Bearbetning av stora datamängder utgör en av de största utmaningarna för många organisationer. Komplexiteten ökar ytterligare när det handlar om stora volymer av data som genereras i realtid.
I denna artikel ska vi utforska vad stordatabearbetning innebär, hur den går till samt ta en närmare titt på Apache Kafka och Spark – två av de mest framstående verktygen för databearbetning!
Vad är databearbetning och hur utförs den?
Databearbetning kan definieras som varje handling eller serie av handlingar som utförs, antingen automatiskt eller manuellt. I grund och botten handlar det om att samla in, strukturera och organisera information på ett logiskt sätt för att underlätta tolkning.
När en användare gör en sökning i en databas och får tillbaka resultat, är det databearbetningen som levererar de önskade svaren. Informationen som presenteras som sökresultat är direkt resultatet av databearbetning. Därför kan databearbetning ses som kärnan i informationsteknikens existens.
Traditionell databearbetning genomfördes med hjälp av enkel programvara. Men i takt med att konceptet ”Big Data” blivit alltmer aktuellt, har förutsättningarna förändrats. Big Data syftar på informationsmängder som kan sträcka sig från hundratals terabyte till petabyte.
Dessutom uppdateras denna information regelbundet, exempelvis data från kontaktcenter, sociala medier eller börshandel. Den här typen av data kallas ibland för dataströmmar – en kontinuerlig och oavbruten flod av data. Ett kännetecken för dessa strömmar är att de saknar definierade gränser, vilket gör det svårt att säga när de börjar eller slutar.
Data bearbetas direkt när de når sin destination, vilket vissa experter kallar realtids- eller onlinebearbetning. Ett annat tillvägagångssätt är batch-, block- eller offlinebearbetning, där datamängder bearbetas under tidsfönster på timmar eller dagar. Batchbearbetning utförs ofta under natten för att sammanställa dagens data. Det finns även fall med tidsfönster på en vecka eller månad, vilket resulterar i mindre aktuella rapporter.
Med tanke på att de mest effektiva plattformarna för big databearbetning via strömning, som Kafka och Spark, är öppen källkod, möjliggör de användning av olika, kompletterande verktyg. Det innebär att de utvecklas snabbare och integrerar fler verktyg. På så sätt kan dataströmmar tas emot från olika källor med varierande hastigheter och utan avbrott.
Låt oss nu granska två av de mest välkända verktygen för databearbetning och jämföra dem:
Apache Kafka
Apache Kafka är ett meddelandesystem som skapar strömningsapplikationer med kontinuerligt dataflöde. Kafka, som ursprungligen utvecklades av LinkedIn, är loggbaserat. En logg är en grundläggande form av lagring där all ny information läggs till i slutet av filen.
Kafka är en av de främsta lösningarna för stordatahantering, främst på grund av sin höga genomströmning. Med Apache Kafka är det till och med möjligt att transformera batchbearbetning till realtidsbearbetning.
Apache Kafka är ett publicerings- och prenumerationssystem där en applikation publicerar meddelanden och en prenumererande applikation tar emot dem. Tiden mellan publicering och mottagning kan vara så kort som millisekunder, vilket gör Kafka till en lösning med låg latens.
Så fungerar Kafka
Apache Kafkas arkitektur består av producenter, konsumenter och själva klustret. En producent är varje applikation som skickar meddelanden till klustret. En konsument är varje applikation som tar emot meddelanden från Kafka. Kafka-klustret är en uppsättning noder som fungerar som en enda instans av meddelandetjänsten.
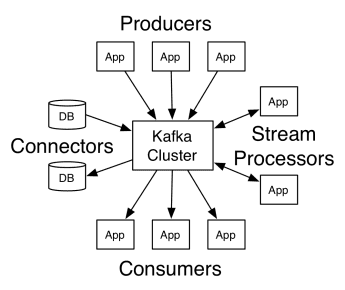
Ett Kafka-kluster består av flera mäklare. En mäklare är en Kafka-server som tar emot meddelanden från producenter och skriver dem till disk. Varje mäklare hanterar en lista med ämnen, och varje ämne är indelat i flera partitioner.
