Google JAX, eller Just After Execution, är ett ramverk skapat av Google för att öka hastigheten på maskininlärningsprocesser.
Tänk på det som ett Python-bibliotek som underlättar snabbare utförande av beräkningar, vetenskapliga analyser, funktionsomvandlingar, djupinlärning, neurala nätverk och mycket mer.
Om Google JAX
Det mest grundläggande beräkningsverktyget i Python är NumPy, som har funktioner för aggregering, vektoroperationer, linjär algebra, n-dimensionella matriser och matrismanipulationer, plus en mängd andra avancerade funktioner.
Men vad händer om vi kunde påskynda de beräkningar som görs med NumPy ännu mer – särskilt för stora datamängder?
Finns det något som skulle fungera lika bra på olika typer av processorer, som en GPU eller TPU, utan att vi behöver ändra koden?
Och tänk om systemet automatiskt kunde utföra sammansatta funktionstransformationer mer effektivt?
Google JAX är ett bibliotek (eller ramverk, som Wikipedia kallar det) som gör just det och kanske ännu mer. Det är designat för att optimera prestanda och effektivt hantera maskininlärning (ML) och djupinlärningsuppgifter. Google JAX erbjuder följande transformationsfunktioner, vilket skiljer det från andra ML-bibliotek och underlättar avancerad vetenskaplig beräkning för djupinlärning och neurala nätverk:
- Automatisk differentiering
- Automatisk vektorisering
- Automatisk parallellisering
- Just-in-time (JIT) kompilering
Google JAX unika egenskaper
Alla transformationer använder XLA (Accelerated Linear Algebra) för förbättrad prestanda och minnesoptimering. XLA är en domänspecifik optimerande kompilatormotor som utför linjär algebra och accelererar TensorFlow-modeller. Att använda XLA ovanpå din Python-kod kräver inga större kodändringar!
Låt oss utforska var och en av dessa funktioner mer detaljerat.
Funktioner i Google JAX
Google JAX kommer med viktiga, sammansättningsbara transformationsfunktioner för att förbättra prestanda och hantera djupinlärningsuppgifter effektivare. Till exempel, automatisk differentiering för att hitta gradienten av en funktion och derivator av vilken ordning som helst. På samma sätt, automatisk parallellisering och JIT för att utföra flera uppgifter samtidigt. Dessa transformationer är centrala för applikationer inom robotik, spel och även forskning.
En sammansättningsbar transformationsfunktion är en ren funktion som omvandlar en uppsättning data till en annan form. De kallas sammansättningsbara eftersom de är oberoende (dvs. dessa funktioner har inga beroenden till resten av programmet) och är tillståndslösa (dvs. samma inmatning ger alltid samma utmatning).
Y(x) = T: (f(x))
I ekvationen ovan är f(x) den ursprungliga funktionen som en transformation tillämpas på. Y(x) är den resulterande funktionen efter att transformationen har tillämpats.
Till exempel, om du har en funktion som heter ’total_bill_amt’ och du vill ha resultatet som en funktionstransform, kan du enkelt använda den transformation du önskar, till exempel gradient:
grad_total_bill = grad(total_bill_amt)
Genom att transformera numeriska funktioner med verktyg som grad() kan vi enkelt få deras högre ordningens derivator, vilka vi kan använda flitigt i optimeringsalgoritmer för djupinlärning, som gradientnedstigning, vilket gör algoritmerna snabbare och mer effektiva. På liknande sätt kan vi, genom att använda jit(), kompilera Python-program just-in-time.
#1. Automatisk differentiering
Python använder autograd-funktionen för att automatiskt differentiera NumPy och inbyggd Python-kod. JAX använder en modifierad version av autograd (dvs. grad) och kombinerar XLA (Accelerated Linear Algebra) för att utföra automatisk differentiering och hitta derivator av valfri ordning för GPU (Graphic Processing Units) och TPU (Tensor Processing Units).
En kort notis om TPU, GPU och CPU: CPU (Central Processing Unit) hanterar alla datorns operationer. GPU är en extra processor som ökar datorkraften och kör avancerade operationer. TPU är en kraftfull enhet som är särskilt utvecklad för komplexa och tunga arbetsbelastningar, som AI och djupinlärningsalgoritmer.
På samma sätt som autograd-funktionen, som kan differentiera genom loopar, rekursioner, förgreningar och så vidare, använder JAX funktionen grad() för gradienter i omvänt läge (backpropagation). Vi kan även differentiera en funktion till vilken ordning som helst med grad:
grad(grad(grad(sin θ))) (1.0)
Automatisk differentiering av högre ordning
Som vi nämnde tidigare är grad mycket användbart för att hitta partiella derivator av en funktion. Vi kan använda partiella derivator för att beräkna gradientnedstigningen för en kostnadsfunktion med avseende på de neurala nätverksparametrarna vid djupinlärning för att minimera förluster.
