Förstå ETL: Extrahera, Transformera, Ladda
ETL, en förkortning för Extrahera, Transformera och Ladda, är en central process inom datahantering. ETL-verktyg ansvarar för att hämta data från varierande källor, omvandla denna data till ett lämpligt format som matchar kraven för det aktuella målsystemet eller datamodellen, och slutligen, för att överföra den transformerade datan till en slutdestination som kan vara en databas, ett datalager eller till och med en datasjö.
För inte så länge sedan, för 15-20 år sedan, var ETL ett begrepp som få hade djupare insikt i. Anpassade batchjobb var då på sin höjdpunkt, kördes ofta direkt på lokal hårdvara.
Många projekt använde sig av någon form av ETL, även om de inte nödvändigtvis benämnde det så. På den tiden, när jag beskrev designlösningar som involverade ETL-processer, framstod det nästan som en futuristisk teknologi. Idag har läget dock förändrats dramatiskt.
Migration till molnet är numera en prioriterad fråga, och ETL-verktyg har blivit en strategiskt viktig del av arkitekturen i de flesta projekt. En molnmigrering innebär ofta att data flyttas från lokala källor till molnbaserade databaser, anpassat för att vara så kompatibelt som möjligt med molnets arkitektur. Just detta är det ETL-verktyg gör.
ETL:s Utveckling och Dess Relevans Idag
Källa: aws.amazon.com
ETL:s kärnfunktioner har alltid varit konstanta. Verktygen hämtar data från olika ursprung, det kan vara databaser, enkla textfiler, webbtjänster eller moderna molntjänster.
Tidigare innebar detta ofta att ta in filer från ett Unix-filsystem som indata och sedan bearbeta dem i olika steg: förbearbetning, bearbetning och efterbearbetning.
Ett återkommande mönster var mappstrukturen, där mappar döptes till exempel:
- Indata
- Utdata
- Fel
- Arkiv
Inuti dessa mappar fanns ytterligare undermappar, ofta organiserade efter datum.
Detta var det standardmässiga sättet att behandla inkommande data och förbereda den för att laddas in i någon form av databas.
Idag är situationen annorlunda, Unix-filsystem är mindre vanliga, och ibland finns inte filer alls. Istället används ofta API:er, eller gränssnitt för applikationsprogrammering. Indataformatet behöver inte längre vara filbaserat.
Allt kan lagras i cacheminnet, men oavsett källan behöver informationen följa ett strukturerat format, oftast JSON eller XML. I vissa fall fungerar även det traditionella CSV-formatet (kommaseparerade värden).
Användaren definierar själva indataformatet. Om historik ska sparas för indatafiler är ett val som processen gör. Det är inte längre ett standardsteg.
Transformation
ETL-verktyg omvandlar den extraherade datan till ett format som är lämpligt för analys. Denna process innefattar datarensning, datavalidering, databerikning och dataaggregering.
Tidigare var det vanligt att datan genomgick komplex anpassad logik med Pro-C eller PL/SQL för att dela, transformera och schemalägga lagringssteg. Det var lika standardiserat som att dela upp inkommande filer i undermappar baserat på bearbetningsstadiet.
Varför var det så naturligt, trots att det var fundamentalt felaktigt? Genom att direkt transformera inkommande data utan permanent lagring förlorade man den stora fördelen med rådata – dess oföränderlighet. Projekt slängde bort det utan möjlighet till återställning.
Idag är tumregeln att ju mindre transformation man gör på rådata i det initiala steget, desto bättre. För den första datalagringen i systemet vill man lagra rådata så oförändrad och atomär som möjligt. Det är ett stort skifte jämfört med hur det var tidigare.
Ladda
ETL-verktygen laddar sedan in den transformerade datan i en måldatabas eller datalager. Det innefattar att skapa tabeller, definiera relationer och ladda data i rätt fält.