Efter att ha mottagit meddelandena skickar mäklaren dem till de prenumererande konsumenterna för respektive ämne.
Inställningarna för Apache Kafka hanteras av Apache Zookeeper, som lagrar klustermetadata som partitionsplats, namnlista, ämnen och tillgängliga noder. Zookeeper ser alltså till att synkroniseringen bibehålls mellan de olika elementen i klustret.
Zookeeper är viktig eftersom Kafka är ett distribuerat system, där skrivning och läsning sker av flera klienter samtidigt. Om ett fel uppstår väljer Zookeeper en ersättare och återställer driften.
Användningsområden
Kafka har blivit populärt, särskilt som ett meddelandeverktyg, men dess mångsidighet gör att det kan användas i en mängd olika scenarier, som illustreras av exemplen nedan.
Meddelanden
En asynkron kommunikationsmetod som kopplar bort parterna som kommunicerar. I den här modellen skickar en part data som ett meddelande till Kafka, som en annan applikation sedan konsumerar.
Aktivitetsspårning
Möjliggör lagring och bearbetning av data som spårar en användares interaktion med en webbplats, såsom sidvisningar, klick, datainmatning, etc. Den här typen av aktivitet genererar vanligtvis stora mängder data.
Mätvärden
Innebär insamling av data och statistik från flera källor för att skapa en centraliserad rapport.
Loggsammanställning
Centraliserar och lagrar loggfiler från andra system.
Strömbearbetning
Bearbetning av datapipelines som består av flera steg, där rådata konsumeras från ämnen och aggregeras, berikas eller omvandlas till andra ämnen.
För att stödja dessa funktioner tillhandahåller plattformen huvudsakligen tre API:er:
- Streams API: Fungerar som en strömprocessor som konsumerar data från ett ämne, transformerar det och skriver det till ett annat.
- Connectors API: Tillåter anslutning av ämnen till befintliga system, som relationsdatabaser.
- Producent- och konsument-API:er: Tillåter applikationer att publicera och konsumera Kafka-data.
Fördelar
Replikerat, partitionerat och ordnat
Meddelanden i Kafka replikeras över partitioner i klusternoder i den ordning de tas emot för att garantera säkerhet och leveranshastighet.
Datatransformering
Med Apache Kafka är det möjligt att transformera batchbearbetning i realtid med hjälp av batch ETL streams API.
Sekventiell diskåtkomst
Apache Kafka lagrar meddelanden på disk, inte i minnet, eftersom det är avsett att vara snabbt. Även om minnesåtkomst i de flesta fall är snabbare, särskilt vid slumpmässig åtkomst, har Kafka sekventiell åtkomst där disken är mer effektiv.
Apache Spark
Apache Spark är en stordataberäkningsmotor och en uppsättning bibliotek för att bearbeta parallella data över kluster. Spark är en vidareutveckling av Hadoop och programmeringsparadigmet Map-Reduce. Det kan vara upp till 100 gånger snabbare tack vare den effektiva användningen av minnet, som inte lagrar data på diskar under bearbetningen.
