

Databasskärning är en teknik för att uppnå horisontell skalbarhet i storskaliga system.
Nästan alla verkliga system består av en databasserver som tar emot många läsbegäranden och en icke försumbar mängd skrivbegäranden. Detta kan överbelasta servern och kan hämma systemets prestanda.
För att mildra sådana effekter och förbättra ett systems prestanda finns det tillvägagångssätt som databasreplikering och databasskärning. I den här guiden kommer vi först att utforska tekniker för att förbättra systemets prestanda, inklusive:
- Skala upp databasservern
- Databasreplikering
- Horisontell partitionering
Efter att ha diskuterat dessa tekniker kommer vi att fortsätta att lära oss hur databasdelning fungerar och även titta på fördelarna och begränsningarna med detta tillvägagångssätt.
Låt oss börja!
Innehållsförteckning
Tekniker för att förbättra systemets prestanda
Låt oss börja med att diskutera tekniker för att förbättra systemets prestanda när det finns flaskhalsar på grund av databasservern:
#1. Skala upp databasservern
Att skala upp databasserverinstansen kan verka som en enkel metod för att förbättra systemets prestanda. Detta inkluderar att förbättra processorkraften, lägga till mer RAM och liknande.
Denna teknik kommer dock med följande begränsning. Vi kan inte ha en server med oändlig lagring och processorkraft. Och bortom en viss gräns får vi minskande avkastning.
#2. Databasreplikering
När databasserverinstansens överbelastning uppstår på grund av inkommande förfrågningar kan vi överväga databasreplikering.
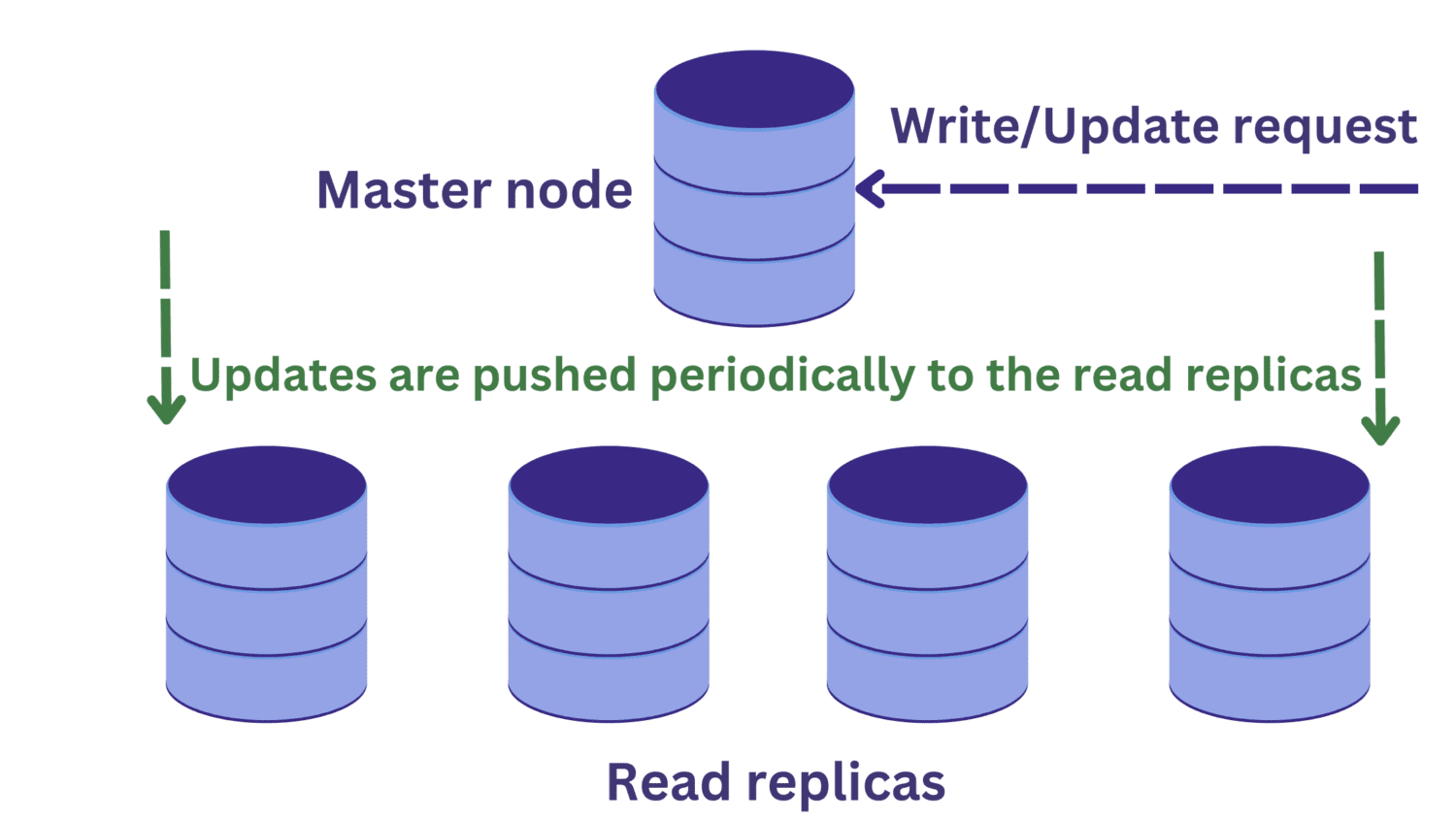
Under databasreplikering har vi en huvudnod som vanligtvis tar emot skrivförfrågningar. Det finns flera lästa repliker.
Detta förbättrar tillgängligheten och minskar systemöverbelastning. Vi kan nu behandla flera frågor parallellt eftersom läsbegäran kan dirigeras till en av läsreplikerna.
Men detta introducerar ett annat problem. Skrivförfrågningar till masternoden kan ändra data, och dessa uppdateringar sprids med jämna mellanrum till läsreplikerna.
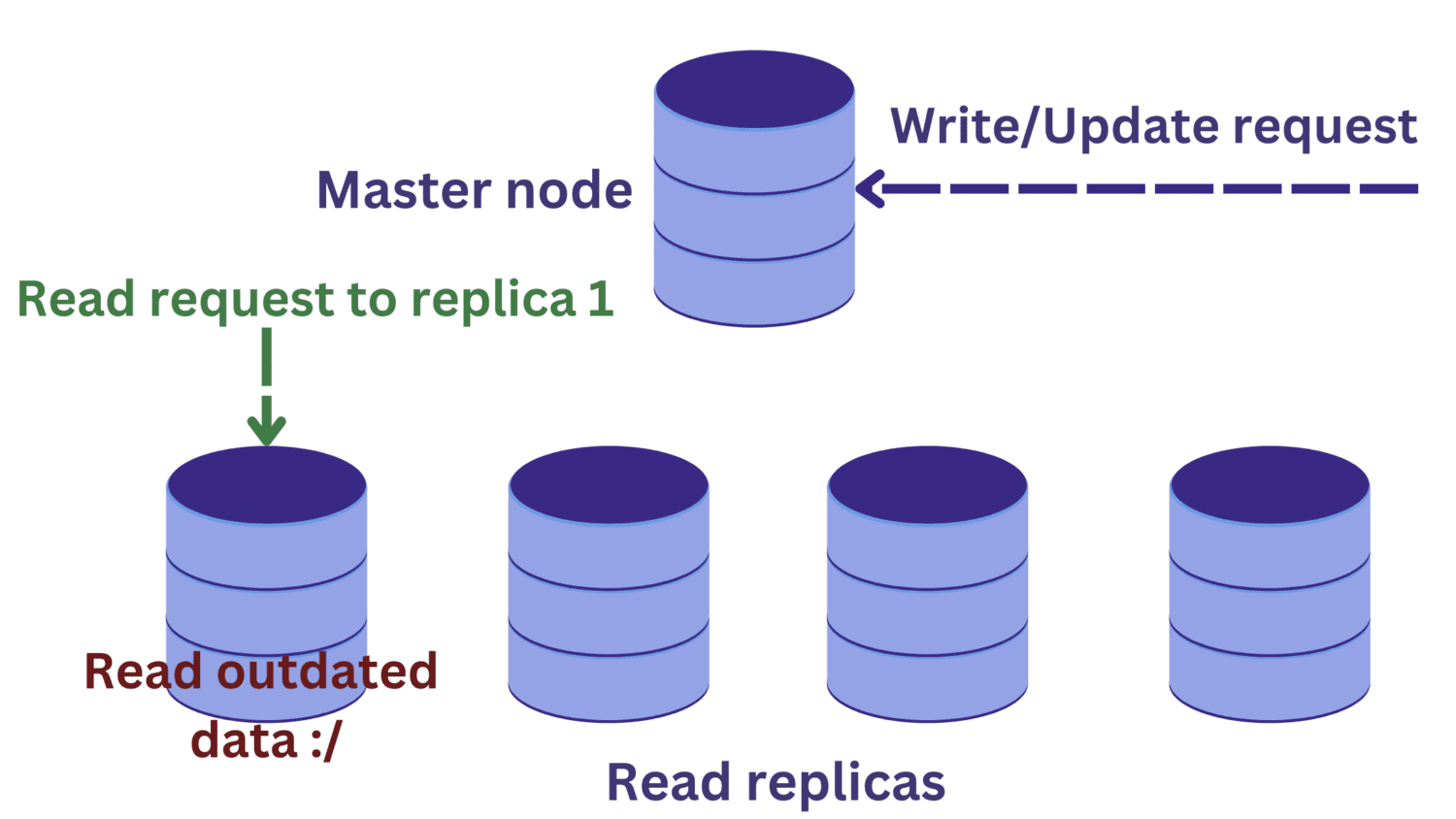
Antag att det finns en läsbegäran till en av läsreplikerna samtidigt som en skrivoperation pågår vid masternoden.
Ändringarna i huvudnoden kommer inte att ha spridits till de lästa replikerna ännu. I det här fallet kan vi läsa inaktuella data, vilket inte är önskvärt.
#3. Horisontell partitionering
Horisontell partitionering är en annan teknik för att optimera systemets prestanda. Vi kan ha en enda stor tabell med miljarder rader (som en tabell över kunder och transaktionsdata).
Läsoperationerna från en sådan databastabell är långsammare. Men genom att använda horisontell partitionering är den enda stora tabellen nu uppdelad i flera partitioner (eller mindre tabeller) som vi kan läsa från. Relationsdatabaser som PostgreSQL stöder partitionering.
Men alla partitioner finns fortfarande i en enda databasserverinstans. Den enda skillnaden är att vi nu kan läsa från partitionerna istället för den enda stora tabellen.
Därför, när det finns en ökning av antalet inkommande förfrågningar, kanske servern inte kan stödja den ökade efterfrågan.
Hur fungerar databasdelning?
Nu när vi har diskuterat metoderna för att förbättra systemets prestanda och deras begränsningar, låt oss förstå hur databasdelning fungerar.
Vid skärning delar vi upp den enda stora databasen i flera mindre databaser, som var och en körs på en databasserverinstans. Varje sådan mindre databas kallas en shard. Och varje skärva innehåller en unik delmängd av data.