Laddningssteget är förmodligen det enda som följer ett liknande mönster över tid. Den enda egentliga skillnaden är vilken databas som är målet. Tidigare var det oftast Oracle, men nu kan det vara vilken databas som helst som finns i AWS-molnet.
ETL i Dagens Molnmiljö
Om du ska flytta din data från lokala system till (AWS) molnet, är ett ETL-verktyg nödvändigt. Det går inte utan, och det har lett till att denna del av molnarkitekturen har blivit en avgörande pusselbit. Om det här steget blir fel, kommer allt annat efteråt att påverkas negativt.
Det finns flera olika aktörer på marknaden, men jag fokuserar på de tre jag har mest erfarenhet av:
- Data Migration Service (DMS) – en inbyggd tjänst från AWS.
- Informatica ETL – förmodligen den största kommersiella aktören inom ETL, som anpassar sin verksamhet från lokal drift till molnet.
- Matillion för AWS – en relativt ny aktör i molnmiljöer. Inte inbyggd i AWS men byggd för molnet. Har inte samma långa historia som Informatica.
AWS DMS som ETL
Källa: aws.amazon.com
AWS Data Migration Services (DMS) är en fullständigt hanterad tjänst som möjliggör migrering av data från olika källor till AWS. Tjänsten stödjer flera migreringsscenarier.
- Homogena migreringar (till exempel Oracle till Amazon RDS för Oracle).
- Heterogena migreringar (till exempel Oracle till Amazon Aurora).
DMS kan flytta data från en mängd källor, inklusive databaser, datalager och SaaS-applikationer, till olika mål såsom Amazon S3, Amazon Redshift och Amazon RDS.
AWS ser DMS-tjänsten som det viktigaste verktyget för att överföra data från vilken databaskälla som helst till molnbaserade system. Huvudsyftet är datakopiering till molnet men tjänsten gör även ett bra jobb med att transformera data längs vägen.
Man kan definiera DMS-uppgifter i JSON-format för att automatisera olika transformationer samtidigt som datan flyttas från källa till mål:
- Slå ihop flera källtabeller eller kolumner till ett enda värde.
- Dela upp ett källvärde i flera målfält.
- Ersätt källdata med ett annat målvärde.
- Ta bort onödig data eller skapa helt ny data baserat på sammanhanget.
Detta innebär att DMS kan användas som ett ETL-verktyg för dina projekt. Det kanske inte är lika sofistikerat som andra alternativ, men det fungerar om målen är tydligt definierade från början.
Lämplighetsfaktor
Även om DMS har en del ETL-funktioner, fokuserar tjänsten primärt på datamigrering. I vissa fall kan det vara bättre att använda DMS istället för ETL-verktyg som Informatica eller Matillion:
- DMS hanterar homogena migreringar där käll- och måldatabaser är av samma typ. Det kan vara en fördel om man flyttar data mellan databaser av samma typ, som Oracle till Oracle eller MySQL till MySQL.
- DMS tillhandahåller grundläggande datatransformationsmöjligheter men är inte lika utvecklat som dedikerade ETL-verktyg. Det kan dock räcka om man har begränsade behov av datatransformation.
- Datakvalitet och styrningsbehov är generellt sett begränsade med DMS. Det är dock områden som kan utvecklas i senare skeden med andra verktyg. Om man vill hålla ETL-delen så enkel som möjligt är DMS ett bra val.
- DMS kan vara ett mer kostnadseffektivt alternativ för organisationer med en begränsad budget. Prismodellen är enklare än för verktyg som Informatica eller Matillion, vilket gör det lättare att förutsäga och hantera kostnaderna.