Beräkning av partiella derivator
Anta att en funktion har flera variabler, x, y och z. Att hitta derivatan av en variabel medan de andra hålls konstanta kallas en partiell derivata. Anta att vi har funktionen,
f(x,y,z) = x + 2y + z2
Exempel för att illustrera partiell derivata
Den partiella derivatan av x kommer att vara ∂f/∂x, vilket visar hur en funktion förändras för en variabel när de andra är konstanta. Om vi gör detta manuellt skulle vi behöva skriva ett program för att differentiera, tillämpa det på varje variabel och sedan beräkna gradientnedstigningen. Detta skulle bli en komplex och tidskrävande uppgift för flera variabler.
Automatisk differentiering delar upp funktionen i en uppsättning elementära operationer, som +, -, *, / eller sin, cos, tan, exp osv., och tillämpar sedan kedjeregeln för att beräkna derivatan. Vi kan göra detta i både framåt- och bakåtriktning.
Och det är inte allt! Alla dessa beräkningar sker snabbt (tänk på en miljon beräkningar som de ovan och hur lång tid det kan ta!). XLA tar hand om hastigheten och prestandan.
#2. Accelererad linjär algebra
Låt oss ta den föregående ekvationen. Utan XLA kommer beräkningen att ta tre (eller fler) kärnor, där varje kärna kommer att utföra en mindre uppgift. Till exempel,
Kärna k1 –> x * 2y (multiplikation)
k2 –> x * 2y + z (addition)
k3 –> Reduktion
Om samma uppgift utförs av XLA tar en enda kärna hand om alla mellanliggande operationer genom att slå ihop dem. Mellanresultaten av elementära operationer strömmas istället för att lagras i minnet, vilket sparar minne och ökar hastigheten.
#3. Just-in-time-kompilering
JAX använder internt XLA-kompilatorn för att öka exekveringshastigheten. XLA kan öka hastigheten på CPU, GPU och TPU. Allt detta är möjligt med JIT-kodexekvering. För att använda detta kan vi använda jit via import:
from jax import jit def my_function(x): …………några rader med kod my_function_jit = jit(my_function)
Ett annat sätt är att dekorera jit över funktionsdefinitionen:
@jit def my_function(x): …………några rader med kod
Denna kod är mycket snabbare eftersom transformationen kommer att returnera den kompilerade versionen av koden till anroparen istället för att använda Python-tolken. Detta är särskilt användbart för vektorinmatning, som arrayer och matriser.
Samma sak gäller alla befintliga Python-funktioner, till exempel funktioner från NumPy-paketet. I detta fall ska vi importera jax.numpy som jnp istället för NumPy:
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
När du har gjort detta ersätter JAX-arrayobjektet, som kallas DeviceArray, standardmatrisen NumPy. DeviceArray är lat – värdena hålls i acceleratorn tills de behövs. Det innebär också att JAX-programmet inte väntar på att resultaten ska återgå till det anropande (Python) programmet, utan skickas asynkront.
#4. Automatisk vektorisering (vmap)
I en typisk maskininlärningsmiljö har vi datamängder med en miljon eller fler datapunkter. Förmodligen skulle vi utföra några beräkningar eller manipulationer på var och en av eller de flesta av dessa datapunkter – vilket är en mycket tid- och minneskrävande uppgift! Om du till exempel vill hitta kvadraten för var och en av datapunkterna i datamängden är det första du skulle tänka på att skapa en loop och ta kvadraten en efter en – suck!
Om vi skapar dessa punkter som vektorer, kan vi göra alla kvadrater på en gång genom att utföra vektor- eller matrismanipulationer på datapunkterna med vår favorit NumPy. Och om ditt program kunde göra detta automatiskt – kan du önska dig något mer? Det är precis vad JAX gör! Det kan automatiskt vektorisera alla dina datapunkter så att du enkelt kan utföra alla operationer på dem – vilket gör dina algoritmer mycket snabbare och effektivare.
JAX använder vmap-funktionen för autovektorisering. Tänk på följande array:
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
Genom att göra bara ovanstående kommer kvadratmetoden att köras för varje punkt i arrayen. Men om du gör följande:
vmap(jnp.square(x))
Kvadratmetoden kommer endast att köras en gång eftersom datapunkterna nu vektoriseras automatiskt med vmap-metoden innan funktionen körs, och looping flyttas ner till den elementära operationsnivån – vilket resulterar i en matrisoperation istället för en skalär multiplikation, vilket ger bättre prestanda.
#5. SPMD-programmering (pmap)
SPMD – eller Single Program Multiple Data-programmering är viktigt i djupinlärningssammanhang – du använder ofta samma funktioner på olika uppsättningar data som finns på flera GPU:er eller TPU:er. JAX har en funktion som heter pmap, vilket möjliggör parallell programmering på flera GPU:er eller vilken accelerator som helst. Precis som JIT kommer program som använder pmap att kompileras av XLA och köras samtidigt på flera system. Denna automatiska parallellisering fungerar för både framåt- och bakåtberäkningar.
