Introduktion till Support Vector Machines (SVM)
Support Vector Machine, eller SVM, är en framstående algoritm inom maskininlärning. Dess effektivitet och förmåga att lära sig från begränsade datamängder gör den mycket användbar. Men vad innebär det egentligen att arbeta med en SVM?
Vad är en Support Vector Machine (SVM)?
En Support Vector Machine är en maskininlärningsalgoritm som nyttjar övervakad inlärning för att konstruera en modell avsedd för binär klassificering. Det kan verka komplext, men i denna artikel ska vi göra SVM-konceptet tydligt och undersöka dess relevans inom området för naturlig språkbehandling. Låt oss först titta närmare på hur en stödvektormaskin fungerar.
Hur fungerar SVM?
Föreställ dig ett enkelt klassificeringsproblem där vi har data som består av två attribut, x och y, och en klassificering som kan vara antingen röd eller blå. Vi kan visualisera en sådan datamängd på följande sätt:
Givet en sådan datamängd är målet att skapa en beslutsgräns. En beslutsgräns är en linje som avskiljer de två klasserna av datapunkter. Med en sådan gräns kan vi avgöra vilken klass en ny datapunkt tillhör, baserat på dess placering relativt beslutsgränsen. Algoritmen för Support Vector Machine är inriktad på att identifiera den optimala beslutsgränsen för klassificering.
Men vad betyder ”optimal” i det här sammanhanget?
Den optimala beslutsgränsen kan beskrivas som den som maximerar avståndet till de närmaste datapunkterna i varje klass, kallade stödvektorer. Stödvektorerna är de datapunkter som ligger närmast den motsatta klassen och därmed utgör den största risken för felklassificering.
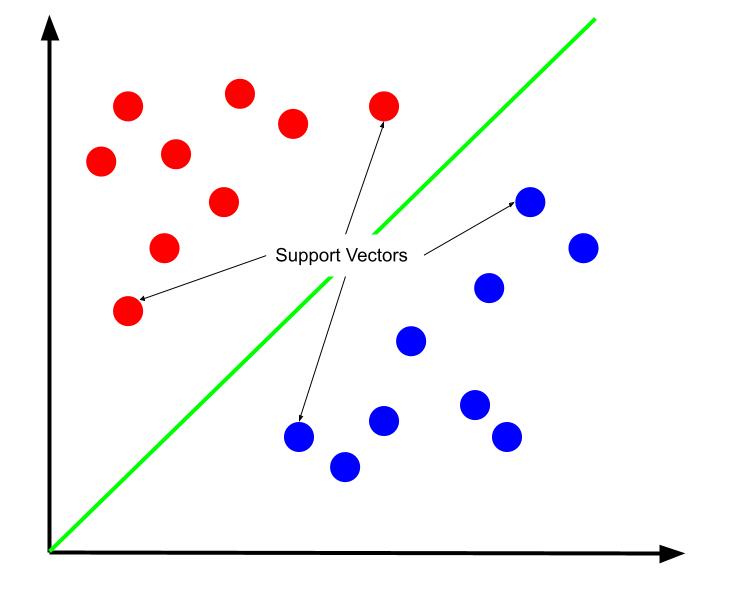
Att träna en stödvektormaskin handlar alltså om att finna den linje som ger största möjliga marginal mellan stödvektorerna.
Det är även viktigt att notera att beslutsgränsens position bestäms enbart av stödvektorerna. Övriga datapunkter har ingen inverkan på gränsens position, vilket innebär att träningsprocessen kan fokusera på dessa avgörande datapunkter.
I det här exemplet är beslutsgränsen en rät linje, vilket beror på att datamängden bara har två attribut. Om datamängden har tre attribut, utgörs beslutsgränsen av ett plan snarare än en linje. Vid fyra eller fler attribut kallas beslutsgränsen för ett hyperplan.
Icke-linjärt Separerbar Data
Det tidigare exemplet handlade om data som kunde separeras med en linjär beslutsgräns. Men om vi tar ett fall där data är ordnad enligt följande:
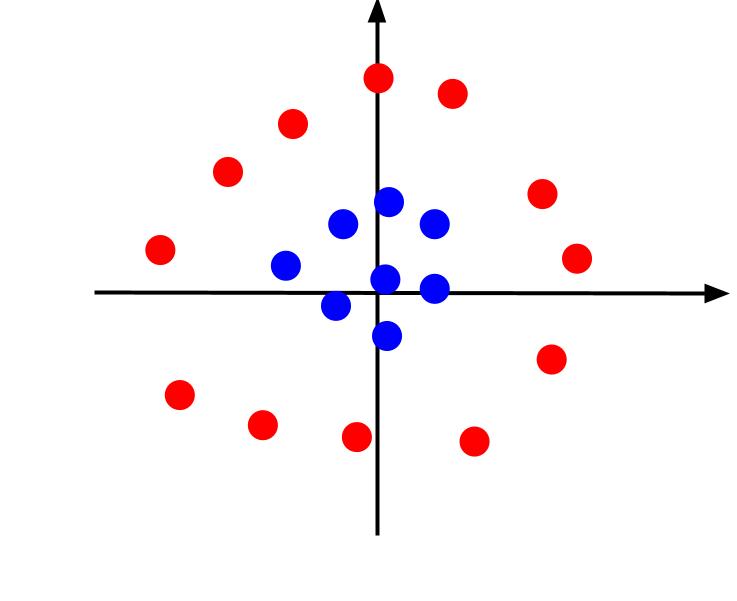
I det här fallet kan vi inte separera data med en linje. Vi kan dock skapa en ny funktion, z, där z = x² + y². Genom att lägga till z som en tredje axel skapas en tredimensionell vy.