Matillion ETL
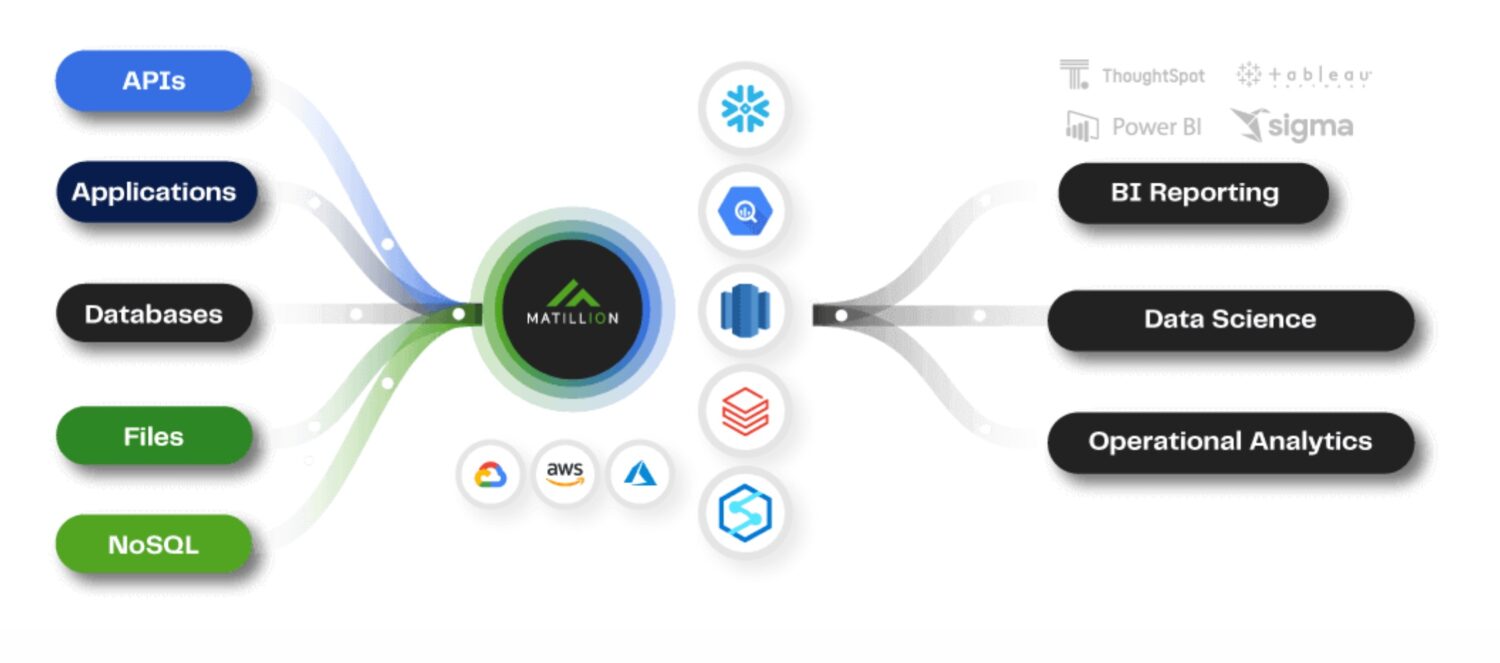
Källa: matillion.com
Matillion är en molnbaserad lösning för att integrera data från olika källor, som databaser, SaaS-applikationer och filsystem. Verktyget erbjuder ett visuellt gränssnitt för att skapa ETL-pipelines och har stöd för flera AWS-tjänster som Amazon S3, Amazon Redshift och Amazon RDS.
Matillion är lättanvänt och kan passa bra för organisationer som är nya på ETL eller som har mindre komplexa dataintegrationsbehov.
Å andra sidan är Matillion relativt ostrukturerat, man måste anpassa verktyget för att använda det effektivt. Man kan inte förvänta sig att Matillion löser alla uppgifter direkt, även om möjligheterna finns där.
Matillion beskrivs ofta som ett ELT-verktyg snarare än ett ETL, vilket innebär att fokus ligger på att ladda datan innan transformationen.
Lämplighetsfaktor
Matillion är med andra ord mer effektivt när man transformerar data efter att den har lagrats i databasen. En anledning till detta är att anpassade skript behövs, all speciell funktionalitet måste kodas först. Effektiviteten beror alltså mycket på den anpassade kodens kvalitet.
