Om du har bekantat dig med programmeringsspråk, har du förmodligen stött på begreppet texttolkning. Det handlar om att göra komplicerad data i en fil mer lättförståelig. Denna artikel kommer att ge dig en djupare förståelse för hur du kan tolka text med hjälp av olika programmeringsverktyg. Om du dessutom har sett felmeddelanden som ”parse text x”, kommer du att lära dig hur du kan felsöka och korrigera dessa problem.
Att Tolka Text: En Komplett Guide
I den här artikeln ger vi en omfattande guide till olika sätt att tolka text och en kort introduktion till begreppet.
Vad Innebär Egentligen Texttolkning?
Innan du börjar gräva ner dig i de tekniska aspekterna av texttolkning, är det viktigt att förstå grunderna i programmering.
Naturlig Språkbehandling (NLP)
Texttolkning använder ofta Naturlig Språkbehandling (NLP), en gren av artificiell intelligens. Python är ett populärt språk i denna kategori, som ofta används för just texttolkning.
NLP-koder gör det möjligt för datorer att bearbeta mänskligt språk, vilket öppnar för en mängd olika applikationer. För att använda maskininlärningstekniker på text, måste ostrukturerad text omvandlas till strukturerade data i tabellform. Python är det språk som oftast används för att utföra denna omvandling.
Definition av Texttolkning
Texttolkning är i grunden konvertering av data från ett format till ett annat. Ett filformat kan behöva tolkas till ett annat för att en användare ska kunna använda det i en annan applikation.
- Detta innebär att analysera en sträng eller text och bryta ner den till logiska komponenter genom att ändra filens format.
- Vissa regler i Python används för att utföra detta vanliga programmeringsarbete. När en text tolkas delas den upp i mindre beståndsdelar.
Varför är Texttolkning Nödvändig?
Det finns flera skäl till att texttolkning är nödvändig:
- Inte all datoriserad data lagras i samma format. Formatet kan skilja sig beroende på vilken applikation som används.
- Dataformat varierar för olika applikationer och inkompatibel kod kan orsaka fel.
- Det finns inget universellt program som kan hantera alla dataformat.
Metod 1: Användning av DataFrame Class
DataFrame-klassen i Python tillhandahåller de nödvändiga funktionerna för att tolka text. Det är ett inbyggt bibliotek som innehåller kod för att konvertera data från ett format till ett annat.
En kort introduktion till DataFrame Class:
DataFrame Class är en datastruktur som används för dataanalys. Det är ett verktyg som kan analysera data med minimal ansträngning.
- Koden laddas in i pandas DataFrame för att utföra analys i Python.
- Klassen inkluderar flera paket från pandas-biblioteket som används av dataanalytiker.
- Funktionaliteten i klassen är en abstraktion. Den interna funktionaliteten är dold för användarna. Detta finns också i NumPy-biblioteket. NumPy är ett bibliotek som innehåller kommandon för att arbeta med arrayer.
- DataFrame-klassen kan rendera en tvådimensionell array med flera rad- och kolumnindex. Dessa index hjälper till att lagra flerdimensionell data och kallas MultiIndex. Dessa måste ändras för att lösa problem med tolkningsfel.
Pandas i Python hjälper till att utföra SQL-liknande operationer, vilket minskar risken för fel i analys av text x. Det innehåller även verktyg för att läsa CSV, MS Excel, JSON, HDF5 och andra format.
Process för texttolkning med DataFrame Class:
Följande steg visar hur du kan tolka text med DataFrame Class:
- Identifiera dataformatet för indata.
- Bestäm utdataformat (t.ex. CSV).
- Skriv koden med en grundläggande datatyp som list eller dict.
Obs: Att skriva kod direkt på en tom DataFrame kan vara komplicerat. Pandas tillåter skapandet av data på DataFrame från dessa datatyper, vilket förenklar processen.
- Analysera datan med hjälp av pandas DataFrame och skriv ut resultatet.
Alternativ I: Standardformat
Här beskrivs en standardmetod för att formatera en fil i ett visst dataformat som CSV.
- Spara filen lokalt på din dator (t.ex. data.txt).
- Importera filen i pandas och tilldela den en variabel. Till exempel importeras pandas till namnet ”pd” i koden.