När vi betraktar 3D-diagrammet med x-axeln horisontell och z-axeln vertikal, ser det ut som följer:
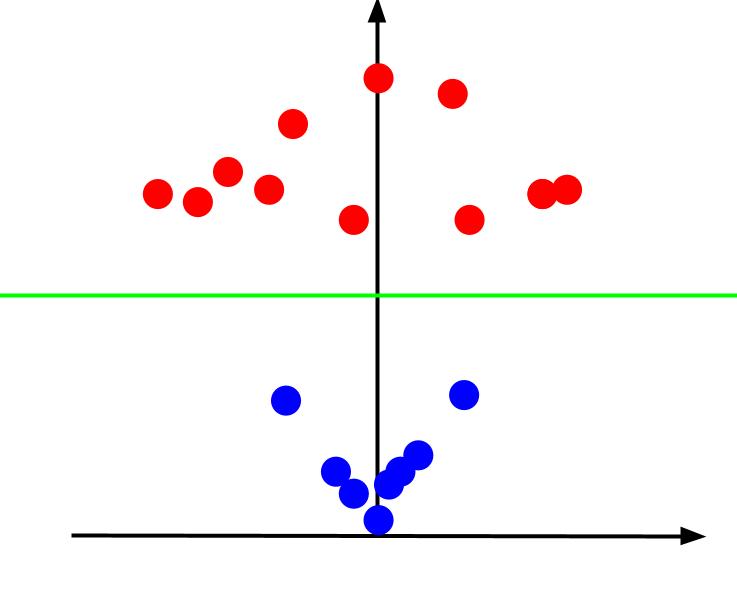
Z-värdet representerar avståndet från origo i det gamla xy-planet. De blå punkterna, som ligger närmare origo, får låga z-värden, medan de röda, som ligger längre bort, får högre värden. Denna representation gör att vi kan separera klasserna med en linjär beslutsgräns.
Detta är en central idé i Support Vector Machines. I praktiken handlar det om att projicera data till högre dimensioner så att datapunkter kan separeras med en linjär gräns. De funktioner som utför denna projicering kallas kärnfunktioner. Exempel på sådana funktioner är sigmoid, linjär, icke-linjär och RBF.
För att effektivisera beräkningarna vid användning av dessa funktioner utnyttjar SVM ett kärntrick.
SVM inom Maskininlärning
Support Vector Machine är en viktig algoritm inom maskininlärning, jämsides med exempelvis beslutsträd och neurala nätverk. Dess fördelar inkluderar dess förmåga att hantera mindre datamängder jämfört med andra algoritmer. Några av de vanliga användningsområdena för SVM inkluderar:
- Textklassificering: Att kategorisera textdata som kommentarer och recensioner.
- Ansiktsigenkänning: Att identifiera ansikten i bilder, vilket kan användas för att lägga till filter i förstärkt verklighet.
- Bildklassificering: Att kategorisera bilder på ett effektivt sätt.
Utmaningen med Textklassificering
Internet är fyllt med stora mängder textdata. Denna data är ofta ostrukturerad och omärkt. För att dra nytta av denna data behöver vi kunna klassificera den. Exempel på tillfällen då textklassificering är relevant är:
- Att kategorisera tweets i ämnen.
- Att kategorisera e-post i sociala, kampanjer och skräppost.
- Att kategorisera kommentarer i hatiska eller stötande på offentliga forum.
Hur SVM Fungerar med Naturlig Språkklassificering
Support Vector Machines används för att sortera text som antingen tillhör ett visst ämne eller inte. Detta uppnås genom att omvandla textdata till en datamängd med flera funktioner.
Ett sätt att göra detta är att skapa en funktion för varje unikt ord i datamängden. Sedan registrerar man hur många gånger varje ord förekommer i varje textdatapost. Om det finns unika ord, kommer man ha funktioner.
Man behöver också ange klassificeringar för datapunkterna. Även om dessa etiketter initialt kan vara textbaserade, kräver de flesta SVM-implementeringar numeriska etiketter. Därför måste dessa etiketter omvandlas till siffror innan träningen startar. När datamängden är förberedd med de omvandlade funktionerna som koordinater, kan man använda en SVM-modell för att klassificera texten.