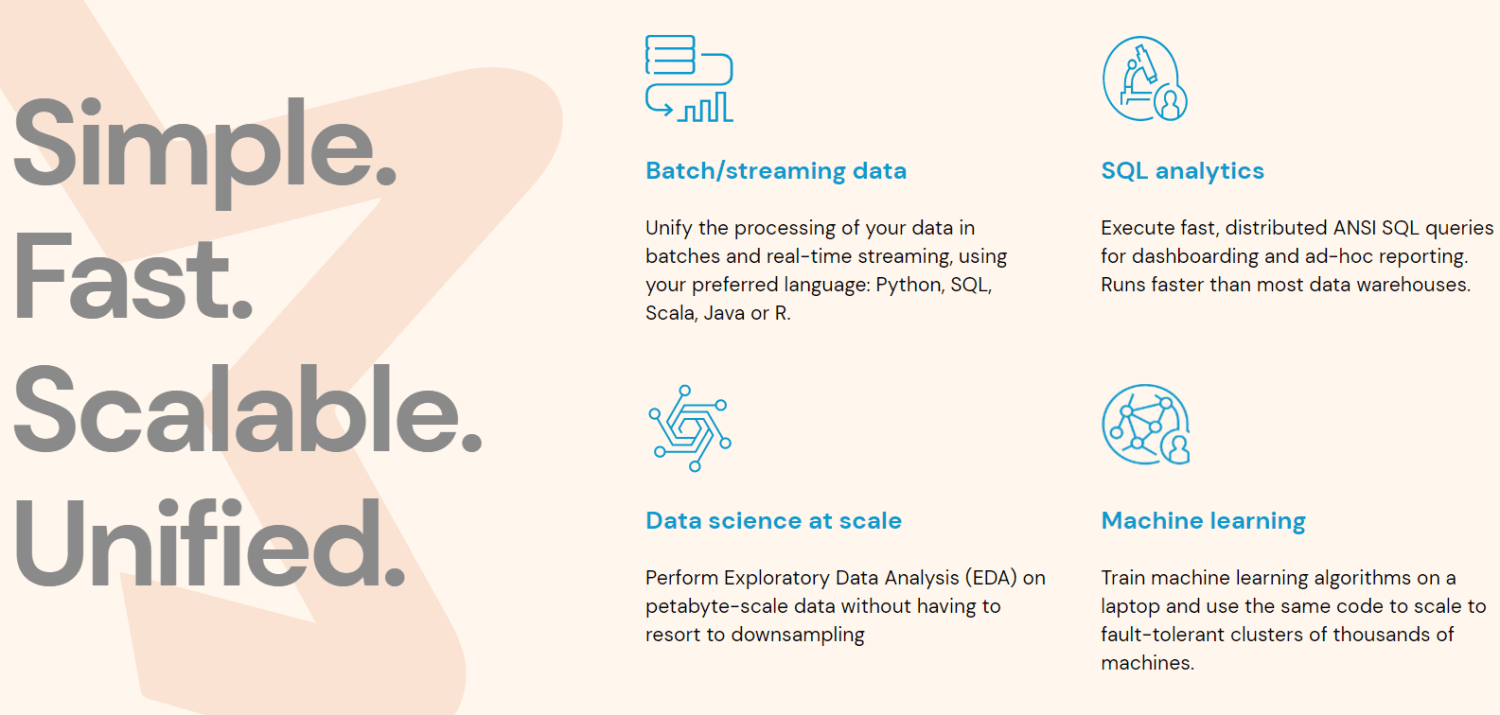
Spark är organiserat på tre nivåer:
- API:er på låg nivå: Denna nivå innehåller grundläggande funktioner för att köra jobb och annan funktionalitet som krävs av andra komponenter. Andra viktiga funktioner är hantering av säkerhet, nätverk, schemaläggning och logisk åtkomst till filsystem som HDFS, GlusterFS, Amazon S3 och andra.
- Strukturerade API:er: Den strukturerade API-nivån hanterar datamanipulation med hjälp av DataSets eller DataFrames, som kan läsas i format som Hive, Parquet, JSON och andra. Med hjälp av SparkSQL (ett API som låter oss skriva frågor i SQL) kan vi manipulera data på det sätt vi önskar.
- Hög nivå: På den högsta nivån finns Spark-ekosystemet med olika bibliotek, inklusive Spark Streaming, Spark MLlib och Spark GraphX. De ansvarar för att hantera strömningsintag och relaterade processer, som kraschåterställning, skapa och validera klassiska maskininlärningsmodeller samt hantera grafer och algoritmer.