- Importen ska innehålla information om indatafilens namn, funktion och filformat.
Obs: Variabeln ”res” används här för att läsa data från ”data.txt” med hjälp av pandas (importerat som ”pd”). Dataformatet anges som CSV.
- Anropa filtypen och analysera den tolkade texten. Kommandot ”res” efter körning kommer att skriva ut den tolkade texten.
Ett exempel på koden visas nedan:
import pandas as pd res = pd.read_csv(‘data.txt’) res
Om filen ”data.txt” innehåller data som t.ex. [1,2,3] kommer det att tolkas och visas som 1 2 3.
Alternativ II: Strängmetod
Om texten endast innehåller strängar eller alfanumeriska tecken, kan specialtecken (komma, mellanslag etc.) användas för att separera och tolka texten. Processen liknar vanliga strängoperationer. Följande steg visar hur man går tillväga:
- Extrahera data från strängen och notera alla specialtecken som skiljer texten åt.
I exemplet nedan identifieras tecknen ”,” och ”:” i strängen ”my_string”. Detta steg är kritiskt för att undvika fel vid texttolkning.
- Dela upp texten baserat på specialtecknens värden och positioner.
Strängen delas upp i textvärden med hjälp av kommandot ”split”.
- Skriv ut textens individuella värden. ”print”-satsen används för att visa den tolkade datan.
Exempelkod:
my_string = ‘Names: Tech, computer’
sfinal = [name.strip() for name in my_string.split(‘:’)[1].split(‘,’)]
print(“Names: {}”.format(sfinal))
Resultatet av den tolkade strängen kommer att visas som:
Names: [‘Tech’, ‘computer’]
För att få en tydligare bild av processen, kan en for-loop användas:
my_string = ‘Names: Tech, computer’
s1 = my_string.split(‘:’)
s2 = s1[1]
s3 = s2.split(‘,’)
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print(“Step {}: {}”.format(idx, item))
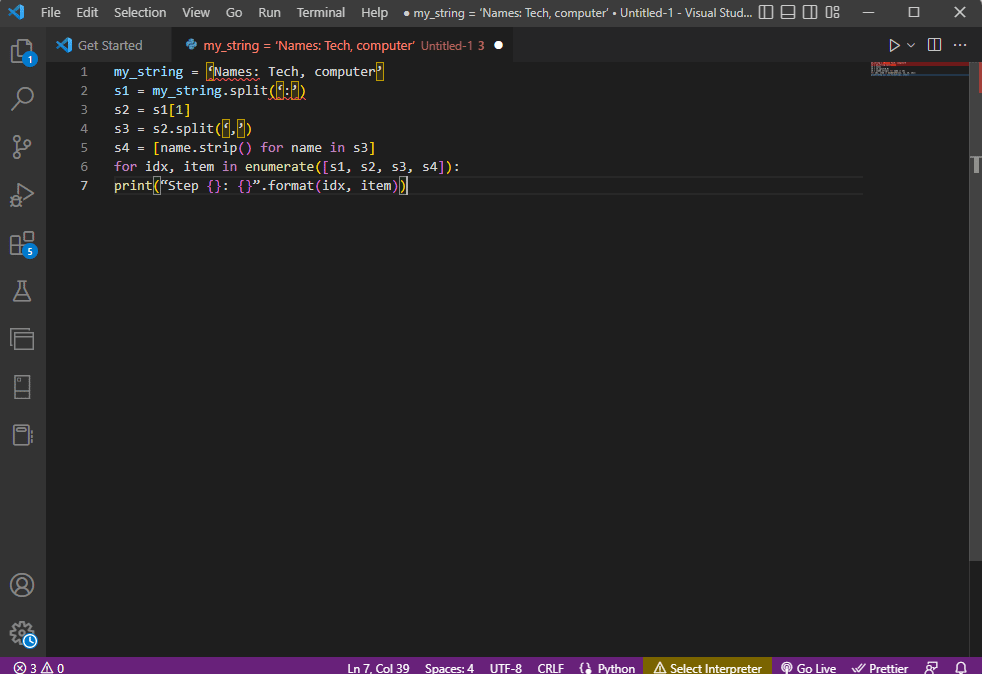
Resultatet av varje steg i tolkningen visas nedan. I steg 0 delas strängen baserat på tecknet ”:” och texten delas vidare i efterföljande steg.
