less /proc/zoneinfo

Varje zon har en uppsättning minnesvärden mätta i sidor. Här är värdena för DMA32-zonen på testmaskinen. Lågvattensmärket är 13966 sidor och högvattenmärket är 16759 sidor:
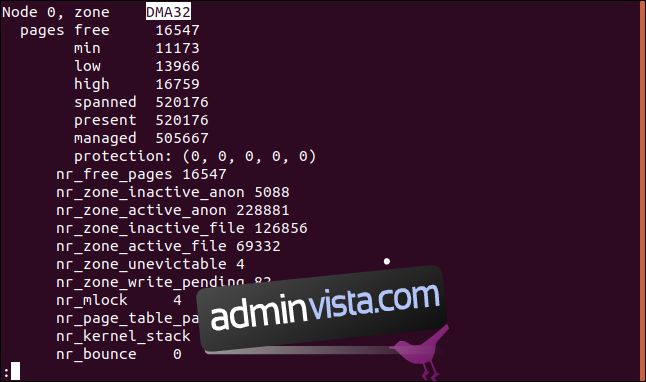
Under normal drift, när ledigt minne i en zon sjunker under zonens lågvattensmärke, börjar swap-algoritmen att skanna minnessidor och söka efter minne som kan återvinnas, med hänsyn till de relativa värdena för anon_prio och file_prio.
Om Linux swappiness-värdet är inställt på noll, kommer swap att ske när summan av fil- och lediga sidor är lägre än högvattenmärket.
Du ser alltså att du inte kan använda Linux swappiness-värdet för att påverka swap-beteendet när det gäller RAM-användning. Det fungerar helt enkelt inte på det sättet.
Vad ska swappiness vara inställt på?
Detta beror på maskinvara, arbetsbelastning, disktyp och om din dator är en stationär dator eller en server. Det är uppenbart att det inte finns en inställning som passar alla.
Du måste också komma ihåg att swap inte bara används för att frigöra RAM när minnet börjar ta slut. Swap är en viktig del av ett välfungerande system, och utan det skulle det bli svårt för Linux att uppnå en bra minneshantering.
Att ändra Linux swappiness-värde har en omedelbar effekt. Du behöver inte starta om. Så du kan göra små justeringar och övervaka effekterna. Helst bör du göra detta under en period av dagar, med olika aktiviteter på din dator, för att hitta den inställning som passar just dig bäst.
Här är några punkter att tänka på:
Att försöka ”inaktivera swap” genom att sätta Linux swappiness-värdet till noll flyttar helt enkelt den swap-relaterade diskaktiviteten till filrelaterad diskaktivitet.
Om du har gamla, mekaniska hårddiskar kan det vara värt att försöka sänka Linux swappiness-värdet för att undvika anonym sidåtervinning och minska aktiviteter på swap-partitionerna. Naturligtvis, när du sänker en inställning, ökar den andra. Att minska swap-aktivitet ökar troligen filsystemets aktivitet. Men din dator kan fungera bättre genom att gynna en metod framför den andra. Det enda sättet att veta säkert är att prova.
För dedikerade servrar, som databasservrar, kan du få vägledning från databasleverantören. Ofta har dessa program egna specialdesignade filcache- och minneshanteringsrutiner som du kan lita på. Programleverantörerna kan föreslå ett Linux swappiness-värde baserat på maskinspecifikationer och arbetsbelastning.
För vanliga datoranvändare med ganska ny maskinvara? Lämna det som det är.
Hur du ställer in Linux Swappiness-värde
Innan du ändrar ditt swappiness-värde måste du veta vad det aktuella värdet är. Om du vill minska det lite, hur mycket är då ”lite”? Du kan ta reda på det med detta kommando:
cat /proc/sys/vm/swappiness

Använd sysctl-kommandot för att konfigurera swappiness-värdet:
sudo sysctl vm.swappiness=45

Det nya värdet används direkt, ingen omstart krävs.
Om du startar om kommer swappiness-värdet att återgå till standardvärdet 60. När du har experimenterat klart och bestämt dig för ett värde du vill använda permanent, kan du göra det beständigt genom att lägga till det i filen /etc/sysctl.conf. Du kan använda valfri editor. Följande kommando redigerar filen med nano:
sudo nano /etc/sysctl.conf

När nano öppnas, scrolla till slutet av filen och lägg till den här raden. Vi använder 35 som permanent swap-värde. Ersätt detta värde med det du vill använda.
vm.swappiness=35
Spara dina ändringar och avsluta nano genom att trycka ”Ctrl+O”, sedan ”Enter” och sedan ”Ctrl+Z”.
Minneshantering är komplex
Minneshantering är komplicerad. Därför är det bäst för vanliga användare att låta kärnan hantera detta.
Det är lätt att tro att du använder mer RAM än du faktiskt gör. Verktyg som ”top” och ”free” kan ge ett felaktigt intryck. Linux kommer att använda ledigt RAM för många olika syften, till exempel diskcache. Detta ökar den ”använda” minnessiffran och minskar den ”lediga” minnessiffran. Faktum är att RAM som används som diskcache markeras som både ”använt” och ”tillgängligt” eftersom det kan återvinnas snabbt när som helst.
För den oinvigde kan det se ut som att swap inte fungerar eller att swappiness-värdet behöver ändras.
Som alltid, ligger djävulen i detaljerna. Eller, i det här fallet, kärnans swap-demon.