Hur Spark fungerar
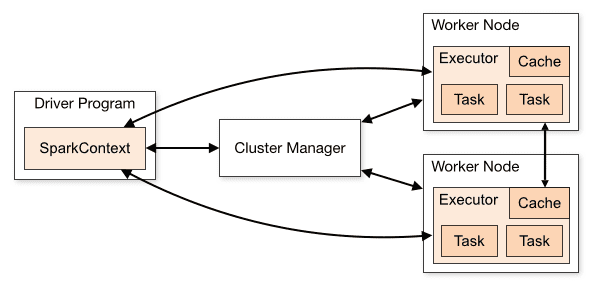
Arkitekturen för en Spark-applikation består av tre huvudsakliga delar:
Drivrutinsprogram: Ansvarar för att samordna utförandet av databearbetningen.
Cluster Manager: Komponenten som hanterar de olika maskinerna i ett kluster. Den behövs endast om Spark körs distribuerat.
Arbetsnoder: De maskiner som utför uppgifterna i ett program. Om Spark körs lokalt på din maskin, kommer den att spela rollen som både drivrutinsprogram och Workes. Detta sätt att köra Spark kallas Fristående.
Spark-kod kan skrivas på flera olika språk. Spark-konsolen, kallad Spark Shell, är interaktiv för inlärning och utforskning av data.
En så kallad Spark-applikation består av ett eller flera jobb, vilket möjliggör stöd för storskalig databearbetning.
När det gäller utförande har Spark två lägen:
- Klient: Drivrutinen körs direkt på klienten, utan att gå via resurshanteraren.
- Kluster: Drivrutinen körs på Application Master via Resurshanteraren (i klusterläge fortsätter applikationen att köras även om klienten kopplas bort).
Det är viktigt att använda Spark korrekt så att länkade tjänster, som resurshanteraren, kan identifiera behovet för varje exekvering, vilket ger optimal prestanda. Det är upp till utvecklaren att avgöra det bästa sättet att köra sina Spark-jobb, strukturera anropet och konfigurera utförarna efter behov.
Spark-jobb använder i första hand minnet, vilket gör det vanligt att justera Spark-konfigurationsvärden för exekutorer för arbetsnoder. Beroende på Spark-arbetsbelastningen kan man fastställa att en viss icke-standardiserad Spark-konfiguration ger bättre exekveringar. Därför kan jämförelsetester göras mellan de olika konfigurationsalternativen och själva standard Spark-konfigurationen.
Användningsområden
Apache Spark hjälper till att bearbeta enorma mängder data, oavsett om de är i realtid eller arkiverade, strukturerade eller ostrukturerade. Följande är några av de vanligaste användningsområdena.
Databerikning
Företag använder ofta en kombination av historiska kunddata med beteendedata i realtid. Spark kan bidra till att bygga en kontinuerlig ETL-pipeline för att omvandla ostrukturerad händelsedata till strukturerad data.
Upptäckt av utlösande händelser
Spark Streaming möjliggör snabb upptäckt och respons på sällsynt eller misstänkt beteende, som kan tyda på ett potentiellt problem eller bedrägeri.
Analys av komplex sessionsdata
Med hjälp av Spark Streaming kan händelser kopplade till en användarsession, som deras aktiviteter efter inloggning i applikationen, grupperas och analyseras. Den här informationen kan också användas kontinuerligt för att uppdatera maskininlärningsmodeller.
Fördelar
Iterativ bearbetning
Om uppgiften är att bearbeta data upprepade gånger, tillåter Sparks Resilient Distributed Dataset (RDD) flera kartoperationer i minnet utan att behöva skriva interimsresultat till disken.
Grafbearbetning
Sparks beräkningsmodell med GraphX API är utmärkt för iterativa beräkningar som är typiska för grafbearbetning.
Maskininlärning
Spark har MLlib – ett inbyggt maskininlärningsbibliotek som har färdiga algoritmer som också körs i minnet.