Step 0: [‘Names’, ‘Tech, computer’] Step 1: Tech, computer Step 2: [‘ Tech’, ‘ computer’] Step 3: [‘Tech’, ‘computer’]
Alternativ III: Tolkning av komplexa filer
I de flesta fall innehåller fildata olika datatyper och värden, vilket gör det svårare att tolka dem med de tidigare metoderna.
Målet är att presentera datat i tabellform.
- Titlar och metadata skrivs ut längst upp i filen.
- Variabler och fält presenteras i tabellform.
- Datavärdena bildar en sammansatt nyckel.
Innan du går vidare med denna metod, är det viktigt att förstå grundläggande begrepp som reguljära uttryck (Regex).
Regex-mönster
För att undvika tolkningsfel, är det viktigt att regex-mönstren i uttrycken är korrekta. Vanliga Regex-mönster inkluderar:
\d: matchar decimalsiffror.\s: matchar blanktecken.\w: matchar alfanumeriska tecken.+eller*: matchar ett eller flera tecken girigt.[a-z]: matchar små bokstäver.[A-Z]eller[a-z]: matchar stora och små bokstäver.[0-9]: matchar numeriska värden.
Reguljära uttryck
Reguljära uttryck (Regex) är en del av pandas-paketet i Python. Det är ett litet språk inbäddat i Python som används för att hitta strängmönster. Regex är strängar med speciell syntax, som tillåter användaren att matcha mönster baserat på värden i andra strängar.
Regex skapas baserat på datatyp och uttryckets behov. Symboler som används i Regex inkluderar:
.: hämtar valfritt tecken.*: noll eller fler förekomster av föregående uttryck.(.*): grupperar en del av det reguljära uttrycket inom parentes.\n: skapar ett nytt linjetecken.\d: skapar ett heltal mellan 0 och 9.+: en eller flera förekomster av föregående uttryck.|: logiskt ”eller”.
RegexObjects
RegexObject är ett returvärde från kompileringsfunktionen och returnerar ett MatchObject om uttrycket matchar matchningsvärdet.
1. MatchObject
Eftersom det booleska värdet för ett MatchObject alltid är ”True”, kan du använda en ”if”-sats för att identifiera positiva matchningar. Index används för att hämta matchningen i uttrycket.
group(): returnerar en eller flera undergrupper av matchningen.group(0): returnerar hela matchningen.group(1): returnerar den första undergruppen med parentes.- För flera grupper används en Python-specifik förlängning för att namnge gruppen. Till exempel skulle uttrycket
(?Phänvisa till gruppen ”group1” och söka efter matchning iregex1) regex1. Det är viktigt att kontrollera att gruppen pekar rätt för att lösa problem med tolkningsfel.
2. Metoder för MatchObject
MatchObject har två metoder:
Match(sträng): hittar matchningar i början av det reguljära uttrycket.Search(sträng): skannar strängen för att hitta en matchning.
Funktioner för reguljära uttryck
Regex-funktioner är kodrader som utför en specifik uppgift. Råsträngar används för att undvika fel i tolkningen genom att lägga till ”r” framför varje mönster.
Vanliga funktioner inkluderar:
1. re.findall()
Returnerar alla mönster om en matchning hittas, annars en tom lista.
2. re.split()
Delar upp strängen om en matchning hittas med t.ex. mellanslag. Annars returneras en tom sträng.
3. re.sub()
Ersätter den matchade texten. Returnerar den ursprungliga strängen om inget mönster hittas.
4. re.search()
Söker efter mönstret och returnerar MatchObject. Returnerar inget värde om sökningen misslyckas.
5. re.compile(pattern)
Kompilerar reguljära uttrycksmönster till ett RegexObject.
Andra krav
regexperanvänds för att visualisera reguljära uttryck.regex101används för att testa reguljära uttryck.