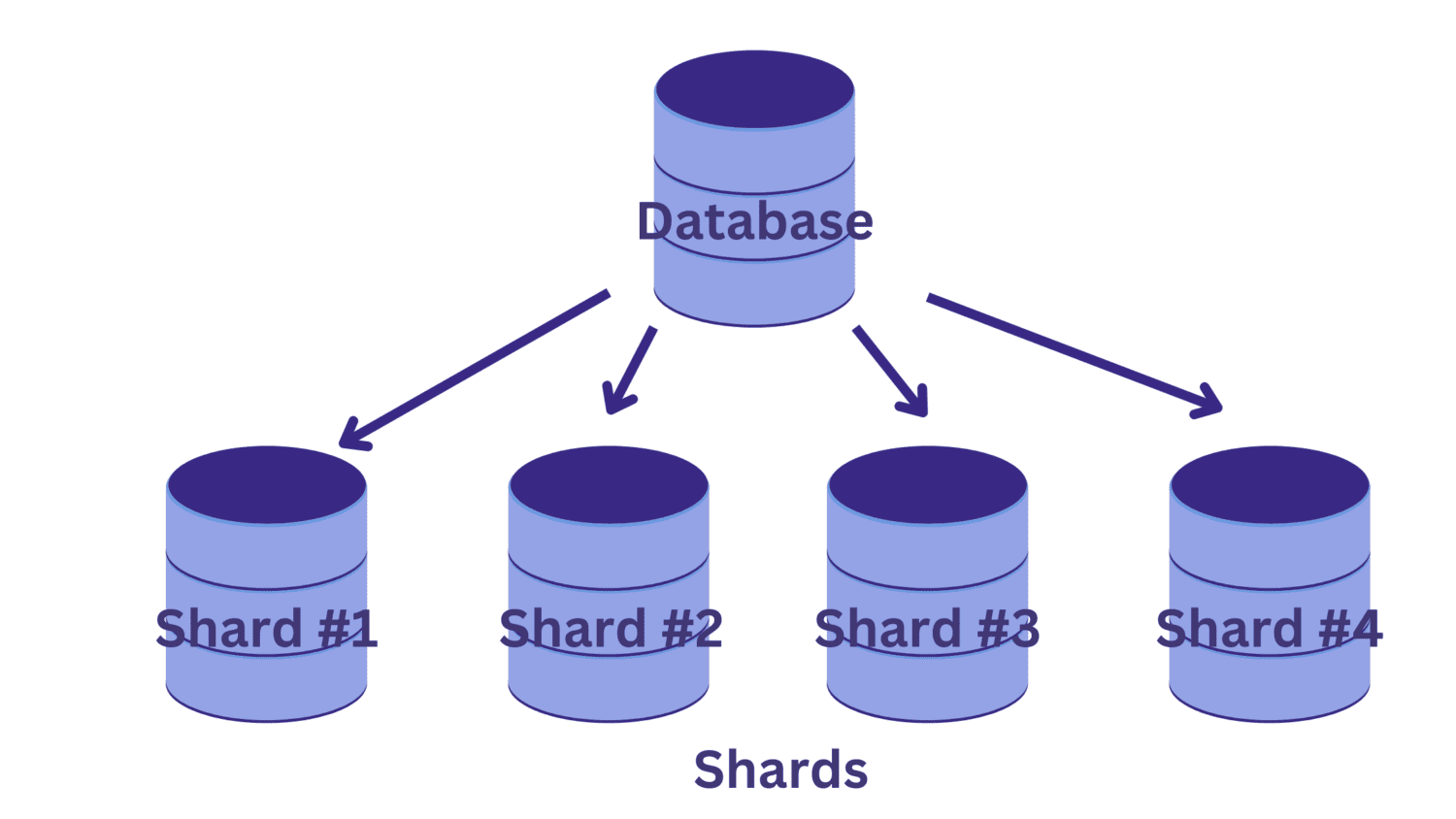
Men hur delar vi upp databasen i skärvor? Och hur bestämmer vi vilken av raderna som går in i vilken av skärvorna?
🔑 Ange sönderdelningsnyckeln.
Förstå Sharding Key
Låt oss förstå rollen av skärningsnyckeln.
Sharding-nyckeln, som vanligtvis är en kolumn (eller en kombination av kolumner) i databastabellen, bör väljas så att fördelningen av data är jämn över flera shards. För vi vill inte att en viss skärva ska vara mycket större än de andra skärvorna.