Det är rimligt att anta att detta hanteras bäst i måldatabassystemet, och att Matillion enbart har i uppgift att ladda in data 1:1. Där finns mindre risk att förstöra något med anpassad kod.
Även om Matillion erbjuder en rad funktioner för dataintegration, kanske det inte har samma nivå av datakvalitet och styrningsfunktioner som andra ETL-verktyg.
Matillion kan skala upp eller ner efter organisationens behov, men kanske inte är lika effektivt för att hantera mycket stora datamängder. Parallell bearbetning är begränsad. I det avseendet är Informatica ett bättre alternativ då det är mer avancerat.
För många organisationer ger Matillion för AWS tillräcklig skalbarhet och parallell kapacitet.
Informatica ETL
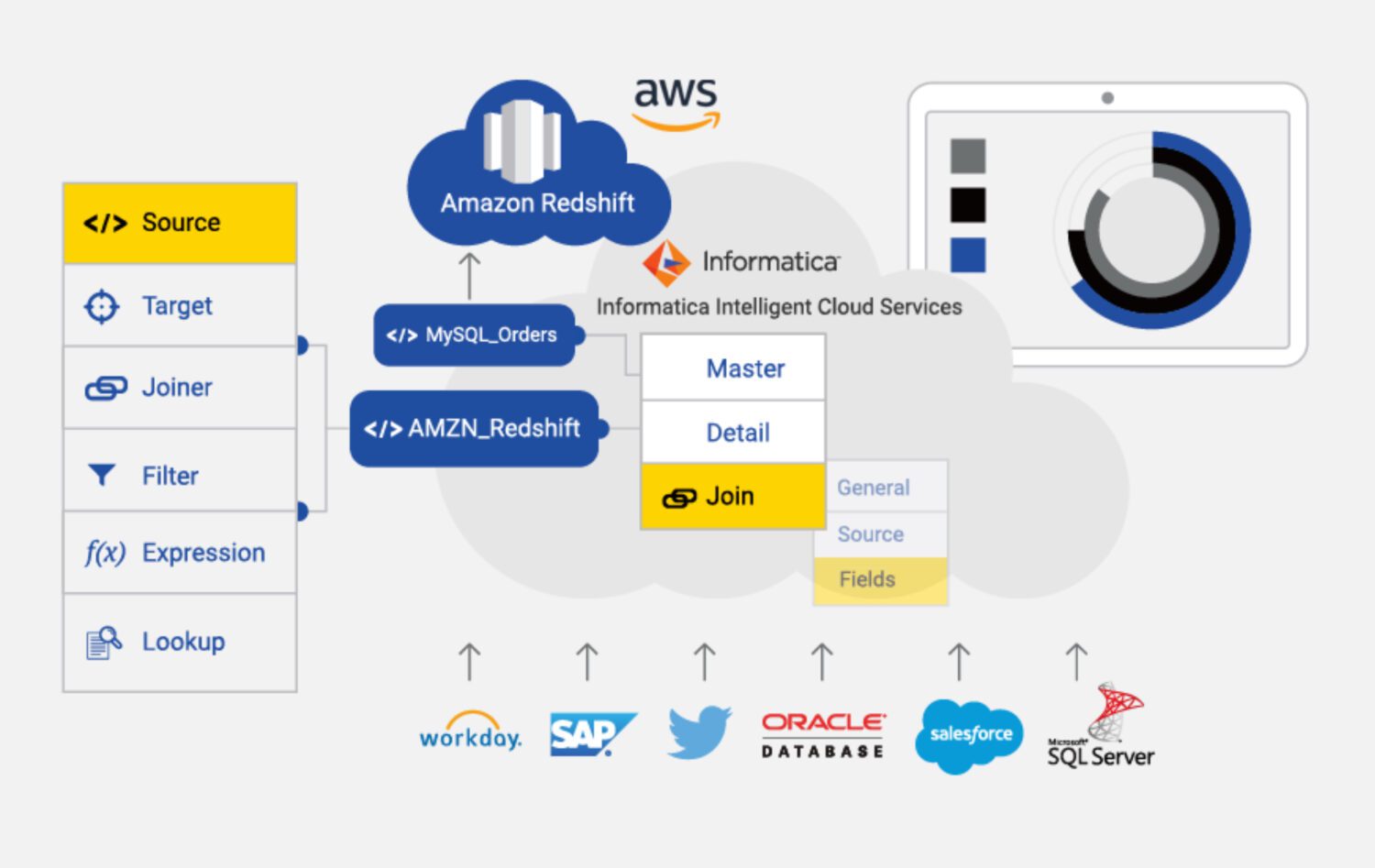
Källa: informatica.com
Informatica för AWS är ett molnbaserat ETL-verktyg för att integrera och hantera data från olika källor och mål i AWS. Det är en helt hanterad tjänst med flera funktioner för dataintegration, inklusive dataprofilering, datakvalitet och datastyrning.