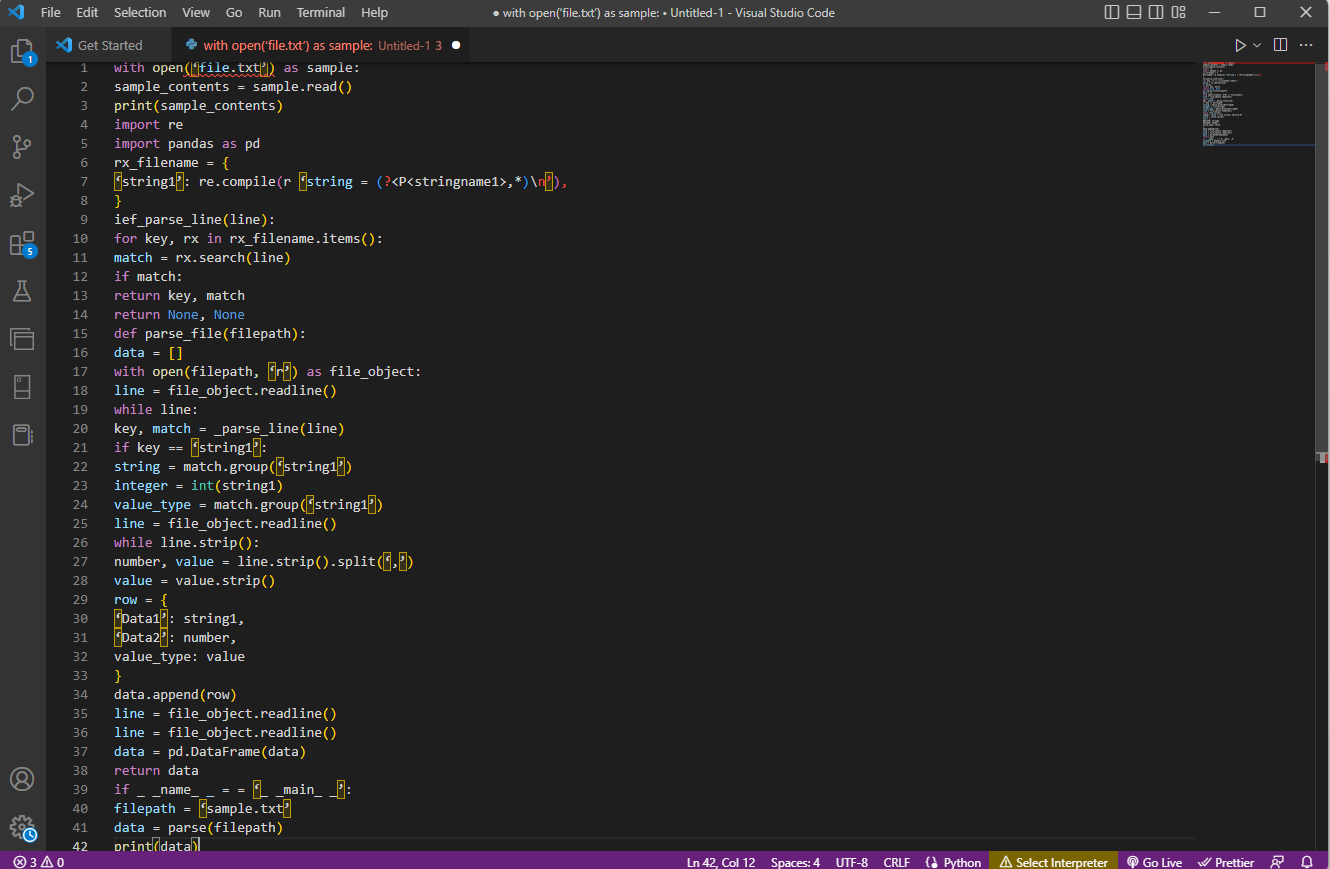
Processen för texttolkning (komplexa filer)
- Förstå inmatningsformatet genom att läsa filens innehåll. T.ex. används
with openochread()för att öppna filen ”sample.txt”. - Skriv ut filens innehåll för att manuellt analysera datan och metadata.
print()används här. - Importera nödvändiga paket (t.ex.
reochpandas) och tilldela ett namn till klassen. - Definiera reguljära uttryck som behövs.