I en databas som lagrar data om kunder och transaktioner är customer_ID en bra kandidat för sharding-nyckeln.
När vi har bestämt oss för skärningsnyckeln kan vi komma på en hashfunktion som bestämmer vilken av raderna som går in i vilken av skärvorna.
I det här exemplet, säg att vi måste dela upp databasen i fem shards (shard #0 till shard #4) med kund_ID som sharding-nyckel. I det här fallet är en enkel hashfunktion kund_ID % 5.
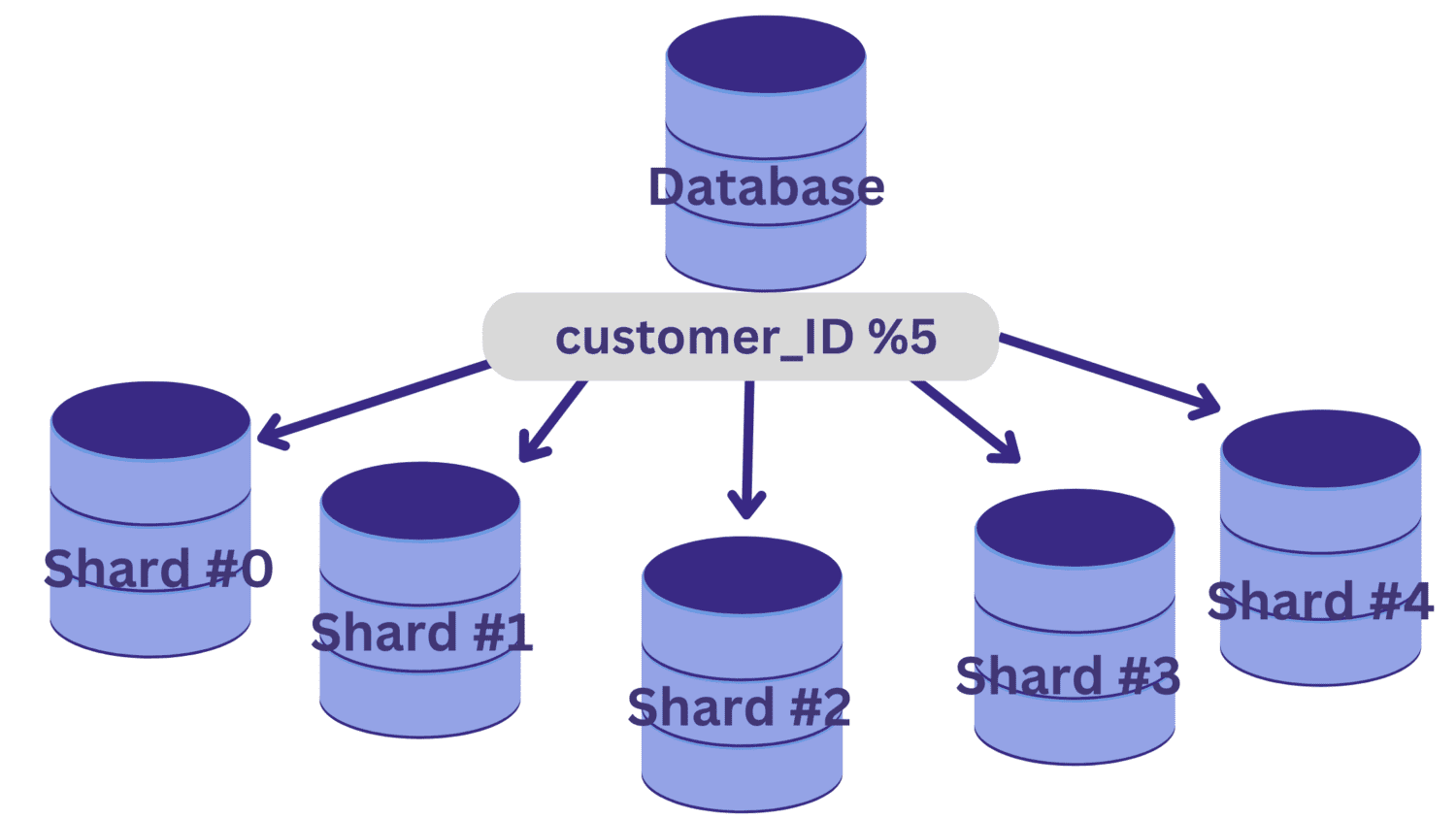
Alla customer_ID-värden som lämnar en rest av noll när de divideras med 5 kommer att mappas till shard #0. Och customer_ID-värden som lämnar resterna 1 till 4 kommer att mappas till shard #1 till shard #4, respektive.