Skapa en SVM i Python
För att skapa en Support Vector Machine (SVM) i Python kan man använda klassen SVC från biblioteket sklearn.svm. Nedan följer ett exempel på hur man kan använda klassen SVC för att bygga en SVM-modell:
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
# Ladda datamängden
X = ...
y = ...
# Dela upp data i tränings- och testuppsättningar
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=19)
# Skapa en SVM-modell
model = SVC(kernel="linear")
# Träna modellen på träningsdata
model.fit(X_train, y_train)
# Utvärdera modellen på testdata
accuracy = model.score(X_test, y_test)
print("Accuracy: ", accuracy)
I detta exempel importerar vi först klassen SVC från biblioteket sklearn.svm. Därefter laddar vi datamängden och delar upp den i tränings- och testuppsättningar.
Vi skapar sedan en SVM-modell genom att instansiera ett SVC-objekt och specificerar kärnparametern som ’linjär’. Sedan tränar vi modellen på träningsdata med metoden fit och utvärderar modellen på testdata med metoden score. Resultatet är modellens noggrannhet, som vi skriver ut i konsolen.
Det är också möjligt att ange andra parametrar för SVC-objektet, som exempelvis C-parametern som styr styrkan i regulariseringen, samt gammaparametern som styr kärnkoefficienten för specifika kärnor.
Fördelar med SVM
Här är en lista med några av fördelarna med att använda Support Vector Machines:
- Effektiva: SVM är generellt effektiva vid träning, särskilt vid stora datamängder.
- Robusthet mot brus: SVM är relativt robusta mot brus i träningsdata tack vare att de försöker hitta en maximal marginalklassificerare.
- Minneseffektiva: SVM kräver endast att en delmängd av träningsdata finns i minnet vid en given tidpunkt.
- Effektiva i högdimensionella utrymmen: SVM kan prestera bra även när antalet funktioner överstiger antalet sampel.
- Mångsidighet: SVM kan användas för både klassificerings- och regressionsuppgifter samt hantera olika typer av data, inklusive både linjära och icke-linjära.
Låt oss nu utforska några av de bästa resurserna för att lära sig Support Vector Machine (SVM).
Lärresurser
En Introduktion till Stödvektormaskiner
Denna bok ger en omfattande och gradvis introduktion till kärnbaserade inlärningsmetoder. Den ger en stabil grund inom teorin för Support Vector Machines.
Stödvektormaskiner – Applikationer
Medan den första boken fokuserade på teorin bakom Support Vector Machines, undersöker den här boken deras praktiska tillämpningar. Den behandlar användningen av SVM inom bildbehandling, mönsterigenkänning och datorseende.
Stödvektormaskiner (informationsvetenskap och statistik)
Syftet med denna bok är att ge en översikt över principerna bakom effektiviteten hos Support Vector Machines (SVM) i olika sammanhang. Författarna lyfter fram flera faktorer som bidrar till SVM:s framgång, inklusive deras förmåga att prestera väl med ett begränsat antal justerbara parametrar, deras motståndskraft mot olika typer av fel samt deras effektiva beräkningsprestanda.
Inlärning med Kärnor
“Learning with Kernels” är en bok som introducerar läsaren till Support Vector Machines och relaterade kärntekniker. Boken är utformad för att ge en grundläggande förståelse för den matematik som ligger bakom kärnalgoritmer. Målet är att ge en omfattande, men lättillgänglig introduktion till SVM och kärnmetoder.
Stödvektormaskiner med Sci-kit Learn
Den här onlinekursen från Coursera lär ut hur man implementerar en SVM-modell med hjälp av maskininlärningsbiblioteket Sci-Kit Learn.

Man får också lära sig teorin bakom SVM och bestämma deras styrkor och begränsningar. Kursen är på nybörjarnivå och tar ungefär 2,5 timmar.
Stödvektormaskiner i Python: Koncept och Kod
Den här betalda onlinekursen från Udemy ger upp till 6 timmars videoundervisning och innehåller ett certifikat.

Kursen täcker SVM och hur de kan implementeras i Python, samt affärstillämpningar för Support Vector Machines.
Maskininlärning och AI: Stödvektormaskiner i Python
I den här kursen kommer du att lära dig att använda Support Vector Machines för olika praktiska tillämpningar, inklusive bildigenkänning, spamdetektion, medicinsk diagnostik och regressionsanalys.

Du kommer att använda programmeringsspråket Python för att implementera ML-modeller för dessa applikationer.
Sammanfattning
I denna artikel har vi berört teorin bakom Support Vector Machines. Vi har gått igenom deras tillämpningar inom maskininlärning och naturlig språkbehandling. Vi har även sett hur implementeringen ser ut med hjälp av scikit-learn, diskuterat praktiska tillämpningar och fördelarna med SVM.
Denna artikel har endast gett en introduktion, men de rekommenderade resurserna ovan kan ge en djupare förståelse för Support Vector Machines. Med tanke på deras mångsidighet och effektivitet, är SVM väl värda att lära sig för att utvecklas som dataforskare och ML-ingenjör.
Du kan också kolla in de bästa maskininlärningsmodellerna för att fördjupa din kunskap.