compile()används för att kompilera strängen från gruppen ”stringname1”. Funktionensearch()används för att leta efter matchningar.- Skriv en radtolkare (
def_parse_file(filepath)), som kontrollerar alla regex-matchningar. Metodenregex search()söker efter nyckeln ”rx” och returnerar nyckeln och matchningen. - Skapa en filtolkare (
def_parse_file(filsökväg)). En tom lista (data = []) skapas, matchningen kontrolleras på varje rad (match = _parse_line(line)), och korrekt data returneras. - Extrahera nummer och värde.
line.strip().split(',')används här. Skapa en dictionary medrow{}, och lägg till det i listan meddata.append(row).
data = pd.DataFrame(data) används för att skapa en pandas DataFrame från dict-värdena. Alternativt kan du använda följande kommandon:
data.set_index(['string', 'integer'], inplace=True)för att ange tabellens index.data = data.groupby(level=data.index.names).first()för att konsolidera och ta bortNaN.data = data.apply(pd.to_numeric, errors='ignore')för att konvertera poäng från float till heltal.
Testa parsern med en if-sats och skriv ut resultatet med print(data).
Exempelkoden visas här:
with open(‘file.txt’) as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
‘string1’: re.compile(r ‘string = (?<P<stringname1>,*)n’),
}
ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, ‘r’) as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == ‘string1’:
string = match.group(‘string1’)
integer = int(string1)
value_type = match.group(‘string1’)
line = file_object.readline()
while line.strip():
number, value = line.strip().split(‘,’)
value = value.strip()
row = {
‘Data1’: string1,
‘Data2’: number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if _ _name_ _ = = ‘_ _main_ _’:
filepath = ‘sample.txt’
data = parse(filepath)
print(data)
Metod 2: Word Tokenization
Att konvertera text till mindre delar, kallade tokens, kallas tokenisering. Det är viktigt att förstå kommandon för ordtokenisering för att åtgärda tolkningsfel. Tokenisering hjälper till med textförbehandling, som att hitta delar av tal och rensa text. Felaktig tokenisering kan leda till fel i analys av text x.
NLTK bibliotek
NLTK (Natural Language Toolkit) är ett populärt bibliotek för NLP-uppgifter, som kan installeras med Pip eller Pip-installationspaketen.
Former av tokenisering
De vanligaste formerna är ordtokenisering och meningstokenisering. Den första skriver ut varje ord individuellt, medan den senare skriver ut meningen i sin helhet.
Processen för texttolkning
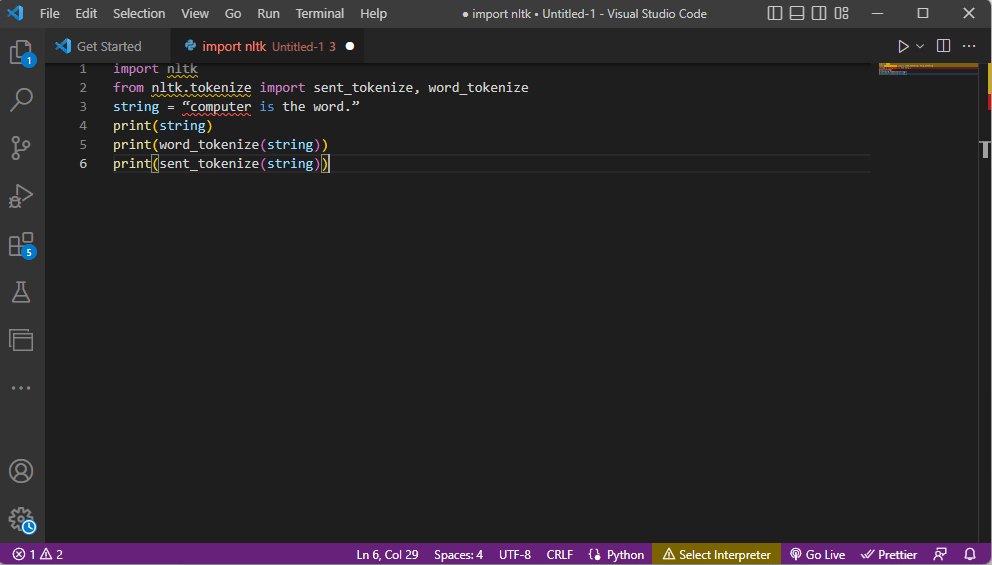
- Importera NLTK och tokeniseringsfunktionerna.