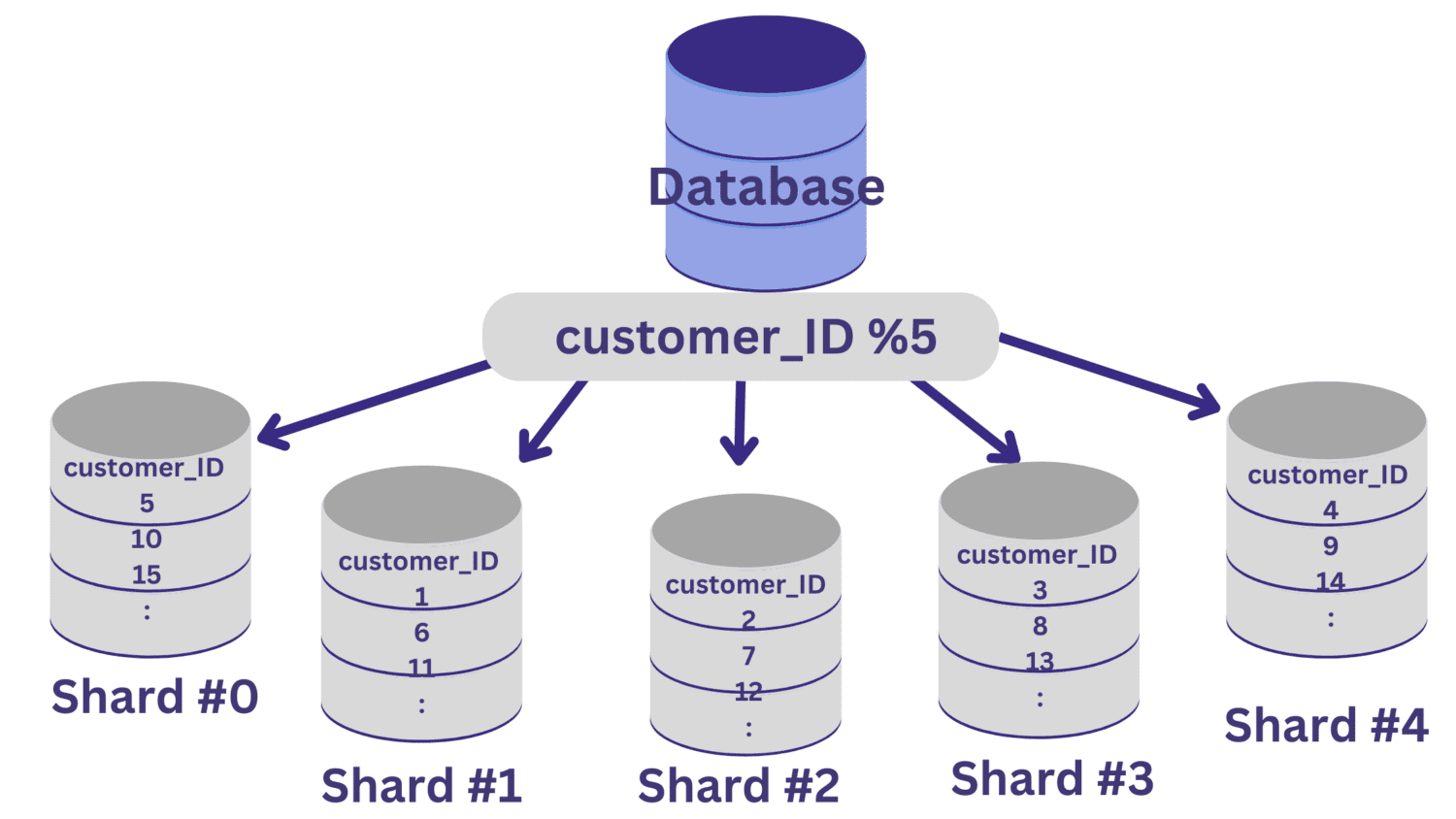
Efter att databasdelningen har implementerats på det här sättet är det viktigt att ha ett routinglager som dirigerar inkommande förfrågningar till rätt databasfragment.