Kafka kontra Spark
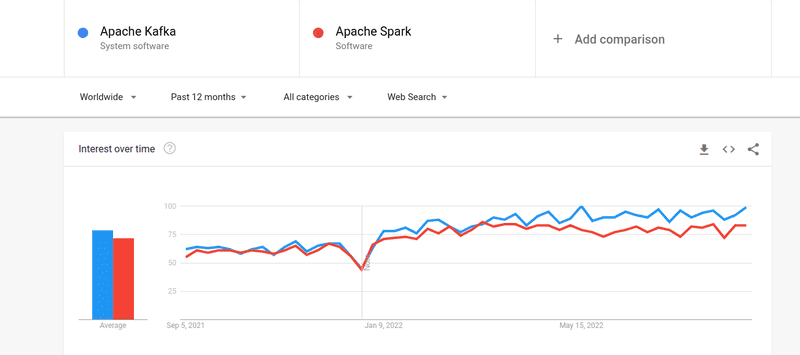
Även om intresset för både Kafka och Spark har varit ungefär lika stort, finns det några avgörande skillnader mellan de två. Låt oss undersöka dem.
#1. Databearbetning
Kafka är ett verktyg för strömning och lagring av data i realtid, ansvarigt för att överföra data mellan applikationer, men det är inte tillräckligt för att bygga en komplett lösning. Därför krävs andra verktyg för uppgifter som Kafka inte hanterar, som exempelvis Spark. Spark, å andra sidan, är en plattform som i första hand bearbetar data i batchar. Den hämtar data från Kafka-ämnen och omvandlar den till kombinerade scheman.
#2. Minneshantering
Spark använder Robust Distributed Dataset (RDD) för minneshantering. I stället för att försöka bearbeta enorma datamängder distribuerar den dem över flera noder i ett kluster. Däremot använder Kafka sekventiell åtkomst som liknar HDFS och lagrar data i ett buffertminne.
#3. ETL-transformering
Både Spark och Kafka stöder ETL-transformationsprocessen, som kopierar poster från en databas till en annan, vanligtvis från en transaktionsbas (OLTP) till en analysbas (OLAP). Men till skillnad från Spark, som har en inbyggd funktion för ETL-process, förlitar sig Kafka på Streams API för att stödja detta.
#4. Datapersistens

Sparks användning av RRD gör att du kan lagra data på flera platser för senare användning, medan du i Kafka måste definiera datauppsättningsobjekt i konfigurationen för att bevara data.
#5. Komplexitet
Spark är en komplett lösning och lättare att lära sig tack vare dess stöd för olika programmeringsspråk på hög nivå. Kafka är beroende av ett antal olika API:er och tredjepartsmoduler, vilket kan göra det svårare att arbeta med.
#6. Återhämtning
Både Spark och Kafka erbjuder alternativ för återhämtning. Spark använder RRD, vilket möjliggör kontinuerlig lagring av data. Om ett klusterfel uppstår kan det återställas.

Kafka replikerar data kontinuerligt i klustret och mellan mäklare, vilket gör att du kan växla till de andra mäklarna om det skulle uppstå ett fel.
Likheter mellan Spark och Kafka
| Apache Spark | Apache Kafka | |
| Öppen källkod | Öppen källkod | Öppen källkod |
| Användningsområde | Skapa applikationer för dataströmning | Skapa applikationer för dataströmning |
| Stateful-bearbetning | Stöds | Stöds |
| SQL-stöd | Stöds | Stöds |
Slutord
Kafka och Spark är båda verktyg med öppen källkod skrivna i Scala och Java, vilket gör det möjligt att bygga applikationer för realtidsdataströmning. De har flera saker gemensamt, inklusive stateful-bearbetning, stöd för SQL och ETL. Kafka och Spark kan även användas som kompletterande verktyg för att hantera komplexiteten vid dataöverföring mellan applikationer.