- Ge en sträng och kör tokeniseringskommandona.
- När du skriver ut strängen kommer utdata att vara ”dator är ordet.”
- Vid ordtokenisering (
word_tokenize()), skrivs varje ord ut individuellt inom citationstecken och separeras med kommatecken. Utdata skulle vara: ’dator’, ’är’, ’ordet’, ’.’ - Vid meningstokenisering (
sent_tokenize()) placeras individuella meningar inom citationstecken, vilket möjliggör ordrepetitioner. Utdata skulle vara: ”dator är ordet.”
Följande kod illustrerar tokeniseringsstegen:
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = “computer is the word.” print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Metod 3: DocParser Class
DocParser Class, likt DataFrame Class, används för att tolka text. Klassen anropar parse-funktionen med filsökvägen.
Processen för texttolkning
Följande instruktioner visar hur du tolkar text med DocParser-klassen:
get_format(filnamn)används för att extrahera filtillägget, returnera det och skicka det till nästa funktion.- En logisk struktur byggs med hjälp av
if-elif-else-satser. - Om filtillägget är giltigt och strukturen är logisk, används
get_parserför att analysera data och returnera strängobjektet.
Obs: Funktionen måste implementeras korrekt för att undvika tolkningsfel.
- Analysen av data görs med hjälp av filtillägget. Den konkreta implementeringen av klassen, t.ex.
parse_txtellerparse_docx, används för att generera strängobjekt. - Analysen kan göras för andra filformat, t.ex.
parse_pdf,parse_htmlochparse_pptx. - Data kan importeras till applikationer med
import-satser och instansiera ett DocParser-objekt (t.ex.parse_file.py).
Metod 4: Verktyg för Texttolkning
Verktyg för texttolkning används för att extrahera specifik data och koppla den till andra variabler. Det är oberoende av andra verktyg och använder plattformens in- och ut-variabler. Du kan använda detta verktyg online.
Metod 5: TextFieldParser (Visual Basic)
TextFieldParser används för att tolka och bearbeta stora, strukturerade filer, t.ex. loggfiler. Metoden används för att extrahera textfält liknande strängmanipulationsmetoder. Avgränsade strängar och fält med olika bredder tokeniseras med avgränsare som komma eller tabbutrymme.
Funktioner för texttolkning
SetDelimitersanvänds för att definiera en avgränsare. T.ex. användstestReader.SetDelimiters(vbTab)för att ställa in tabbutrymme som avgränsare.testReader.SetFieldWidths (integer)används för att ställa in en fältbredd för fast fältbredd.testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidthanvänds för att testa fälttypen.
Metoder för att hitta MatchObject
- Definiera formatet och gå igenom filen med metoden
ReadFields. - Metoden
PeekCharsanvänds för att kontrollera varje fält individuellt innan du läser det, vilket gör att du kan reagera på olika format.
Om ett fält inte matchar formatet, returneras ett MalformedLineException-undantag.
Expert Tips: Texttolkning med MS Excel
Som en sista metod kan du använda MS Excel för att skapa tabbavgränsade och kommaavgränsade filer. Detta kan användas för att dubbelkolla dina tolkade resultat och hjälpa dig hitta fel.
1. Markera datavärdena och tryck Ctrl+C för att kopiera.
2. Öppna Excel.