Fördelar med databasdelning
Här är några av fördelarna med databasskärning:
#1. Hög skalbarhet
Det är alltid möjligt att dela en större databas i flera mindre skärvor. Så databasskärning tillåter oss att skala ut horisontellt.
#2. Hög tillgänglighet
När det finns en enda databasserverinstans som hanterar alla inkommande förfrågningar har vi en enda felpunkt. Om databasservern är nere är hela applikationen nere.
Med databasskärning är sannolikheten att alla databasskärvor ligger nere vid ett givet ögonblick relativt låg. Därför, om ett visst fragment är nere, kommer vi inte att kunna behandla läsbegäranden till det fragmentet. Men de andra skärvorna kan fortfarande behandla de inkommande förfrågningarna. Detta resulterar i hög tillgänglighet och ökad feltolerans.
Begränsningar för databasdelning
Låt oss nu gå igenom några av begränsningarna för databasdelning:
#1. Komplexitet
Även om skärning har fördelar när det gäller skalbarhet och feltolerans, introducerar det komplexitet i systemet.
Från att mappa poster till partitioner till att implementera routinglagret för att dirigera frågor till respektive shards, det är avsevärd komplexitet involverad i sharding av databaser.
#2. Omhärdning
En annan begränsning av skärning är behovet av omskärning.
Även om vi använder hashfunktion för att få en jämn fördelning av dataposter, är det möjligt att en av skärvorna är mycket större än de andra skärvorna, och den kan bli uttömd tidigare. I det här fallet måste vi ta hänsyn till omdelning (eller omblandning), och det kommer med betydande omkostnader.
#3. Kör komplexa frågor
När du behöver köra frågor för analys som involverar kopplingar måste du använda poster från flera skärvor i motsats till en enda databas. Så det här kan vara en utmaning när du behöver köra för många analytiska frågor. Du kan komma runt detta genom att avnormalisera databaser, men det kräver fortfarande en del ansträngning!
Slutsats
Låt oss avsluta diskussionen med en sammanfattning av vad vi har lärt oss.
Att skala upp hårdvaran är inte alltid optimalt. Så att förbättra serverinstansen rekommenderas inte. Vi har också granskat tekniker som databasreplikering och horisontell partitionering och deras begränsningar.
Sedan lärde vi oss hur databasdelning fungerar genom att dela upp en stor databas i mindre och lätthanterliga skärvor. Vi diskuterade hur skärningsnyckeln bör väljas noggrant för att få jämna partitioner och behovet av ett routinglager för att dirigera de inkommande förfrågningarna till rätt databasskärva.
Databasdelning har fördelar som hög tillgänglighet och skalbarhet. Några av nackdelarna inkluderar komplexiteten i att sätta upp skärning och omskärning när en eller flera skärvor blir uttömda.
Så du kan överväga skärning när du tror att fördelarna överväger komplexiteten som introduceras av skärning. Kolla sedan in jämförelsen av de olika AWS relationsdatabaserna.