Några viktiga egenskaper hos Informatica för AWS är:
- Informatica är designat för att skala upp eller ner efter faktiska behov. Det kan hantera stora mängder data och integrera data från flera källor, som databaser, datalager och SaaS-applikationer.
- Informatica har flera säkerhetsfunktioner, inklusive kryptering, åtkomstkontroller och granskningsspår. Det följer olika industristandarder som HIPAA, PCI DSS och SOC 2.
- Informatica har ett visuellt gränssnitt för att skapa ETL-pipelines, vilket gör det lätt att hantera dataintegrationsprocesser. Det finns även flera fördefinierade kopplingar och mallar för att ansluta systemen.
- Informatica integreras med olika AWS-tjänster som Amazon S3, Amazon Redshift och Amazon RDS, vilket underlättar dataöverföring mellan dessa tjänster.
Lämplighetsfaktor
Informatica är det mest funktionsrika ETL-verktyget i den här listan. Det kan dock vara dyrare och mer komplext att använda än de andra verktygen.
Informatica kan vara kostsamt, särskilt för små och medelstora organisationer. Prismodellen bygger på användning, vilket kan leda till högre kostnader om användningen ökar.
Verktyget kan också vara komplext att installera och konfigurera, speciellt för de som är nya på ETL. Det kan kräva betydande investeringar i tid och resurser.
Det finns också en ”komplex inlärningskurva”. Det kan vara en nackdel för de som behöver integrera data snabbt eller har begränsade resurser.
Informatica är kanske inte lika effektivt för att integrera data från icke-AWS-källor. I det fallet kan DMS eller Matillion vara bättre alternativ.
Informatica är till stor del ett slutet system, det finns begränsade möjligheter att anpassa det efter projektets specifika behov. Man måste i stort sett använda standardinställningarna, vilket kan begränsa flexibiliteten.
Slutord
Det finns ingen universallösning, inte ens när det gäller ETL-verktyg i AWS.
Man kan välja den mest komplexa, funktionsrika och dyra lösningen med Informatica, men det är mest vettigt om:
- Projektet är ganska stort och man är säker på att hela lösningen och alla datakällor kommer att fungera med Informatica.
- Man har råd att anlita ett team av erfarna Informatica-utvecklare och konfiguratörer.
- Man värdesätter robust support och är beredd att betala för det.
Om något av ovanstående inte stämmer kan man istället ge Matillion ett försök:
- Om projektets behov inte är alltför komplexa.
- Om man behöver infoga anpassade steg i bearbetningen och flexibilitet är ett viktigt krav.
- Om man inte har något emot att bygga de flesta funktionerna från grunden med teamet.
För allt som är ännu mindre komplicerat är DMS för AWS det självklara valet, som en inbyggd tjänst som sannolikt fyller sitt syfte.
Kolla sedan in verktyg för datatransformation för att hantera din data bättre.