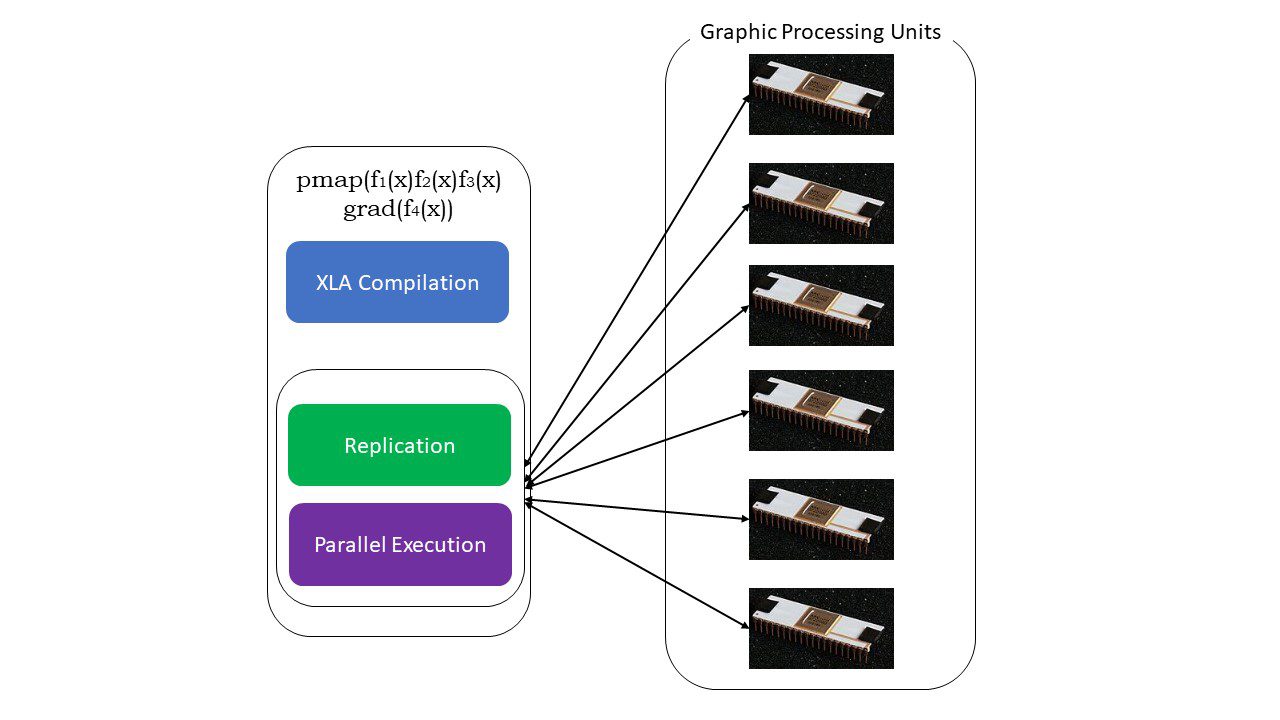 Hur fungerar pmap
Hur fungerar pmap
Vi kan också tillämpa flera transformationer i vilken ordning som helst på vilken funktion som helst:
pmap(vmap(jit(grad (f(x)))))
Flera sammansättningsbara transformationer
Begränsningar för Google JAX
Google JAX-utvecklare har noggrant tänkt på att påskynda algoritmer för djupinlärning samtidigt som de introducerat alla dessa fantastiska transformationer. De vetenskapliga beräkningsfunktionerna och paketen är i linje med NumPy, så du behöver inte oroa dig för inlärningskurvan. JAX har dock följande begränsningar:
- Google JAX är fortfarande i ett tidigt utvecklingsstadium, och även om dess huvudsakliga syfte är prestandaoptimering, ger det inte mycket fördelar för CPU-beräkningar. NumPy verkar prestera bättre, och att använda JAX kan öka overheaden.
- JAX befinner sig fortfarande i ett forsknings- eller tidigt stadium och behöver mer finjustering för att nå infrastrukturstandarderna för ramverk som TensorFlow, som är mer etablerade och har fler fördefinierade modeller, projekt med öppen källkod och läromedel.
- För närvarande stöder JAX inte operativsystemet Windows – du skulle behöva en virtuell maskin för att få det att fungera.
- JAX fungerar bara med rena funktioner – de som inte har några bieffekter. För funktioner med bieffekter kanske JAX inte är ett bra alternativ.
Hur man installerar JAX i din Python-miljö
Om du har Python installerat på ditt system och vill köra JAX på din lokala dator (CPU), använd följande kommandon:
pip install --upgrade pip pip install --upgrade "jax[cpu]"
Om du vill köra Google JAX på en GPU eller TPU, följ instruktionerna på GitHub JAX-sidan. För att ställa in Python, besök Pythons officiella nedladdningssida.
Slutsats
Google JAX är utmärkt för att skriva effektiva algoritmer för djupinlärning, robotik och forskning. Trots sina begränsningar används det flitigt med andra ramverk som Haiku, Lin och många fler. Du kommer att kunna uppskatta vad JAX gör när du kör program och ser skillnaden i tid vid exekvering av kod med och utan JAX. Du kan börja med att läsa officiell Google JAX-dokumentation, som är ganska omfattande.