3. Klicka på A1 och tryck Ctrl+V för att klistra in texten.
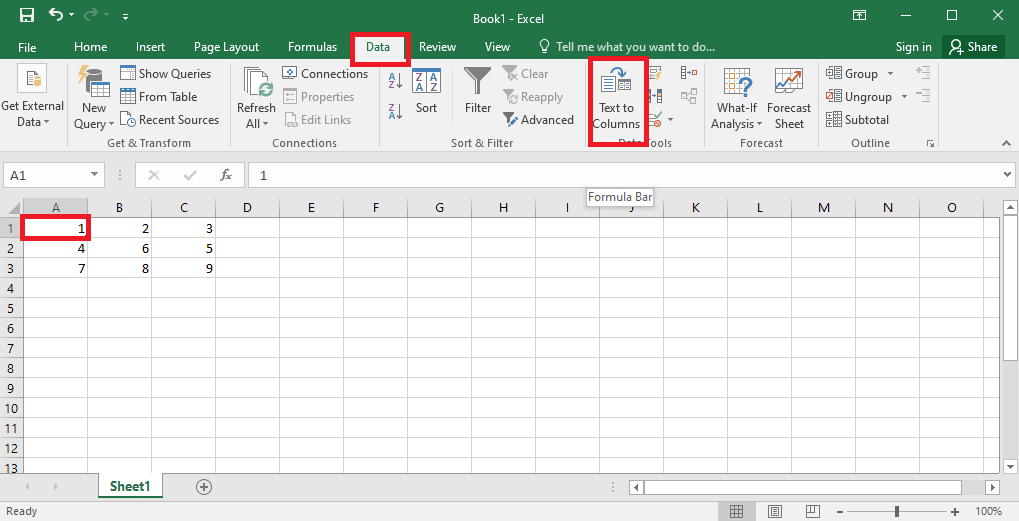
4. Välj A1, gå till fliken ”Data” och klicka på ”Text till kolumner” i avsnittet ”Dataverktyg”.
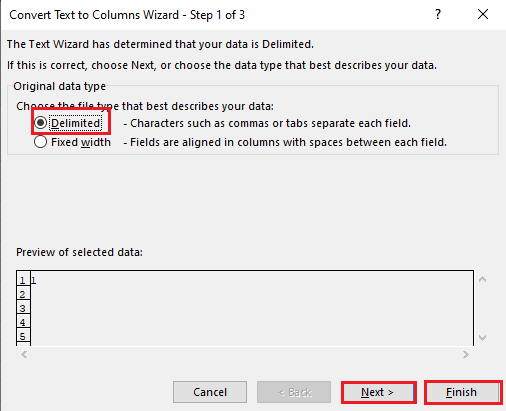
5A. Välj ”Avgränsat” om ett komma eller tabbutrymme används som avgränsare och klicka ”Nästa” och ”Slutför”.
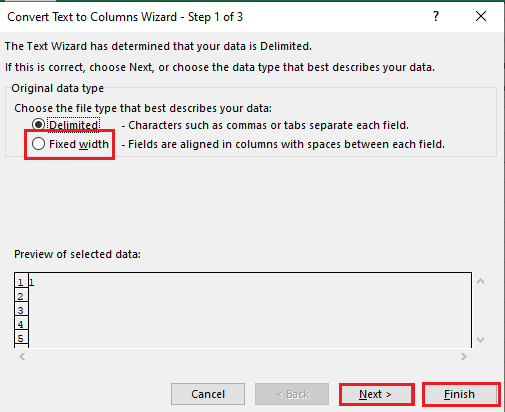
5B. Välj ”Fast bredd”, ange ett värde för avgränsaren och klicka ”Nästa” och ”Slutför”.
Hur Man Åtgärdar Tolkningsfel
Felmeddelanden som ”Parse Error: Det uppstod ett problem med att analysera paketet” kan uppstå på Android. Detta händer oftast när appen inte kan installeras från Google Play Butik, eller om en app från tredje part körs.
Felet kan uppstå om en lista med teckenvektorer loopas, eller om linjära modeller används för att beräkna data. Ett felmeddelande kan vara ”Error in parse(text = x, keep.source = FALSE)::2.0:unexpected end of input 1:OffenceAgainst ~ ^.”.
Du kan läsa artiklar om hur du åtgärdar tolkningsfel på Android för att lära dig mer om orsakerna och metoderna för att lösa felet.
Ytterligare korrigeringar kan vara:
- Ladda ner
.apk-filen igen eller ändra namnet på filen. - Återställ ändringar i filen
AndroidManifest.xml, om du har programmeringskunskaper.
***
Denna artikel har visat hur man tolkar text och hur man åtgärdar tolkningsfel. Berätta vilken metod som hjälpte dig att lösa fel i analys av text x, och vilken metod du föredrar. Dela gärna dina tankar och frågor i kommentarsfältet nedan.